알고리즘
1.[알고리즘] 시간 복잡도(Time Complexity)와 Big-O 표기법
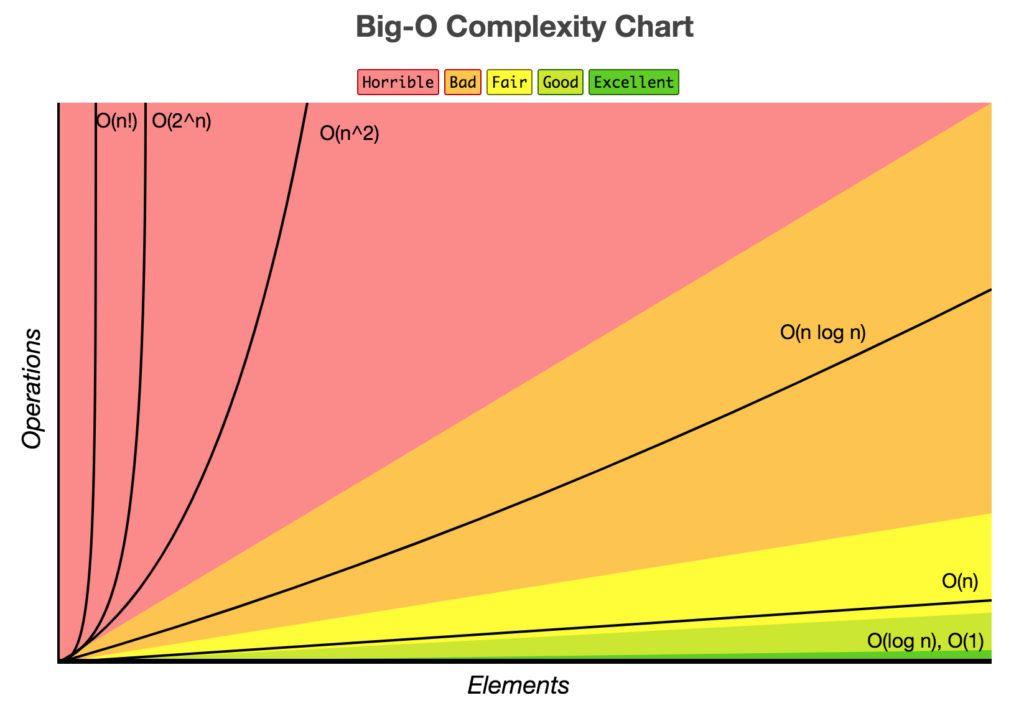
알고리즘에서 실행시간은 실행환경에 따라 달라진다. 같은 알고리즘이어도 하드웨어, 운영체제, 언어, 컴파일러... 등의 환경에 따라 실행되는 시간은 달라질 수 있기 때문에 이를 절대적인 시간 단위(1초, 2초)로 말할 수 없다. 그래서 실행시간을 측정하는 대신에, 알고
2.[알고리즘] 이진 탐색 (Binary search)
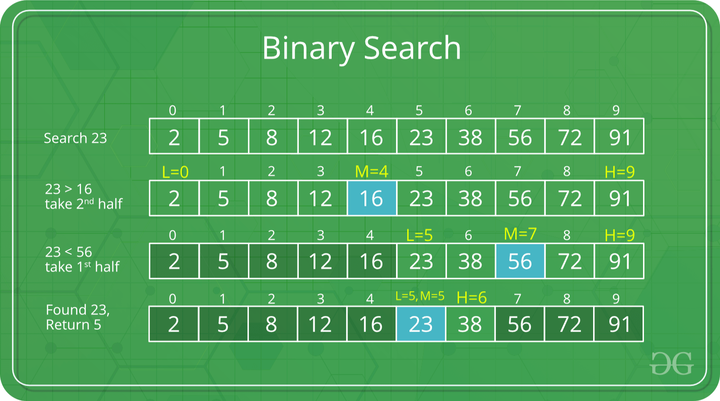
배열이 오름차순으로 정렬되어 있다는 가정 하에 특정한 값을 검색하는 알고리즘이다.처음 중간값(middle)을 임의로 선택한 후, 만약 찾고자 하는 값이 중간값보다 크다면 2등분으로 분할한 배열에서 왼쪽으로 이동한다. 또, 분할된 배열의 중간값을 선택한 후 찾고자 하는
3.[알고리즘] 기본 정렬 알고리즘(Selection sort, Bubble sort, Insertion sort)
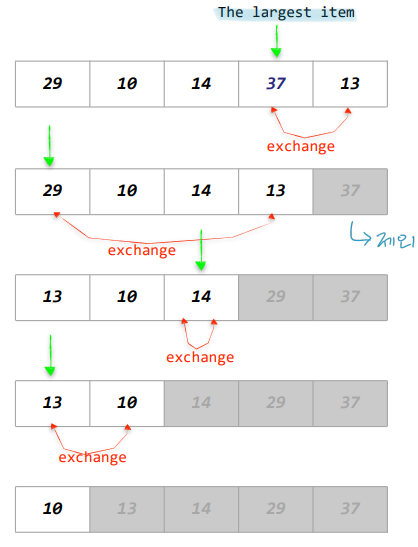
1. Selection sort (선택 정렬) 선택 정렬의 작동 원리 리스트에서 최소값을 찾는다. 최소값을 찾으면, 배열의 맨 앞 원소와 자리를 교체한다. 루프에서 맨 앞의 원소를 제외한 후 다시 루프를 돈다. 이는 최소값이 아닌 최대값에도 작동한다. 최대값을 중심
4.[알고리즘] 분할정복법 (Merge sort, Quick sort)
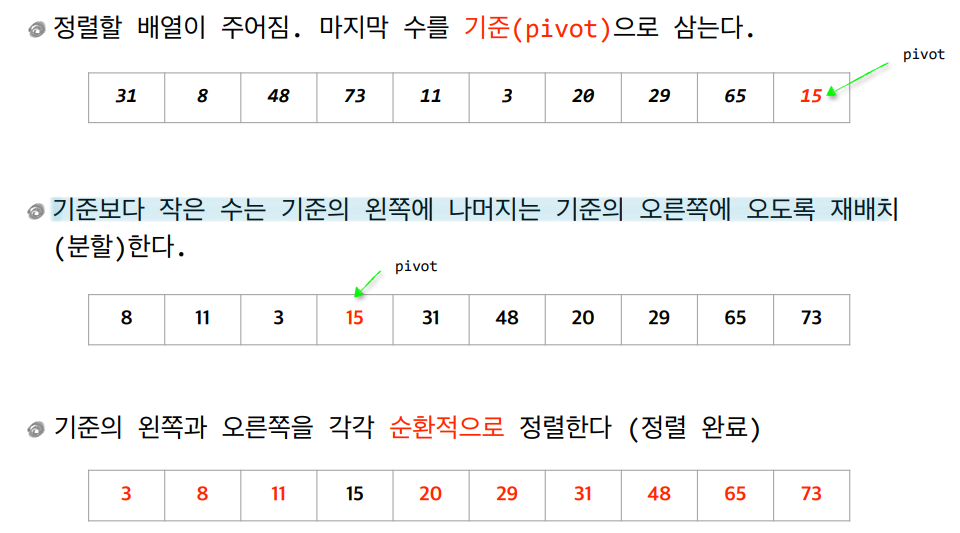
분할정복법 분할정복법이란 해결하고자 하는 문제를 작은 크기의 동일한 문제들로 분할(Divide)하고, 각각의 문제들을 순환적으로 해결(정복, Conquer)하고, 작은 문제의 해들을 합병(Merge)하여 원래 문제에 대한 해를 구하는 방법이다. 분할정복법에는 합병정
5.[알고리즘] 힙 정렬(Heap sort)
힙 정렬은 이진 힙(binary heap) 자료구조를 사용하는 정렬 방법이다. 힙이란? Heap은 최댓값 및 최솟값을 빠르게 찾아내기 위해 고안된 자료 구조로, 완전이진트리(complete binary tree)이면서 힙 속성(heap property)를 만족한다.
6.[알고리즘] 정렬 알고리즘들의 실행 시간 비교
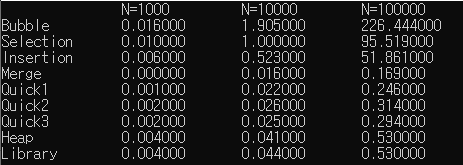
정렬마다 난수를 새로 만들기 때문에 100% 정확한 비교 데이터는 아니나, 상대적인 시간 복잡도를 비교해볼 수 있는 코드이다. 컴퓨터 성능에 따라 실행시간은 달라질 수 있다. 소스코드
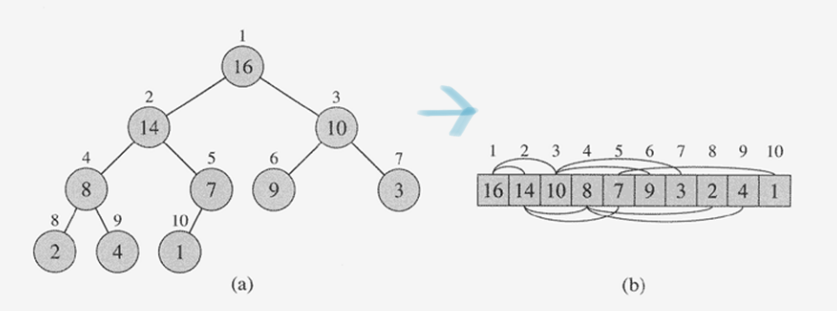
7.[알고리즘] 이진트리와 순회(Inorder, Preorder, Postorder)
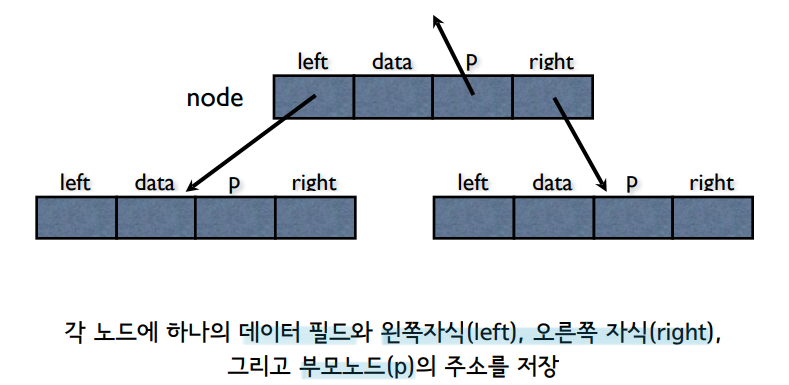
트리는 계층적인 구조를 표현하는 자료 구조로, 가장 상위 노드인 루트 노드와 나머지 내부 노드, 그리고 가장 끝의 자식이 없는 리프 노드로 구성된다.이진 트리란 각 노드가 최대 2개의 자식을 갖는 트리이다. 이진 트리는 배열로 구현할 수도 있으나 연결 리스트로 구현하면
8.[알고리즘] 스택
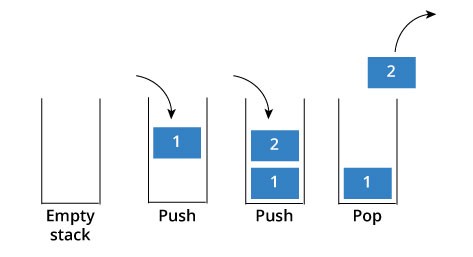
일종의 리스트이나, 데이터의 삽입과 삭제가 한쪽 끝에서만 이루어진다는 특징을 가지는 자료 구조이다.
9.[알고리즘] 큐(queue)

큐 (queue) 큐 자료 구조는 스택과 유사하게 일종의 리스트라고 할 수 있다. 단, 큐에서 데이터의 삽입은 한 쪽 끝에서, 삭제는 반대쪽 끝에서만 일어난다. 이때 삽입이 일어나는 쪽을 rear, 삭제가 일어나는 쪽을 front라고 한다. 큐의 주요 연산 |연산
10.[알고리즘] 재귀: 멱집합(Powerset), 순열 구하기
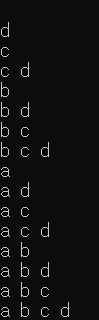
data = {a, b, c, d} 가 존재할 때이 집합의 멱집합은 ∅, {a}, {b}, {c}, {d}, {a, b}, {a, c}, {a, d} ...어떤 집합이 존재할 때 그 집합의 모든 부분집합의 집합을 멱집합(Powerset)이라고 한다.{a, b, c, d
11.[알고리즘] 백트래킹(Backtracking): N-queens 문제
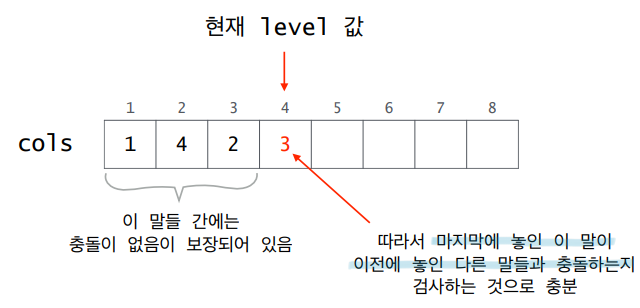
백트래킹 (Backtracking) 상태공간트리란 문제 해결 과정에서 해를 포함하고 있는 트리이다. 해가 존재한다면 그 해는 반드시 상태공간트리의 어떤 노드에 해당하므로, 이 트리를 체계적으로 탐색하면 언젠가는 해를 구할 수 있다. 해를 찾기 위해 상태공간트리를 완전
12.[알고리즘] 동적 계획법(DP, Dynamic Programming)
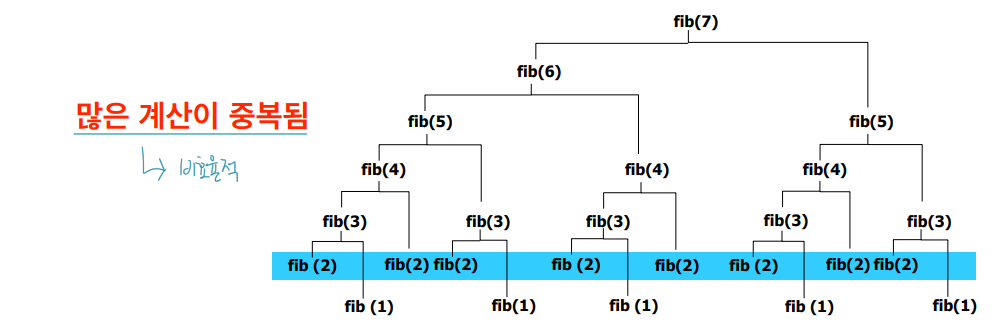
재귀(再歸)라고 하는 수학적 개념에 기초를 두고 「최적성의 원리」에 따라 다단계의 결정과정을 취급하는 것이며 최대의 목재생산을 위한 간벌계획문제를 비롯해서 각종의 배분문제, 재고문제, 경제문제 등의 여러 가지 결정문제에 유용하게 쓰인다.\[네이버 지식백과] 동태계획법
13.[알고리즘] 그래프 탐색(너비우선탐색(BFS), 깊이우선탐색(DFS))
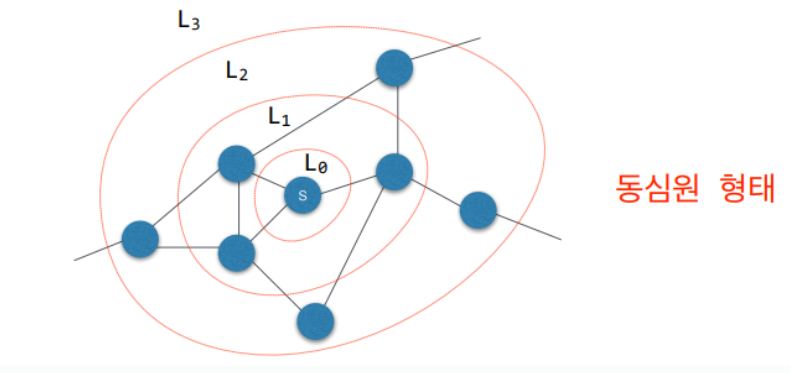
그래프를 순회하는 방법에는 크게 BFS와 DFS가 있다. 1. 너비우선탐색 (BFS) BFS는 시작 정점에서부터 출발하여 인접한 정점들부터 차례대로 방문하는 탐색 방법이다. $L0$에서 시작하여 시작 노드와 가장 인접한 $L1$의 노드들을 차례대로 방문한다. $L