최근 Anthropic이 Claude에 적용한 infinite-length conversations가 꽤 흥미로운 주제로 떠올랐다.
국내에서는 이것을 “무한 컨텍스트 윈도우”라고 부르는 경우가 많다.
말만 들으면 Claude가 이제 무제한으로 모든 대화를 기억하고, 아무리 긴 문서나 코드베이스도 한 번에 끝없이 처리할 수 있게 된 것처럼 느껴진다.
하지만 정확히 보면 조금 다르다.
Anthropic이 말하는 핵심은 진짜 무제한 토큰 창이 아니라,
컨텍스트가 한도에 가까워졌을 때 이전 내용을 요약하고 압축해서 대화를 계속 이어가는 구조에 가깝다.
즉, “컨텍스트 윈도우가 물리적으로 무한해졌다”기보다는
사용자 입장에서 긴 대화가 끊기지 않게 느껴지도록 만든 context management 기능이라고 보는 것이 정확하다.
먼저 컨텍스트 윈도우가 무엇인가
LLM에서 컨텍스트 윈도우는 모델이 한 번에 참고할 수 있는 정보의 범위다.
사용자가 입력한 프롬프트, 이전 대화, 첨부된 문서, 도구 호출 결과, 모델이 생성할 답변까지 모두 토큰 단위로 계산된다.
쉽게 말하면 컨텍스트 윈도우는 모델의 작업 메모리다.
사람이 책상 위에 자료를 펼쳐놓고 작업한다고 생각하면 된다.
책상이 넓을수록 더 많은 자료를 한 번에 볼 수 있다.
하지만 책상이 넓다고 해서 무조건 일을 잘하는 것은 아니다.
자료가 너무 많고 정리가 안 되어 있으면 오히려 중요한 내용을 놓칠 수 있다.
LLM도 비슷하다.
컨텍스트가 길어지면 더 많은 정보를 담을 수 있지만,
모델이 그 안에서 항상 모든 정보를 완벽하게 기억하고 활용하는 것은 아니다.
Anthropic이 말한 “무한”의 정체
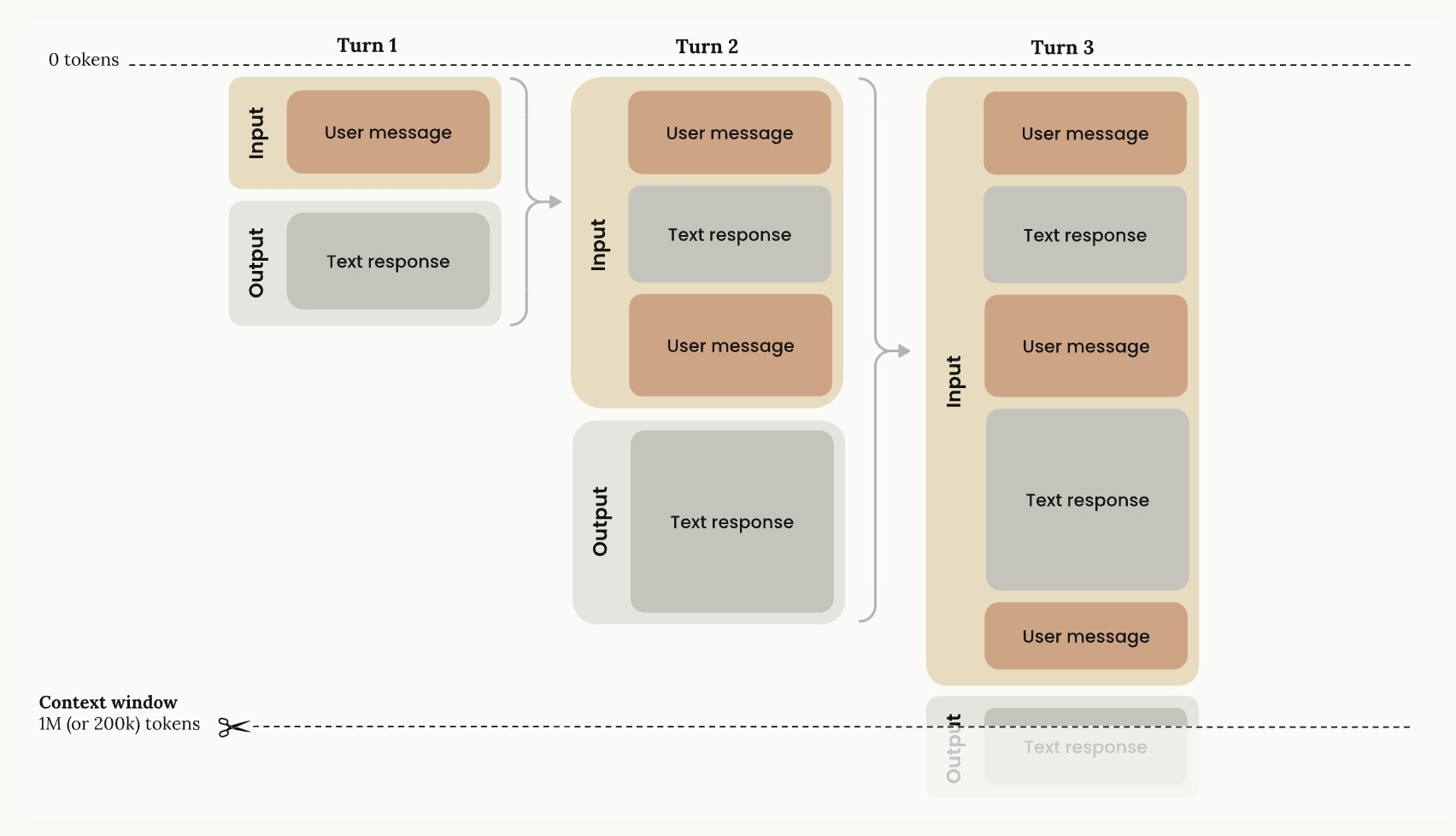
Anthropic의 공식 표현에 가까운 말은 infinite-length conversations with compaction이다.
여기서 중요한 단어는 infinite보다 compaction이다.
Compaction은 긴 대화가 컨텍스트 한도에 가까워졌을 때,
이전 대화 내용을 요약하고 압축해서 새 컨텍스트 안에 다시 넣는 방식이다.
흐름은 대략 이렇다.
- 사용자가 Claude와 긴 대화를 이어간다.
- 대화, 파일, 도구 호출 결과가 쌓이면서 컨텍스트 한도에 가까워진다.
- Claude가 오래된 대화 내용을 요약한다.
- 원문 전체 대신 요약본을 바탕으로 대화를 계속 이어간다.
- 사용자는 새 채팅을 만들지 않고도 계속 작업할 수 있다.
이 방식 덕분에 사용자는 예전처럼
“대화가 너무 길어졌으니 새 채팅을 시작하세요” 같은 흐름을 덜 겪게 된다.
그래서 체감상은 “무한 대화”처럼 느껴진다.
하지만 내부적으로는
모든 원문을 끝없이 그대로 들고 가는 것이 아니라, 중요한 내용을 압축해서 이어가는 것이다.
진짜 무한 컨텍스트는 아니다
이 부분이 가장 중요하다.
Anthropic의 무한 컨텍스트 윈도우는
말 그대로 무제한 토큰을 한 번에 넣을 수 있다는 뜻이 아니다.
여전히 모델마다 실제 컨텍스트 한도는 존재한다.
Claude API 문서 기준으로 일부 최신 모델은 1M 토큰 컨텍스트 윈도우를 지원하고, 다른 모델은 200K 토큰 컨텍스트 윈도우를 사용한다.
Claude 앱의 요금제나 기능에 따라서도 사용할 수 있는 길이와 사용량에는 제한이 있다.
즉, “무한”은 물리적인 토큰 제한이 사라졌다는 의미가 아니다.
더 정확한 표현은 다음과 같다.
고정된 컨텍스트 윈도우 안에서 오래된 내용을 자동으로 정리하고 압축해, 긴 작업을 계속 이어갈 수 있게 만드는 기능
그래서 이 기능은 “무한 컨텍스트 윈도우”라기보다는
자동 컨텍스트 관리 기능에 더 가깝다.
왜 이런 기능이 필요한가
LLM을 실제 업무에 써보면 컨텍스트 문제는 생각보다 빨리 온다.
간단한 질문 몇 개를 할 때는 문제가 없다.
하지만 다음과 같은 작업을 하면 컨텍스트는 금방 쌓인다.
- 큰 코드베이스 분석
- 긴 리서치 작업
- 여러 문서 비교
- 수십 번 이어지는 기획 수정
- 에이전트가 도구를 반복 호출하는 작업
- 긴 디버깅 세션
- 여러 파일을 읽고 수정하는 코딩 작업
특히 에이전트형 AI에서는 문제가 더 커진다.
에이전트는 단순히 답변만 하지 않는다.
파일을 읽고, 명령어를 실행하고, 검색하고, 결과를 다시 해석하고, 다음 행동을 결정한다.
이 과정에서 도구 호출 결과와 중간 작업 로그가 계속 쌓인다.
결국 컨텍스트가 가득 차면 두 가지 문제가 생긴다.
첫째, 더 이상 새 정보를 넣기 어렵다.
둘째, 너무 많은 정보 때문에 모델의 판단 품질이 떨어질 수 있다.
Anthropic이 context management를 강조하는 이유도 여기에 있다.
Compaction은 어떻게 동작하는가
Compaction은 말 그대로 압축이다.
하지만 단순히 글자 수를 줄이는 요약과는 조금 다르다.
좋은 compaction은 아래 내용을 보존해야 한다.
- 사용자가 원래 요청한 목표
- 지금까지 결정된 방향
- 중요한 제약 조건
- 해결되지 않은 문제
- 코드 수정 내역
- 아키텍처 결정
- 앞으로 해야 할 작업
- 실수하면 안 되는 주의사항
반대로 이런 내용은 줄이거나 버릴 수 있다.
- 오래된 도구 호출 결과
- 반복된 로그
- 이미 해결된 오류 메시지
- 중복된 설명
- 현재 작업과 관련 없는 대화
즉, compaction의 핵심은
무엇을 남기고 무엇을 버릴지 판단하는 것이다.
이 판단이 잘되면 긴 작업에서도 맥락이 유지된다.
반대로 이 판단이 잘못되면 중요한 정보가 요약 과정에서 사라질 수 있다.
그래서 compaction은 편리하지만 완벽한 마법은 아니다.
Memory와는 무엇이 다른가
Anthropic은 compaction뿐 아니라 memory tool도 함께 강조한다.
둘은 비슷해 보이지만 역할이 다르다.
Compaction
현재 대화가 너무 길어질 때,
이전 내용을 압축해서 같은 작업을 계속 이어가게 해준다.
즉, 목적은 현재 세션 유지다.
Memory
중요한 정보를 컨텍스트 윈도우 밖에 저장해두고,
나중에 다시 불러올 수 있게 한다.
즉, 목적은 장기 상태 유지다.
예를 들어 개발 에이전트를 생각해보자.
Compaction은 지금 진행 중인 디버깅 대화를 압축해 계속 이어가게 해준다.
Memory는 프로젝트의 아키텍처 결정, 자주 발생하는 버그 패턴, 사용자의 선호 같은 내용을 저장해 다음 세션에서도 참고하게 만든다.
정리하면 다음과 같다.
| 구분 | 역할 |
|---|---|
| Context window | 모델이 지금 바로 참고하는 작업 메모리 |
| Compaction | 길어진 대화를 요약해 계속 이어가는 압축 |
| Memory | 컨텍스트 밖에 중요한 정보를 저장해두는 장기 기억 |
| RAG | 필요한 문서 조각을 검색해서 컨텍스트에 넣는 방식 |
이 네 가지는 서로 경쟁하는 개념이 아니라,
긴 작업을 처리하기 위해 함께 쓰이는 구조다.
왜 이게 중요한 변화인가
이번 변화가 중요한 이유는 AI 사용 방식이 바뀌고 있기 때문이다.
예전에는 AI에게 질문하고 답을 받는 방식이 중심이었다.
하지만 지금은 점점 이런 식으로 바뀌고 있다.
- “이 코드베이스를 분석해줘”
- “이 버그를 끝까지 추적해줘”
- “이 문서들을 비교해서 보고서를 만들어줘”
- “내 프로젝트 구조를 이해하고 기능을 추가해줘”
- “여러 단계로 리서치하고 결과물을 만들어줘”
이런 작업은 한두 번의 응답으로 끝나지 않는다.
여러 단계가 이어지고, 중간 결정이 뒤에 영향을 주고, 이전 맥락이 계속 필요하다.
따라서 AI가 진짜 업무 도구가 되려면
단순히 답변을 잘하는 것보다 긴 작업을 끊기지 않고 유지하는 능력이 중요해진다.
Anthropic의 infinite-length conversations는 이 방향의 변화다.
장점
이 기능의 장점은 분명하다.
1. 긴 대화를 새로 시작하지 않아도 된다
이전에는 대화가 길어지면 새 채팅을 만들고, 이전 맥락을 다시 설명해야 했다.
이 과정이 꽤 번거로웠다.
Compaction이 적용되면 같은 대화 안에서 더 오래 작업을 이어갈 수 있다.
2. 장기 작업에 유리하다
리서치, 코딩, 문서 작성, 기획 수정처럼 여러 단계가 필요한 작업에서 유용하다.
이전 결정이 다음 작업에 영향을 주는 경우, 맥락 유지가 중요하기 때문이다.
3. 에이전트 작업에 적합하다
에이전트는 도구 호출 결과가 많이 쌓인다.
오래된 도구 결과를 그대로 계속 들고 있으면 컨텍스트를 낭비한다.
Compaction과 context editing은 오래된 도구 결과를 줄이고, 중요한 상태만 남기는 데 도움이 된다.
4. 사용자 경험이 좋아진다
사용자 입장에서는 컨텍스트 한도라는 기술적 제약을 덜 느끼게 된다.
긴 프로젝트를 하나의 대화 안에서 계속 이어갈 수 있다는 점은 체감상 큰 변화다.
한계도 분명하다
하지만 이 기능을 과장해서 보면 안 된다.
1. 요약은 손실 압축이다
Compaction은 원문 전체를 보존하는 것이 아니다.
요약 과정에서 덜 중요해 보였던 정보가 사라질 수 있다.
문제는 어떤 정보는 당시에는 중요해 보이지 않다가,
나중에 갑자기 중요해질 수 있다는 점이다.
2. 긴 컨텍스트가 항상 좋은 답을 만들지는 않는다
컨텍스트가 길어지면 모델이 더 많은 정보를 볼 수 있다.
하지만 정보가 너무 많으면 정확도나 recall이 떨어질 수 있다.
Anthropic 문서에서는 이런 현상을 context rot이라고 설명한다.
즉, 많은 정보를 넣는 것보다 중요한 정보를 잘 정리해서 넣는 것이 더 중요하다.
3. 비용과 사용량 문제는 여전히 남는다
긴 대화와 자동 context management는 사용량을 더 많이 소모할 수 있다.
사용자 입장에서는 “계속 이어진다”는 경험을 얻지만,
그만큼 사용량 제한이나 비용 관리 문제는 여전히 고려해야 한다.
4. 모든 작업에 필요한 기능은 아니다
간단한 질문, 짧은 요약, 단순 코드 수정에는 굳이 긴 컨텍스트가 필요 없다.
오히려 짧고 명확한 입력이 더 좋은 결과를 만들 수 있다.
개발자 입장에서 어떻게 활용해야 할까
개발자라면 이 기능을 “무한 기억”으로 보기보다
긴 작업을 안정적으로 유지하기 위한 도구로 보는 것이 좋다.
실제로는 아래처럼 쓰는 것이 좋다.
1. 중요한 결정은 명시적으로 남긴다
긴 작업 중간에 중요한 결정이 생기면 이렇게 적어두는 것이 좋다.
지금까지의 결정 사항을 정리해줘.
앞으로 유지해야 할 제약 조건과 TODO를 분리해서 써줘.이렇게 해두면 compaction 과정에서도 중요한 내용이 보존될 가능성이 높아진다.
2. 불필요한 로그를 무작정 넣지 않는다
테스트 로그, 빌드 로그, 에러 로그를 통째로 붙이는 것은 좋지 않다.
가능하면 핵심 부분만 넣는 것이 낫다.
전체 로그 중 실패 원인과 관련된 부분만 요약해서 분석해줘.
필요하면 추가로 어떤 로그가 필요한지 말해줘.3. 작업 단위를 나눈다
아무리 긴 대화가 가능해져도 한 대화에 모든 작업을 다 넣는 것은 좋지 않다.
예를 들어 다음처럼 나누는 편이 좋다.
- 인증 흐름 분석
- DB 스키마 분석
- API 라우팅 분석
- 테스트 전략 수립
- 실제 코드 수정
이렇게 나누면 모델이 더 명확하게 집중할 수 있다.
4. 요약본을 검증한다
Compaction 후에는 모델이 이전 내용을 잘 기억하고 있는지 확인하는 과정이 필요하다.
지금까지의 핵심 맥락을 요약해줘.
놓친 제약 조건이나 잘못 이해한 부분이 있는지 확인할게.긴 작업일수록 이런 체크포인트가 중요하다.
기존 RAG와 비교하면 무엇이 다른가
RAG는 필요한 문서를 검색해서 현재 질문에 맞는 부분만 컨텍스트에 넣는 방식이다.
반면 compaction은 현재까지 진행된 대화와 작업 내용을 압축해서 이어가는 방식이다.
둘은 목적이 다르다.
| 방식 | 목적 |
|---|---|
| RAG | 외부 문서에서 관련 정보를 찾아 넣기 |
| Compaction | 길어진 대화 자체를 압축해 이어가기 |
| Memory | 세션 밖의 장기 정보를 저장하고 다시 불러오기 |
| Context editing | 불필요한 도구 결과나 오래된 내용을 제거하기 |
실제 에이전트 시스템에서는 이 방식들이 함께 쓰일 가능성이 높다.
예를 들어 코드 에이전트는 이렇게 동작할 수 있다.
- RAG로 관련 파일이나 문서를 찾는다.
- 컨텍스트 윈도우에 필요한 내용만 넣는다.
- 작업이 길어지면 compaction으로 대화를 압축한다.
- 중요한 결정은 memory에 저장한다.
- 오래된 도구 결과는 context editing으로 제거한다.
이 구조가 잘 작동하면 AI는 단기 기억, 장기 기억, 검색, 압축을 조합해서 더 긴 작업을 처리할 수 있다.
“무한 컨텍스트”라는 표현이 위험한 이유
마케팅적으로 “무한 컨텍스트”라는 표현은 강력하다.
하지만 개발자 입장에서는 조심해서 받아들여야 한다.
이 표현을 그대로 믿으면 이런 오해가 생길 수 있다.
- 이제 문서를 무한히 넣어도 된다
- 모델이 모든 이전 대화를 완벽히 기억한다
- 요약 과정에서 정보 손실이 없다
- 컨텍스트 관리가 더 이상 필요 없다
- 긴 대화일수록 무조건 성능이 좋아진다
모두 정확하지 않다.
오히려 반대로 봐야 한다.
컨텍스트가 길어질수록
무엇을 남기고, 무엇을 지우고, 무엇을 외부 메모리에 저장할지가 더 중요해진다.
무한 컨텍스트 시대가 온 것이 아니라,
컨텍스트 엔지니어링이 더 중요해진 시대가 온 것이다.
이 변화가 AI 에이전트에 주는 의미
AI 에이전트는 긴 시간 동안 상태를 유지해야 한다.
예를 들어 코딩 에이전트가 큰 기능을 구현한다고 해보자.
에이전트는 다음 내용을 계속 기억해야 한다.
- 사용자의 원래 요구사항
- 현재 코드베이스 구조
- 이미 수정한 파일
- 실패한 접근 방식
- 통과한 테스트
- 남은 TODO
- 사용자가 싫어하는 구현 방식
- 프로젝트의 스타일과 규칙
이걸 전부 원문 그대로 컨텍스트에 넣으면 금방 한도에 닿는다.
그래서 앞으로의 에이전트는 단순히 모델 성능만 좋아져서는 부족하다.
좋은 에이전트는 다음 능력을 가져야 한다.
- 필요한 정보만 컨텍스트에 넣기
- 오래된 정보 정리하기
- 중요한 결정은 메모리에 저장하기
- 작업 단계마다 요약하기
- 하위 에이전트로 작업 분리하기
- 최종 결과를 검증하기
Anthropic의 compaction과 memory는 이 방향을 향한 중요한 기능이다.
정리
Anthropic이 발표한 infinite-length conversations는 꽤 중요한 변화다.
하지만 이것을 “진짜 무한 컨텍스트 윈도우”라고 이해하면 안 된다.
정확히는 다음에 가깝다.
컨텍스트 한도에 가까워질 때 이전 대화를 요약하고 압축해서, 긴 작업을 계속 이어갈 수 있게 만드는 자동 컨텍스트 관리 기능
이 기능은 긴 리서치, 코딩, 문서 작업, 에이전트 워크플로에서 큰 도움이 된다.
하지만 동시에 한계도 있다.
- 실제 토큰 한도는 여전히 존재한다
- 요약 과정에서 정보 손실이 생길 수 있다
- 긴 컨텍스트는 context rot을 만들 수 있다
- 비용과 사용량 제한도 사라지지 않는다
- 중요한 정보는 사용자가 명시적으로 정리해야 한다
결국 핵심은 이것이다.
미래의 AI 생산성은 “컨텍스트를 얼마나 많이 넣을 수 있는가”가 아니라
“필요한 컨텍스트를 얼마나 잘 관리하는가”에 달려 있다.
Anthropic의 무한 컨텍스트 윈도우는
무제한 기억 장치라기보다는,
AI가 더 긴 작업을 버틸 수 있게 만드는 컨텍스트 관리 시스템에 가깝다.
그리고 이 변화는 앞으로 AI 에이전트를 설계할 때
context engineering이 얼마나 중요한 분야가 될지를 보여준다.
