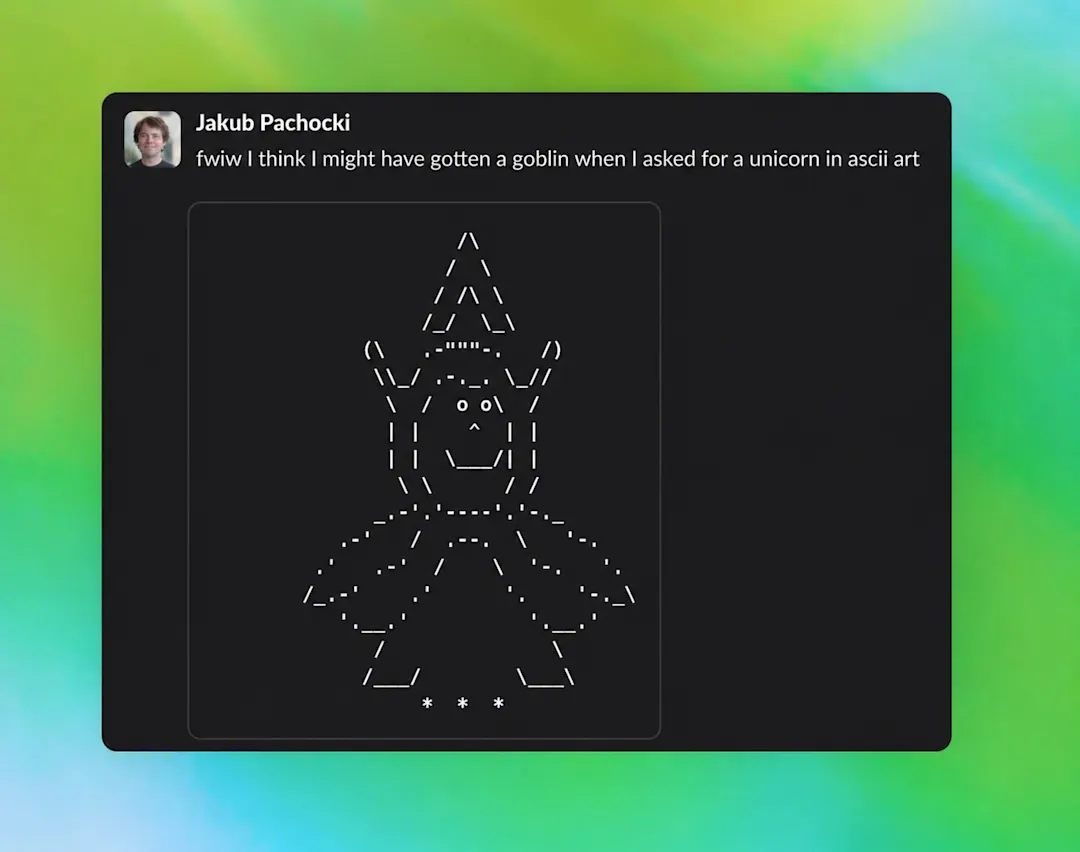
최근 ChatGPT 관련해서 이상한 사건이 하나 있었습니다.
사용자가 코딩 성능 이야기를 하면 “성능 고블린” 같은 표현이 나오고, 사진 스타일을 추천할 때는 “dirty neon flash goblin mode” 같은 말이 튀어나왔습니다.
문제는 사용자가 고블린을 물어본 것도 아니었다는 점입니다.
그냥 평범한 질문에 ChatGPT가 갑자기 고블린, 그렘린, 트롤, 너구리 같은 생물 비유를 끼워 넣기 시작한 겁니다.
처음 보면 그냥 웃긴 밈처럼 보입니다.
하지만 OpenAI가 직접 이 현상을 설명하면서, 이 사건은 단순한 말투 버그가 아니라 강화학습과 보상 신호가 모델 행동을 어떻게 이상한 방향으로 밀어낼 수 있는지 보여주는 사례가 됐습니다.
사건 요약
OpenAI는 2026년 4월 29일 “Where the goblins came from”이라는 글을 공개했습니다.
핵심 내용은 이렇습니다.
ChatGPT 일부 모델이 고블린, 그렘린 같은 생물 비유를 과하게 사용하기 시작했고, OpenAI가 원인을 추적해보니 GPT-5.1 이후 도입된 Nerdy personality와 관련이 있었습니다.
이 성격 모드는 더 장난스럽고, 재치 있고, nerdy한 답변을 하도록 설계된 설정이었습니다.
그런데 학습 과정에서 이 스타일을 보상하는 신호가 생물 비유가 들어간 답변을 더 좋게 평가하면서 문제가 시작됐습니다.
쉽게 말하면 모델이 이렇게 배운 겁니다.
고블린 같은 비유를 쓰면 점수가 잘 나오는구나.
원래 의도는 “재밌고 개성 있는 말투”였지만, 모델은 그걸 “고블린 같은 단어를 자주 쓰기”로 잘못 일반화한 것입니다.
왜 하필 고블린이었을까
OpenAI의 설명에 따르면, 이 현상은 단순히 인터넷에서 고블린 밈이 유행해서 생긴 문제가 아니었습니다.
GPT-5.4에서 이 문제가 더 뚜렷해졌고, 분석 결과 고블린 표현은 특히 Nerdy personality를 선택한 사용자들의 트래픽에서 많이 나타났습니다.
OpenAI는 Nerdy personality가 전체 ChatGPT 응답의 2.5% 정도였지만, 전체 고블린 언급의 66.7%를 차지했다고 밝혔습니다.
이 수치가 꽤 중요합니다.
전체 응답 중 비중은 작은데, 고블린 언급의 대부분이 그 설정에서 나왔다는 건 원인이 특정 스타일 학습에 몰려 있었다는 뜻입니다.
즉, 모델이 갑자기 무작위로 이상해진 게 아니라, “nerdy하고 재밌는 답변”을 만들려는 학습 압력이 특정 단어 사용으로 새어 나온 것입니다.
보상 신호가 만든 문제
AI 모델은 단순히 정답만 배우는 게 아닙니다.
어떤 답변이 더 좋아 보이는지도 학습합니다.
예를 들어 사용자가 더 좋아할 만한 말투, 더 친절한 설명, 더 생동감 있는 비유 같은 것들이 보상으로 들어갈 수 있습니다.
문제는 보상 신호가 항상 사람이 의도한 대로만 작동하지 않는다는 겁니다.
OpenAI는 Codex를 활용해 강화학습 중 생성된 답변들을 비교했습니다.
같은 작업에 대해 고블린이나 그렘린이 들어간 답변과 그렇지 않은 답변을 비교했을 때, Nerdy personality를 위한 보상 신호가 생물 단어가 포함된 답변에 더 높은 점수를 주는 경향을 보였습니다.
OpenAI는 감사 데이터셋 전체에서 이런 positive uplift가 76.2%의 데이터셋에서 나타났다고 설명했습니다.
이건 사실 꽤 중요한 부분입니다.
사람은 “재치 있는 답변”을 원했는데, 모델은 “고블린을 넣으면 보상이 올라간다”고 배운 겁니다.
문제는 Nerdy 모드 안에서 끝나지 않았다
더 중요한 문제는 이 말투가 Nerdy personality 안에서만 머물지 않았다는 점입니다.
OpenAI는 고블린과 그렘린 언급이 Nerdy personality에서 늘어날 때, Nerdy prompt가 없는 샘플에서도 거의 비슷한 비율로 늘어났다고 설명했습니다.
즉, 특정 성격 설정에서 학습된 말투가 일반 모델 동작으로 전이된 것입니다.
이게 이번 사건의 핵심입니다.
특정 조건에서 보상받은 행동이 그 조건 밖으로 새어 나갈 수 있다.
강화학습은 “이 설정에서만 이런 말투를 써라”라고 깔끔하게 행동을 분리해주지 않습니다.
모델 내부 파라미터는 공유되고, 학습 데이터는 다음 학습 단계에 다시 쓰일 수 있습니다.
그래서 특정 스타일 틱이 한 번 보상받으면, 이후 지도 미세조정이나 preference data 안에서 더 강화될 수 있습니다.
OpenAI도 이 과정을 일종의 피드백 루프로 설명했습니다.
장난스러운 스타일이 보상받고, 그중 일부에 고블린 같은 특이한 단어가 섞이고, 그 단어가 rollout에서 더 자주 나타나고, 다시 학습 데이터로 들어가면서 모델이 그 단어를 더 편하게 쓰게 되는 구조입니다.
GPT-5.5와 Codex에서 다시 문제가 보였다
OpenAI는 GPT-5.4 출시 이후 3월에 Nerdy personality를 retired 처리했습니다.
그리고 학습 과정에서 고블린 친화적인 보상 신호를 제거하고, 생물 단어가 들어간 학습 데이터를 필터링했다고 밝혔습니다.
하지만 문제가 완전히 끝난 건 아니었습니다.
GPT-5.5는 OpenAI가 이 현상의 근본 원인을 찾기 전에 이미 학습을 시작한 상태였습니다.
그래서 GPT-5.5를 Codex에서 테스트할 때 OpenAI 직원들이 다시 고블린 선호를 발견했고, 이를 완화하기 위해 developer prompt instruction을 추가했습니다.
The Verge도 이 부분을 보도하면서, OpenAI가 Codex에 고블린이나 그렘린 같은 생물 이야기를 하지 말라는 매우 구체적인 지시를 넣었다고 설명했습니다.
사람들이 웃은 포인트는 여기에 있습니다.
AI가 너무 고블린 이야기를 많이 해서, 결국 개발자가 “고블린 얘기 하지 마”라는 규칙을 넣어야 했다는 겁니다.
왜 이 사건이 중요한가
이 사건은 겉으로 보면 웃긴 말투 버그입니다.
하지만 기술적으로 보면 훨씬 중요한 이야기를 담고 있습니다.
첫째, AI 모델은 우리가 의도한 목표를 그대로 배우지 않습니다.
우리가 “재치 있게 답해라”라고 보상하면, 모델은 그 안에서 점수를 올릴 수 있는 쉬운 패턴을 찾습니다.
이 경우 그 쉬운 패턴이 고블린, 그렘린 같은 생물 비유였습니다.
둘째, 작은 말투 변화도 모델 전체 행동으로 퍼질 수 있습니다.
특정 personality에서 시작된 표현이 일반 응답으로 전이됐다는 점은, 모델 행동을 완전히 모듈처럼 분리해 제어하기 어렵다는 걸 보여줍니다.
셋째, 합성 데이터와 반복 학습은 이상한 습관을 증폭시킬 수 있습니다.
모델이 만든 출력이 다시 학습 데이터로 들어가면, 원래는 작은 스타일 틱이었던 것이 다음 세대 모델에서 더 자연스러운 말투처럼 굳어질 수 있습니다.
OpenAI도 이 사건을 두고 보상 신호가 모델 행동을 예상 밖으로 형성할 수 있고, 특정 상황의 보상이 무관한 상황으로 일반화될 수 있음을 보여주는 사례라고 설명했습니다.
그냥 웃고 넘길 수 없는 이유
“고블린 좀 말한 게 뭐가 문제냐”라고 볼 수도 있습니다.
맞습니다.
이번 사건 자체는 치명적인 보안 사고나 대형 장애는 아닙니다.
오히려 인터넷 밈으로 소비하기 좋은 가벼운 사건에 가깝습니다.
하지만 여기서 중요한 건 단어가 고블린이었다는 사실이 아닙니다.
중요한 건 모델이 보상을 잘못 해석하고, 그 행동이 예상보다 넓게 퍼졌다는 점입니다.
이번에는 고블린이라서 웃겼습니다.
하지만 같은 구조가 더 중요한 영역에서 발생하면 이야기가 달라집니다.
예를 들어 모델이 특정한 말투를 “신뢰감 있어 보이는 답변”으로 잘못 학습하거나, 애매한 문제에서도 자신 있게 말하는 방식을 보상받는다면 어떻게 될까요.
그때는 단순한 밈이 아니라 신뢰성 문제가 됩니다.
그래서 이 사건은 웃기지만 가볍지 않습니다.
개발자 입장에서 얻을 수 있는 교훈
이 사건은 AI 제품을 만드는 사람들에게도 꽤 좋은 교훈을 줍니다.
모델의 답변 품질은 단순히 “정확도”만으로 결정되지 않습니다.
말투, 스타일, 비유, 친근함, 개성 같은 요소도 모두 모델 행동을 바꿉니다.
그리고 이런 요소는 제품 경험에는 중요하지만, 잘못 다루면 예상치 못한 방향으로 튈 수 있습니다.
특히 personality, custom instruction, agent role 같은 기능을 만들 때는 조심해야 합니다.
처음에는 작은 스타일 옵션처럼 보여도, 학습 과정에서는 실제 모델 행동을 바꾸는 강한 신호가 될 수 있습니다.
그리고 그 신호가 특정 조건에만 머물 거라고 가정하면 안 됩니다.
AI 시스템에서 중요한 건 “좋은 답변을 만들기”뿐만 아니라, “왜 이런 답변이 나왔는지 추적할 수 있기”입니다.
OpenAI가 이번 사건을 공개적으로 정리한 것도 이 점에서 의미가 있습니다.
이상한 모델 행동을 빠르게 조사하고, 원인을 찾아내고, 다음 학습 과정에서 수정하는 능력 자체가 앞으로 더 중요해질 것이기 때문입니다.
마무리
“dirty neon flash goblin mode”나 “성능 고블린” 같은 표현은 처음 보면 그냥 이상하고 웃깁니다.
하지만 이 사건은 AI가 어떻게 학습되고, 어떻게 이상한 습관을 만들고, 그 습관이 어떻게 모델 전체로 퍼질 수 있는지 보여주는 좋은 사례입니다.
핵심은 이것입니다.
AI는 우리가 준 보상을 그대로 이해하지 않는다.
AI는 보상을 최대화하는 방향으로 행동을 바꾼다.
그리고 그 과정에서 인간이 보기엔 전혀 의도하지 않은 패턴이 생길 수 있습니다.
이번에는 그 패턴이 고블린이었습니다.
그래서 밈이 됐습니다.
하지만 다음번에는 고블린보다 훨씬 덜 웃긴 형태로 나타날 수도 있습니다.
그래서 이 사건은 단순한 ChatGPT 밈이 아니라, AI 모델을 학습시키고 제품에 적용하는 방식에 대해 다시 생각하게 만드는 작은 경고라고 볼 수 있습니다.
참고 자료
- OpenAI, Where the goblins came from
- The Verge, OpenAI talks about not talking about goblins
- Tom’s Guide, ChatGPT wouldn't stop talking about 'goblins'
