[TIL] HashTable

What I learned today :)
✨ Linked List
🙀 Hash Table 📌HashTable 이란?
해시테이블은 키-값 쌍을 저장하는 자료구조라서, 해시 맵이라고도 불린다.
참고)
Map 객체는 키-값 쌍을 저장하며 각 쌍의 삽입 순서도 기억하는 콜렉션입니다.
아무 값(객체와 원시 값)이라도 키와 값으로 사용할 수 있습니다.
( HashTable 구현할 때 map.prototype.get && set사용해보기)key와 value로 데이터를 저장하는 자료구조 중 하나이다.
해시 테이블은 키를 저장할 때에 메모리 공간을 덜 사용할 수 있도록,
키를 "해시 함수"(Hash function)라는 함수를 통해 특정 숫자값의 인덱스로 변환해는 구조라서
공간을 소모하여 시간을 얻는 방법 혹은 가장 빠른 데이터를 검색하는 방법이라고 부르기도 한다고 한다.
HashTable 동작 구조
F(key) -> HashCode -> Index -> Value
1. 검색하고자하는 key값을 입력받아
2. 해쉬함수를 돌려서 반환받은 HashCode를
3. 배열의 Index로 환산해서
4. 데이터에 접근하는 자료구조이다.
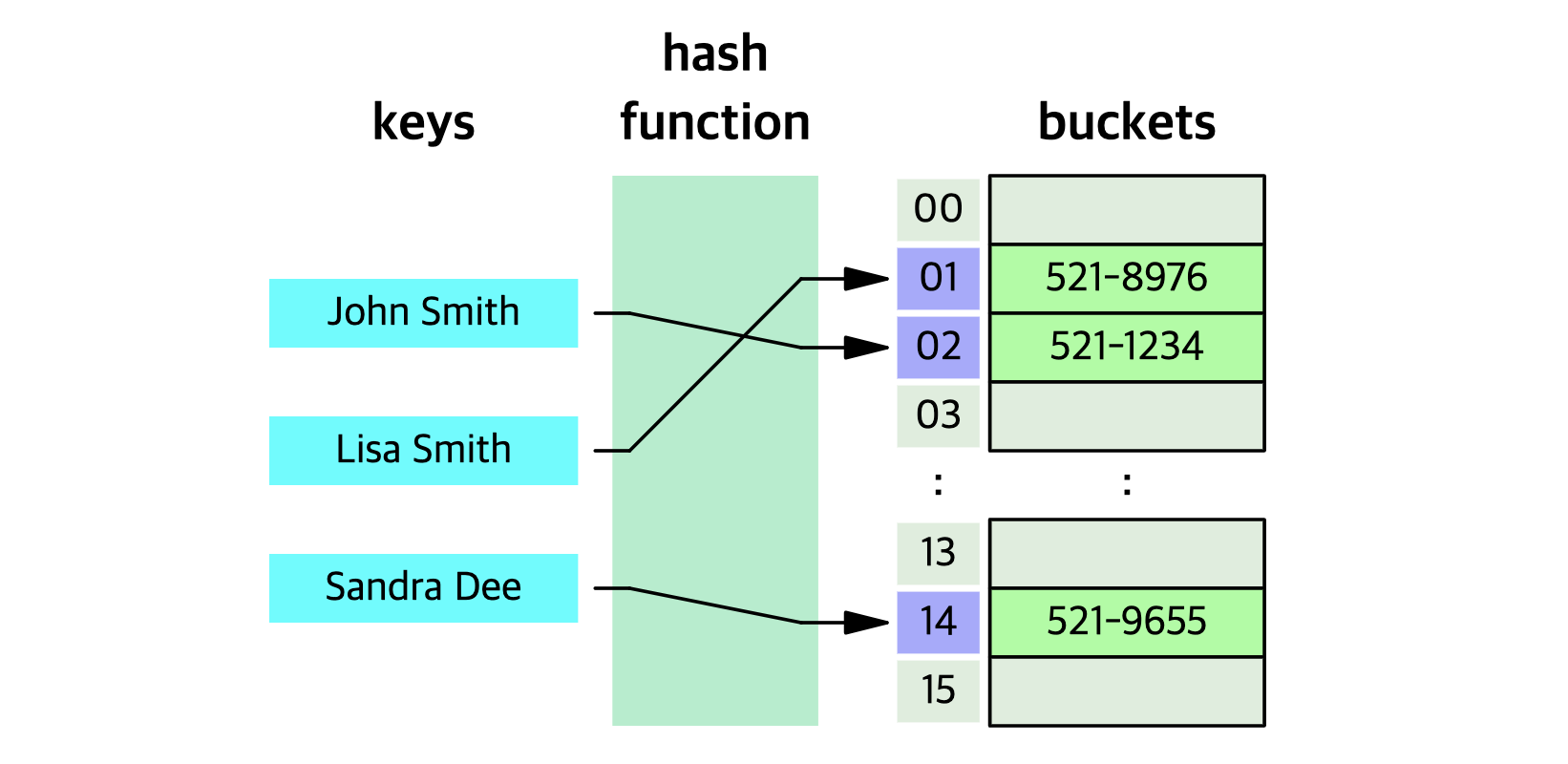
Hash함수는 데이터를 효율적으로 관리하기 위하여, 주어진 Key값을 고정된 배열 공간에 매핑하는 작업을 한다.
해쉬함수의 특징은 어떠한 특정한 규칙을 사용해 key의 크기 상관없이 동일한 HashCode를 만든 후
먼저 만들어진 고정된 배열 공간에 HashCode를 배열의 개수만큼 나머지 연산(index === '해쉬화 된 key')을 하여 배열에 나눠담는다.
이러한 구조는 HashCode자체가 배열의 인덱스의 역할을 하게되어 곧바로 데이터에 접근이 가능해져 검색 속도가 빨라진다는 장점을 가지고 있다. O(1)만큼의 시간을 소요함.
[요약]
해시함수 : '키'를 → "해시 함수"(Hash function)라는 함수를 통해 → 특정 숫자값(buckets)의 인덱스로 변환
HashFunction의 특징은
1. 항상 내가 가지고 있는 어레이의 크기, 안에서 값이 나와야 함
ex) 고정된 어레이의 크기는 7로 가정.
'dog'라는 Key를 넣었는데 13이 나오면 해당 값을 뽑아낼 수 없음.
따라서 0~length-1의 값만 반환 시켜줄 수 있어야 함.
2. 언제든지 넣었을 때 같은 값이 나와야 함.
ex) 언제는 dog를 넣었는데 4가 나오고 언제는 5가 나오면 안됨.
따라서 값은 항상 일정하여야 한다.
3. Hash Function은 '저장'이란걸 할 수 없다.
그냥 그 때 그 때 해시함수를 작동시켜 Key를 주면 값을 줄 수 있어야 한다.
단, Hash Algorism이 잘못 짜여져서 한 방에 여러 데이터들이 몰리게 되면 collision(충돌)이 일어나게 되는데,
O(n)만큼의 시간이 소요될 수 있게 된다.
Collision (충돌)
하나의 배열방에 겹쳐서 들어오는 경우를 Collision이 발생했다고 한다.
Collision 해결 방법
-
Separate Chaining
해시 충돌이 발생하면 Linked List(연결리스트)로 데이터들을 연결하는 방식이다.
이는 collision이 생길 때를 대비해 데이터를 바로 배열 방에 저장하지 말고,
하나의 배열 방 안에 Linked List를 선언하고 -> 데이터가 배열 방에 할당이 될 때 마다 Linked List에 데이터를 추가해보도록 하자.
이 때, 검색 요청이 들어왔을 때는 검색할 키의 HashCode를 index로 환산한 후
해당 방의 List들을 돌면서 찾고자하는 데이터를 가져오면 된다. -
Open Addressing
해시 충돌이 일어나면 다른 버켓에 데이터를 삽입하는 방식이다.
Hash Table Resizing
Hash Table은 필요할 때에만 메모리 크기를 늘리고, 가능한 작은 크기를 유지한다.
Hash Table은 storage 안에 있는 값들이 25% ~75%의 범위 안에 존재할 때 효과적으로 작동된다.
만약 75%를 초과하게 될 경우, storage의 사이즈를 2배 늘려주고
만약 25% 이하로 내려가려 한다면 사이즈를 반으로 줄여주면 된다.이렇게 리사이징을 해주면 자료가 들어올 때마다 커지고, 빠질 때마다 작아지기 때문에 O(1)을 유지할 수 있다.
단, 75% 초과로 Hash Table을 늘릴 때 Hashing을 다시 해줘야하는데
이로인해 O(n)의 시간이 걸릴 수 있다.
따라서, 이를 방지하기 위해 사이즈를 키우고 줄이는 Hash Function을 잘 만드는 것이 관건이다.어디서 사용이 될까?
암호화폐 각 개인의 공공 장부들을 확인할 때 사용이 된다고 한다.
이에 대해서는 따로 어떻게 활용되는지 공부를 해봐야할 것 같다.정리
HashTable 장점
1. 검색 속도가 매우 빠르다. - 배열은 반복문을 돌려 값을 찾아야하지만, HashTable은 Key: Value의 데이터 저장방식이라 Key만 있다면 바로 원하고자 하는 값을 찾을 수 있음. - 즉, Hashing이 Key를 가진 인덱스를 사용하기에 삽입, 삭제, 검색이 빠르다. - Collision이 별로 없다면 일정하게 O(1) !!HashTable 단점
1. 무작위 주소 부여로 collision 발생으로 골치 아파짐. - 따라서 Hash Function을 잘~~~ 만들어놔야한다. 2. HashTable의 크기는 정해져있어져 있고(유한성) && 하나의 bucket에 여러 값들이 들어가게 되면 Collision 발생 가능성 높아짐 3. Collision이 발생할 수록 O(n)..!!
