서비스를 배포하고 나면 끝나는 것이 아니다. 실제로 배포를 완료하고 운영 단계가 중요하다.
갑자기 잘 떠있던 서비스가 떨어질 수도 있고, 갑자기 트래픽을 못 받을 수도 있고, 리소스가 부하를 못견디는 상태일 수도 있다.
이런 상황을 대비하기 위해서는 모니터링이 필수일 것이다.
시스템 모니터링
주요 모니터링 항목으로는 아래와 같은 것들이 존재한다.
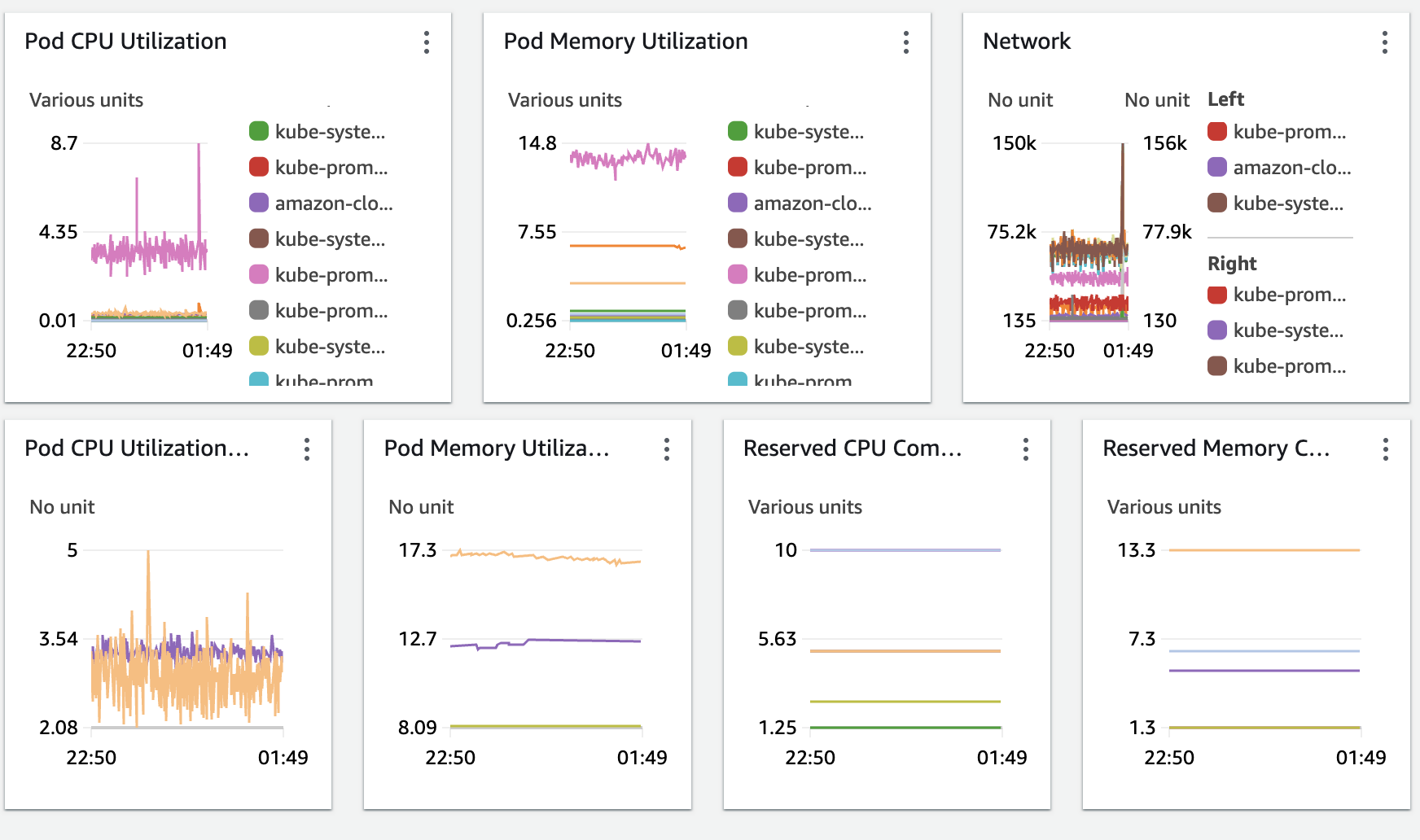
- 생사 모니터링
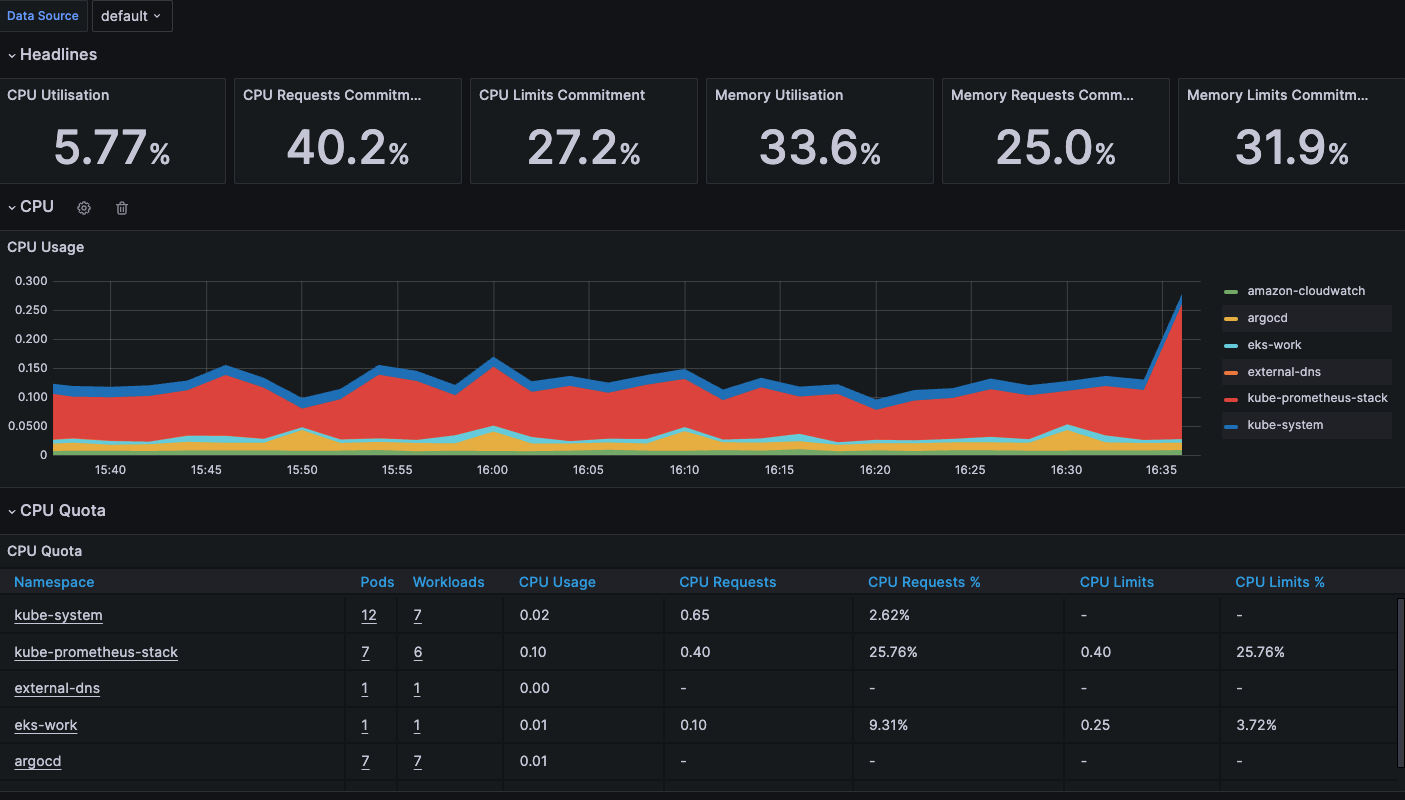
- CPU 사용률
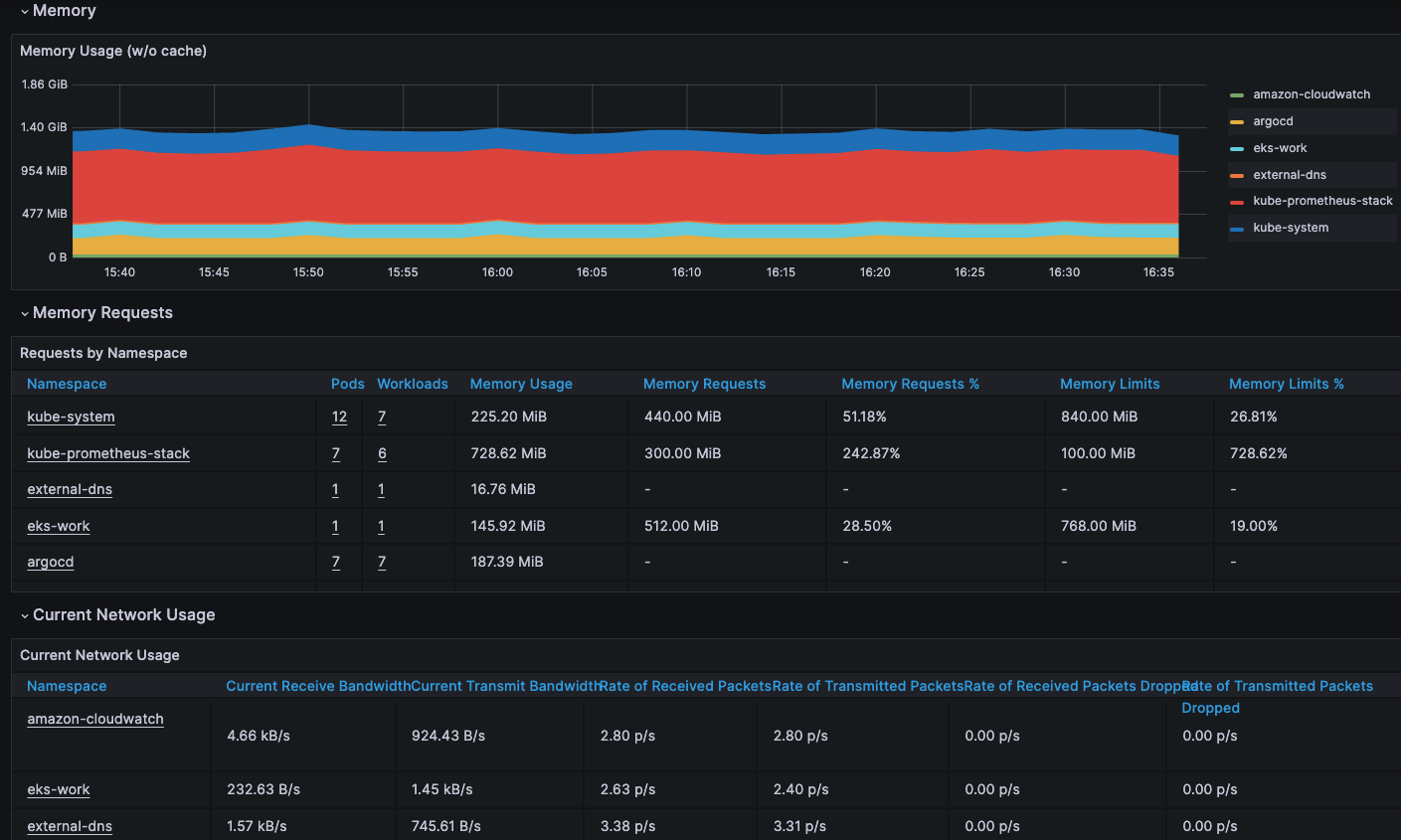
- 메모리 사용률
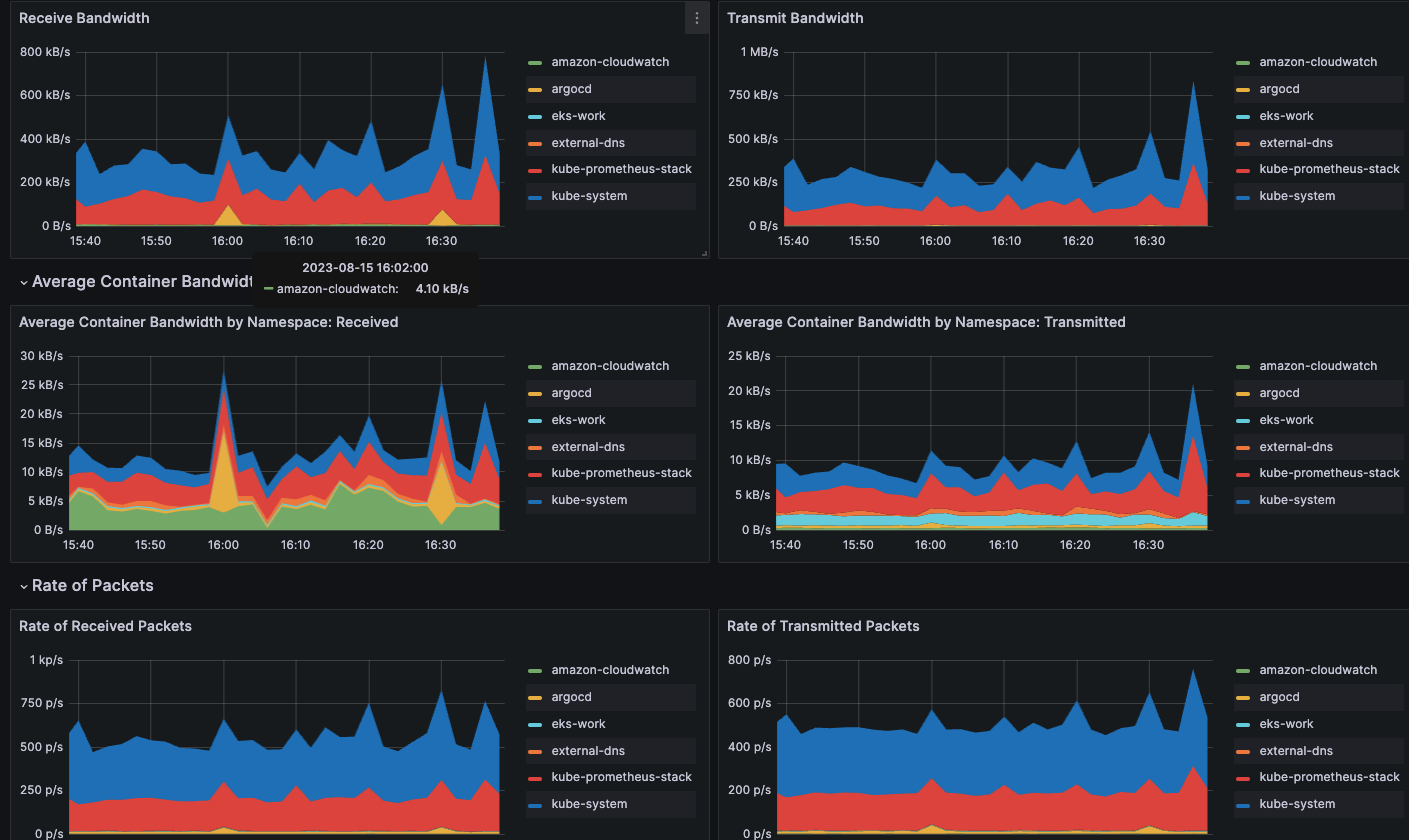
- 네트워크 트래픽
AWS에서는 모니터링 툴로 CloudWatch를 제공하지만, 쿠버네티스를 사용하는 EKS 클러스터 환경에서는 보통 Prometheus와 대시보드로 Grafana를 사용한다.
Prometheus
프로메테우스는 오픈 소스 기반의 모니터링 시스템이다.
시스템의 metric을 수집하여 저장하고 검색할 수 있다.
특히 쿠버네티스의 메인 모니터링 시스템으로 많이 사용되고 있다.
하지만, 대시보드 기능이 존재하지 않는데 Grafana를 통해 이를 해결하게 된다.
CPU
메모리
네트워크
CloudWatch
Prometheus를 주로 사용한다고 CloudWatch가 안좋은 것이 아니다. CloudWatch도 k8s 클러스터 모니터링을 지원하기 때문에 전혀 문제가 되지 않는다.
Container Insights 서비스를 통해 다음과 같은 대시보드를 제공받을 수 있다.
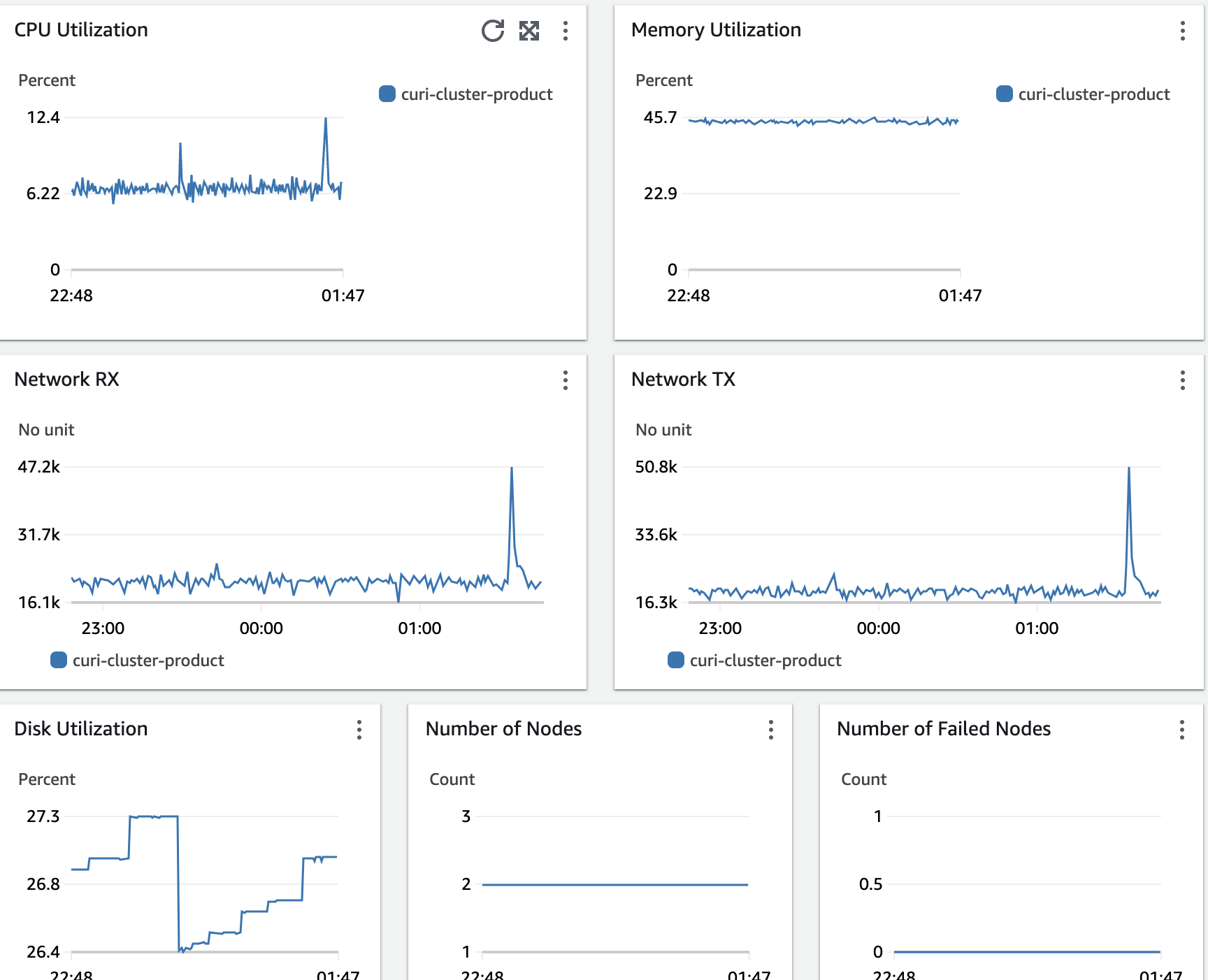
로그 모니터링
시스템 모니터링 뿐만이 아니라, 각 컨테이너에서 돌고 있는 서비스의 정보 또한 모니터링, 수집해야 한다.
오류가 났거나, 어뷰징이 발생한 경우 로그를 기반으로 추적해야하기 때문이다. 로그를 적재적소에 작성하는 것이 1순위이겠지만, 결국에 이 로그가 수집되지 못하면 말짱 도루묵이다.
fluent bit
보통 로그 모니터링 스택으로 ELK를 많이 들어봤을 것이다. 이 중에서 L은 Logstash로 로그 수집의 역할을 하는데, k8s 클러스터 환경에서는 이 역할에 fluent bit를 사용하여 EFK라고 부르기도 한다.
대표적인 로그 수집기중 가장 가볍고, 분산 환경을 고려하여 만들어져 k8s 로그 수집기로 선택하는 경우도 많다고 한다.
EFK로 구현하는 것도 좋겠지만, 러닝 커브가 부담된다면 CloudWatch와 fluent bit를 통해 로그 모니터링 시스템을 구축해도 좋다.

정리가 잘 된 글이네요. 도움이 됐습니다.