이 글은 출판사 인투북스의 "객체 지향과 디자인 패턴" 도서를 읽고 정리한 내용임
챕터 1. 들어가기
1장에서 다루는 핵심 내용은 객체 지향 기법의 장점인 변화 가능한 유연한 구조에 대한 소개다.
예제 코드를 통해 지저분해지기 쉬운 코드를 수정이 용이한 구조의 코드로 변화시켜가는 과정을 보여준다.
최초의 코드는 하나의 클래스에서, 현재 메뉴에 따라 공통 버튼을 클릭했을 때 화면과 그 버튼에 따라 수행할 메서드를 각각 만들어 수행한다.
또한 클릭 이벤트 리스너 하나가 if-else로 모든 버튼 클릭 이벤트를 처리하고 있다.
이처럼 if-else 구조를 동일하게 복사 붙여넣기하여 의미없이 코드를 증식시키는 행위는 바람직하지 않음을 쉽게 알 수 있다.
예제에서도 나타나듯, 추가 요구 사항이 들어왔을 경우 비효율적인 복사 붙여넣기 작업을 수행해야 하고, 이 의미없는 작업은 변동사항이 많을 수록 더욱 골치가 아파진다.
이미 알고 있는 코드라고 생각하여 단순하게 생각하기 때문에 꼼꼼히 확인하지 않아 오타가 날 확률도 매우 높으며 그것을 해결하기 위해 시간도 낭비한다.
코드의 가독성도 떨어질 뿐더러 유연함이 전혀 없다고 말할 수도 있다.
다음으로는 수정하기 좋은 구조를 가진 코드를 보여주는데, 기존의 지저분한 코드에서 변경한 내용은 다음과 같이 정리할 수 있다.
1. "버튼 클릭 시 동작" 과 같이 동일한 작업에 대한 메서드를 가지는 객체(인터페이스로부터 구현)를 만들어 관리한다.
2. 다른 역할을 하는 버튼에 대한 리스너를 각각 생성하여 분리하여 관리한다.
결론적으로 다수가 존재할 수 있는 '화면'에 대해서 인터페이스를 만들어 그것을 구현함으로써 각각의 화면에 대한 버튼과 그 기능에 대해 구현할 수 있도록 만들었다.
이렇게 객체 지향적인 구조로 변경하여 새로운 버튼 추가 시 처리 코드에 영향도 없으며, 한 메뉴(화면)관련 코드가 하나의 클래스로 모여있어 분석 및 수정이 용이하게 되었다.
변화 가능한 유연한 구조로 탈바꿈한 것이다.
사실 이러한 구조에 대해서는 객체 지향에 대해 깊이 공부하지 않아도 개발을 하는 사람이라면 직감적으로도 알 수 있는 부분이라고 생각했었다.
하지만 책을 읽으며 스스로를 돌아 보니 응용을 잘 하고 있었나 반성하게 되었다.
나름 고민해서 유연하게 만든다고 개발한 코드들도 두세 번 갈아엎은 적이 많다. 이것은 내가 유연하지 않게 개발했기 때문이다.
이 도서를 공부하여 객체 지향에 대해 깊게 알고 익숙해져 적절한 응용이 가능해지길 기대한다.
챕터 2. 객체 지향
절차 지향이라는 것은 원어로 Procedural Oriented로써 저자의 생각으론 프로시저 지향에 가깝다고 한다.
절차 지향은 각 데이터를 사용하여 기능을 구현하며, 필요에 따라서 다른 프로시저를 사용하기도 하고, 여러 프로시저가 데이터를 공유한다.
따라서 절차 지향 방식은 자연스럽게 데이터를 중심으로 구현된다.
이런 구현 방식은 자연스럽고 쉽게 최초의 코드를 작성할 수 있지만, 데이터의 변경이나 데이터를 프로시저들이 서로 다른 의미로 사용하면 문제가 생긴다.
데이터를 변경하게 되면 모든 관련 프로시저를 수정해야 하고, 다른 의미로 사용하는 경우에는 예기치 않은 오류가 발생하게 되기 때문이다.
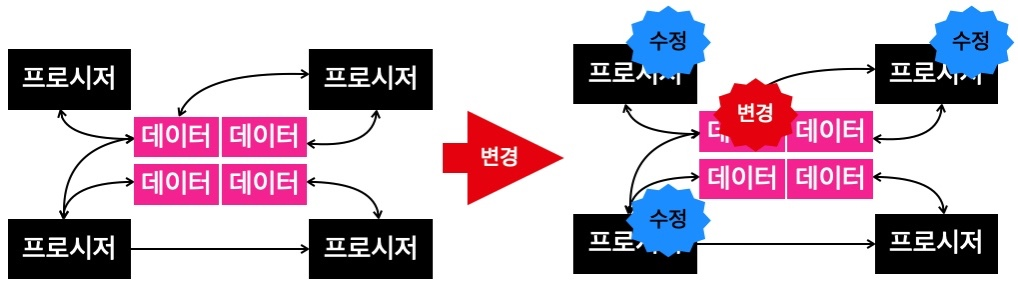
절차 지향과 달리 객체 지향은 데이터 및 데이터와 관련된 프로시저를 객체 단위로 묶는다.
객체는 자신만의 프로시저와 데이터를 가지며, 각 객체들은 연결되어 다른 객체가 제공하는 기능을 사용할 수 있다.
객체의 데이터 변경이 일어났을 때, 해당 객체로만 변화가 집중되고 영향을 최소화 할 수 있다는 장점을 갖는다.
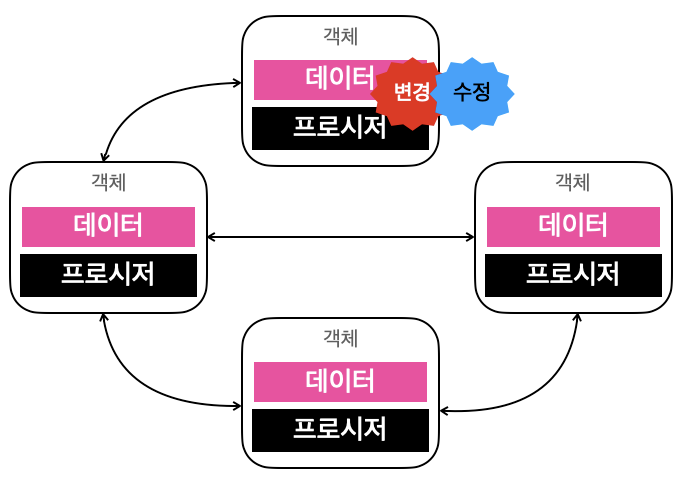
객체의 핵심은 기능을 제공하는 것이다. 객체 정의 시에도 기능에 중점을 두며, 데이터는 이에 따른 부수적인 것일 뿐이다.
객체는 오퍼레이션으로 정의가 되는데, 오퍼레이션은 기능 식별 이름, 파라미터 및 타입, 기능 실행 결과 값 세 가지의 시그니처로 구성된다.
객체가 재공하는 모든 오퍼레이션 집합을 객체의 인터페이스라고 부르며, 인터페이스를 구분할 때 사용되는 명칭이 타입이다.
그리고 실제 객체의 구현을 정의하는 것을 클래스라고 한다.
객체에 오퍼레이션 실행을 요청하는 것을 '메시지를 보낸다'고 표현한다.
자바에서는 메서드를 호출하는 것이 메시지를 보내는 과정에 해당된다.
Something some = new SomeThing();
some.printHello();객체의 책임과 크기
객체는 기능으로 정의된다고 했는데, 이는 다시 말하면 객체마다 자신만의 책임이 있다는 의미다.
한 객체가 갖는 책임을 정의한 것이 타입/인터페이스라고 보면 되며, 이 책임을 결정하는 것이 객체 지향 설계의 시작이다.
프로그램을 만들기 위한 기능 목록을 정리해 놓고 이를 적절히 분배(할당)하는 과정이 필요하다.
이 과정에서 정답을 찾기는 어려운 일이다. 하지만 확실한 규칙이 하나 존재한다면, 바로 객체가 갖는 책임의 크기는 작을수록 좋다는 것이다.
한 객체가 모든 기능을 가지고 있다면 결국 절차 지향과 다를 게 없다는 것은 설명이 필요 없다.
객체가 갖는 책임이 작으면 작을 수록 유연함을 얻기 쉬우며, 이와 관련된 원칙이 바로 단일 책임 원칙이다.
단일 책임 원칙을 따르다 보면 자연스럽게 변경해야 할 부분을 한 곳으로 집중할 수 있다.
의존
한 객체가 다른 객체를 생성하거나 메서드를 호출할 때, 이를 그 객체에 의존한다고 표현한다.
다른 타입에 의존을 한다는 것은 의존하는 타입에 변경이 발생할 때 나도 함께 변경될 가능성이 높다는 의미다.
의존은 또한 전파되는 특징을 갖기 때문에 순환하여 영향을 끼칠 수 있다.
public class ProductManager {
public boolean insert(Product p) {
Product product = findProductByProductId(p.getProductId());
if (product != null) return false;
return insertProduct(p);
}
...
}public class ProductService {
public void insertProduct(Product p) {
ProductManager manager = new ProductManager();
if (manager.insert(p)) {
// 성공 처리
} else {
// 실패 처리
}
}
}위 예제에서 ProductService는 ProductManager에 의존하고 있다. ProductManager가 변경된다면 당연히 ProductService도 영향을 받게 된다.
위와 같은 상황에서 같은 Product를 insert 하고자 할 때 명시적인 Exception 처리를 하고 싶어서 ProductService를 다음과 수정한다고 가정해보자.
...
public void insertProduct(Product p) {
ProductManager manager = new ProductManager();
try {
manager.insert(p);
} catch (DuplicateException e) {
sendResponse("중복입니다.");
}
...
}
...이렇게 되면 ProductManager는 데이터가 중복일 때 Exception을 던져주는 구조로 변경이 되어야 한다.
이 예제로 의존이 상호간에 영향을 준다는 것을 확인할 수 있었다.
순환 의존이 발생하지 않도록 하는 원칙 중의 하나는 의존 역전 원칙이 있는데, 자세한 내용은 챕터 5에서 다룰 것이다.
캡슐화
객체 지향은 캡슐화를 통해서 한 곳의 변화가 다른 곳에 미치는 영향을 최소화한다.
캡슐화는 객체가 내부적으로 기능을 어떻게 구현하는지를 감추는 것이다. 내부가 변경되더라도 그 기능을 사용하는 다른 코드는 영향을 받지 않도록 만들어준다.
다음 예제에서 캡슐화에 대해서 알아본다.
아래와 같은 Person 객체가 있고, 객체가 가진 생년 데이터를 토대로 나이를 반환해주는 getAge() 메소드를 가지고 있다.
public class Person {
private int yearOfBirth;
public int getAge() {
return LocalDateTime.now().getYear() - yearOfBirth;
}
}getAge() 기능을 사용하다 보니 국가별로 나이를 세는 방식이 달라 from 필드를 추가하였다.
...
private String from;
...기존에 Person 객체의 getAge() 기능을 사용하던 부분들이 다음과 같이 수정되었다.
Person person = new Person();
person.setFrom("KR");
person.setYearOfBirth(1994);
// 기존
int age = person.getAge();
// 수정
if (person.getFrom().equals("KR")) {
age = person.getAge() + 1;
} else if (person.getFrom().equals("US")) {
age = person.getAge();
} else if ...위와 같은 예제는 캡슐화의 적절하지 않은 예로 볼 수 있다.
적절하게 캡슐화가 되었다면 Person의 getAge() 메서드를 사용하는 곳에서는 어떻게 구현했는지에 대해 알 필요가 없으며 받아와서 사용하면 그만이다.
따라서 내부 구현이 변경되어도 영향을 최소화시키려면 다음과 같이 Person의 getAge()에 대해서 적절한 캡슐화를 수행시켜 주어야 한다.
public int getAge() {
if (from.equals("KR")) {
return LocalDateTime.now().getYear() - yearOfBirth + 1;
} else if (from.equals("US")) {
return LocalDateTime.now().getYear() - yearOfBirth;
} ...
}이제 캡슐화된 Person의 getAge()를 사용하는 것은 단 한 줄이면 충분하다.
수정 사항이 일어나도 사용하는 부분에선 아무 일도 하지 않아도 된다.
int age = person.getAge();캡슐화를 위한 두 개의 규칙이 있다.
- Tell, Don't Ask : 데이터를 물어보지 않고, 기능을 실행해 달라고 말하는 것.
위에서 person.getFrom()을 가져와 직접 로직을 작성한 방식을 데이터를 물어본 것의 예로 들 수 있다.
getAge()를 사용하는 곳에선 다른 것을 물어보지 않고 단지 getAge()만 실행하도록 바꿔 주었다. - 데미테르의 법칙(Law of Demeter) : 'Tell, Don't Ask' 규칙을 따를 수 있도록 만들어 주는 또 다른 규칙이다.
다음과 같은 간단한 규칙으로 구성된다.
- 메서드에서 생성한 객체의 메서드만 호출
- 파라미터로 받은 객체의 메서드만 호출
- 필드로 참조하는 객체의 메서드만 호출
예를 들면, 메서드에서 생성하였거나 파라미터로 받았거나 필드로 참조하는 객체의 메서드 반환값에 대해서 체이닝을 걸지 말라는 뜻으로 볼 수 있다.
결국 체이닝이나 2차 3차 가공 등이 필요한 데이터는 또 다른 메서드를 생성하여 돌려 주는 것이 맞다는 의미로,
이는 기능 중심으로 코드를 작성하도록 유도하기 때문에 기능 구현의 캡슐화를 향상시켜 준다.
객체 지향 설계 과정
지금까지 살펴본 객체의 정의, 책임, 의존, 캡슐화에 대해 종합적으로 정리해 보면 결국 객체 지향 설계는 다음 작업을 반복하는 과정으로 볼 수 있다.
- 제공해야 할 기능을 찾거나 세분화하고, 그 기능을 알맞은 객체에 할당
- 기능을 구현하는데 필요한 데이터를 객체에 추가, 혹은 데이터를 먼저 추가하고 그에 맞는 기능 구현
- 기능은 최대한 캡슐화해서 구현 - 객체 간의 메시지 전달방법 결정
객체의 핵심은 기능을 제공하는 것이라고 했다.
결론적으로 기능을 적절히 제공하기 위해 책임과 크기에 대한 고려가 필요하고, 순환적인 의존 관계가 이루어 지지 않도록 해야 하며, 캡슐화를 통해 그 기능을 사용하는 메서드들의 변경을 최소화하여야 하겠다.
챕터 3. 다형성과 추상 타입
구현 변경의 유연함을 줄 수 있는 또 다른 방법으로는 추상화가 있다.
다형성은 한 객체가 여러 가지 모습(타입)을 갖는다는 것을 의미하며, 이 다형성이라는 성질이 추상화를 가능하게 해준다.
자바, C++, C# 등의 언어는 다형성을 구현하기 위해 타입을 상속받는 방법을 사용하는데, 타입 상속은 크게 인터페이스 상속과 구현 상속으로 구분해 볼 수 있다.
아래 예제의 자바 인터페이스와 상속 관계를 보고 두 가지 방법에 대해 알아본다.
public interface Animal {
public void breath();
}
public interface Carnivore {
public void eatingMeat();
}
public class Dog implements Animal, Carnivore {
@Override
public void breath() {
System.out.println("breath");
}
@Override
public void eatingMeat() {
System.out.println("eatingMeat");
}
public void bark() {
System.out.println("bark bark");
}
}
public class BorderCollie extends Dog {
@Override
public void bark() {
System.out.println("shepherd");
super.bark();
}
}인터페이스 상속
인터페이스 상속은 타입 정의만을 상속받는다.
자바와 같이 클래스 다중 상속을 지원하지 않는 언어에서는 interface를 이용해서 객체가 다형을 갖게 된다.
인터페이스를 구현한 클래스의 객체는 상위 인터페이스 타입이 될 수 있으며(대입될 수 있다는 의미), 이 경우 인터페이스는 메서드의 시그니처만 제공할 뿐, 실제 구현은 인터페이스를 상속받은 하위 클래스가 제공한다.
public static void main(String[] args) {
Animal animal = new BorderCollie();
animal.breath();
Carnivore carnivore = new BorderCollie();
carnivore.eatingMeat();
}
>>>
breath
eatingMeat구현 상속
구현 상속은 클래스 상속을 통해 이루어지며, 보통 상위 클래스에 정의된 기능을 재사용하기 위한 목적으로 사용된다.
상속을 할 때 재정의를 통해서 자신에 맞게 수정할 수 있고, 이 하위 객체를 생성해서 할당한 경우 재정의 된 기능이 사용된다.
public static void main(String[] args) {
Dog dog = new BorderCollie();
dog.bark();
}
>>>
shepherd
bark bark추상 타입과 유연함
로그를 수집하기 위해 다음과 같은 세 개의 기능을 사용하고 있었다고 가정해 보자.
- FTP에서 파일 다운로드
- 소켓에서 데이터 읽기
- DB 테이블의 데이터를 조회
이 세 개의 기능을 추상화하면 '로그 수집'이라는 개념으로 정의할 수 있다.
이를 실제 클래스에 적용해 보면 아래와 같이 각 구현 클래스를 추상화하여 인터페이스를 도출할 수 있다.
class FtpLogFileDownloader { ... }
class SocketLogReader { ... }
class DbTableLogGateway { ... }
=== (추상화) ===>
interface LogCollector {
public void collect();
}추상 타입과 실제 구현의 연결
추상 타입과 실제 구현 클래스는 상속을 통해서 연결한다.
LogCollector collector = createLogCollector(); // createLogCollector는 알맞은 구현 클래스의 객체를 생성
collector.collect();다형성에 의해 collector.collect()는 실제 collector 객체 타입의 메서드를 호출할 것이다.
이처럼 상위 타입의 기능을 실제로 구현한 하위 타입 클래스들은 실제 구현을 제공한다는 의미로 '콘크리트 클래스'(또는 구상 클래스)라고 부른다.
추상 타입을 이용한 구현 교체의 유연함
콘크리트 클래스를 다음과 같이 직접 사용할 수도 있는데 왜 추상 타입을 사용하는 것일까?
SocketLogReader reader = new SocketLogReader();
reader.collect();결론적으로 말하자면 위 로직을 사용하는 제어를 담당하는 클래스에서 요구사항의 변화가 발생한 경우 제어의 책임만을 가지고 있는 해당 클래스 또한 변경이 이루어져야 하기 때문이다.
즉, 이런 식으로 코드를 작성하는 경우 유연하지 않다는 의미로 볼 수 있다.
파라미터로 받는 조건에 따라서 콘크리트 클래스가 달라져야 할 경우가 생길 수 있고, 또한 새로운 클래스를 추가하거나 그에 따른 파라미터의 변화까지 생각한다면 당연한 결과다.
소스가 변경되더라도 이를 사용하는 클래스는 바뀌지 않도록 해야 하며, 이를 위한 방법으로는 두 가지가 존재하며, 이번 챕터에서는 1번 방법을 사용한다.
- 소스 타입의 객체를 생성하는 기능을 별도 객체로 분리한 뒤, 그 객체를 사용하여 소스를 생성
- 생성자(또는 다른 메서드)를 이용해서 사용할 소스를 전달받기 (6장, DI와 서비스 로케이터에서 살펴본다)
위의 '추상 타입과 실제 구현의 연결' 예제 코드에서 createLogCollector() 메서드를 이용해서 알맞은 구현 클래스의 객체를 생성하는 것이 1번 방법을 사용한 것이라 볼 수 있다.
또한 알맞은 구현 클래스를 대입하기 위해 추상화된 타입을 사용한 것도 볼 수 있다.
이렇게 되면 이제 타입의 추가나 변경에 대해서는 이 제어 클래스에서 신경을 쓰지 않아도 되며, 유연함을 가졌다고 이야기 할 수 있다.
변화되는 부분을 추상화하기
처음부터 완벽하게 추상화를 하기는 쉽지 않다. 하지만 경험하지 않은 분야라 하더라도 추상화할 수 있는 방법이 있는데, 그것은 바로 변화되는 부분을 추상화하는 것이다.
요구 사항이 바뀔 때 변화되는 부분은 이후에도 변동될 소지가 많고, 바로 이런 부분이 추상 타입으로 교체해야 할 대상이며 교체를 통해 유연하게 대처할 수 있는 가능성이 높아진다.
추상화가 되어 있지 않은 코드는 주로 동일 구조를 갖는 if-else 블록으로 드러난다. 이런 부분에 대해 항상 추상 타입으로의 교체를 고려해보아야 한다.
인터페이스에 대고 프로그래밍하기
인터페이스에 대고 프로그래밍하기는 객체 지향의 유명한 규칙 중 하나다.
실제 구현을 제공하는 콘크리트 클래스를 사용해서 프로그래밍하지 말고,
기능을 정의한 인터페이스를 사용해서 프로그래밍 하라는 뜻이다.
이 규칙을 따르면 쉽게 추상화를 통한 유연함을 얻을 수 있다.
하지만 유연함을 얻는 과정에서 타입이 증가하고 구조도 복잡해지기 때문에 남발해서는 안된다.
인터페이스를 사용해야 할 때는 변화 가능성이 높은 경우에 한해서만 사용해야 한다.
인터페이스는 변화가 발생하는 곳으로부터 시작하는 추상화 과정을 통해 도출되기 때문에, 변경 가능성의 희박한 클래스에 대해 인터페이스를 도출할 필요는 없다.
인터페이스는 인터페이스 사용자 입장에서 만들기
인터페이스를 작성할 때는 그 인터페이스를 사용하는 코드 입장에서 작성해야 한다.
인터페이스를 사용하는 쪽에서 직관적으로 확인할 수 있어야 하며 오해의 소지가 없어야 한다.
간단한 예로는 적절한 네이밍 룰을 따르는 것을 들 수 있겠다.
인터페이스와 테스트
콘크리트 클래스를 사용하지 않고 추상 타입을 이용한 프로그래밍의 장점으로 테스트의 용이함을 들 수도 있다.
인터페이스를 사용하는 코드 입장에서는 콘크리트 클래스들의 완성 여부와 관계없이 로직을 작성하고 테스트 할 수 있다.
그 방법은 바로 Mock(가짜, 모의) 테스트 콘크리트 클래스를 추상 타입에 대입하여 사용하는 것이다.
요구 사항의 변경이나 수정과 같은 맥락이라고 볼 수 있는데, 사용자의 로직은 변경하지 않고 추후에 완성된 콘크리트 클래스를 어떻게 대입할 것인지에 대해서만 고려하면 되는 것이다.
챕터 4. 재사용: 상속보단 조립
상속을 사용하면 재사용을 쉽게 할 수 있는 것은 분명하지만, 이에는 한계가 있다.
이 챕터에서는 상속을 통한 재사용 과정에서 발생할 수 있는 문제점을 살펴보고,
또 다른 재사용 방법인 객체 조합을 통해 이 문제를 해소하는 방법을 알아본다.
1. 상위 클래스 변경의 어려움
상속은 상위 클래스의 변경을 어렵게 만든다.
의존하는 상위 클래스의 코드가 변경되면 이 여파가 계층을 따라 하위 클래스에 전파된다.
최악의 경우 상위 클래스의 변화가 모든 하위 클래스에 변화를 줄 수 있으며, 이는 클래스 계층도에 있는 거대 클래스들을 한 개의 거대한 단일 구조처럼 만들어 주는 결과를 초래한다.
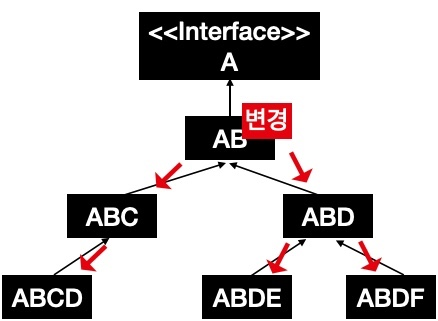
2. 클래스의 불필요한 증가
유사한 기능을 확장하는 과정에서 클래스의 개수가 불필요하게 증가할 수 있다.
자바에서는 다중 상속을 할 수 없어 한 개의 클래스만 상속받고 다른 기능을 별도로 구현해야 하기 때문에
필요한 기능의 조합이 증가할수록 상속을 통한 기능 재사용을 하면 클래스의 개수는 함께 증가하게 된다.
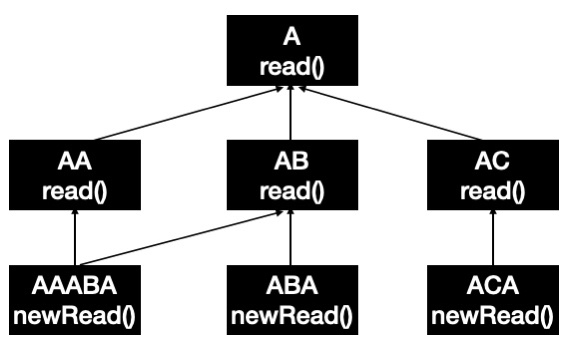
위 그림처럼 기존 A 클래스의 읽어오기 기능 read() 를 상속받아 AA, AB, AC 클래스에서 각각의 추가적인 기능을 구현했다고 치자.
AAABA는 AA의 추가적인 기능과 AB의 추가적인 기능을 모두 사용하기 위해 새로 만들어진 클래스이며, ABA와 ACA도 같은 맥락으로 생성된 클래스다.
위에서 필요한 기능의 조합이 증가한다는 의미가 바로 이런 의미이며, 위처럼 상속을 통해 재사용성을 도모하는 경우 이 조합의 변경에 따라 클래스가 생성되어야만 함을 알 수 있다.
3. 상속의 오용
상속 자체를 잘못 사용하는 경우가 문제가 될 수 있다.
상속은 IS-A 관계가 성립할 때만 사용해야 한다. 즉, 상속받은 메서드 중 어느 것을 사용하더라도 문제가 없어야 정상적이다.
하지만 같은 종류가 아닌 클래스의 구현을 재사용하기 위해 상속을 받게 되면 오용의 여지를 남기는 것이 된다.
오용의 여지가 남게 되는 경우 당연히 오용으로 인한 문제가 발생할 가능성이 있다.
오용의 예를 들자면, 아래와 같이 네이밍 룰에 따라 SHOP 으로 시작하는 상품만 담을 수 있는 카트 클래스를 만들었다고 생각해보자.
이 카트 클래스는 ArrayList를 상속받아 구현했다.
public class Cart extends ArrayList<Product> {
public void put(Product product) throws UnknownProductNameException {
if (checkProductName(product)) throw new UnknownProductNameException();
super.add(product);
}
public boolean checkProductName(Product product) {
return product.getName().startsWith("SHOP");
}
}이 Cart 클래스를 사용하는 곳에서 put 메서드를 사용하면 Product를 등록할 때 상품명이 SHOP으로 시작하는 지 정상적으로 걸러낼 수 있다. (의도한대로 동작)
하지만 ArrayList를 상속받았기 때문에 당연히 바로 add()메서드를 사용할 수도 있을 것이며, 그렇게 되면 상품명을 체크하지 않고 무조건 리스트에 담을 수 있다. (의도하지 않은 동작)
조립을 이용한 재사용
객체 조립은 여러 객체를 묶어 더 복잡한 기능을 제공하는 객체를 만들어 내는 것이다.
객체 지향 언어에서 객체 조립은 보통 필드에서 다른 객체를 참조하는 방식으로 구현된다.
public class FlowController {
private Encryptor enc = new Encryptor(); // 필드로 조립
public void process() {
...
byte[] encryptedData = enc.encrypt(data);
...
}
}한 객체가 다른 객체를 조립해서 필드로 갖는다는 것은 기능을 사용한다는 의미로, 위에서는 Encryptor 클래스를 재사용하는 것으로 볼 수 있다.
조립을 통한 재사용은 상속을 통한 재사용을 할 때 발생했던 문제들을 해소해 준다.
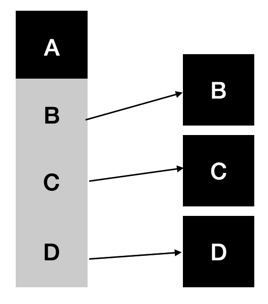
조립을 통해 재사용을 하게 되면, 위 그림과 같이 A 클래스에서 필요한 기능들을 담고있는 클래스들(B,C,D)을 조립해서 사용한다.
새로운 기능이 추가된다고 해도 상속관계의 불필요한 클래스의 수가 증가하지 않고, 또한 필요한 기능(책임)에 집중하여 오용의 가능성도 없어진다.
또한 상위 클래스로부터 변경이 전파되는 구조가 아니기 때문에 변경에 유연하다고 볼 수 있다.
추가로, 상속의 경우 소스 코드를 작성할 때 관계가 형성되기 때문에 런타임 시점에 상위 클래스를 교체할 수 없는 단점이 있다.
하지만 조립하는 방법을 이용하게 되면 생성자 혹은 set 메서드를 이용하여 필드를 교체해주면 되기 때문에 런타임에 변경이 가능하다.
결론적으로 상속을 사용하다 보면 변경 관점에서 유연함이 떨어질 가능성이 높으니 객체 조립을 우선으로 고민하는 것이 바람직하다.
런타임 구조가 복잡해지고 구현이 어렵다는 단점이 있지만, 장기적으로 보면 유연함을 확보하는 데서 오는 장점이 크기 때문이다.
위임
위임은 내가 할 일을 다른 객체에게 넘긴다는 의미로, 조립 방식을 이용해 구현한다.
위임은 조립과 마찬가지로 요청을 위임할 객체를 필드로 연결하거나 혹은 객체를 새로 생성해서 요청을 전달한다.
조립은 객체가 필요한 기능들을 필드에 다른 기능을 가진 객체를 연관시킴으로써 완성하는 것이고,
위임은 객체에 필요한 정보를 만들어주는 책임을 가진 객체를 연결하거나 혹은 생성하여 요청해 받는 것이다.
결론적으로 객체 지향적으로 구현하면 자연스럽게 많은 객체들이 만들어지고, 조립과 위임을 통해 객체를 재사용하게 됨을 알 수 있다.
그렇다면 상속은 언제 사용하나?
상속은 재사용이라는 관점이 아닌 기능의 확장이라는 관점에서 적용을 고려해야 하며, 명확하게 IS-A 관계가 성립되어야만 한다.
대표적인 예로 UI 위젯을 들 수 있다.
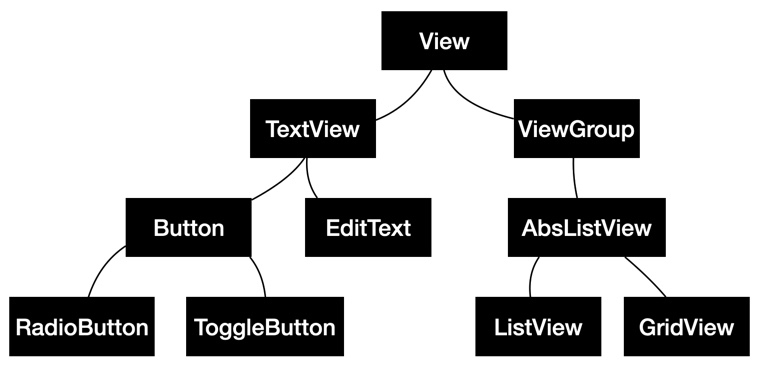
안드로이드 화면에 보이는 버튼이나 텍스트, 목록 등은 모두 UI 위젯이다.
따라서 위 계층도의 모든 객체는 명확한 IS-A 관계라고 볼 수 있다.
이들 클래스 계층은 하위로 내려갈수록 상위 클래스의 기본적인 기능을 그대로 유지하면서 그 기능을 확장해 나간다.
최상위인 View 클래스는 화면에 보이는 위젯 UI의 크기, 색 등의 기본 속성을 설정하는 기능을 제공한다.
이를 상속받은 TextView 위젯은 여기에 추가로 글자를 출력하는 기능을 제공한다.
이처럼 상속은 명확한 IS-A 관계에서 점진적으로 상위 클래스의 기능을 확장해 나갈 때 사용할 수 있다.
하지만 상속을 통한 재사용의 단점이라고 언급했던 다음과 같은 문제가 발생한다면 조립으로 전환하는 것을 고려해야 하겠다.
- 클래스가 불필요하게 증가 !
- 상위 클래스 변경이 어려워짐 !
챕터 5. 설계 원칙: SOLID
SOILD 설계 원칙은 다음 다섯 가지 원칙으로 구성되며, 원칙들은 서로 밀접하게 연관되어 있으므로 종합적으로 이해해야 한다.
- 단일 책임 원칙 (Single responsibility principle; SRP)
- 개방-폐쇄 원칙 (Open-Closed principle; OCP)
- 리스코프 치환 원칙 (Liskov substitution principle; LSP)
- 인터페이스 분리 원칙 (Interface segregation principle; ISP)
- 의존 역전 원칙 (Dependency inversion principle; DIP)
단일 책임 원칙 (Single responsibility principle; SRP)
클래스는 단 한 개의 책임을 가져야 한다.
클래스가 여러 책임을 갖게 되면 각 책임마다 변경되는 이유가 발생한다.
클래스가 한 개의 이유로만 변경되려면 한 개의 책임만을 가져야 한다.
객체에 책임을 할당하는 것이 객체 설계의 기본이므로, 이것은 가장 중요한 원칙 중 하나다.
다른 원칙들도 잘 지켜지게 하기 위해서는 단일 책임 원칙을 잘 지켜야 하므로 최대한 지켜야 한다.
하지만 '한 개의 책임'에 대한 정의가 명확하지 않고, 책임을 도출해내기 위해서 많은 경험이 필요하기 때문에 가장 지키기 어려운 원칙으로도 볼 수 있다.
단일 책임 원칙을 어기면 재사용이 어려워지고, 어떤 하나의 이유로 책임이 변경되었을 때 연쇄적으로 다른 기능들이 함께 변경되는 특징을 갖는다.
❗ 책임이란 변화에 대한 것
서로 다른 이유로 바뀌는 책임들이 한 클래스에 함께 포함되어 있다면 단일 책임을 어기고 있다고 볼 수 있는 것이다.
단일 책임 원칙을 잘 지키려면 메서드를 실행하는 것이 누구인지 확인해 보는 방법이 있다.
해당 클래스의 사용자들이 서로 다른 메서드들을 사용한다면, 그들 메서드는 각각 다른 책임에 속할 가능성이 높고 책임 분리 후보가 될 수 있다.
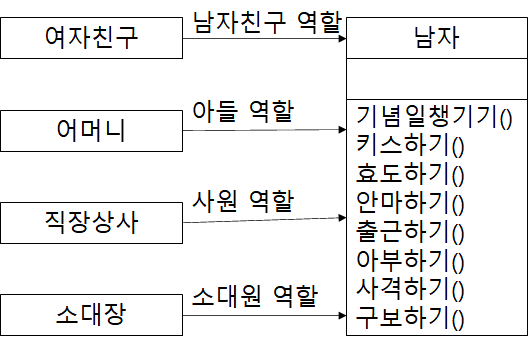
남자라는 클래스의 역할이 너무 많다.
만약 남자가 여자친구와 헤어졌다면, 기념일 챙기기와 키스하기는 더 이상 필요가 없게 된다.
위와 같은 경우에 아래와 같이 책임을 분리하는 것이 단일 책임 원칙이다.

개방-폐쇄 원칙 (Open-Closed principle; OCP)
확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다.
위 말을 구체적으로 풀어보자면 다음과 같다.
기능을 변경하거나 확장할 수 있으면서 그 기능을 사용하는 코드는 수정하지 않는다.
3장에서 인터페이스를 구현함으로써 그 기능을 사용하는 객체에 코드 수정이 이루어지지 않도록 작성해 보았다.
그와 같은 구조는 사용되는 기능의 확장에는 열려 있고, 기능을 사용하는 코드의 변경에는 닫혀 있다고 얘기할 수 있다.
개방 폐쇄 원칙은 상속을 이용해서도 구현할 수 있다. 상속은 상위 클래스의 기능을 그대로 사용하면서 하위 클래스에서 일부 구현을 오버라이딩 할 수 있는 방법을 제공한다.
public class Messenger {
...
public void sendMessage() {
sendTimeInfo();
sendMessageBody();
}
protected void sendTimeInfo() { ... }
protected void sendMessageBody() { ... }
}위와 같이 시간 정보와 메시지에 대한 내용을 보내는 Messenger 객체가 있다고 생각해보자.
만약 이 상황에서 시간 정보를 한국 시간으로 보내고 싶다면, 아래와 같이 상속받은 클래스에서 오버라이딩 하여 사용할 수 있다.
public class KoreanMessenger extends Messenger {
...
@Override
protected void sendTimeInfo() {
// 한국 시간에 맞춰 보내기
}
}한국 시간으로 보내는 기능을 추가했지만 Messenger 클래스의 코드는 변경되지 않았다.
따라서 Messenger 클래스는 확장에는 열려 있으며 변경에는 닫혀 있다고 볼 수 있다.
개방 폐쇄 원칙이 깨질 때의 주요 증상은 다음과 같다.
- 다운 캐스팅을 한다:
instanceof와 같은 타입 확인 연산자를 사용하여 특정 타입에 대해 추가적인 작업을 수행한다면, 해당 코드는 개방 폐쇄 원칙을 지키지 않을 가능성이 높다.
이런 경우에는 타입 캐스팅 후 실행하는 메서드가 변화 대상인지 확인해 보아야 한다. - 비슷한 if-else 블록이 존재한다:
변경이 필요할 때 새로운 if 블록이 추가된다면 변경에 닫혀 있다고 볼 수 없다.
이러한 경우 개방 폐쇄 원칙을 따르도록 변경하려면 if-else 블록에 대해 추상화를 수행하여 이 추상 타입을 사용하는 구조로 변경되어야 한다.
❗ 개방 폐쇄 원칙은 유연함에 대한 것
개방 폐쇄 원칙은 변화가 예상되는 것을 추상화해서 변경의 유연함을 얻도록 해준다.
바꿔 말하면, 변화되는 부분을 추상화하지 못하면 개방 폐쐐 원칙을 지킬 수 없게 되어 시간이 흐를수록 기능 변경이나 확장을 어렵게 만든다는 것이다.
변화 요구가 발생하면 관련 구현을 추상화할 수 있는지 확인하는 습관을 가져야 한다.
리스코프 치환 원칙 (Liskov substitution principle; LSP)
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램을 정상적으로 동작해야 한다.
리스코프 치환 원칙은 개방 폐쇄 원칙을 받쳐 주는 다형성에 관한 원칙을 제공한다.
public void doSomething(SuperClass class) {
class.doSomething();
};이 메서드는 상위 타입인 SuperClass 타입의 객체를 사용하고 있는데, 아래와 같이 하위 타입의 객체를 전달해도 정상적으로 동작해야 한다는 것이 리스코프 치환 원칙이다.
doSomething(new SubClass());리스코프 치환 원칙이 지켜지지 않으면 다형성에 기반한 개방 폐쇄 원칙 또한 지켜지지 않으므로 리스코프 치환 원칙을 지키는 것은 매우 중요하다.
다음과 같이 입력 스트림으로부터 데이터를 읽어 출력 스트림에 복사 해주는 기능이 있다고 해보자.
public class CopyUtil {
public static void copy(InputStream in, OutputStream out) {
byte[] data = new byte[512];
int len = -1;
while ((len = in.read(data)) != -1) {
out.write(data, 0, len);
}
}
}InputStream의 read는 더 이상 데이터를 읽어올 수 없을 때 -1을 return 하기 때문에, 이러한 동작을 기대하고 while문을 통해 출력하도록 작성했다.
아래와 같이 InputStream의 하위 타입에서 read를 아래와 같이 구현했다고 가정해보자.
public class CustomInputStream implements InputStream {
public int read(byte[] data) {
...
return 0; // 데이터가 없을 때
}
}이제 CopyUtil.copy()를 사용하고자 할 때 하위 타입 구현체인 CustomInputStream을 대입했다.
InputStream in = new CustomInputStream(data);
OutputStream out = new FileOutputStream(path);
CopyUtil.copy(in, out);어떻게 될까? 당연히 무한 루프에 빠지게 될 것이다. CopyUtil의 copy 메서드는 데이터가 없을 때 -1을 리턴할 것을 기대하고 while문을 작성했기 때문이다.
이같은 문제가 발생하는 것은 하위 타입의 객체가 상위 타입을 올바르게 대체하지 않기 때문이다.
❗ 리스코프 치환 원칙은 계약과 확장에 대한 것
계약에 대한 것은 기능의 명세를 의미하며, 하위 타입은 상위 타입에서 정의한 명세를 벗어나지 않는 범위에서 구현해야 한다.
하위 타입이 명세에 벗어난 동작을 하게 되면 이 명세에 기반해 구현한 코드는 비정상적으로 동작할 수 있기 때문이다.
흔히 발생하는 위반 사례로는 다음과 같은 것들이 있다.
- 명세에서 벗어난 값을 리턴
- 명세에서 벗어난 Exception을 발생
- 명세에서 벗어난 기능을 수행
확장에 대한 것은 이 원칙을 어기면 개방 폐쇄 원칙을 어길 가능성이 높아짐을 의미한다.
개방 폐쇄 원칙에서 알아보았듯이 instanceof 연산자를 사용하는 경우는 하위 타입이 상위 타입을 완벽하게 대체하지 못하는 상황이 발생했다는 것이다.
하위 타입이 상위 타입을 완벽하게 대치하려면 알맞은 오버라이딩 등을 사용해서 해당 객체에 맞는 메서드를 구현해주어야 한다.
그 후 instanceof 연산자를 사용하던 기존 위치에선 완벽하게 대치될 것을 기대하고 코드를 작성하기만 하면 되는 것이고, 이처럼 리스코프 치환 원칙이 잘 지켜지면 또한 확장이 잘 이루어진다고 볼 수 있다.
인터페이스 분리 원칙 (Interface segregation principle; ISP)
인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다.
원래 원칙의 정의는 "클라이언트는 자신이 사용하는 메서드에만 의존해야 한다."로 되어 있으나, 저자가 이해와 기억이 쉽도록 정의를 변경했다.
용도에 맞게 인터페이스를 분리하는 것은 단일 책임 원칙과 연결된다. 단일 책임 원칙에서 봤듯이 하나의 타입에 여러 기능이 섞여 있을 경우 한 기능의 변화로 인해 다른 기능이 영향을 받을 가능성이 높아진다.
따라서 클라이언트 입장에서 사용하는 기능만 제공하도록 인터페이스를 분리함으로써 한 기능에 대한 변경의 여파를 최소화할 수 있다.
또한, 단일 책임 원칙이 잘 지켜질 때 인터페이스와 콘크리트 클래스의 재사용 가능성을 높일 수 있으므로 인터페이스 분리 원칙은 결국 인터페이스와 콘크리트 클래스의 재사용성읖 높여 주는 효과를 갖는다.
❗ 인터페이스 분리 원칙은 클라이언트에 대한 것
인터페이스 분리 원칙은 클라이언트 입장에서 인터페이스를 분리하라는 원칙이다.
각 클라언트가 사용하는 기능을 중심으로 인터페이스를 분리함으로써 클라이언트로부터 발생하는 인터페이스 변경의 여파가 다른 클라이언트에 미치는 영향을 최소화할 수 있게 된다.

의존 역전 원칙 (Dependency inversion principle; DIP)
고수준 모듈은 저수준 모듈의 구현에 의존해서는 안 된다. 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다.
고수준 모듈은 어떤 의미 있는 단일 기능을 제공하는 모듈이라고 정의할 수 있으며,
저수준 모듈은 고수준 모듈의 기능을 구현하기 위해 필요한 하위 기능의 실제 구현으로 정의할 수 있다.

저수준 모듈이 변경되더라도 고수준 모듈은 변경되지 않아야 한다. 고수준 모듈이 개별적인 저수준 모듈의 구현에 의존하게 되면 프로그램의 변경을 어렵게 만든다.
이를 위한 원칙이 바로 의존 역전 원칙이다.
결국 저수준 모듈이 고수준 모듈을 의존하게 만들어야 한다는 것인데, 그렇다면 어떻게 저소준 모듈이 고수준 모듈을 의존하게 만들어야 할까? 답은 추상화에 있다.
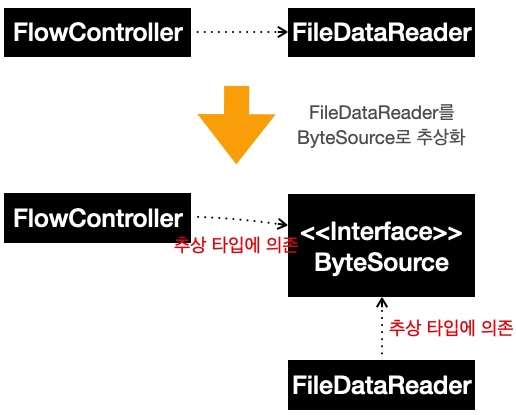
고수준 모듈인 FlowController와 저수준 모듈인 FileDataReader가 모두 추상화 타입인 ByteSource에 의존함으로써 고수준 모듈의 변경 없이 저수준 모듈을 변경할 수 있는 유연함을 얻는다.
의존 역전 원칙은 리스코프 치환 원칙과 함께 개방 폐쇄 원칙을 따르는 설계를 만들어 주는 기반이 된다.
또한 의존 역전 원칙은 타입의 소유 역전(고수준 모듈이 타입을 소유)으로 이어지며, 이는 각 패키지를 독립적으로 배포할 수 있도록 만들어 준다.
만약 추상화되지 않아 고수준 모듈이 저수준 모듈에 의존하고, 또 타입의 소유가 저수준 모듈에 있었다면 기능상 필요 없는 jar 파일이나 DLL파일 등까지 포함이 될 수 밖에 없을 것이다.
따라서 의존 역전 원칙은 개방 폐쇄 원칙을 클래스 수준 뿐만 아니라 패키지 수준까지 확장시켜 주는 디딤돌이 된다고 할 수 있다.
SOLID 정리
단일 책임 원칙과 인터페이스 분리 원칙은 객체가 커지지 않도록 막아 준다.
객체가 단일 책임을 갖게 하고 클라이언트마다 다른 인터페이스를 사용하게 함으로써 변경의 영향을 최소화할 수 있고, 이는 결국 변경을 쉽게 할 수 있도록 한다.
리스코프 치환 원칙과 의존 역전 원칙은 개방 폐쇄 원칙을 지원한다.
의존 역전 원칙은 변화되는 부분을 추상화할 수 있도록 도와주고, 리스코프 치환 원칙은 다형성을 도와준다.
SOLID 원칙은 사용자 입장에서의 기능 사용을 중시하여 사용자 관점에서의 설계를 지향하고 있다.
챕터 6. DI(Dependency Injection)와 서비스 로케이터
로버트 C 마틴은 소프트웨어를 두 개의 영역으로 구분해서 설명한다.
어플리케이션 영역은 고수준 정책 및 저수준 구현을 포함하는 영역이고,
메인 영역은 어플리케이션이 동작하도록 각 객체들을 연결해 주는 영역이다.
챕터 6에서는 어플리케이션 영역과 메인 영역에 대해 살펴보고, 메인 영역에서 객체를 연결하기 위해 사용되는 방법인
DI(dependency injection; 의존성 주입)와 서비스 로케이터에 대해 알아본다.
어플리케이션 영역과 메인 영역
개방 폐쇄 원칙을 준수하여 변화되는 부분을 추상화한 인터페스를 만들고,
의존 역전 원칙을 준수하여 콘크리트 클래스에 의존하지 않는 어플리케이션 구조를 설계했다고 생각해보자.
그럼 이제 추상화된 부분을 구현한 저수준 모듈 객체를 누가 초기화 해 주며 실행해 줄 것인가?
이것이 바로 메인 영역의 역할이며, 메인 영역은 다음 작업을 수행한다.
- 어플리케이션 영역에서 사용될 객체를 생성한다.
- 각 객체 간의 의존 관계를 설정한다.
- 어플리케이션을 실행한다.
메인 영역은 어플리케이션 영역의 객체를 생성, 설정, 실행하는 책임을 갖는다.
따라서 어플리케이션에서 사용할 하위 수준의 모듈을 변경하고 싶다면 메인 영역을 수정하게 된다.
여기서 알 수 있는 점은 모든 의존은 메인 영역에서 어플리케이션 영역으로 향한다는 것이다.
반대 경우인 어플리케이션 영역에서 메인 영역으로의 의존은 존재하지 않는다.
이것은 즉 메인 영역을 변경한다고 해도 어플리케이션 영역은 변경되지 않는다는 것을 뜻한다.
의존 객체를 찾을 때 Locater라는 객체를 활용해서 필요한 객체를 가져온 뒤에 원하는 기능을 실행하는 방식을 이용할 때, 사용할 객체를 제공하는 책임을 갖는 객체를 서비스 로케이터라고 부른다.
서비스 로케이터는 생성자나 set 메서드등을 통해 초기화될 수 있고, 그것을 제공하는 책임을 갖는다.
서비스 로케이터 방식은 몇 가지 단점이 존재하기 때문에, 외부에서 사용할 객체를 주입해주는 DI(Dependency Injection)방식을 사용하는 것이 일반적이다.
DI(Dependency Injection)을 이용한 의존 객체 사용
사용할 객체를 직접 생성할 경우 다음과 같이 콘크리트 클래스에 대한 의존이 발생하게 된다.
public class Worker {
public void run() {
// 콘크리트 클래스를 사용
JobQueue jobQueue = new FileJobQueue(); // DIP(의존 역전 원칙) 위반
...
}
}콘크리트 클래스를 직접 사용해서 객체를 생성하게 되면 의존 역전 원칙을 위반하게 되며, 결과적으로 확장 폐쇄 원칙을 위반하게 된다.
또한, 서비스 로케이터를 사용하면 서비스 로케이터를 통해서 의존 객체를 찾게 되는데, 이 경우에도 몇 가지 단점이 발생하게 된다.
이러한 단점을 보완하는 방법이 바로 DI(Dependency Injection; 의존 주입)이다.
DI는 필요한 객체를 직접 생성하거나 찾지 않고 외부에서 넣어주는 방식이다.
스스로 의존하는 객체를 찾거나 생성하지 않고, 호출 대상 프로그램에서 생성자를 통해 사용할 객체를 주입받는다.
외부에서 의존하는 객체를 넣어 주기 때문에 의존 주입이라고 부르는 것이다.
또한 객체 조립 역할을 수행하는 클래스를 별도로 분리해서 사용할 수 있다.
이를 조립기라고 칭하며, 조립기를 분리하면 향후에 구현 변경의 유연함을 얻을 수도 있다.
public class Assembler {
...
public void createAndWire() {
JobQueue que = new FileJobQueue();
Transcoder tc = new FfmpegRranscoder();
this.worker = new Worker(que, tc);
this.jobCli = new JobCli(que);
}
public Worker getWorker() {
return this.worker;
}
public JobCli getJobCli() {
return this.jobCli;
}
}DI를 적용하는 데에는 크게 두 가지 방식이 존재한다.
- 생성자 방식
- 설정 메서드 방식
생성자 방식과 설정 메서드 방식
생성자 방식
생성자 방식은 앞서 살펴보았던 생성자를 통해서 의존 객체를 전달받는 방식이다.
생성자를 통해서 전달받은 객체를 필드로 보관한다.
public class JobCli {
private JobQueue jobQueue;
// 생성자를 통해서 의존 객체를 전달받음
public JobCli(JobQueue queue) {
this.jobQueue = jobQueue;
}
}생성자 방식은 객체를 생성하는 시점에 필요한 모든 의존 객체를 준비할 수 있다.
생성자를 통해서 필요한 의존 객체를 전달받기 때문에 객체를 생성하는 시점에서 의존 객체의 정상 여부를 확인할 수 있다는 장점이 있다.
즉, 한 번 객체가 생성되면 객체가 정상적으로 동작함을 보장할 수 있다는 의미다.
하지만 당연하게도 생성자에 전달하기 이전에 의존 객체가 먼저 생성이 되어 있어야만 하므로, 의존 객체를 먼저 생성할 수 없는 경우는 생정자 방식을 사용할 수 없다.
설정 메서드 방식
설정 메서드 방식은 메서드를 이용해서 의존 객체를 전달받는 방식이다.
public class Worker {
...
public void setJobQueue(JobQueue jobQueue) {
this.jobQueue = jobQueue;
}
...
}자바빈 프로퍼티 규약에 따라 리턴 타입이 void이고 메서드 명을 set으로 한 예시였다.
하지만 사용 편의에 따라 한 개의 메서드를 만들어 의존 객체를 모두 설정하거나, 체이닝이 가능하도록 this를 리턴하게 만들 수도 있다.
설정 메서드 방식은 객체를 생성한 뒤에 의존 객체를 주입하게 된다.
그렇기 때문에 의존 객체를 설정하지 못한 상태에서 객체를 사용할 수 있고, 이는 NullPointerException 등의 발생 가능성이 존재한다는 의미다.
즉, 완전히 의존 객체가 설정이 되어 정상적으로 동작함을 보장할 수 없다.
하지만 설정 메서드 방식은 객체 생성 이후에 언제든지 의존 객체를 설정할 수 있다.
그렇기 때문에 의존 대상 객체가 해당 객체보다 더 늦은 시점에 생성된다면 이 방식을 사용해서 의존성을 주입할 수 있다.
또한 의존할 객체가 많은 경우에, 각각의 설정 메서드를 호출하는 코드를 작성하게 되면
어떤 의존 객체를 설정하는지 확인하기가 비교적 수월하기 때문에 코드 가독성을 높여주는 효과가 있다고 볼 수 있다.
DI와 테스트
DI는 의존 객체를 Mock 객체로 쉽게 대체할 수 있도록 함으로써 단위 테스트를 할 수 있도록 돕는다.
DI 패턴을 따르는 클래스에 생성자나 설정 메서드를 통해 Mock 객체를 전달하여 테스트하면 된다.
서비스 로케이터를 이용한 의존 객체 사용
서비스 로케이터가 가진 단점 때문에 의존성 주입을 일반적으로 사용한다고 했었는데,
실행 환경의 제약 등으로 DI 패턴을 적용할 수 없는 경우에는 의존 객체를 찾는 다른 방법을 모색해야 하기 때문에 서비스 로케이터를 사용할 수 있다.
서비스 로케이터의 구현
서비스 로케이터는 어플리케이션에서 필요로 하는 객체를 제공하는 책임을 갖는다.
서비스 로케이터를 구현하는 방법은 다양하게 존재할 수 있는데, 객체 등록 방식의 구현 방법과 상속을 통한 구현 방법에 대해 알아본다.
객체 등록 방식의 서비스 로케이터 구현
- 서비스 로케이터를 생성할 때 사용할 객체를 전달한다.
- 서비스 로케이터 인스턴스를 지정하고 참조하기 위한 static 메서드를 제공한다.
생성자를 이용해서 객체를 등록 받는 서비스 로케이터 구현 > 메인 영역에서 서비스 로케이터에 객체 등록
or 객체마다 등록 메서드를 따로 제공하는 서비스 로케이터 구현
상속을 통한 서비스 로케이터 구현
객체를 구하는 추상 메서드를 제공하는 상위 타입 구현
상위 타입을 상속받은 하위 타입에서 사용할 객체 설정
public abstract class ServiceLocator {
public abstract JobQueue getJobQueue();
public abstract Transcoder getTranscoder();
protected ServiceLocator() {
ServiceLocator.instance = this;
}
...
}public class MyServiceLocator extends ServiceLocator {
private FileJobQueue jobQueue;
private FfmpegRranscoder transcoder;
public MyServiceLocator() {
super();
this.jobQueue = new FileJobQueue();
this.transcoder = new FfmpegRranscoder();
}
@Override
public JobQueue getJobQueue() {
return jobQueue;
}
@Override
public Transcoder getTranscoder() {
return transcoder;
}
}// 서비스 로케이터 초기화 시 아래처럼 인스턴스만 생성해주면 됨
new MyServiceLocator();제네릭/템플릿을 이용한 서비스 로케이터 구현
서비스 로케이터의 단점은 인터페이스 분리 원칙을 위배한다는 것이다. (특정 기능을 사용하지 않더라도, 서비스 로케이터 안에서 사용하는 다른 타입들에 대한 의존이 존재)
자바의 제네릭이나 C++의 템플릿을 이용해서 서비스 로케이터를 구현하면 중복된 코드를 피하면서 인터페이스를 분리한 것과 같은 효과를 볼 수 있다.
public class ServiceLocator {
private static Map<Class<?>, Object> objectMap = new HashMap<Class<?>, Object>();
public static <T> T get(Class<T> klass) {
return (T) objectMap.get(klass);
}
public static void regist(Class<?> klass, Object obj) {
objectMap.put(klass, obj);
}
}public static void main(String[] args) {
ServiceLocator.regist(JobQueue.class, new FileJobQueue());
ServiceLocator.regist(Transcoder.class, new FfmpegTranscoder());
JobCli cli = new JobCli();
cli.interact();
}public class JobCli {
public void interact() {
...
// JobQueue에만 의존
JobQueue jobQueue = ServiceLocator.get(JobQueue.class);
...
}
}서비스 로케이터의 단점
서비스 로케이터의 가장 큰 단점은 동일 타입의 객체가 다수 필요할 경우, 각 객체 별로 제공 메서드를 만들어 주어야 한다는 점이다.
구현 객체가 변경되거나 새로 필요할 때마다 코드가 함께 변경되어야만 하는 상황으로 개방 폐쇄 원칙을 완벽하게 어기게 된다.
DI를 사용하면 이런 상황이 발생하지 않는다.
각 객체가 사용할 의존 객체를 주입받아 사용하기 때문에, 의존하는 구현 객체가 변경되더라도 각 객체의 코드는 영향을 받지 않는다.
Worker w1 = new Worker();
w1.setJobQueue(new FileJobQueue());
Worker w2 = new Worker();
w2.setJobQueue(new DbJobQueue());서비스 로케이터의 또 다른 단점은 앞서 살펴본 것처럼 인터페이스 분리 원칙을 위배한다는 점이 있다.
서비스 로케이터를 사용하는 코드 입장에서, 자신이 필요한 타입 뿐만 아니라 서비스 로케이터가 제공하는 다른 타입에 대한 의존이 함께 발생하기 때문에, 다른 의존 객체에 의해서 발생하는 서비스 로케이터의 수정 때문에 영향을 받을 수 있게 된다.
❗ 부득이한 상황이 아니라면 서비스 로케이터보다는 DI를 사용하자.
챕터 7. 주요 디자인 패턴
전략(Strategy) 패턴
전략 패턴은 특정 콘텍스트에서 알고리즘(전략)을 별도로 분리하는 설계 방법이다.
전략 패턴에서 콘텍스트는 사용할 전략을 직접 선택하지 않고, 콘텍스트 클라이언트가 콘텍스트에 사용할 전략을 전달해 준다.
즉, 의존 주입을 이용해서 콘텍스트에 전략을 전달해 주는 것이다.
public class Maaaamin {
public static void main(String[] args) {
Customer firstCustomer = new Customer(new NormalStrategy());
// Normal billing
firstCustomer.add(1.0, 1);
// Start Happy Hour
firstCustomer.setStrategy(new HappyHourStrategy());
firstCustomer.add(1.0, 2);
// New Customer
Customer secondCustomer = new Customer(new HappyHourStrategy());
secondCustomer.add(0.8, 1);
// The Customer pays
firstCustomer.printBill();
// End Happy Hour
secondCustomer.setStrategy(new NormalStrategy());
secondCustomer.add(1.3, 2);
secondCustomer.add(2.5, 1);
secondCustomer.printBill();
}}
class Customer {
private List<Double> drinks;
private IBillingStrategy strategy;
public Customer(IBillingStrategy strategy) {
this.drinks = new ArrayList<Double>();
this.strategy = strategy;
}
public void add(double price, int quantity) {
drinks.add(strategy.getActPrice(price * quantity));
}
public void printBill() {
double sum = 0;
for (Double i : drinks) {
sum += i;
}
System.out.println("total : " + sum);
}
public void setStrategy(IBillingStrategy strategy) {
this.strategy = strategy;
}
}
interface IBillingStrategy {
Double getActPrice(Double rawPrice);
}
class NormalStrategy implements IBillingStrategy {
public Double getActPrice(Double rawPrice) {
return rawPrice;
}
}
class HappyHourStrategy implements IBillingStrategy {
public Double getActPrice(Double rawPrice) {
return rawPrice * 0.5;
}
}예제 코드를 보면 각 전략 객체를 생성하여 생성자에 전달하거나 set을 통해 전달하는것을 확인할 수 있다.
이는 콘텍스트를 사용하는 클라이언트가 전략의 상세 구현에 대한 의존이 발생한다는 것을 뜻한다.
콘텍스트의 클라이언트가 전략의 인터페이스가 아닌 상세 구현을 안다는 것이 문제처럼 보일 수 있으나,
전략의 콘크리트 클래스와 클라이언트 코드가 쌍을 이루기 때문에 유지 보수 문제가 발생할 가능성이 줄어든다고 볼 수 있다.
전략 패턴을 적용함으로써 콘텍스트 코드의 변경 없이 새로운 전략을 추가할 수 있다.
확장에는 열려 있고 변경에는 닫혀 있는, 개방 폐쇄 원칙을 따르는 구조를 갖게 되는 것이다.
템플릿 메서드 패턴
실행 과정/단계는 동일한데 각 단계의 구현이 다른 경우에 템플릿 메서드 패턴을 사용할 수 있다.
템플릿 메서드 패턴은 다음 두 가지로 구성된다.
- 실행 과정을 구현한 상위 클래스
- 실행 과정의 일부 단계를 구현한 하위 클래스
상위 클래스는 실행 과정을 구현한 메서드를 제공하고, 이 메서드는 기능을 구현하는데 필요한 각 단계를 정의하며 이 중 일부 단계는 추상 메서드를 호출하는 방식으로 구현된다.
public abstract class Authenticator {
// 템플릿 메서드
public Auth authenticate(String id, String pw) {
if (!doAuthenticate(id, pw) {
throw createException();
}
return createAuth(id);
}
protected abstract boolean doAuthenticate(String id, String pw);
private RuntimeException createException() {
throw new AuthException();
}
protected abstract Auth createAuth(String id);
}위 예제 코드에서 인증 여부를 확인하는 단계는 doAuthenticate() 추상 메서드로 만들어 두고,
Auth 객체를 생성하는 단계는 createAuth() 추상 메서드로 만들어 두었다.
authenticate() 메서드는 모든 하위 타입에 동일하게 적용되는 실행 과정을 제공하기 때문에 이 메서드를 템플릿 메서드라고 부른다.
이제 Authenticator 클래스를 상속받은 하위 클래스는 authenticate() 메서드에서 호출하는 다른 메서드만 알맞게 재정의해주면 된다.
하위 클래스는 전체 실행 과정 구현을 제공하지 않고 일부 과정의 구현을 제공한다(abstract).
전체 실행 과정은 상위 타입인 Authenticator의 authenticate() 메서드에서 제공하게 되는 것이다.
템플릿 메서드 패턴을 사용하게 되면 동일한 실행 과정의 구현을 제공하면서 동시에 하위 타입에서 일부 단계를 구현하도록 할 수 있으며,
이는 각 타입에서 코드가 중복되는 것을 방지하는 효과를 얻을 수 있다.
위의 예제에서 확인할 수 있듯이, 템플릿 메서드 패턴의 특징은 상위 클래스에서 흐름 제어를 한다는 것이다.
이렇게 상위 클래스에서 실행 시점이 제어되고, 기본 구현을 제공하면서, 하위 클래스에서 알맞게 확장할 수 있는 메서드를 훅(hook) 메서드라고 부른다.
상태(State) 패턴
상태 패턴은 기능이 상태에 따라 다르게 동작해야 할 때 사용할 수 있는 패턴이다.
상태 패턴에서는 상태를 별도 타입으로 분리하고 각 상태별로 알맞은 하위 타입을 구현한다.
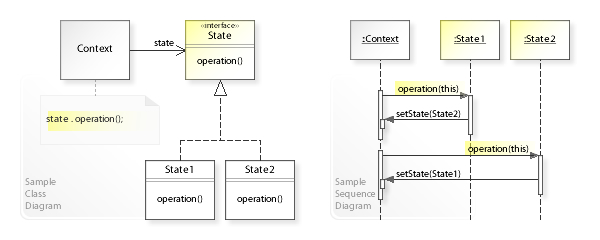
상태 패턴에서 중요한 점은 상태 객체가 기능을 제공한다는 점이다.
위 그림에서 State 인터페이스는 operation()이라는 메서드를 정의하고 있으며, 이 메서드는 모든 상태에 동일하게 적용되는 기능이다.
public class StateNumberOne implements State {
@Override
public void operation() {
...
}
}
public class StateNumberTwo implements State {
@Override
public void operation() {
...
}
}public class StateTest {
private State state;
public StateTest() {
state = new StateNumberOne();
}
public void changeState(State newState) {
this.state = newState;
}
public void doOperation() {
state.operation(); // 상태 객체에 위임
}
}위 예제 코드를 보면 StateTest에 구현되어 있는 동작 구현 코드가 각 상태의 구현 클래스로 이동함을 알 수 있다.
상태 객체에 코드 구현을 위임함으로써 코드가 단순해지는 효과를 얻을 수 있다.
또한 새로운 상태가 추가되더라도 콘텍스트 코드가 받는 영향을 최소화할 수 있다.
또 다른 장점으로는 상태에 따른 동작을 구현한 코드가 각 상태별로 구분되기 때문에 상태 별 동작을 수정하기가 쉽다는 점이 있다.
만약 상태 패턴을 이용하지 않고 조건문을 이용한 방식을 사용하는 경우 동작을 수정하려면 각 메서드를 찾아다니며 수정해 주어야 하는데,
상태 패턴을 적용한 경우에는 해당 상태 클래스만 수정해주면 된다.
관련된 코드가 한 곳에 모여 있어 안전하고 빠르게 구현을 변경할 수 있게 된다.
상태 변경을 누가 할지는 주어진 상황에 알맞게 정해 주어야 한다.
콘텍스트에서 상태를 변경하는 방식은 상태 개수가 적고 규칙이 거의 바뀌지 않는 경우 유리하다.
상태 객체에서 콘텍스트의 상태를 변경하는 경우는 콘텍스트에 영향을 주지 않으면서 상태를 추가하거나 변경 규칙을 바꿀 수 있지만,
변경 규칙이 여러 클래스에 분산되어 있어 상태 구현 클래스가 많아질수록 규칙을 파악하기가 어려워진다. (또한 상태 클래스간 의존도 발생함)
