
💡 CPU
프로그램의 기계어 명령을 수행하는 컴퓨터 내의 중앙 처리 장치
-
CPU 버스트 : 사용자 프로그램이 CPU를 작업을 처리하는 단계
- CPU 바운드 프로세스 : CPU 버스트 > I/O 버스트 (I/O 요청 ⬇️)
-
I/O 버스트 : I/O 요청에 의해 커널에 의해 입출력을 처리하는 단계
- I/O 바운드 프로세스 : CPU 버스트 < I/O 버스트 (I/O 요청 ⬆️)
 : 일반적인 컴퓨터는 CPU가 한 개이므로, CPU를 보다 효율적으로 사용하기 위해 적절한 스케줄링이 필요하다.
: 일반적인 컴퓨터는 CPU가 한 개이므로, CPU를 보다 효율적으로 사용하기 위해 적절한 스케줄링이 필요하다.
📒 CPU 스케줄링
준비 상태에 있는 프로세스 중 어떤 프로세스에게 CPU를 할당할 것인가?
✔️ CPU 스케줄링이 필요한 경우
-
실행 상태의 프로세스가 봉쇄 상태로 바뀌는 경우
-
실행 상태의 프로세스가 타이머 인터럽트에 의해 준비 상태로 바뀌는 경우
-
봉쇄 상태의 프로세스가 준비 상태로 바뀌는 경우
-
실행 상태의 프로세스가 종료되는 경우
📝 방식
- 비선점형 : CPU를 할당받은 프로세스가 CPU를 반납하기 전까지는 CPU를 빼앗기지 않는 방식
- 선점형 : 경우에 따라 CPU를 강제로 빼앗을 수 있는 방식
📝 성능 평가
✔️ 시스템 관점 : 이용률, 처리량
-
이용률 : 전체 시간 중, CPU가 일을 한 시간의 비율
➡️ CPU가 일을 하지 않는 휴면 상태에 머무르는 시간을 최소화 해야 함! -
처리량 : 주어진 시간 동안 처리한 프로세스의 개수
➡️ 많은 프로세스를 처리하기 위해서는, CPU 버스트 시간이 짧은 I/O 바운드 프로세스를 먼저 처리하는 것이 유리함!
✔️ 사용자 관점 : 소요시간, 대기시간, 응답시간
- 소요시간 : 준비 큐에서 기다린 시간 + 실제로 CPU를 사용한 시간
- 대기시간 : 준비 큐에서 기다린 시간의 총합
- 응답시간 : 첫번째 CPU를 할당받기 위해 기다린 시간
📒 스케줄링 알고리즘
📝 선입선출 (FIFO, FCFS)
프로세스가 준비 큐에 도착한 시간 순서대로 CPU를 할당
| 프로세스 | CPU 버스트 시간 | 도착 시간 |
|---|---|---|
| p1 | 12 | 0 |
| p2 | 3 | 0 |
| p3 | 3 | 0 |
ex1) p1 → p2 → p3 순서로 도착한 경우 : 평균 대기시간 = 9
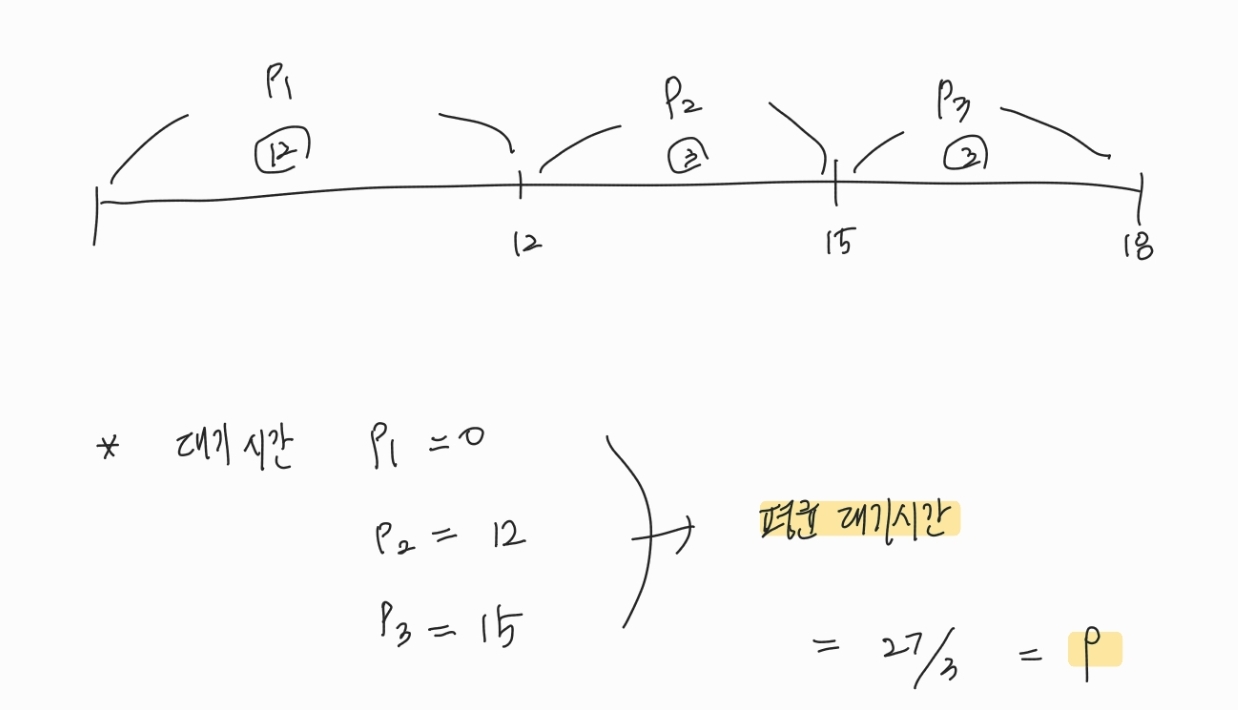
ex2) p2 → p3 → p1 순서로 도착한 경우 : 평균 대기시간 = 3
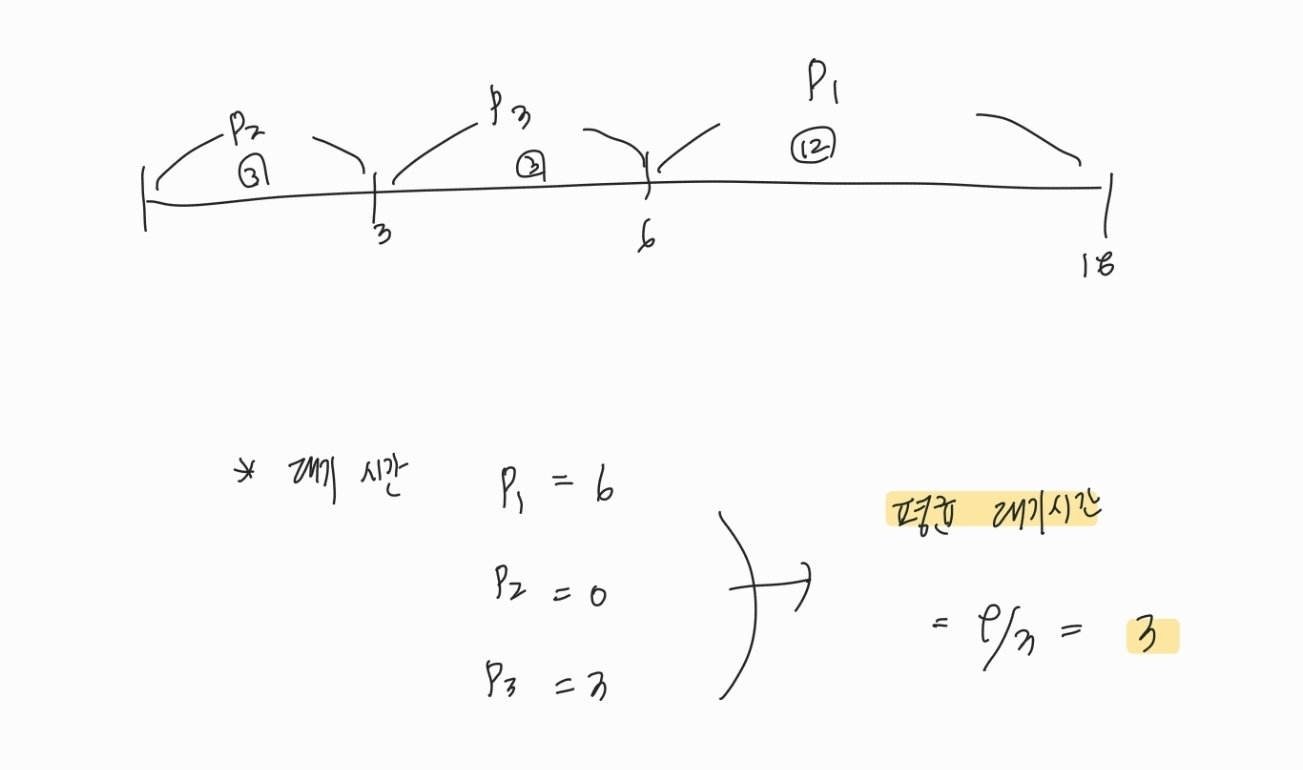
✅ 콘보이 현상 발생
선입선출법을 사용하는 경우, 먼저 도착한 프로세스의 CPU 버스트 시간에 따라 평균 대기 시간이 달라진다.
만약 CPU 버스트가 긴 프로세스가 가장 먼저 도착하고 CPU 버스트가 짧은 프로세스가 나중에 도착하게 되면, CPU 버스트가 짧은 프로세스는 먼저 도착한 CPU 버스트가 긴 프로세스의 작업을 마칠 때까지 기다려야 하므로 매우 비효율적이다.
📝 최단작업 우선 스케줄링 (SJF)
CPU 버스트가 가장 짧은 프로세스에게 먼저 CPU를 할당
✔️ 비선점형 방식
현재 처리 중인 작업을 마친 후, 가장 짧은 프로세스에 CPU 할당
| 프로세스 | CPU 버스트 시간 | 도착 시간 |
|---|---|---|
| p1 | 14 | 0 |
| p2 | 8 | 4 |
| p3 | 2 | 8 |
| p4 | 8 | 10 |
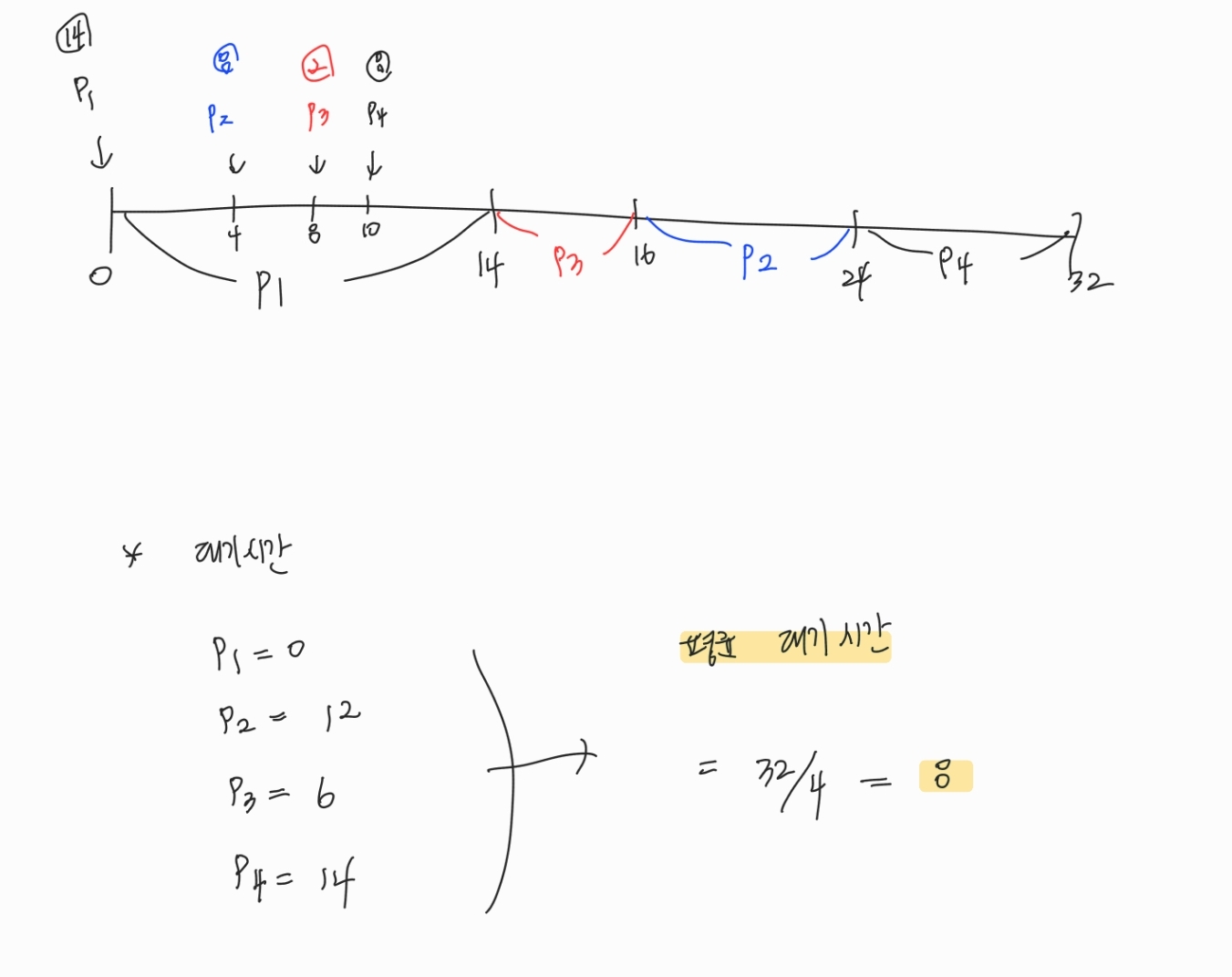
✔️ 선점형 방식
현재 처리 중인 프로세스보다 CPU 버스트가 짧은 프로세스가 도착하면, CPU를 뺏어 해당 프로세스에 할당
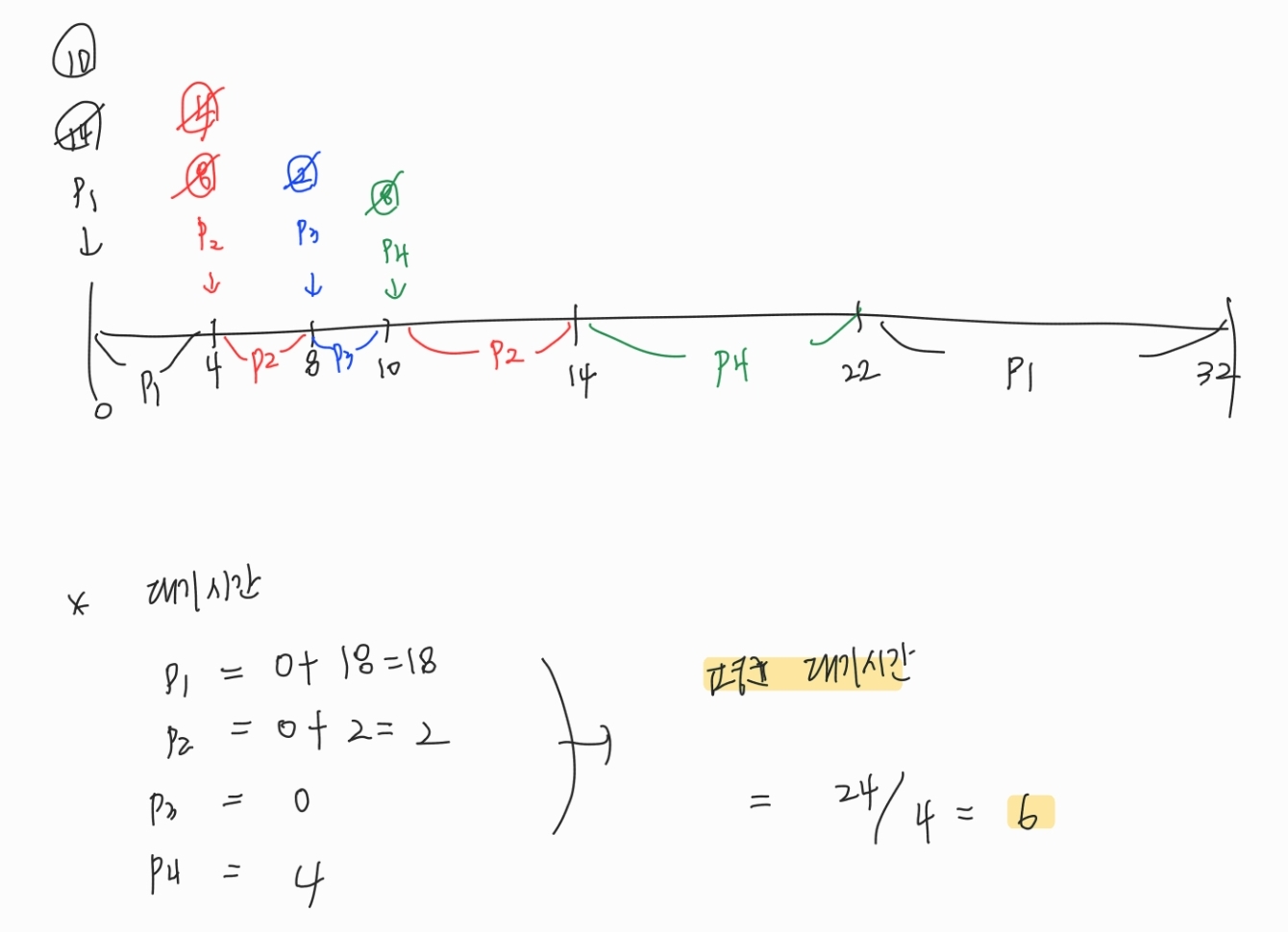
✅ 기아 현상 발생
SJF를 사용하면 CPU 버스트가 짧은 프로세스에게 우선적으로 CPU가 할당되기 때문에, CPU 버스트가 짧은 프로세스가 계속 도착하게 되면 CPU 버스트가 가장 긴 프로세스는 무한정으로 기다려야 하는 경우가 발생할 수 있다.
📝 우선순위 스케줄링
우선순위가 가장 높은 프로세스에게 먼저 CPU를 할당 (우선순위 값 ↓ : 우선순위 ↑)
✔️ 비선점형 & 선점형
SJF와 같다!
✅ 노화 기법 사용
우선순위는 CPU 버스트, 작업의 중요도 등 다양한 기준을 통해 부여할 수 있다.
만약 CPU 버스트가 짧은 작업의 우선순위를 높게 준다면 SJF 알고리즘과 같으므로 기아 현상이 발생할 수 있다. 이 때, CPU 버스트가 긴 프로세스의 대기 시간에 따라 우선순위를 높여줌으로써 기아 현상을 해결할 수 있다!
이처럼, 대기 시간이 길어지면 우선순위를 조금씩 높여 우선순위가 낮은 프로세스도 언젠가는 CPU를 할당받을 수 있게 하는 방법을 노화 기법이라고 한다.
📝 라운드 로빈 (Round Robin)
각 프로세스의 CPU 사용 시간을 제한하여, 시간이 경과하면 CPU를 뺏어 다른 프로세스에게 CPU를 할당 = 시분할 시스템
: 할당시간이 너무 길면 선입선출과 같이 콘보이 현상이 발생하게 되고, 너무 짧으면 프로세스의 교체 횟수가 증가하여 문맥교환의 오버헤드가 커진다.
ex) p1 → p2 → p3 순서로 도착, 할당시간 = 5
| 프로세스 | CPU 버스트 시간 |
|---|---|
| p1 | 14 |
| p2 | 7 |
| p3 | 3 |
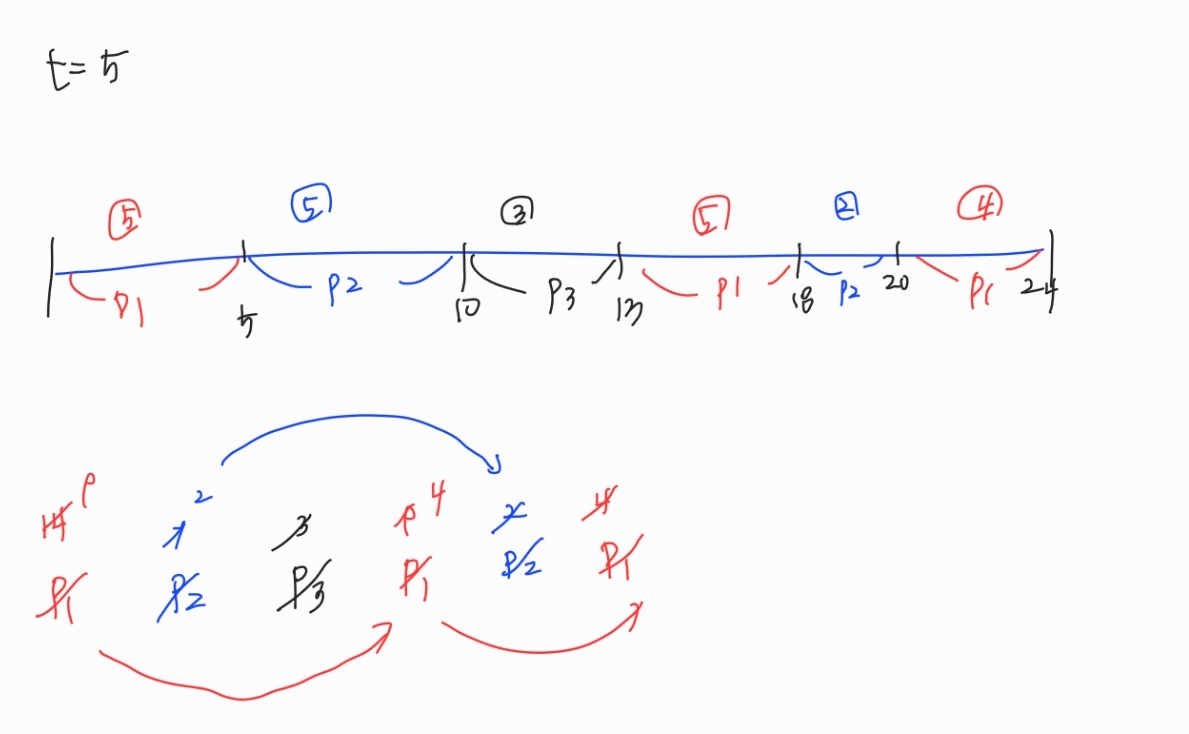
: 도착한 순서대로 CPU를 할당받되, 할당시간이 지나면 타이머 인터럽트가 발생하여 다음 순서의 프로세스에게 CPU를 넘겨주고, 준비 큐의 가장 뒤로 가서 다시 줄을 선다. 이 때, 할당시간만큼 작업을 처리하였으므로 이후에는 남은 시간만큼만 작업을 처리해주면 된다.
📝 멀티레벨 큐
준비 큐를 여러 개로 분할하여 관리
-
전위 큐 (라운드 로빈): 대화형 작업을 위한 큐 ➡️ CPU 버스트 ↓, 응답시간 ↓
-
후위 큐 (선입선출) : 계산 위주의 작업을 위한 큐 ➡️ CPU 버스트 ↑

각 큐에 대해 고정 우선순위 방식을 사용하여 우선순위가 높은 큐를 먼저 처리하고, 해당 큐가 비어있을 때만 우선순위가 낮은 큐를 처리하는 방식으로 사용한다.
하지만 고정 우선순위 방식을 사용하면 기아 현상이 발생할 수 있으므로, 큐마다 CPU 시간을 적절한 비율로 할당하는 타임 슬라이스 방식을 사용할 수도 있다.
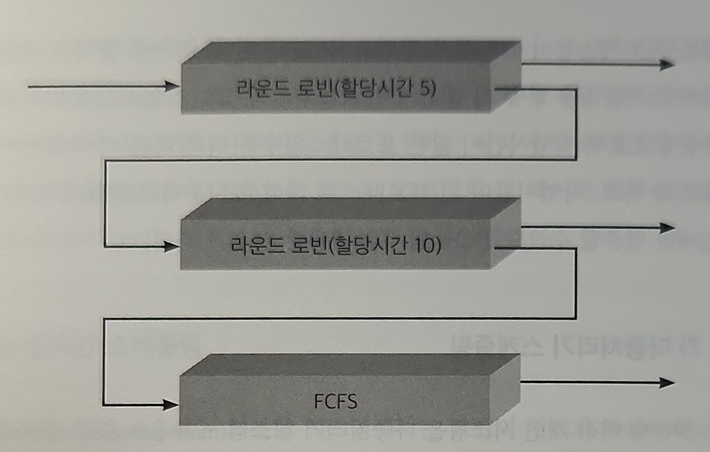
📝 멀티레벨 피드백 큐
프로세스가 기존의 큐에서 다른 큐로 이동 가능
📝 다중처리기
CPU가 여러 개인 시스템
: 프로세스를 한 줄로 세워 각 CPU가 알아서 프로세스를 꺼내가게 함
- 대칭형 : 각 CPU가 각자 알아서 스케줄링 결정
- 비대칭형 : 한 CPU가 모든 CPU의 스케줄링을 결정
📝 실시간 시스템 (EDF)
데드라인이 얼마 남지 않은 요청을 먼저 처리
출처 : 운영체제와 정보기술의 원리
