Elasticsearch를 이용한 자동 완성 프로그램 만들기 - Elasticsearch java low level client with Spring
Elasticsearch
- 사용하는 elasticsearch와 kibana의 버전은 8.11.1입니다
1-1. 8.x 버전 끼리는 크게 차이 없을 것으로 예상되나 이외의 버전에서 진행에 문제가 생긴다면 반드시 검색을 통해 확인해 봐야합니다- 사용하는 Spring Boot의 버전은 3.1.2입니다
- 사용하는 Java의 버전은 17입니다
이번 글에서는 필자가 Java Spring에서 Elasticsearch java low level client를 사용한 방법과 그를 이용해 Search Query를 보낸 코드에 대해 간략하게 설명하겠다.
필자의 elasticsearch 세팅이 궁금하다면 해당 시리즈의 앞에 글들을 참고하면 될 것이다.
의존성 설치
의존성 설치는 이전 글(의존성-설치)에 설명해 두었으니 해당 글을 확인하고 글을 읽어주길 바란다.
들어가기 전에 발생할 수 있는 오류
Spring Boot 3.x와 Elasticsearch 8.9.x+를 함께 사용했을 때,Bean을 등록하는 과정에서 생성자가 충돌하는 문제가 발생할 수 있다.
관련 설명은 이전 글(spring-사용시-발생할-수-있는-오류)에서 했기 때문에 이번 글에서는 주의 사항으로만 알리고 다음으로 넘어가겠다.
혹시 바로 관련 이슈로 넘어가고 싶다면 다음 링크1, 링크2를 보면된다.
해결법
필자도 해당 오류에서 자유롭지 못했다..ㅎ
따라서 아래와 같이 @SpringBootApplication에 충돌하는 2개의 생성자 중 한 쪽, 즉 springframework의 elsticsearch 자동 설정을 제외해주면 정상적으로 작동한다.
@SpringBootApplication(exclude = org.springframework.boot.autoconfigure.elasticsearch.ElasticsearchClientAutoConfiguration.class)
public class BookSearchingApplication {
public static void main(String[] args) {
SpringApplication.run(BookSearchingApplication.class, args);
}
}ElasticSearchClientConfig
Elasticsearch java low level client는 client를 생성하기 위해 넣어줘야하는 값이나 해줘야하는 설정이 은근히 있다.
API Key나 ID, Password 그리고 TLS/SSH 암호화 통신을 이용하는 경우 인증서까지 추가로 필요하다 이짓을 매번 할 수 없으니 bean으로 등록해두고 사용하기 위해 작성한 Configuration이다.
package com.example.booksearching.spring.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.TransportUtils;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.Header;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.elasticsearch.client.RestClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig
{
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private Integer port;
@Value("${elasticsearch.username}")
private String username;
@Value("${elasticsearch.password}")
private String password;
@Value("${elasticsearch.encodedApiKey}")
String encodedApiKey;
@Value("${elasticsearch.fingerprint}")
String fingerprint;
CredentialsProvider credentials = new BasicCredentialsProvider();
@Bean
public RestClient getRestClient() {
// credential(ID, Password) 정보 생성
credentials.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
return RestClient.builder(
new HttpHost(host, port, "https"))
.setDefaultHeaders(new Header[]{
new BasicHeader("Authorization", "ApiKey " + encodedApiKey) // 헤더에 API Key 추가
})
.setHttpClientConfigCallback(httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(TransportUtils.sslContextFromCaFingerprint(fingerprint)) // 인증서 추가
.setDefaultCredentialsProvider(credentials) // credential 추가
)
.build();
}
@Bean
public ElasticsearchTransport getElasticsearchTransport() {
return new RestClientTransport(getRestClient(), new JacksonJsonpMapper());
}
@Bean
public ElasticsearchClient getElasticsearchClient() {
return new ElasticsearchClient(getElasticsearchTransport());
}
}
Java에서 쿼리 작성하고 보내기 / 결과 받기
GitHub 링크
Elasticsearch java low level client는 공식 문서를 찾아보면 메서드의 매개변수나 반환 값 정도는 찾아 볼 수 있을 것이다.
그러나 각 메서드 관련한 예시나 설명은 "일절" 존재하지 않기 때문에 공식문서나 메서드의 코드를 직접보고 익히거나 구글링이나 해당 메서드의 정의를 AI에게 가져가서 물어보면 사용법 정도는 알 수도 있다.
필자는 우선 쿼리를 작성한다음 해당 쿼리를 기반으로 Elasticsearch java low level client에서 최대한 비슷하게 했겠거니하는 생각을 바탕으로 AI한테 메서드 작성법도 물어보고 시간도 박아가며 작성한 코드이다...ㅎㅎ
package com.example.booksearching.spring.service;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch._types.ElasticsearchException;
import co.elastic.clients.elasticsearch._types.query_dsl.DisMaxQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.MatchPhraseQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.MatchQuery;
import co.elastic.clients.elasticsearch._types.query_dsl.Query;
import co.elastic.clients.elasticsearch.core.SearchRequest;
import co.elastic.clients.elasticsearch.core.SearchResponse;
import co.elastic.clients.elasticsearch.core.search.*;
import com.example.booksearching.elasticsearch.model.BookDocument;
import com.example.booksearching.spring.dto.BookSearchResponse;
import com.example.booksearching.spring.entity.Book;
import com.example.booksearching.spring.exception.ElasticsearchCommunicationException;
import com.example.booksearching.spring.exception.ElasticsearchCommunicationExceptionType;
import com.example.booksearching.spring.repository.BookRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.*;
import java.util.stream.Collectors;
@Slf4j
@RequiredArgsConstructor
@Transactional
@Service
public class BookService {
private final ElasticsearchClient esClient;
public List<BookSearchResponse> searchBookTitles(String keyword) {
final String BOOK_INDEX = "books";
final String FIELD_NAME = "title";
final Integer SIZE = 10;
final Float KEYWORD_BOOST_VALUE = 2f;
final Float PHRASE_BOOST_VALUE = 1.5f;
final Float LANGUAGE_BOOST_VALUE = 1.2f;
final Float DEFAULT_BOOST_VALUE = 1f;
final Float PARTIAL_BOOST_VALUE = 0.5f;
String[] fieldSuffixes = containsKorean(keyword) ? new String[]{"", "_chosung", "_jamo"} : new String[]{"", "_engtokor"};
Map<String, Float> boostValueByMultiFieldMap = Map.of(
"", KEYWORD_BOOST_VALUE,
".edge", DEFAULT_BOOST_VALUE,
".partial", PARTIAL_BOOST_VALUE
);
List<Query> queryList = new ArrayList<>(createMatchQueryList(FIELD_NAME, fieldSuffixes, boostValueByMultiFieldMap, keyword).stream().map(MatchQuery::_toQuery).toList());
String languageField = FIELD_NAME + (containsKorean(keyword) ? ".kor" : ".en");
queryList.add(createMatchQuery(keyword, languageField, LANGUAGE_BOOST_VALUE)._toQuery());
queryList.add(createMatchPhraseQuery(keyword, languageField, PHRASE_BOOST_VALUE)._toQuery());
DisMaxQuery disMaxQuery = new DisMaxQuery.Builder()
.queries(queryList)
.build();
// Highlight 생성
Highlight highlight = createHighlightFieldMap(List.of(FIELD_NAME, FIELD_NAME + ".en", FIELD_NAME + ".kor", FIELD_NAME + ".edge", FIELD_NAME + ".partial"));
SearchRequest searchRequest = new SearchRequest.Builder()
.index(BOOK_INDEX)
.size(SIZE)
.query(queryBuilder -> queryBuilder.disMax(disMaxQuery))
.highlight(highlight)
.build();
SearchResponse<BookDocument> response = null;
try {
response = esClient.search(searchRequest, BookDocument.class);
} catch (ElasticsearchException e) {
// 클라이언트에 보기좋게 던지기 위한 사용자 정의 예외, 공식 X
throw new ElasticsearchCommunicationException(ElasticsearchCommunicationExceptionType.ELASTICSEARCH_SEARCH_FAIL);
} catch (IOException e) {
// 클라이언트에 보기좋게 던지기 위한 사용자 정의 예외, 공식 X
throw new ElasticsearchCommunicationException(ElasticsearchCommunicationExceptionType.ELASTICSEARCH_IO_FAIL);
}
TotalHits total = response.hits().total();
assert total != null;
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
log.info("There are " + (isExactResult ? "" : "more than ") + total.value() + " results");
List<Hit<BookDocument>> hits = response.hits().hits();
List<BookSearchResponse> res = hits.stream().map(BookSearchResponse::from).toList();
log.info("Search result: {{}}", res.stream().map(BookSearchResponse::toString).collect(Collectors.joining(",\n")));
return res;
}
private boolean containsKorean(String text) {
return (text != null) && text.matches(".*[ㄱ-ㅎㅏ-ㅣ가-힣]+.*");
}
private List<MatchQuery> createMatchQueryList(String fieldName, String[] fieldSuffixes, Map<String, Float> boostValueByMultiFieldMap, String keyword) {
return Arrays.stream(fieldSuffixes)
.flatMap(fieldSuffix -> boostValueByMultiFieldMap.entrySet().stream()
.map(boostValueByMultiFieldEnt -> {
String multiField = boostValueByMultiFieldEnt.getKey();
Float boostValue = boostValueByMultiFieldEnt.getValue();
return createMatchQuery(keyword, fieldName + fieldSuffix + multiField, boostValue);
}))
.collect(Collectors.toList());
}
private MatchQuery createMatchQuery(String keyword, String fieldName, Float boostValue) {
return new MatchQuery.Builder()
.query(keyword)
.field(fieldName)
.boost(boostValue)
.build();
}
private MatchPhraseQuery createMatchPhraseQuery(String keyword, String fieldName, Float boostValue) {
return new MatchPhraseQuery.Builder()
.query(keyword)
.field(fieldName)
.boost(boostValue)
.build();
}
// https://stackoverflow.com/questions/71351777/how-to-explicitly-order-highlighted-fields-using-elasticsearch-java-api-client
private Highlight createHighlightFieldMap(List<String> fieldNames) {
Map<String, HighlightField> highlightFieldMap = new HashMap<>();
for (String fieldName : fieldNames) {
highlightFieldMap.put(
fieldName,
new HighlightField.Builder().postTags("</strong>").preTags("<strong>").build()
);
}
return new Highlight.Builder().fields(highlightFieldMap).build();
}
}
우선 필자가 작성한 쿼리는 바로 이전 글에서 확인 할 수 있듯이 검색어에 한글이 포함되어 있냐 없냐에 따라 검색 대상이 되는 필드가 다르다.
기본적으로 title과 관련 필드를 대상으로하며 관련 필드들은 뒤에 _를 통해 필드명이 추가되기 때문에 String[] fieldSuffixes에 저장했다.
또, 한글이 포함된 쿼리, 그렇지 않은 쿼리 양쪽다 공통으로 사용하는 Multi Field에 대해서는 Map<String, Float> boostValueByMultiFieldMap에 Boost Value와 매핑하여 저장해서 하드 코딩을 조금이라도 줄이고자 했다.
Multi Field 중 공통된 부분은 Map<String, Float> boostValueByMultiFieldMap으로 빼뒀지만 그렇지 못한 .kor와 .en은 직접 작성해서 추가했다.
createMatchQueryList
다른 메서드들은 설명이 딱히 필요 없어 보이는데 해당 메서드만 좀 복잡해 보여서 간단히 설명을 추가한다.
private List<MatchQuery> createMatchQueryList(String fieldName, String[] fieldSuffixes, Map<String, Float> boostValueByMultiFieldMap, String keyword) {
return Arrays.stream(fieldSuffixes)
.flatMap(fieldSuffix -> boostValueByMultiFieldMap.entrySet().stream()
.map(boostValueByMultiFieldEnt -> {
String multiField = boostValueByMultiFieldEnt.getKey();
Float boostValue = boostValueByMultiFieldEnt.getValue();
return createMatchQuery(keyword, fieldName + fieldSuffix + multiField, boostValue);
}))
.collect(Collectors.toList());
}앞서 정의한 String[] fieldSuffixes, Map<String, Float> boostValueByMultiFieldMap 을 이용해 모든 경우의 수를 조합하여 Match Query를 생성한다.
이때, BoostValue는 Multi Field명에 따라 간다.
Query 자료형
위에 코드를 보면 알겠지만 쿼리를 생성하는 모든 코드가 Builer패턴으로 작성되어있다.
Elasticsearch에 Json으로 쿼리를 작성해서 보내는 것과 1대1 대응시켜 작성하도록 의도한 것으로 보인다.
따라서 어떻게 코드를 작성해야 할지 모르겠다면, 먼저 쿼리를 작성하고 해당 쿼리를 그대로 옮겨온다는 생각으로 작성하는 것이 편할 것이다.
추가로, 여러가지 쿼리가 존재하지만 놀랍게도 MatchQuery, DisMaxQuery, BoolQuery 등등 모든 쿼리는 Query 클래스를 상속받지 않는다!
대신 QueryVariant라는 interface를 구현해 _toQuery 메서드를 통해 Query로 변환 할 수 있게 만들었다.
대부분의 Builder의 query 메서드는 Query 자료형만을 매개변수로 받기 때문에 주의해야한다.
Request
자신이 원하는 Request의 종류와 맞는 클래스를 찾아서 실제 쿼리를 작성하듯 작성하면 된다.
Request 관련 클래스는 Elasticsearch에 실제로 요청을 보낼 수 있는 만큼 많이 존재하기 때문에 필요한 요청이 있다면 RequestBase 공식문서에서 해당 클래스를 상속하는 클래스 중 찾아서 작성하면 될 것 같다.
Response
Response는 반대로 별에 별 정보가 다 담겨있다.
아래는 모든 Response가 상속받는 ResponseBody의 생성자이다.
여기서 필요한 정보가 있다면, getter를 통해 대부분 얻어 낼 수 있을 것이다.
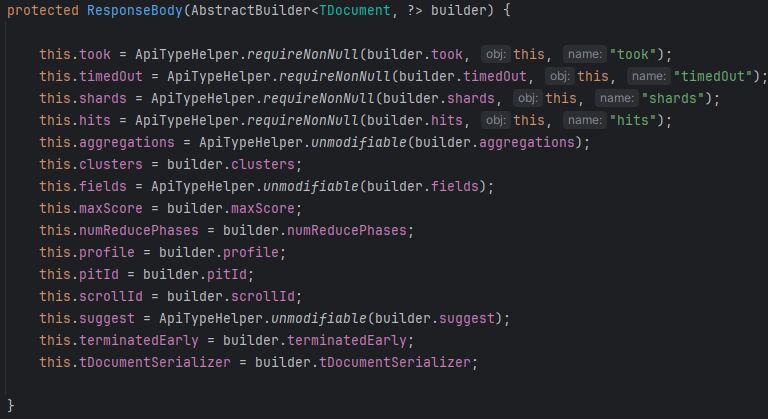
이외에 검색 결과는 ResponseBody의 private final HitsMetadata<TDocument> hits;에 담긴다.
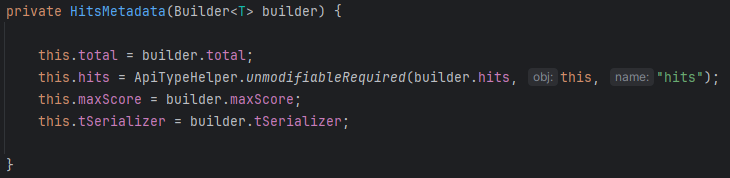
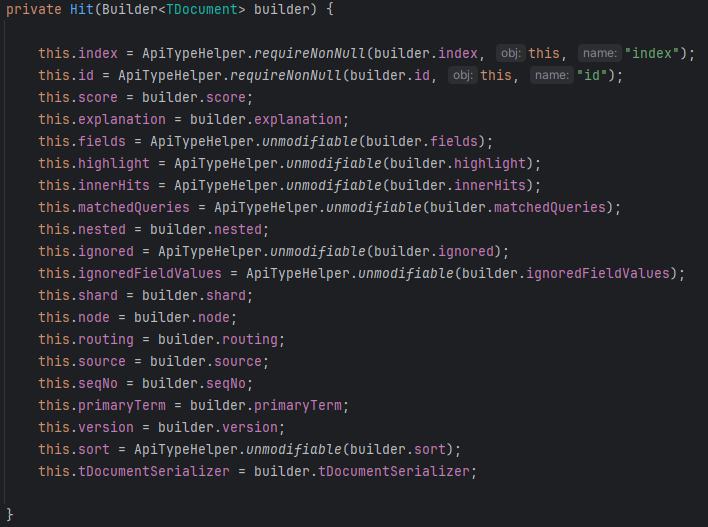
필자는 관련 검색 결과를 @Entity로 받고 DTO인 BookSearchResponse로 변환해 클라이언트에 던져줬다.
마무리
뭔가.. 뭔가.. 잘 설명해보고 싶은데 설명하자니 끝도 없을 것 같고, 모든 것에 대해 자세히 설명도 못할 것 같아 두루뭉실하게 설명한 글이 되어버렸다.
꽤 많은 시간을 박아서 작성한 코드이긴한데 설명하려니까 짧게 끝나기도하고...
그래도 이 불친절한 Elasticsearch java low level client를 사용하고 싶은데 방법을 모르는 누군가에게는 도움이 되었으면 좋겠다.
