요즘 AI를 이야기할 때 거의 빠지지 않는 단어가 있다.
Transformer
ChatGPT, BERT, GPT 계열 모델, 번역 모델, 요약 모델, 이미지 생성 모델까지.
현대 AI의 많은 흐름은 Transformer 위에서 움직인다.
그리고 그 Transformer를 세상에 본격적으로 알린 논문이 바로 2017년에 공개된 Attention Is All You Need다.
이 논문은 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin이 작성했다.
핵심 주장은 제목 그대로다.
Attention Is All You Need
다시 말하면,
RNN도 필요 없고, CNN도 필요 없다. Attention만으로 충분하다.
이 말은 당시 자연어 처리 흐름을 완전히 바꿨다.
기존 방식의 문제
Transformer가 나오기 전, 자연어 처리에서 강력한 모델들은 대부분 RNN, LSTM, GRU 같은 구조를 사용했다.
이 모델들의 기본 방식은 문장을 순서대로 읽는 것이다.
예를 들어 이런 문장이 있다고 해보자.
I arrived at the bank after crossing the river.여기서 bank는 은행일 수도 있고, 강둑일 수도 있다.
하지만 뒤에 river가 나오기 때문에 여기서는 강둑에 가까운 의미다.
문제는 RNN 계열 모델이 문장을 앞에서부터 차례대로 처리한다는 점이다.
I → arrived → at → the → bank → after → crossing → the → river이렇게 처리하면 멀리 떨어진 단어 사이의 관계를 이해하기 어렵다.
bank의 의미를 제대로 알기 위해서는 뒤쪽의 river까지 봐야 하는데, RNN은 중간 단어들을 순서대로 거쳐야 한다.
문장이 길어질수록 이런 장기 의존성 문제가 더 커진다.
또 하나의 문제는 병렬 처리가 어렵다는 점이다.
RNN은 이전 단어의 계산 결과가 있어야 다음 단어를 계산할 수 있다.
1번째 단어 처리
2번째 단어 처리
3번째 단어 처리
...즉, 순서대로 계산해야 한다.
GPU는 병렬 계산에 강한데, RNN 구조는 그 장점을 제대로 활용하기 어렵다.
Transformer의 핵심 아이디어
Transformer는 이 문제를 다른 방식으로 풀었다.
문장을 꼭 순서대로 읽을 필요가 없다고 본 것이다.
대신 각 단어가 문장 안의 다른 모든 단어를 직접 바라보게 만들었다.
각 단어 ↔ 모든 단어이 구조의 핵심이 바로 Self-Attention이다.
Self-Attention은 간단히 말하면 이런 질문을 던진다.
이 단어를 이해하려면 문장 안의 어떤 단어를 봐야 할까?
예를 들어 bank라는 단어를 이해하려면 river가 중요하다.
Self-Attention은 bank와 river의 관계를 직접 계산한다.
중간 단어들을 하나씩 거칠 필요가 없다.
이게 Transformer의 가장 중요한 변화다.
Attention이란 무엇인가
Attention은 이름 그대로 “어디에 집중할 것인가”를 정하는 방식이다.
사람도 문장을 읽을 때 모든 단어를 똑같이 중요하게 보지 않는다.
예를 들어 이런 문장을 보자.
The animal did not cross the street because it was too tired.여기서 it이 무엇을 가리키는지 이해하려면 animal을 봐야 한다.
모델 입장에서는 이런 질문이 필요하다.
it을 이해하려면 어떤 단어가 중요하지?Attention은 이 중요도를 숫자로 계산한다.
중요한 단어에는 높은 가중치를 주고, 덜 중요한 단어에는 낮은 가중치를 준다.
결국 모델은 모든 단어를 보되, 더 중요한 단어에 더 집중한다.
Query, Key, Value
Transformer의 attention을 이해하려면 세 가지 개념이 필요하다.
Query
Key
Value처음 보면 어렵게 느껴지지만, 개념은 생각보다 단순하다.
Query
Query는 “내가 찾고 싶은 정보”다.
예를 들어 bank라는 단어가 있다면, 이 단어는 이렇게 묻는다.
내 의미를 이해하려면 어떤 정보가 필요하지?이 질문이 Query다.
Key
Key는 각 단어가 가진 정보의 특징이다.
문장 안의 다른 단어들은 각자 Key를 가지고 있다.
모델은 Query와 Key를 비교해서 두 단어가 얼마나 관련 있는지 계산한다.
Value
Value는 실제로 가져올 정보다.
관련도가 높은 단어의 Value는 더 많이 반영된다.
관련도가 낮은 단어의 Value는 덜 반영된다.
정리하면 이렇게 볼 수 있다.
Query: 내가 찾는 것
Key: 비교할 기준
Value: 실제로 가져올 정보Attention은 Query와 Key를 비교해서 중요도를 계산하고, 그 중요도에 따라 Value를 섞는 방식이다.
Scaled Dot-Product Attention
논문에서 사용한 attention 방식은 Scaled Dot-Product Attention이다.
수식은 다음과 같다.
Attention(Q, K, V) = softmax(QKᵀ / √dₖ) V수식이 복잡해 보이지만 흐름은 단순하다.
- Query와 Key를 곱해서 관련도를 계산한다.
- 값이 너무 커지지 않도록 √dₖ로 나눈다.
- softmax를 적용해서 가중치로 만든다.
- 그 가중치로 Value를 섞는다.
여기서 중요한 부분은 √dₖ로 나누는 것이다.
벡터 차원이 커질수록 dot product 값이 너무 커질 수 있다.
값이 너무 커지면 softmax가 극단적으로 치우치고, 학습이 불안정해질 수 있다.
그래서 scaling을 넣어 값을 조정한다.
Multi-Head Attention
Transformer는 attention을 한 번만 하지 않는다.
여러 attention을 동시에 수행한다.
이걸 Multi-Head Attention이라고 한다.
Head 1: 문법 관계를 볼 수 있음
Head 2: 의미 관계를 볼 수 있음
Head 3: 위치 관계를 볼 수 있음
Head 4: 다른 패턴을 볼 수 있음물론 실제로 각 head가 항상 이렇게 명확하게 역할을 나눈다고 단정할 수는 없다.
하지만 핵심은 하나다.
하나의 관점으로만 보지 않고, 여러 관점에서 동시에 본다.
단어 사이의 관계는 하나의 기준으로만 설명되지 않는다.
어떤 단어는 문법적으로 중요하고, 어떤 단어는 의미적으로 중요하고, 어떤 단어는 위치상 중요하다.
Multi-Head Attention은 이런 다양한 관계를 병렬로 학습할 수 있게 만든다.
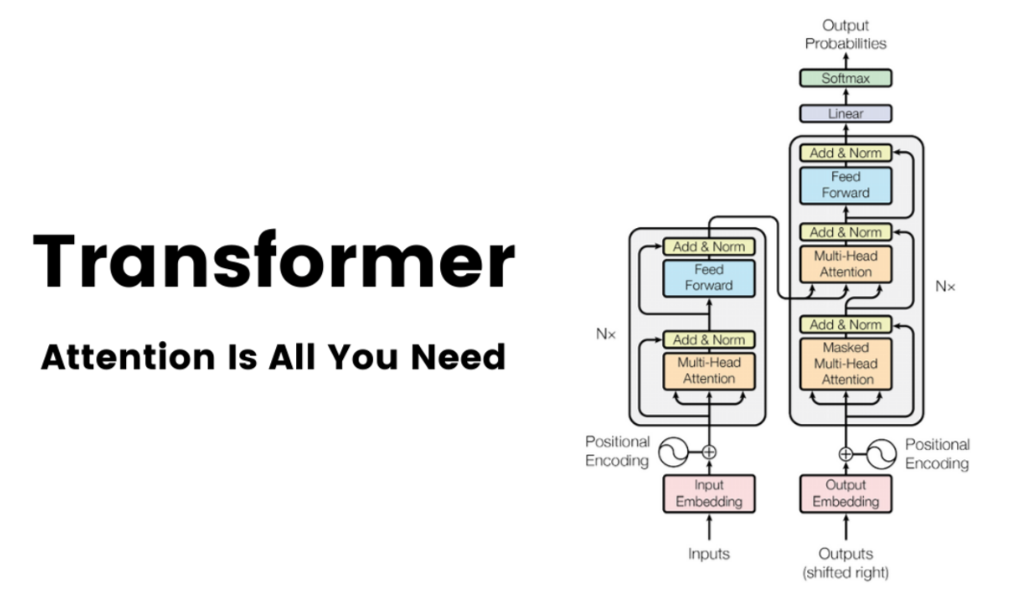
Transformer의 전체 구조
Transformer는 크게 두 부분으로 나뉜다.
Encoder
Decoder기계 번역을 기준으로 보면,
입력 문장 → Encoder → 의미 표현 → Decoder → 출력 문장Encoder는 입력 문장을 이해한다.
Decoder는 Encoder가 만든 표현을 바탕으로 출력 문장을 생성한다.
Encoder 구조
Encoder는 여러 개의 동일한 layer를 쌓은 구조다.
각 Encoder layer는 크게 두 부분으로 구성된다.
Multi-Head Self-Attention
Feed Forward Network먼저 Self-Attention을 통해 각 단어가 문장 안의 다른 단어들과 어떤 관계를 가지는지 계산한다.
그다음 Feed Forward Network를 통해 각 위치의 표현을 더 정교하게 변환한다.
여기에 residual connection과 layer normalization이 붙는다.
구조를 단순하게 보면 다음과 같다.
입력
↓
Multi-Head Self-Attention
↓
Add & Norm
↓
Feed Forward Network
↓
Add & Norm
↓
출력Encoder는 이 과정을 반복하면서 문장 전체의 의미를 점점 더 잘 표현한다.
Decoder 구조
Decoder도 여러 개의 layer를 쌓은 구조다.
다만 Encoder보다 조금 더 복잡하다.
Decoder layer는 크게 세 부분으로 구성된다.
Masked Multi-Head Self-Attention
Encoder-Decoder Attention
Feed Forward Network여기서 중요한 것은 Masked Self-Attention이다.
Decoder는 문장을 생성할 때 미래 단어를 보면 안 된다.
예를 들어 번역 결과를 생성하는 중이라고 해보자.
I am going to다음 단어를 예측해야 하는데, 정답 문장의 뒤쪽 단어를 미리 보면 안 된다.
그건 시험을 보면서 답지를 보는 것과 같다.
그래서 Transformer는 Decoder에서 미래 위치를 가린다.
현재 위치 이후의 단어는 볼 수 없음이걸 masking이라고 한다.
Positional Encoding이 필요한 이유
Transformer는 RNN이 아니다.
그래서 구조 자체만 보면 단어의 순서를 알 수 없다.
하지만 문장에서 순서는 매우 중요하다.
예를 들어 다음 두 문장을 보자.
나는 밥을 먹었다.
밥이 나를 먹었다.사용된 단어는 비슷하지만 의미는 완전히 다르다.
순서가 바뀌었기 때문이다.
Transformer는 순서 정보를 직접 처리하지 않기 때문에, 입력 embedding에 위치 정보를 더해줘야 한다.
이게 Positional Encoding이다.
논문에서는 sine과 cosine 함수를 사용해 위치 정보를 만든다.
단어 embedding에 positional encoding을 더하면, 모델은 각 단어가 문장 안에서 어느 위치에 있는지 알 수 있다.
정리하면 이렇다.
Token Embedding + Positional Encoding = Transformer 입력왜 Transformer가 빨랐는가
Transformer의 강점은 성능만이 아니다.
학습이 빠르다는 점도 중요하다.
RNN은 순서대로 계산해야 한다.
1번째 단어 → 2번째 단어 → 3번째 단어 → ...하지만 Transformer는 문장 안의 모든 단어 관계를 한 번에 계산할 수 있다.
모든 단어 관계를 병렬 계산이 구조는 GPU와 잘 맞는다.
그래서 Transformer는 기존 RNN 기반 모델보다 병렬화에 유리하다.
논문에서도 Transformer가 더 병렬화하기 쉽고, 학습 시간 측면에서도 효율적이라고 설명한다.
논문의 성능 결과
논문은 WMT 2014 기계 번역 작업에서 Transformer를 평가했다.
대표적인 결과는 다음과 같다.
English → German: 28.4 BLEU
English → French: 41.8 BLEU이 결과가 중요한 이유는 단순히 점수가 높았기 때문만은 아니다.
더 중요한 건 구조적 변화다.
기존처럼 RNN이나 CNN에 의존하지 않고도 좋은 성능을 냈다.
즉, 이 논문은 다음을 보여줬다.
Attention만으로도 강력한 sequence model을 만들 수 있다.
이 논문이 바꾼 것
Attention Is All You Need의 진짜 의미는 번역 성능 향상에만 있지 않다.
이 논문은 자연어 처리의 기본 구조를 바꿨다.
이전에는 문장을 순서대로 처리하는 방식이 자연스럽다고 여겨졌다.
문장은 순서가 있으니 모델도 순서대로 읽어야 한다고 생각한 것이다.
Transformer는 이 생각을 바꿨다.
순서대로 읽기보다, 관계를 직접 보자.각 토큰이 다른 모든 토큰과 직접 관계를 맺게 하자.
이 관점이 이후 BERT, GPT 같은 모델로 이어졌다.
단점도 있다
Transformer가 완벽한 구조는 아니다.
가장 큰 문제 중 하나는 attention의 계산량이다.
Self-Attention은 모든 토큰이 모든 토큰을 본다.
토큰 수가 n개라면 관계를 계산해야 하는 쌍은 대략 n²개가 된다.
Attention 계산량 ≈ O(n²)짧은 문장에서는 괜찮지만, 긴 문서나 긴 코드, 긴 영상, 긴 오디오를 다룰 때는 부담이 커진다.
그래서 이후에는 긴 context를 더 효율적으로 다루기 위한 다양한 연구가 이어졌다.
예를 들면 sparse attention, linear attention, efficient transformer 계열 연구들이 있다.
개인적인 생각
이 논문이 대단한 이유는 아이디어가 복잡해서가 아니다.
오히려 핵심은 매우 선명하다.
중요한 정보에 집중하면 된다.
RNN은 순서대로 기억하려 했다.
CNN은 주변 패턴을 쌓아 올리려 했다.
Transformer는 이렇게 물었다.
지금 이 토큰이 봐야 할 토큰은 무엇인가?이 질문 하나가 모델 구조를 바꿨다.
그리고 그 결과가 지금의 LLM 시대까지 이어졌다.
한 줄 정리
Attention Is All You Need는 RNN과 CNN 중심의 자연어 처리 흐름을 attention 중심으로 바꾼 논문이다.
더 짧게 말하면 이렇게 정리할 수 있다.
Transformer는 “순서대로 읽기”보다 “관계를 직접 보기”가 더 강력할 수 있다는 걸 보여준 구조다.
이 논문 이후 AI는 더 커졌고, 더 빨라졌고, 더 넓은 문제로 확장됐다.
그래서 이 논문은 단순한 NLP 논문이 아니라, 현대 생성형 AI의 출발점 중 하나로 봐도 된다.
