배경
- 현재 재직중인 회사에서 담당하고 있는 상품권서비스에는
spring-batch 4.3.7버전으로 배치 애플리케이션이 구성되어 있습니다. Transactional Outgbox pattern을 도입하기 위해 다음과 같은 테이블에 쌓인 메시지들은 생성된순서대로 발행하는 배치 Job을 개발해야 했습니다.

- 개발계에서 수월한 테스트를 위해 임시 데이터를 입력받은 개수만큼 다음과 같이
Insert하는Procedure를 만들었습니다.
INSERT INTO outbox(..., created_at) VALUES (..., NOW())문제
- 메시지의 발행 순서를 보장하기 위해 created_at(생성일시) 컬럼을 기준으로 sort하여 읽어왔습니다.
- 다음과 같이
Query Provider를 만들었더니,JdbcPagingItemReader의chunk size만큼만 데이터가 처리되는 현상이 발생했습니다.ex) chunk size: 10, 테스트 데이터: 90개인 경우,
10개씩 9번 처리되어 90개가 모두 처리되기를 기대했으나, 10개만 수행되고 Job이 종료되었습니다.
val provider = SqlPagingQueryProviderFactoryBean()
provider.setDataSource(dataSource)
provider.setSelectClause("""
SELECT
t1.id, t1.message_payload, t1.message_topic, t1.message_status,
t1.try_count, t1.created_at
""".trimIndent())
provider.setFromClause("""
FROM outbox t1
""".trimIndent())
provider.setWhereClause("""
WHERE 1=1
-- .. 중략
AND t1.created_at BETWEEN :startDateTime AND :endDateTime
""".trimIndent())
provider.setSortKeys(mapOf("t1.created_at" to Order.ASCENDING))
return provider.`object`원인 파악
실행된 쿼리 확인
- 처음 개발할 때,
JdbcPagingItemReader가 read할 때 MySQL의offset, limit을 활용해 페이징 쿼리를 생성할 것으로 예상했습니다. - 하지만 실제로 로그에 찍힌 쿼리는 다음과 같았습니다.
첫 페이지 조회 쿼리
SELECT
-- .. 중략
FROM
outbox t1
WHERE 1=1
-- .. 중략
AND t1.created_at BETWEEN :startDateTime AND :endDateTime
ORDER BY t1.created_at ASC LIMIT 100다음 페이지 조회 쿼리
SELECT
-- .. 중략
FROM
outbox t1
WHERE (1=1
-- .. 중략
AND t1.created_at BETWEEN :startDateTime AND :endDateTime)
AND ((t1.created_at > :_t1.created_at))
ORDER BY t1.created_at ASC LIMIT 100PagingQueryProvider 인터페이스
spring-batch에서는 DB의존성을 최소화하기 위해 각 DB별로PagingQueryProvider구현체를 제공합니다.ex) SqlPagingQueryProviderFactoryBean 클래스의 생성자
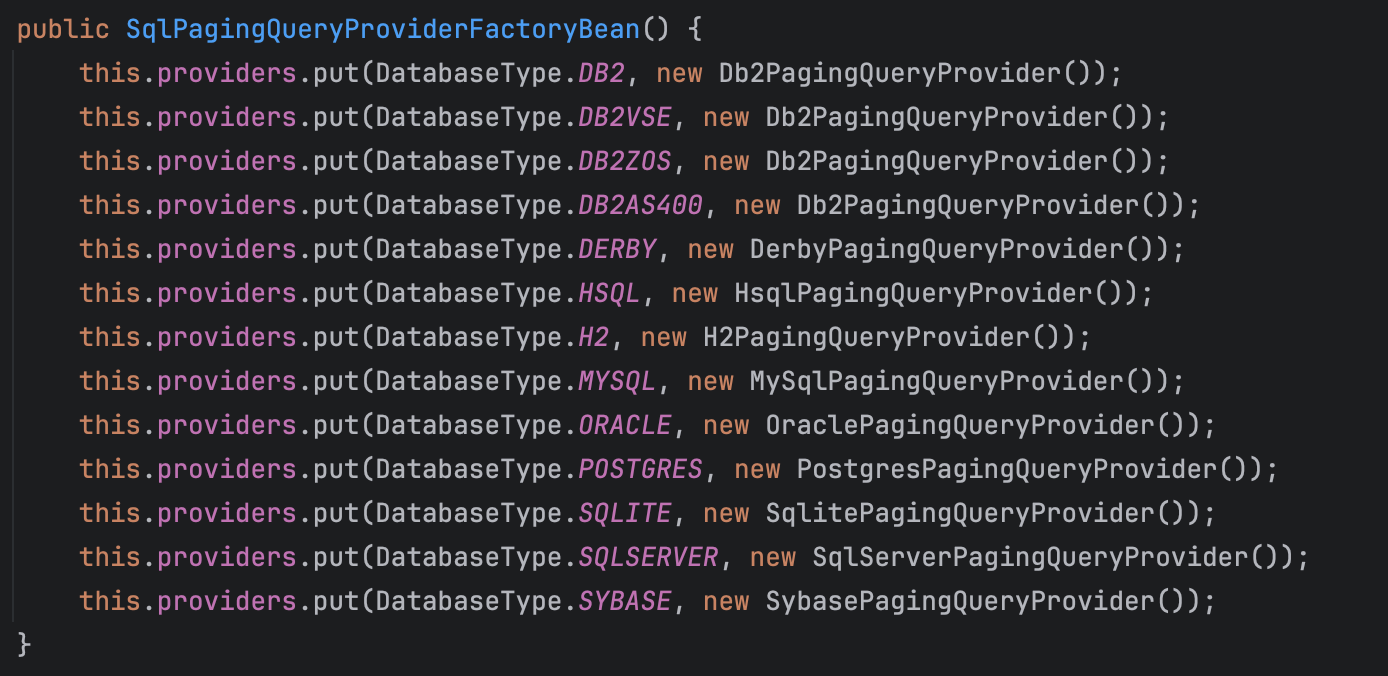
JdbcPagingItemReader bean과 sql
-
저는
ItemReader를@StepScope로 만들었기 때문에, 매번 Step이 실행될 때 ItemReader bean이 생성됩니다. -
JdbcPagingItemReader의 bean 이 생성된 뒤,firstPageSql(첫 페이지 조회 쿼리)와remainingPageSql(나머지 페이지 조회 쿼리)가 초기화됩니다.JdbcPagingItemReader 클래스
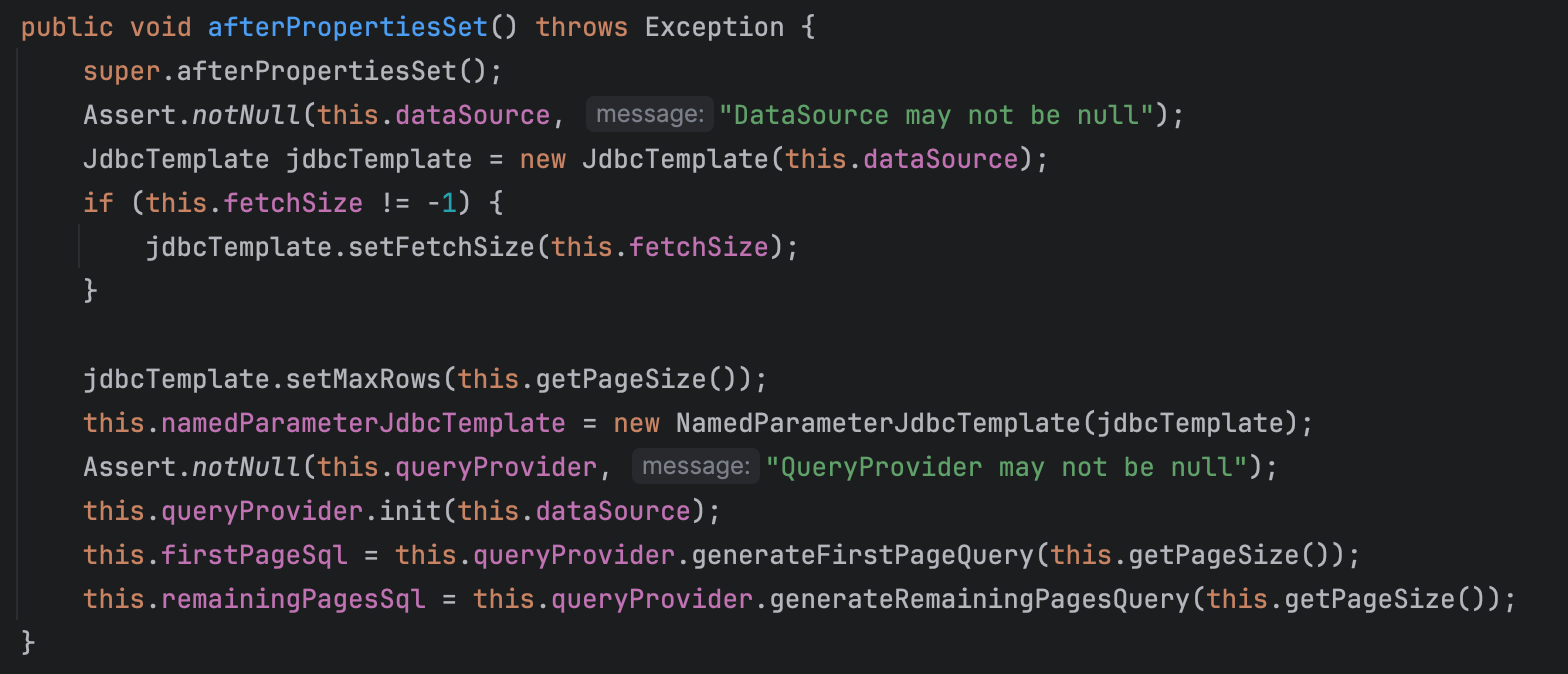
-
where 조건으로 paging하는 쿼리가
this.queryProvider.generateRemainingPagesQuery(this.getPageSize())
여기서 생성되기 때문에, 이부분을 살펴보았습니다.
쿼리 생성 과정 살펴보기
MySqlPagingQueryProvider
MySqlPagingQueryProvider 에 들어가보면 다음과 같이 쿼리를 생성하는 메서드가 다음과 같이 두 개 있습니다.
// 좌우로 길어서 캡처하지 못하고, 소스코드를 직접 복붙했습니다.
public class MySqlPagingQueryProvider extends AbstractSqlPagingQueryProvider {
// .. 중략
public String generateFirstPageQuery(int pageSize) {
return SqlPagingQueryUtils.generateLimitSqlQuery(this, false, this.buildLimitClause(pageSize));
}
public String generateRemainingPagesQuery(int pageSize) {
return StringUtils.hasText(this.getGroupClause()) ? SqlPagingQueryUtils.generateLimitGroupedSqlQuery(this, true, this.buildLimitClause(pageSize)) : SqlPagingQueryUtils.generateLimitSqlQuery(this, true, this.buildLimitClause(pageSize));
}
// .. 중략제 경우, group by 구문이 없기 때문에 SqlPagingQueryUtils.generateLimitSqlQuery()메서드에서 쿼리가 생성되고 있습니다.
SqlPagingQueryUtils
SqlPagingQueryUtils 클래스를 타고 들어가면 다음과 같은 메서드가 있습니다.
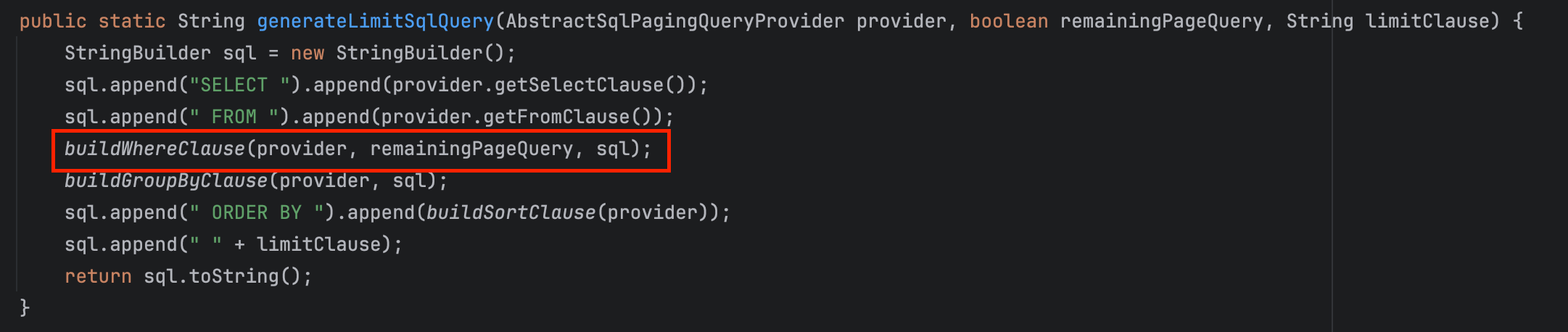
로그에 찍힌 쿼리에서는 where 조건 아래에 paging 하는 부분이 있었기 때문에, buildWhereClause 메서드로 들어가 봅시다.
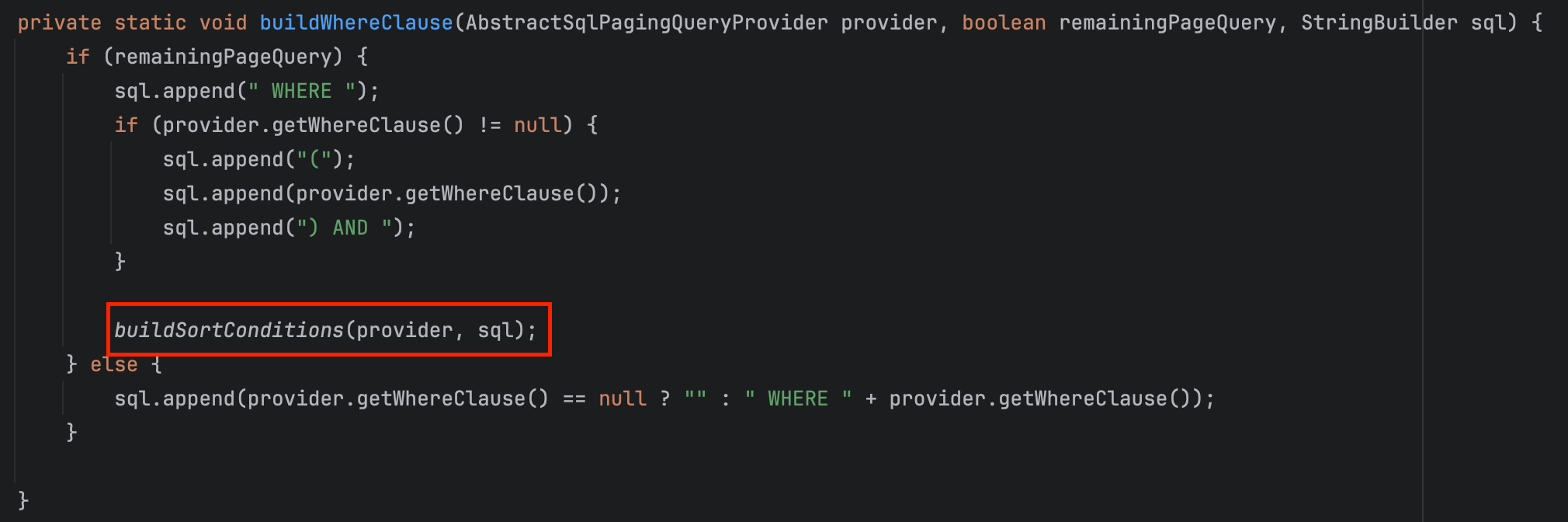
여기서 정렬조건을 기반으로 paging하는 쿼리를 다음과 같이 생성하고 있습니다.
// 좌우로 길어서 캡처하지 못하고, 소스코드를 직접 복붙했습니다.
public static void buildSortConditions(AbstractSqlPagingQueryProvider provider, StringBuilder sql) {
List<Map.Entry<String, Order>> keys = new ArrayList(provider.getSortKeys().entrySet());
List<String> clauses = new ArrayList();
String prefix;
for(int i = 0; i < keys.size(); ++i) {
StringBuilder clause = new StringBuilder();
prefix = "";
for(int j = 0; j < i; ++j) {
clause.append(prefix);
prefix = " AND ";
Map.Entry<String, Order> entry = (Map.Entry)keys.get(j);
clause.append((String)entry.getKey());
clause.append(" = ");
clause.append(provider.getSortKeyPlaceHolder((String)entry.getKey()));
}
if (clause.length() > 0) {
clause.append(" AND ");
}
clause.append((String)((Map.Entry)keys.get(i)).getKey());
if (((Map.Entry)keys.get(i)).getValue() != null && ((Map.Entry)keys.get(i)).getValue() == Order.DESCENDING) {
clause.append(" < ");
} else {
clause.append(" > ");
}
clause.append(provider.getSortKeyPlaceHolder((String)((Map.Entry)keys.get(i)).getKey()));
clauses.add(clause.toString());
}
sql.append("(");
String prefix = "";
Iterator var10 = clauses.iterator();
while(var10.hasNext()) {
prefix = (String)var10.next();
sql.append(prefix);
prefix = " OR ";
sql.append("(");
sql.append(prefix);
sql.append(")");
}
sql.append(")");
}발생한 이슈의 원인
위에서 찾은 대로 페이징쿼리가 실제로는 다음과 같이 생성됩니다.
SELECT
-- .. 중략
FROM
outbox t1
WHERE (1=1
-- .. 중략
AND t1.created_at BETWEEN :startDateTime AND :endDateTime)
AND ((t1.created_at > :_t1.created_at))
ORDER BY t1.created_at ASC LIMIT 100- 이 때, t1.created_at 이 가진 시간 정보가 초(second)까지밖에 없습니다.
- 제가
PL/SQL로 만든 테스트데이터는 now()를 사용했기 때문에 몇개의 데이터가 생성되던 같은 초(second)를 가지고 있었습니다. - 초(second)가 같기 때문에 첫번째 chunk 까지만 수행되고 이후에는 where 조건에서 걸러졌습니다.
해결
outbox테이블의 PK를auto_increment로 생성하고 있었기 떄문에, 단순히 정렬조건을 id로 바꾸니 문제가 해결되었습니다.- spring-batch 공식문서에서도 다음과 같이
sortKey는unique Key constraint를 가져야 한다고 설명하고 있습니다.

왜 where로 페이징을 할까..?
- offset과 limit을 사용하는 쿼리를 실행하면, where조건을 만족하는 데이터 중
offset + limit만큼 데이터를 가져온 뒤 거기서limit까지만 보여주도록 되어있습니다. - 즉,
지금은 필요없는 앞페이지의 데이터까지 모두 조회하기 때문에 성능 상 disadvantage가 있습니다
사내 블로그 투고!!
이 글에서 해결했던 이슈와, 그 이후 새롭게 해결한 이슈를 합쳐 사내 블로그에 투고했습니다.
혼자 파고들어 알게된 지식을 동료들과 공유한다고 생각하니 묘한 기분이 들어서 좋았습니다 :)
