
📌 Collection Framework
자료구조를 자바에서 구현하여 제공하는 클래스들의 모음 (API)
java.util패키지에서 제공Set,List,Map인터페이스 계열로 구분 ➡️ 각 인터페이스의 구현체 클래스를 사용하여 데이터 관리toString()메서드가 오버라이딩 되어있음.
💡 Set 계열
✅ HashSet, TreeSet
📒 HashSet
인덱스를 사용하지 않고, 중복 데이터를 허용하지 않음
HashSet<> set1 = new HashSet<>();
Set<> set2 = new HashSet<>(); // HashSet -> Set : 업캐스팅📝 메서드
add(): 요소 저장여부 리턴 ➕addAll(Collection c): 컬렉션 복사toString(): 모든 요소 출력 (생략 가능)boolean isEmpty(): 객체가 비어있는지 여부int size(): 저장된 요소 개수
System.out.println("set 객체가 비어있는가? " + set.isEmpty()); // 비어있으면 true
System.out.println("set 객체에 저장된 요소 개수? " + set.size());
// 제네릭 타입을 지정하지 않았으므로, 모든 타입 저장 가능
System.out.println();
set.add(5);
set.add("오");
System.out.println("set 객체가 비어있는가? " + set.isEmpty());
System.out.println("set 객체에 저장된 요소 개수? " + set.size());
System.out.println("set 객체의 모든 요소 출력 : " + set);
boolean contains(Object o): 객체 내에 요소 o 포함 여부boolean remove(Object o): 요소 o 삭제 및 결과 리턴Object[] toArray(): 컬렉션 ➡️ 배열로 변환clear(): 초기화
Object [] oArr = set.toArray();
System.out.println(Arrays.toString(oArr));
System.out.println();
System.out.println("정수 5 존재하는가? : " + set.contains(5));
System.out.println("정수 10 존재하는가? : " + set.contains(10));
System.out.println();
System.out.println("정수 5 삭제 : " + set.remove(5)); // true : 삭제
System.out.println("정수 10 삭제 : " + set.remove(10)); // false : 요소가 없어 삭제 불가
System.out.println();
set.clear();
System.out.println("set 객체의 모든 요소 출력 : " + set);
📒 TreeSet
HashSet 결과 값 오름차순 정렬 ➡️ 같은 타입 데이터만 정렬 가능
Set set = new HashSet();
set.add(300);
set.add(30);
set.add(200);
set.add(1);
set.add(100);
set.add(10);
System.out.println("set : " + set);
Set treeSet = new TreeSet(set);
System.out.println("treeSet : " + treeSet);

💡 List 계열
✅ ArrayList, Vector, LinkedList
📒 ArrayList
인덱스를 사용하고, 중복 데이터를 허용함 ➡️ 데이터 타입과 크기가 가변적인 배열이다!
List<Integer> list = new ArrayList<Integer>(); // 제네릭 -> int형
list.add(1);
list.add(2);
list.add(3);
System.out.println("list 객체가 비어있는가? " + list.isEmpty());
System.out.println("list 객체에 저장된 요소 개수 : " + list.size());
System.out.println("list 객체에 저장된 모든 요소 : " + list);
📝 메서드
Object get(int index): 해당 인덱스의 요소int [last]indexOf(Object o): 특정 요소가 위치한 인덱스
list.add(3);
System.out.println("1번 인덱스에 저장된 요소 : " + list.get(1));
System.out.println("정수 3의 인덱스 : " + list.indexOf(3)); // 앞에서부터 탐색
System.out.println("정수 3의 인덱스 : " + list.lastIndexOf(3)); // 뒤에서부터 탐색

Object remove(Object o): 요소 삭제 후, 삭제된 요소 리턴 ➡️ 정수를 입력하면 데이터가 아닌 인덱스로 인식하기 때문에,indexOf()를 사용해야 함.
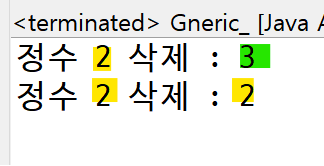
System.out.println("정수 2 삭제 : " + list.remove(2)); // 2번 인덱스 삭제
System.out.println("정수 2 삭제 : " + list.remove(list.indexOf(2))); // 2 삭제
add(int index, Object o): 특정 인덱스에 요소 추가set(int index, Object o): 특정 인덱스에 해당 요소 덮어씀List subList(int begin, int end): begin ~ end-1까지 부분 리스트 추출
list.add(1, 5);
System.out.println("list 객체에 저장된 모든 요소 : " + list);
list.set(1, 10);
System.out.println("list 객체에 저장된 모든 요소 : " + list);
List sublList = list.subList(1, 3); // 1 ~ 3-1(2)까지 추출
System.out.println("추출된 부분 리스트 : " + sublList);

📝 Collections 클래스
Collections.sort(List): 오름차순 정렬 (같은 타입 요소만 가능)Collections.shuffle(List): 무작위 섞기 (타입 무관)
System.out.println("정렬 전 : " + list);
Collections.sort(list);
System.out.println("정렬 후: " + list);
Collections.shuffle(list);
System.out.println("셔플 후: " + list);
📒 Vector
ArrayList와 동일한 구조를 가지지만, 동기화 처리를 하여 속도가 느리다! : 스레드 환경에서 사용
List<String> vector = new Vector<String>();
vector.add("벡");
vector.add("터");
System.out.println("vector 객체가 비어있는가? : " + vector.isEmpty());
System.out.println("vector 객체에 저장된 요소 개수 : " + vector.size());
System.out.println("vector 객체에 저장된 모든 요소 : " + vector);
📒 LinkedList
양방향 연결 리스트 : 각각의 노드를 연결하는 방식 (List + Queue)
List<Integer> link = new LinkedList<Integer>();
link.add(1);
link.add(10);
link.add(100);
System.out.println("link 객체에 저장된 요소 개수 : " + link.size());
System.out.println("link 객체에 저장된 모든 요소 : " + link);
System.out.println("1번 인덱스에 저장된 요소 : " + link.get(1));
💡 Map 계열
✅ HashMap, TreeMap, HashTable, Properties
📒 HashMap
키(key)와 값(value)을 한 쌍으로 가지는 자료구조 ➡️ 키 중복 불가, 값 중복 가능
HashMap<Integer, String> map1 = new HashMap<Integer, String>();
Map<Integer, String> map2 = new HashMap<Integer, String>(); // HashMap -> Map 업캐스팅📝 메서드
put(Object key, Object value): key에 해당하는 value 매핑Object get(Object key): key에 해당하는 값 리턴 (없을 경우 null)
map.put(1, "자바");
map.put(2, "JSP");
map.put(3, "클라우드");
map.put(3, "Spring Framework"); // 키 중목 불가 : 같은 키를 가진 값에 덮어씀
map.put(4, "자바"); // 깂 중복 가능
System.out.println("map 객체의 모든 엔트리 : " + map);
Set keySet(): Map 객체 내의 모든 키를 Set 타입으로 리턴Collection values(): Map 객체 내의 모든 값 리턴Set entrySet():키=값을 한 쌍으로 가지는 엔트리 객체를 Set 타입으로 리턴
Set keySet = map.keySet();
System.out.println("모든 키 : " + keySet);
// List valueList = (List)map.values(); // 주의! 직접 다운캐스팅 불가!
List valueList = new ArrayList(map.values()); // 객체 생성 파라미터로 전달
System.out.println("모든 값 : " + valueList);
Set entrySet = map.entrySet();
System.out.println(entrySet);

💡 Stack & Queue
📒 스택 (Stack)
데이터를 아래쪽(Bottom)부터 차례대로 쌓는 구조 : 후입선출 (LIFO)
Stack<String> stack = new Stack<String>();📝 메서드
push(): 데이터 추가peek(): 맨 위(Top)에 위치한 요소 확인pop(): 맨 위(Top) 위치한 요소 꺼내기 = 삭제 ➡️ 꺼낼 데이터 없으면 예외 발생
stack.push("홍길동");
stack.push("이순신");
stack.push("강감찬");
System.out.println("모든 요소 출력 : " + stack);
System.out.println("맨 위(TOP) 요소 확인 : " + stack.peek());
System.out.println();
System.out.println("맨 위(TOP) 요소 꺼내기 : " + stack.pop());
System.out.println("맨 위(TOP) 요소 확인 : " + stack.peek());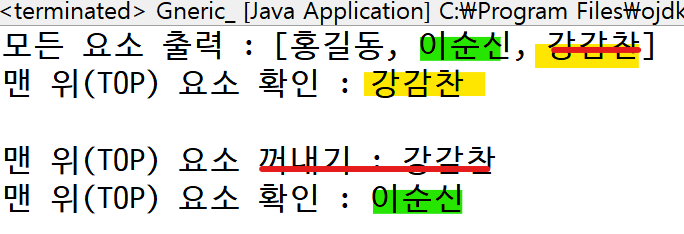
📒 큐 (Queue)
한 쪽(Rear)에서 삽입, 반대쪽(Front)에서 삭제가 일어나는 구조 : 선입선출 (FIFO)
// Queue를 상속받아 구현한 LinkedList 클래스 사용
Queue<String> q = new LinkedList<String>();📝 메서드
offer(): 데이터 추가peek(): 출구(Front)의 요소 확인poll(): 출구(Front)의 요소 꺼내기 = 삭제 ➡️ 꺼낼 데이터 없으면 null 반환
q.offer("java");
q.offer("jsp");
q.offer("mysql");
System.out.println("모든 요소 확인 : " + q);
System.out.println("가장 먼저 추가된 요소 확인(peek) : " + q.peek());
System.out.println();
System.out.println("가장 먼저 추가된 요소 꺼내기(poll) : " + q.poll());
System.out.println("가장 먼저 추가된 요소 확인(peek) : " + q.peek());

백엔드 개발자👩🏻💻가 되고 싶다