생성형 AI는 이제 텍스트, 이미지, 코드까지 만들어낸다.
하지만 실제 서비스에서는 “좋은 답변”보다 더 중요한 게 있다.
-> 사용자가 바로 행동할 수 있는 인터페이스
A2UI(Agent-to-User Interface)는 이 문제를 해결하기 위해 등장한 프로토콜이다.
에이전트가 단순한 텍스트가 아니라 실행 가능한 UI 구조 자체를 전달하는 방식이다.
왜 A2UI가 필요한가
기존 LLM 기반 인터랙션은 이런 흐름이다.
- 사용자: "예약하고 싶어"
- AI: "날짜를 입력하세요"
- 사용자: "3월 25일"
- AI: "시간을 입력하세요"
-> 솔직히 말하면 비효율적이다.
A2UI는 이렇게 바꾼다.
- 사용자: "예약하고 싶어"
- AI: 날짜 선택 UI + 시간 선택 UI + 버튼 생성
즉,
대화 → 인터페이스로 전환
핵심 개념 한 줄 요약
에이전트는 "HTML을 보내는 게 아니라"
UI의 의도(구조)를 데이터로 보낸다
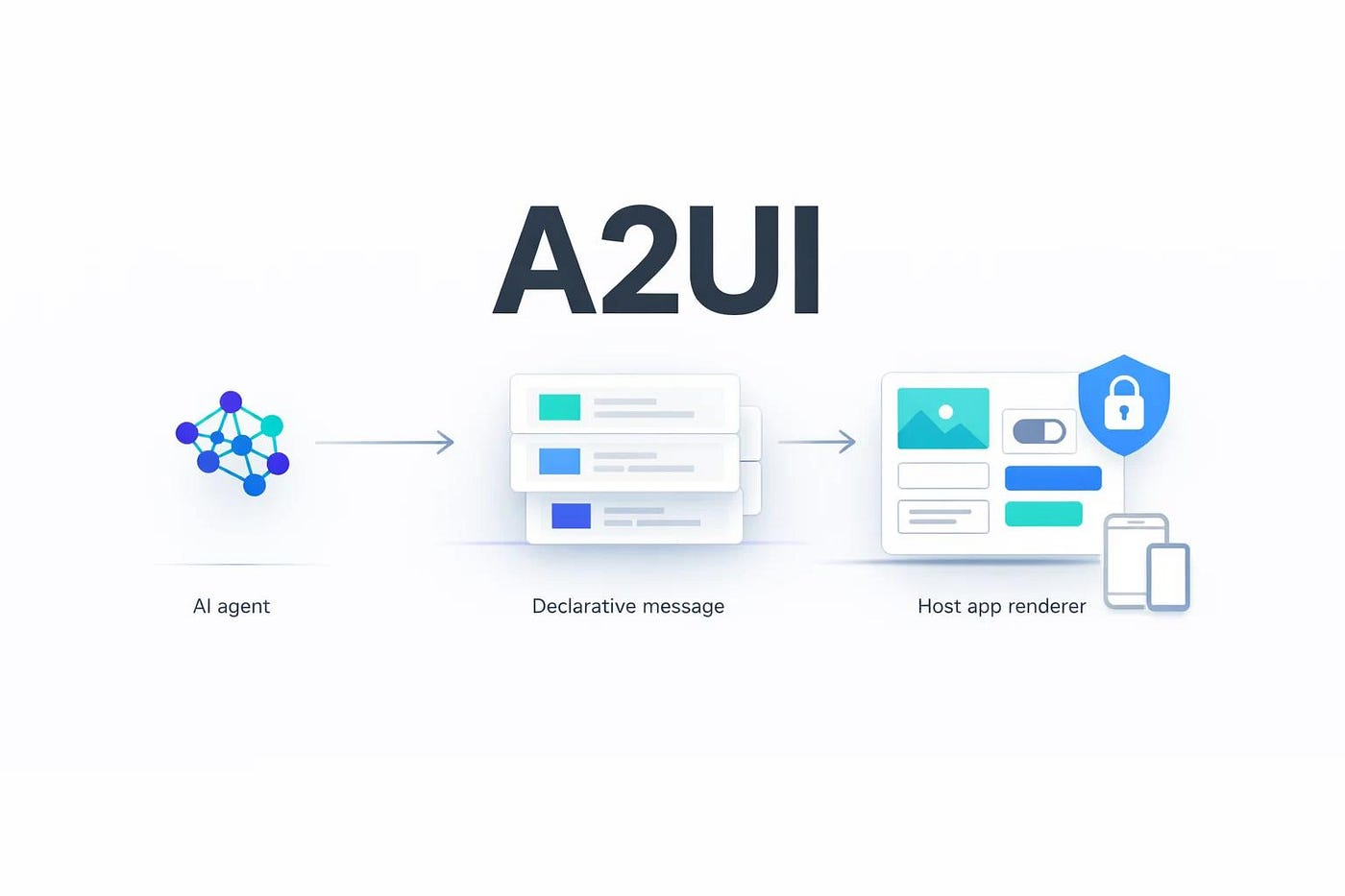
A2UI 동작 구조
전체 흐름은 단순하다.
- 사용자 요청
- 에이전트가 UI 구조 생성
- 클라이언트가 네이티브 UI로 렌더링
- 사용자 입력 발생
- 다시 에이전트로 전달
흐름을 코드처럼 보면
User → Agent → A2UI Message → Client Render → User Action → Agent
기존 방식 vs A2UI
| 구분 | 기존 방식 | A2UI |
|---|---|---|
| 출력 | 텍스트 | UI |
| 상호작용 | 대화 기반 | 인터페이스 기반 |
| 속도 | 느림 | 빠름 |
| 사용자 경험 | 반복 입력 | 즉시 선택 |
| 보안 | HTML/JS 위험 | 선언형 안전 구조 |
중요한 설계 포인트
1. 선언형 UI
A2UI는 코드가 아니다.
"이 버튼을 만들어라"
"이 폼을 보여줘라"
-> 명령이 아니라 설명
2. 클라이언트가 렌더링 책임을 가진다
에이전트는 UI를 직접 그리지 않는다.
- React → React 컴포넌트로 렌더링
- Flutter → Flutter 위젯으로 렌더링
-> 프레임워크 독립성 확보
3. 보안
- HTML 실행 없음
- JavaScript 실행 없음
- 허용된 컴포넌트만 사용
-> 원격 에이전트도 안전하게 UI 전달 가능
4. 스트리밍 기반 업데이트
A2UI는 UI를 한 번에 다 보내지 않는다.
- UI 구조 먼저
- 데이터는 나중에 업데이트
-> 불필요한 리렌더링 최소화
실제 활용 사례
1. 예약 시스템
- 날짜 선택기
- 시간 선택기
- 확인 버튼
2. 데이터 입력 폼
- 동적으로 필드 생성
- 조건에 따라 UI 변경
3. 대시보드
- 차트 자동 생성
- 상태 기반 UI 변경
4. 멀티 에이전트 환경
- 다른 서버의 에이전트가 UI 생성
- 클라이언트는 안전하게 렌더링
왜 이게 중요한가
지금까지 AI는 “답변”을 잘하는 게 중요했다.
앞으로는 달라진다.
-> "바로 실행 가능하게 만들어주는 능력"
한 단계 더 깊게 보면
A2UI는 단순한 UI 기술이 아니다.
이건 사실:
에이전트 간 협업을 위한 인터페이스 표준
이다.
한계와 현실
A2UI가 만능은 아니다.
- 전체 앱을 만드는 프레임워크는 아님
- 클라이언트 구현 필요
- 디자인 시스템 직접 관리해야 함
-> 즉,
"UI 생성"이 아니라 "UI 전달 프로토콜"
개인적인 생각
A2UI의 방향은 꽤 명확하다.
앞으로 AI는 이렇게 변할 가능성이 크다.
텍스트 AI → 인터페이스 생성 AI → 작업 수행 AI
지금은 아직 초기 단계지만
멀티 에이전트 시대가 오면 이런 구조는 필수가 된다.
결론
A2UI를 한 줄로 정리하면:
에이전트가 UI를 "그리는 것"이 아니라
UI를 "설명하고 전달하는 방식"
