Airflow & Timezone
- airflow.cfg에는 두 종류의 타임존 키가 존재한다.
- default_timezone
- default_ui_timezone
start_date, end_date, schedule: default_timezone을 따른다.execution_date, log_time: 항상 UTC를 따른다. → 변환이 필요하다.
Open Weathermap DAG 구현
API key 받기
: https://openweathermap.org/price
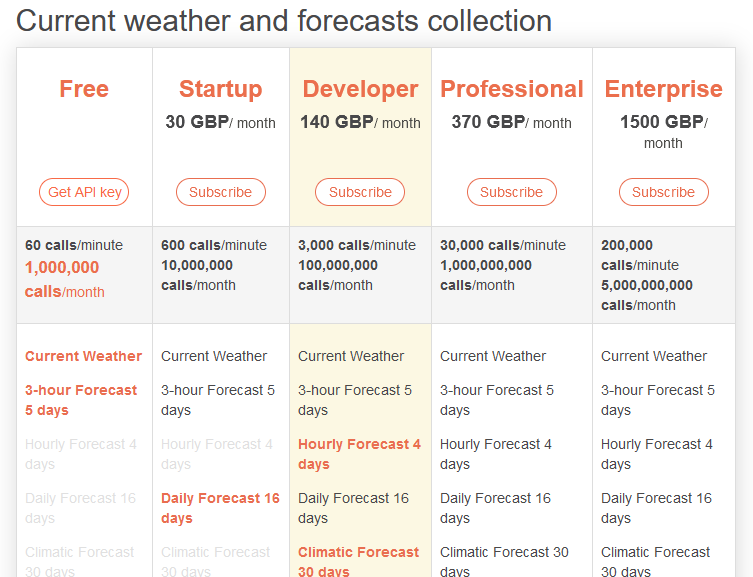
- API 호출 방법 :
https://api.openweathermap.org/data/2.5/onecall?lat={lat}&lon={lon}&exclude={part}&appid={API_key}&units=metric - 테이블 저장 코드
CREATE TABLE schema1.weather_forecast (
date date primary key,
temp float, -- 낮 온도
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);Primary Key Uniqueness 보장하기
Primary Key Uniqueness란?
- 테이블에서 하나의 레코드를 유일하게 지칭할 수 있는 필드(들)
- 다수의 필드 사용도 가능하다.
- CRATE TABLE 사용시에 지정한다.
-- 방식 1
CREATE TABLE pktest(
id INT PRIMARY KEY,
...
);
-- 방식 2
CREATE TABLE pktest(
id INT,
...
PRIMARY KEY(id),
);빅데이터 기반 데이터 웨어하우스들은 PK를 지켜주지 않는다.
- 데이터 인력이 이를 보장해야한다.
- 유일성을 보장하지 않는 이유 : 메모리와 시간이 더 들기 때문에 대용량 데이터의 적재가 걸림돌이 되기 때문이다.
- 보장되지 않는 예시
CREATE TABLE schema.table_name(
date date primary key,
value bigint
);- 아래 작업의 수행에 있어 문제가 없다.
INSERT INTO schema.table_name VALUES ('2023-12-12',100);
INSERT INTO schema.table_name VALUES ('2023-12-12',150);PK 보장방법
- create_date 생성 → Date가 같아도 create_date는 다르기 때문에 최근 정보 선택이 가능하다.
CREATE TABLE {schema}.{table} (
date date,
temp float,
min_temp float,
max_temp float,
created_date timestamp default GETDATE()
);- ROW_NUMBER를 사용
- 2개의 컬럼을 사용해서 일련번호를 하고싶다.
- A컬럼별로 레코드를 모으고, 그 안에서 B 컬럼의 역순으로 정렬 후 1번부터 번호를 부여하고 싶은 경우 :
ROW_NUMBER() OVER (partition by A order by B DESC) seq
- 임시 테이블을 사용
- 임시테이블을 이용하여 중복을 체크하고, 제거 후 원본 테이블로 복사
- 임시테이블에 일련번호를 추가해서 사용
- 임시 테이블 추가 :
CREATE TEMP TABLE t AS SELECT * FROM schema.table; - 임시 테이블에 레코드 추가(DAG)
- 기존 테이블 제거 :
DELETE FROM schema.table; - 중복 없는 테이블 생성
- 임시 테이블 추가 :
INSERT INTO schema1.weather_forecast
SELECT date, temp, min_temp, max_temp, created_date
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1;Upsert
- PK를 기준으로 존재하는 레코드면 새 정보로 수정
- 존재하지 않는 레코드면 새 레코드로 적재
- 데이터 웨어하우스에서 UPSERT를 효율적으로 해주는 문법을 지원한다.
Backfill
Incremental Update
- Incremental Update를 하게되면 효율성은 좋을 수 있지만, 운영/유지보수의 난이도가 올라간다.
- Incremental Update pipeline에서 실패한 부분을 재실행하는 경우 난이도가 높다. → backfill수행
Backfill
- 정의 : 실패한 데이터 파이프라인 재실행 혹은 데이터의 문제로 다시 읽어와야하는 경우를 의미한다.
- Backfill 해결은 Incremental Update에서 복잡해진다.
- Airflow에서는 Backfill을 잘 지원한다.
- DAG 작성 시에는 Backfill이 쉽게 진행될 수 있도록 염두하고 코딩해야한다.
- 시스템적으로 쉽게 해주는 방법을 구현한다.
- 실패한 날짜에 해당 날짜를 입력해둔다.
- Airflow의 접근 방식 : execution_date이 모든 DAG실행에 지정되어 있다. → 이를 바탕으로 데이터를 갱신하도록 코드를 구성해야한다.
Daily Incremental Update & Backfill
- 2020년 11월 7일의 데이터부터 매일 하루의 데이터를 읽어온다고 가정
- ETL의 동작은 11월 8일부터이다.
- start_date : 처음 읽어와야 할 데이터의 날짜 → 위의 경우 start_date = 2020-11-07
- 그러나 다른 날이라면? → 11월9일에 실행해도 start_date 는 동일하다.
- 읽어와야하는 데이터의 날짜는 하루전이다. → 어떻게 가져오는가?
- execution_date : 읽어야하는 데이터의 날짜를 지정할 수 있다.
- BigQuery나Snowflake 같이 고정되지 않은 요금을 사용한다면 큰 금액이 청구 될 수 있다.
Backfill과 관련된 Airflow 변수들
Start_date: DAG가 처음 실행되는 날짜가 아니라 DAG가 처음 읽어와야하는 데이터의 날짜/시간. 실제 첫 실행날짜는 start_date + DAG의 실행주기이다.execution_date: DAG가 읽어와야하는 데이터의 날짜와 시간catchup: DAG가 처음 활성화된 시점이 start_date보다 미래라면 그 사이에 실행이 안된 것들에 대해 처리 여부를 결정하는 파라미터. True인 경우 실행 안된 것들을 모두 실행하게된다. (default : True)end_date: Backfill을 날짜 범위에 대해 하는 경우에 필요하다.
오늘 발생한 이슈들
- Docker 명령어가 무응답인 경우 발생
- Docker desktop 재실행
- wsl 재시작 :
wsl —shutdown
- airflow container에서 airflow 명령어가 듣지 않는 경우
- 관리자 권한인 경우에 실행이 안된다.
docker exec -it <container_id> sh으로 사용할 것.
- VSCODE permission Error :
sudo chown -R <계정명> <작업폴더>
