최근 기계학습을 위한 데이터의 수집 및 전처리 과정등을 위해 웹 크롤러의 역할이 점차 중요해지고 있다. Scrapy를 알고 있다면 크롤링을 좀 더 안정적이고, 빠르게 할 수 있고, 다양한 포맷으로 저장할 수도 있다.
😎 Scrapy 공부한 내용을 정리해 보겠다.
Scrapy
스크래피(Scrapy)는 Python으로 작성된 오픈소스 웹 크롤링 프레임워크이다. 웹 데이터를 수집하는 것을 목표로 설계되었다. 또한 API를 이용하여 데이터를 추출할 수 있고, 범용 웹 크롤러로 사용될 수 있다.
기본적으로 가상 환경을 만들고 시작한다.
# 가상환경 만들기
python -m venv craw_env
# 가상환경 활성화
craw_env/Script/activate
Scrapy 설치
명령어를 입력해서 쉽게 설치 할 수 있다.
공식 설치 방법 이곳에서 들어가서 확인이 가능하다.
Scrapy가 설치 되기 전에 window에서는 에러가 나는 경우가 있기 때문에 pip, setuptools은 upgrade 해준다. Win32 에러 발생 시 pip install pypiwin32 설치 해 준다.
# pip, setuptools upgrade
python -m pip install --upgrade pip
pip install --upgrade setuptools
# scrapy 설치
pip install scrapy
# scrapy 버전확인
scrapy versionProject 생성
scrapy startproject [프로젝트이름] 으로 프로젝트를 생성한다.
# 프로젝트 생성
scrapy startproject test_project기본적인 scrapy 프로젝트의 구조이다.
$ tree craw_env
test_project
├── scrapy.cfg
└── test_project
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.pySpider 생성
프로젝트를 생성한 뒤 genspider 명령어를 통해서 spider class를 만들어준다. scrapy.cfg 있는 폴더 안에서 명령어를 실행 해야 한다.
크롤링 테스트를 할 수 있는 사이트로 scrapinghub 로 테스트 했다.
scrapy genspider [스파이더 이름] [크롤링URL]
# spider 생성
scrapy genspider testspider scrapinghub.com이렇게 하면 spiders 폴더안에 testspider.py가 만들어 진다.
testspider.py 열어 본다.
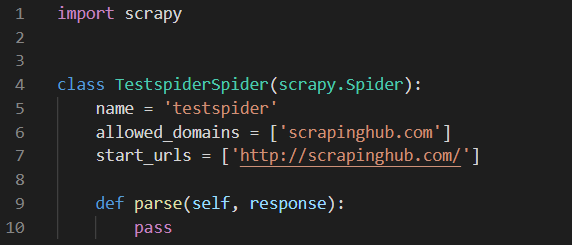
지정한 스파이더 이름과 크롤링 url 들어간 것을 확인 할 수 있다.
나는 class이름과 실행명령어 name을 수정 하겠다.
🌷 print를 통해서 값을 확인 해 본다.
import scrapy
class TestSpider(scrapy.Spider):
# 스파이더 이름(실행)
name = 'test'
# 허용 도메인
allowed_domains = ['scrapinghub.com']
# 시작 URL
start_urls = ['https://scrapinghub.com/']
def parse(self, response):
print('dir', dir(response))
print('status', response.status)
print('text', response.body) settings.py
실행하기 전에 settings.py 에서 DOWNLOAD_DELAY를 수정한다.
주석처리가 되어 있는데 크롤링 테스트 페이지를 이용하므로 2초 정도로 수정 했다.
DOWNLOAD_DELAY = 2실행 하기
실행하기 전에 명령어에는 Runspider 와 Crawl 가 있다.
scrapy crawl [스파이더 name]
scrapy runspider [스파이더]
runspider는 spiders폴더에서 실행할 수 있고, crawl은 scrapy.cfg 파일이 존재하는 폴더에서 실행해야 한다.
runspider은 spider bot을 실행시키는 것은 단위 테스트 방식을 할 때 유용하고 crawl은 구조를 다 만들어 놓은 후 테스트를 할 때나 실제로 크롤링을 할 경우 사용하는 것이 유용하다.
# runspider : spiders 폴더에서 실행
scrapy runspider testspider.py
# crawl : scrapy.cfg파일이 존재하는 path에서 실행
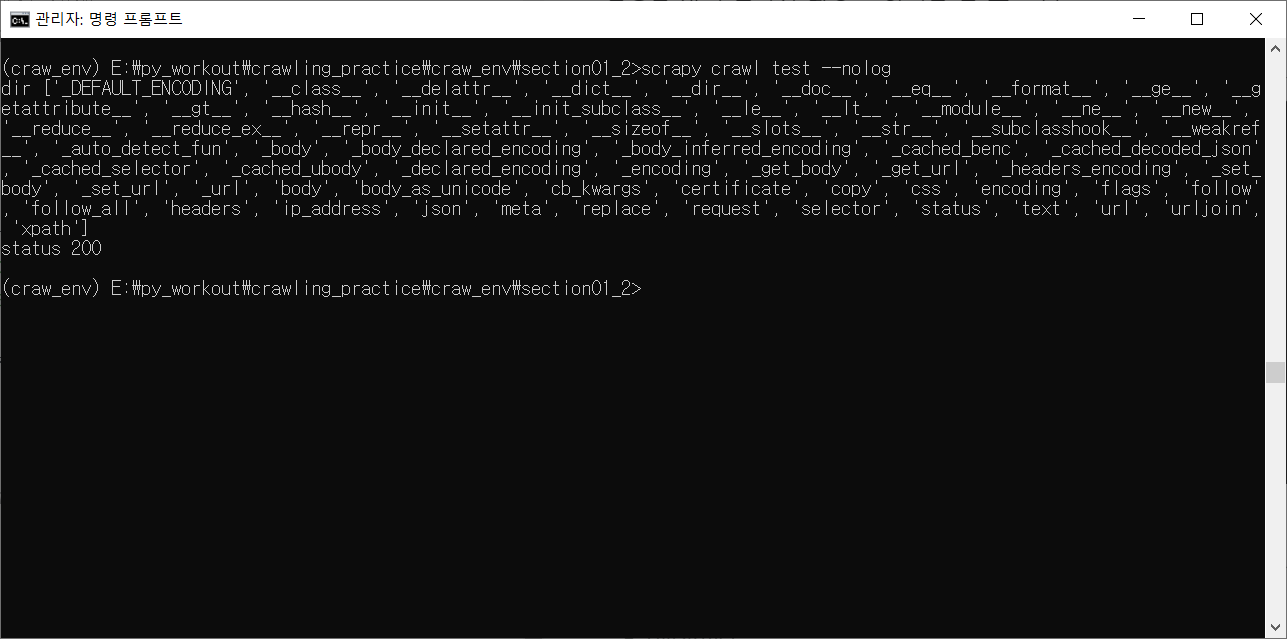
scrapy crawl test실행을 하면 로그가 나오는 화면을 볼 수 있다.
로그를 나오게 하지 않으려면 실행 명령어 뒤에 --nolog 명령어를 사용한다.
# runspider
scrapy runspider testspider.py --nolog
# crawl
scrapy crawl test --nologlog가 없어진 것을 확인 할 수 있다.