과제
1️⃣문제1. 배송 지연 고객 분석
배송 지연은 고객 만족도에 큰 영향을 미칠 수 있습니다. 특히, 여러 번 주문을 한 고객들이 예상 배송일보다 실제 배송이 늦어진 경우, 이들은 브랜드에 대한 충성도가 높을 수 있으므로 특별한 주의가 필요합니다.
이번 과제는 예상 배송일보다 실제 배송을 늦게 받은 고객들 중에서, 가장 많은 주문을 한 고객을 찾아내는 것입니다. 이 고객들은 배송 서비스 개선이나 VIP 혜택을 제공하기 위한 중요한 대상이 될 수 있습니다.
문제
예상 배송일보다 실제 배송을 늦게 받은 고객들 중에서, 가장 많은 주문을 한 고객의 ID와 총 주문 수를 조회하세요.
- 결과 컬럼: customer_id, total_orders
나의 해결 방안
접근방식 :
1. marketer_orders 테이블에서
2. 예상 배송일 실제 배송일 확인 하고 늦은고객 확인
3. 제일많이 주문한 고객 > 어떻게? 중복검사 해야할것 같음> 행 이름을 주문횟수로 지정해야할 듯
필요한 colum
1. order_estimated
2. order_delivered customer
3. order approved
point 1. 예상 배송일 보다 실제 배송이 늦게 받은 고객 확인
2. 그 중에서 가장 많은 주문을 한 고객을 찾아내는것
순서
where > group by > order by > limit
2회차 시도
SELECT customer_id,
COUNT(*)
FROM marketer_orders mo
where order_estimated_delivery_date < order_delivered_customer_date
GROUP BY order_approved_at
LIMIT 1;
시도이유 :
1. count로 센다
2. 그리고 where 에서 예상 도착일 < 진짜도착일 로 배송 지연된거 걸러줌
3. 그룹바이 + 카운트 집계 함수로 승인된 내역 중
4. limit으로 가장 큰 하나만 뽑으려고 했음.

피드백 ---- 정답률 55%
내 산출 값과 정답 값은 똑같음
그러나 나는 group by를 order_approved_at 즉 승인 날짜로 잡았고
limimt1을 했음으로 최신날짜가 나오게됨 그러니까 한마디로 얻어걸림.
- 문제의 요지는 가장 많은 주문을 한 고객을 찾아내는 것임으로
2, group by를 customer_id로
3차 시도
SELECT customer_id,
COUNT(*) AS total_orders
FROM marketer_orders mo
where order_estimated_delivery_date < order_delivered_customer_date
GROUP BY customer_id
LIMIT 1;
결과 :

값은 똑같다 ;;; 어쩄든
피드백 : 정답율 85%
- 현재 가장 큰 값 아님
- 왜냐면 order by로 정렬을 하지않았기에 LIMIT1 으로 구한게 어떤 기준인지 알 수 없음(my sql 내부정렬)
- 그렇기 때문에 order by로 내림차순 정렬 해줘야함
쿼리 순서 1. where 2. group by 3. order by 4. limit
4차시도 :
SELECT customer_id,
COUNT(*) AS total_orders
FROM marketer_orders mo
where order_estimated_delivery_date < order_delivered_customer_date
GROUP BY customer_id
ORDER BY total_orders DESC
LIMIT 1;
피드백 : 정답율 100%
시도 1
SELECT payment_type,
SUM(payment_value) over group by payment_type
FROM marketer_payments mp;
피드백 : 정답율 40퍼
근데 말도안됨
1. SUM over~ 문법 틀림
시도 2
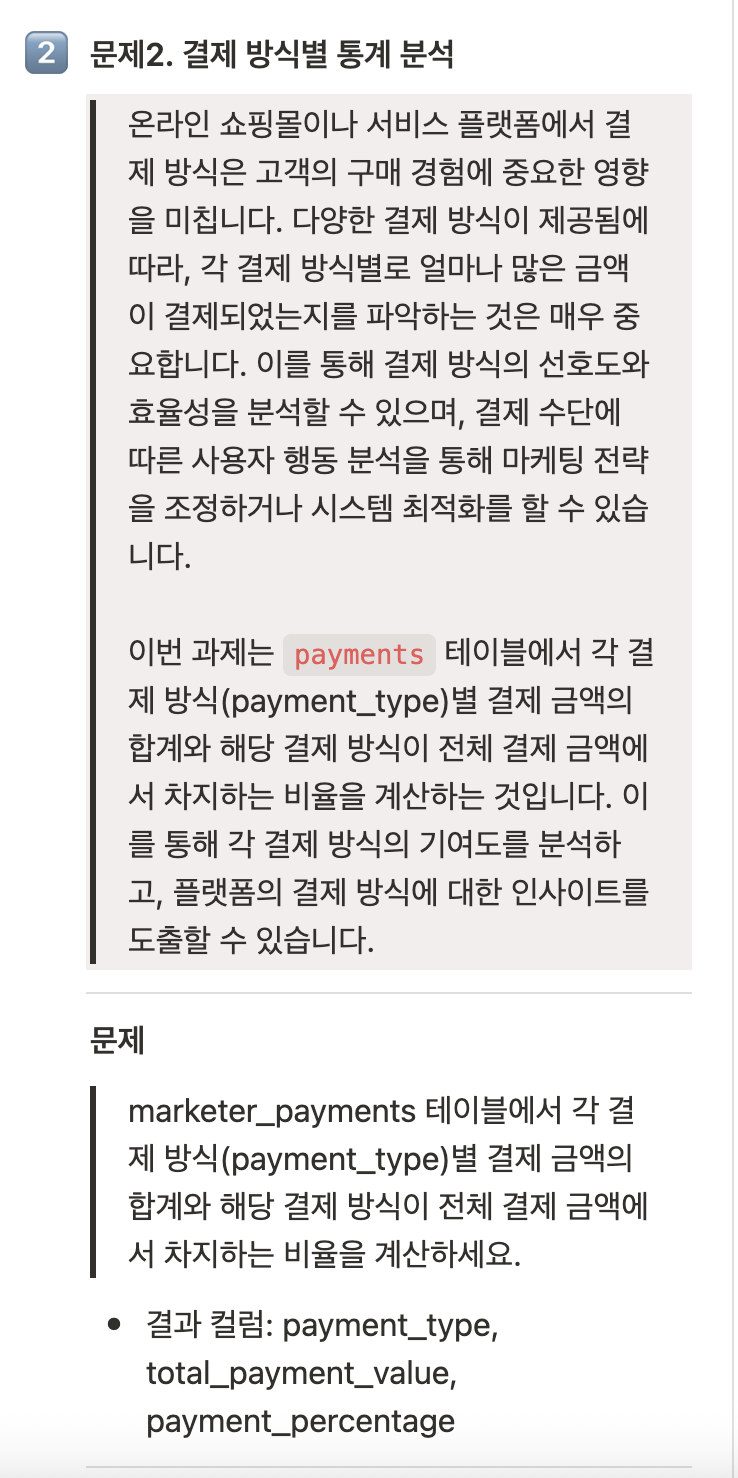
SELECT payment_type,
SUM(payment_value)
FROM marketer_payments mp
GROUP BY payment_type;
피드백 : 정답율 70퍼
1. payment_ type 별로 묶고
2. sum(payment_value)
3. group by로 payment_type별 산출
이제 남은건 전체 얼마를 차지하는지 구하면됨.
시도 3
관건은 각 결제방식 주문금액이 전체의 몇퍼센트인지를 나타내는 payment_percentage 구하기
SELECT payment_type,
SUM(payment_value),
SUM(payment_value)/ GROUP BY payment_type
FROM marketer_payments mp
GROUP BY payment_type;
오류
피드백 : 75퍼
1. 나누는 구문이 문법 오류 group by는 연산자뒤에 쓸 수 없음
2. 전체값을 불러와서 개별로 나눠봐야하는데...
시도 4
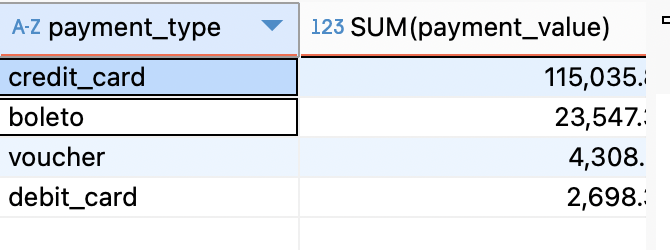
SELECT payment_type,
SUM(payment_value) AS total_payment_value,
SUM(payment_value) / (SELECT SUM(payment_value) FROM marketer_payments) * 100
FROM marketer_payments mp
GROUP BY payment_type;
피드백 : 정답율 99퍼
해설 1.
select payment_type
2. sum(payment_value) AS total_payment_value 더하고 나중에 group by로 개별합으로 분류 count() 후 나누는거랑 똑같.
3. SUM(payment_value) <<개별합 / (SELECT SUM(payment_value)
FROM marketer_payments) 100 <<서브쿼리로 전체합을 불러옴
4. GROUP BY payment_type << 여기서 group by로 묶었기때문에 3번의 sum(payment_value) 처럼 그냥 날것으로 나오는건 다 개별합으로 분류 (분자) 한마디로 group by가 개별 값( 전체테이블에서 미니테이블 값으로 바꿔줌)
5. 그렇기때문에 percentage를 구하려면 분자/분모를 해야되고 이미 sum(payment_value)값은 개별값 취급이므로 서브쿼리(하나의 독립적인)로 전체합을 만들어줘야함 > 개별/전체값을 해야함으로
6. 그래서 전체값을 불러오는 서브쿼리문은
(SELECT (SUM (payment_value) FROM marketer_payments) * 100
시도 5
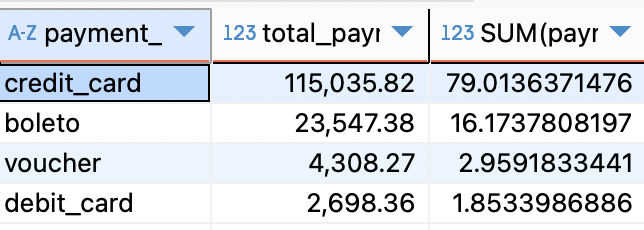
SELECT payment_type,
SUM(payment_value) AS total_payment_value,
ROUND(SUM(payment_value) / (SELECT SUM(payment_value) FROM marketer_payments) * 100, 2) AS payment_percentage
FROM marketer_payments mp
GROUP BY payment_type;
피드백 : 정답율 100퍼
존나게 재밌다.
새로알게된 사실
- GROUP BY는 결국에 어떤 집계 함수를 써도 기준을 알려주는것 그니까 집계 함수, GROUP BY 자체가 중요한게 아니라
- 내가 SUM이든 COUNT 든 어떤 값을 산출한걸 항목별로 보고 싶은면 GROUP BY로 쓰면됨
- 서브 쿼리는 단순히 괄호치고 SELECT, FROM문을 치는것 어렵지않음 괄호안에 넣기만하면됨 가로로)
