
사용자 커맨드
사용자 커맨드는 hdfs, hadoop 쉘을 이용할 수 있습니다. 일부 커맨드는 hdfs 쉘을 이용해야 합니다. 둘 다 이용할 수 있는 경우 각 쉘의 결과는 동일하며, 사용법은 다음과 같습니다.
# dfs 커맨드는 둘다 동일한 결과를 출력
$ hdfs dfs -ls
$ hadoop fs -ls
# fsck 커맨드도 동일한 결과 출력
$ hdfs fsck /
$ hadoop fsck /
# fs.defaultFS 설정값 확인
$ hdfs getconf -confKey fs.defaultFS
hdfs://127.0.0.1:8020
# 명령어를 인식하지 못함
$ hadoop getconf
Error: Could not find or load main class getconf
사용자 커맨드 목록
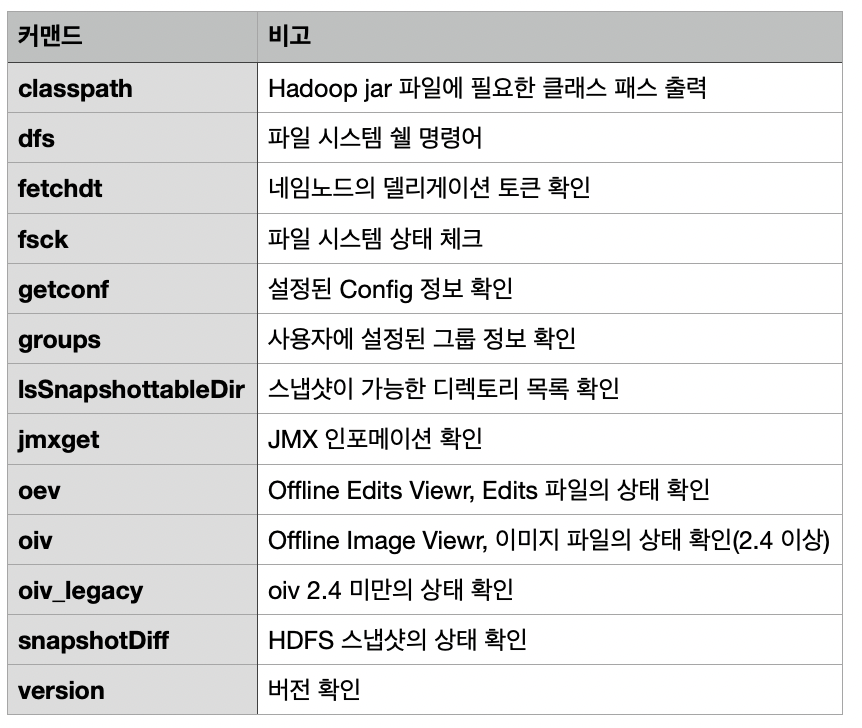
이 명령어 중에서 필수적인 dfs와 fsck 커맨드에 대해서 확인해 보겠습니다.
dfs 커맨드
dfs 커맨드는 파일시스템 쉘을 실행하는 명령어 입니다. dfs는 hdfs dfs, hadoop fs, hadoop dfs 세가지 형태로 실행이 가능합니다. 전체 명령어는 파일시스템쉘 가이드(바로가기)를 확인하시면 됩니다. 명령어의 사용법은 다음과 같습니다.
$ hdfs dfs -ls
Found 17 items
drwxr-xr-x - hadoop hadoop 0 2018-11-30 06:15 datas
$ hadoop fs -ls
Found 17 items
drwxr-xr-x - hadoop hadoop 0 2018-11-30 06:15 datas
dfs 커맨드 명령어


- df는 복제개수를 포함한 전체의 용량을 표현하고, du 단일 파일 또는 경로의 용량입니다. 1M파일의 용량을 du로 확인하면 1M으로 나오지만, df로 파일 시스템의 용량을 확인하면 복제개수가 3일때 3M으로 표현됩니다.
이중에서 주요 명령어의 사용법을 확인해 보겠습니다.
cat
지정한 파일을 기본 입력으로 읽어서 출력합니다.
$ hadoop fs -cat /user/file.txt
text
지정한 파일을 텍스트 형식으로 읽습니다. gzip, snappy 등의 형식으로 압축된 파일을 자동으로 텍스트 형식으로 출력해 줍니다.
$ hadoop fs -text /user/file.txt
ls
주어진 경로의 파일 목록을 조회합니다.
- 주요옵션:
h,R,u
$ hadoop fs -ls /user/
# 사람이 읽을 수 있는 형태로 파일사이즈를 메가, 기가로 변경하여 출력
$ hadoop fs -ls -h /user/
# 하위 폴더까지 조회
$ hadoop fs -ls -R /user/
# 액세스 시간을 조회. 기본설정은 생성 시간. 마지막 접근 시간을 확인하여 파일 정리 가능
$ hadoop fs -ls -u /user/
mkdir
디렉토리를 생성합니다.
- 주요옵션:
p
$ hadoop fs -mkdir /user/folder
# /user/folder1/folder2를 생성, 상위 폴더가 없으면 자동으로 생성
$ hadoop fs -mkdir -p /user/folder1/folder2
cp
HDFS 상의 파일을 복사 합니다.
$ hadoop fs -cp /user/data1.txt /user/data2.txt
mv
HDFS 상의 파일을 이동 합니다. 파일 이름을 변경할 때도 사용합니다.
$ hadoop fs -mv /user/data1.txt /user/data2.txt
get
HDFS의 파일을 로컬에 복사할 때 사용합니다.
- 주요옵션:
f
$ hadoop fs -get /user/data1.txt ./
# 동일한 이름의 파일이 존재하면 덮어씀
$ hadoop fs -get -f /user/data1.txt ./
put
로컬의 파일을 HDFS에 복사할 때 사용합니다.
- 주요옵션:
f
$ hadoop fs -put ./data1.txt /user/
# 동일한 이름의 파일이 존재하면 덮어씀
$ hadoop fs -put -f ./data1.txt /user/
rm
HDFS의 파일을 삭제할 때 사용합니다.
- 주요옵션:
r,spkipTrash
$ hadoop fs -rm /user/data1.txt
# 디렉토리를 포함하여 하위의 모든 파일을 삭제, 디렉토리 삭제시 필요함
$ hadoop fs -rm -r /user/
# 쓰레기통을 사용하지 않고 파일 삭제
$ hadoop fs -skipTrash /user/
setrep
디렉토리, 파일의 레플리케이션 팩터를 수정합니다.
- 주요옵션:
R
# 디렉토리의 복제개수를 5로 설정
$ hadoop fs -setrep 5 /user/
# 하위의 모든 디렉토리, 파일의 복제개수를 5로 설정
$ hadoop fs -setrep 5 -R /user/
touchz
0byte 파일을 생성합니다.
$ hadoop fs -touchz /user/test.txt
stat
주어진 포맷에 따른 파일의 정보를 확인합니다.
# 주요 포맷
# %y : 마지막 수정 시간
# %x : 마지막 접근 시간
# %n : 파일 이름
# %b : 파일 사이즈 (byte)
$ hadoop fs -stat "%y %n" hdfs://127.0.0.1:8020/*
fsck 커맨드
fsck 커맨드는 HDFS 파일시스템의 상태를 체크하는 명령어 입니다. fsck 커맨드는 파일시스템에 블록 상태 확인, 파일의 복제 개수를 확인하여 결과를 알려줍니다. 일반적으로 네임노드가 자동으로 상태를 복구하기 위한 작업을 진행하기 때문에 fsck 커맨드가 오류를 확인해도 상태를 정정하지는 않습니다.
fsck 커맨드 명령어
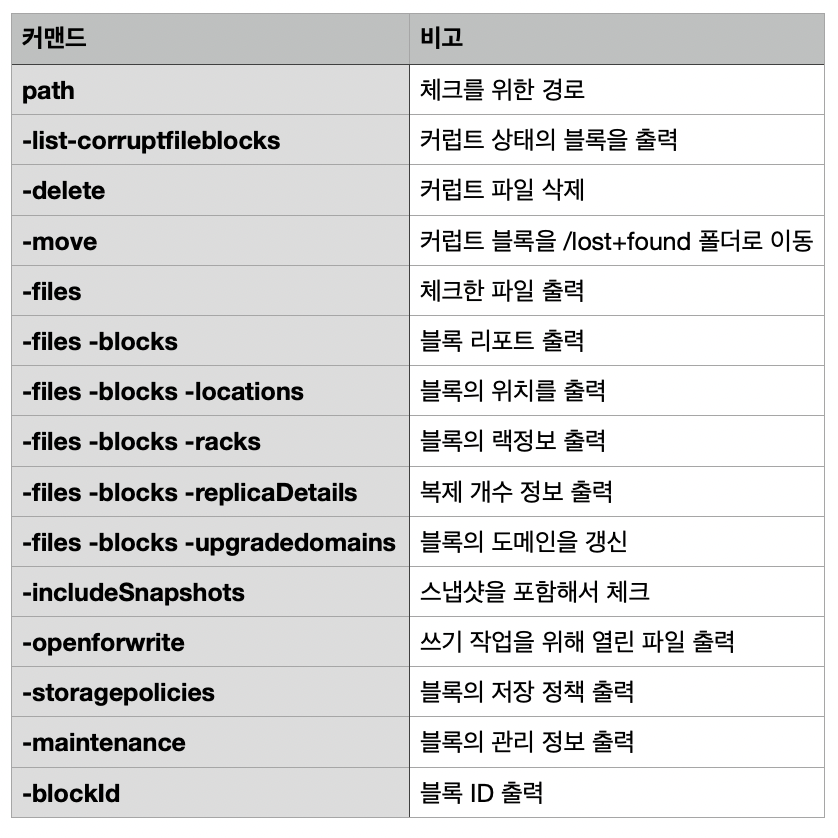
사용법
fsck 커맨드는 우선 를 지정해야 합니다. 파일 시스템의 상태를 체크할 경로를 지정하고 필요한 명령어를 입력하면 됩니다. fsck 커맨드로 파일 시스템의 상태를 확인하고, -delete 커맨드로 오류가 난 파일을 삭제할 수 있습니다.
$ hdfs fsck <path> [-list-corruptfileblocks
[-move | -delete | -openforwrite]
[-files [-blocks [-locations | -racks]]]]
[-includeSnapshots] [-storagepolicies] [-blockId <blk_Id>]
$ hdfs fsck /
$ hdfs fsck /user/hadoop/
$ hdfs fsck /user -list-corruptfileblocks
$ hdfs fsck /user -delete
$ hdfs fsck /user -files
$ hdfs fsck /user -files -blocks
$ hdfs fsck /
Status: HEALTHY
Total size: 7683823089 B
Total dirs: 3534
Total files: 14454
Total symlinks: 0
Total blocks (validated): 14334 (avg. block size 536055 B)
Minimally replicated blocks: 14334 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 14334 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 2
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 31288 (68.58095 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Fri Dec 28 04:07:32 UTC 2018 in 172 milliseconds
운영자 커맨드
운영자 커맨드도 hdfs, hadoop 쉘을 이용할 수 있습니다. 일부 커맨드는 hdfs 쉘을 이용해야 합니다. 둘 다 이용할 수 있는 경우 각 쉘의 결과는 동일하며, 사용법은 다음과 같습니다.
# 둘다 balancer를 실행
$ hdfs balancer
$ hadoop balancer
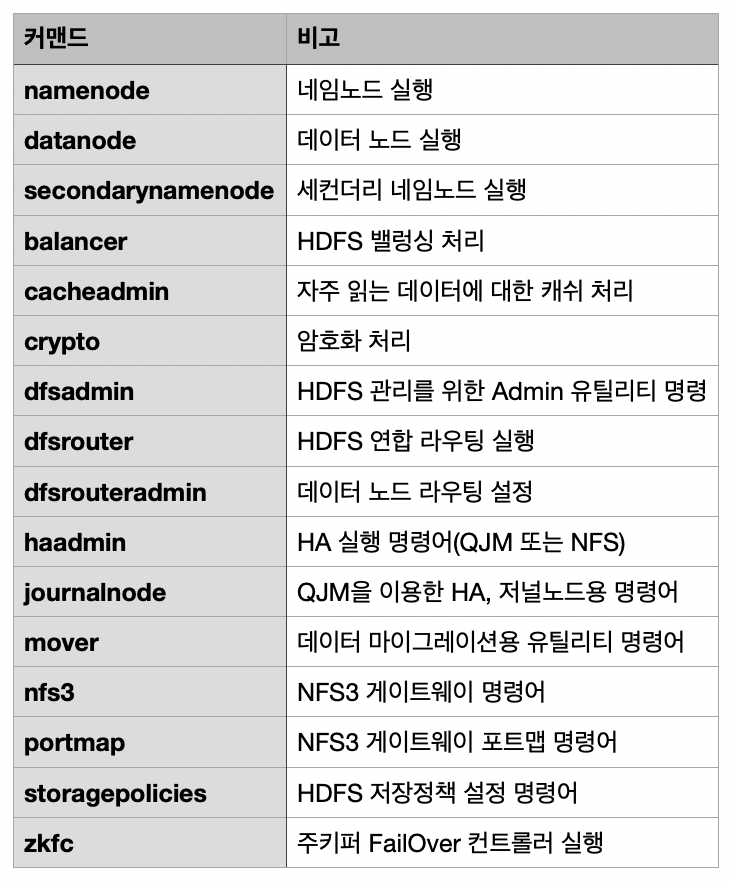
운영자 커맨드 목록
운영자 커맨드는 주로 실행, 설정 관련 명령어가 많습니다. 각 명령어의 주요 옵션은 Administration Commands2를 확인하면 됩니다.
dfsadmin 커맨드
dfsadmin 커맨드는 hdfs의 관리를 위한 정보를 설정 및 변경할 수 있습니다. 쿼타(Quota) 설정, 노드들의 리프레쉬, 노드들의 동작 및 정지등을 처리할 수 있습니다. 주요 명령어는 다음과 같습니다.
fsck 커맨드 명령어
사용법
dfsadmin 커맨드가 가지고 있는 명령어는 다음과 같이 다양합니다. 주요 명령어의 사용 방법을 알아보겠습니다.
전체 명령어
$ hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.
[-report [-live] [-dead] [-decommissioning]]
[-safemode <enter | leave | get | wait>]
[-saveNamespace]
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes]
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>]
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
[-finalizeUpgrade]
[-rollingUpgrade [<query|prepare|finalize>]]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh <host:ipc_port> <key> [arg1..argn]
[-reconfig <datanode|...> <host:ipc_port> <start|status>]
[-printTopology]
[-refreshNamenodes datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-fetchImage <local directory>]
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-metasave filename]
[-triggerBlockReport [-incremental] <datanode_host:ipc_port>]
[-help [cmd]]
report
HDFS의 각 노드들의 상태를 출력합니다. HDFS의 전체 사용량과 각 노드의 상태를 확인할 수 있습니다.
- Configured Capacity: 각 데이터 노드에서 HDFS에서 사용할 수 있게 할당 된 용량
- Present Capacity: HDFS에서 사용할 수 있는 용량
- Configured Capacity에서 Non DFS Used 용량을 뺀 실제 데이터 저장에 이용할 수 있는 용량
- DFS Remaining: HDFS에서 남은 용량
- DFS Used: HDFS에 저장된 용량
- Non DFS Used: 맵리듀스 임시 파일, 작업 로그 등 데이터 노드에 저장된 블록 데이터가 아닌 파일의 용량
- Xceivers: 현재 작업중인 블록의 개수
$ hdfs dfsadmin -report
Configured Capacity: 165810782208 (154.42 GB)
Present Capacity: 152727556096 (142.24 GB)
DFS Remaining: 140297670656 (130.66 GB)
DFS Used: 12429885440 (11.58 GB)
DFS Used%: 8.14%
Under replicated blocks: 18861
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (1):
Name: x.x.x.x:50010 (data_node)
Hostname: data_node
Decommission Status : Normal
Configured Capacity: 165810782208 (154.42 GB)
DFS Used: 12429885440 (11.58 GB)
Non DFS Used: 13083226112 (12.18 GB)
DFS Remaining: 140297670656 (130.66 GB)
DFS Used%: 7.50%
DFS Remaining%: 84.61%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 2
Last contact: Thu Apr 25 08:29:50 UTC 2019
safemode
세이프모드에 진입하고 빠져나올 수 있습니다.
$ hdfs dfsadmin -safemode get
Safe mode is OFF
$ hdfs dfsadmin -safemode enter
Safe mode is ON
$ hdfs dfsadmin -safemode get
Safe mode is ON
$ hdfs dfsadmin -safemode leave
Safe mode is OFF
$ hdfs dfsadmin -safemode wait
Safe mode is OFF
