1. 배치(batch)란?
배치는 데이터를 실시간으로 처리 하지 않고 일괄적으로 모아서 처리하는 작업입니다. 이는 사용자의 요청에 대해 즉각적인 응답을 필요로 하지 않은 서비스에 적용이 가능합니다.
배치의 핵심을 한 줄로 나타내면 “대량의 데이터를, 특정 시간에, 일괄적으로 처리한다” 로 볼 수 있습니다. 이렇게 정의한 배치의 핵심을 하나씩 뜯어서 예시로 살펴보겠습니다.
이러한 배치의 개념과 반대에 위치한 것이 OLTP 방식입니다. Online Transaction Processing, 온라인 트랜잭션 처리, 즉 네트워크 상의 여러 이용자가 실시간으로 데이터 베이스의 데이터를 갱신하거나 조회하는 등의 단위 작업을 처리하는 방식을 말합니다. 다수의 이용자가 거의 동시에 이용할 수 있도록 송수신 자료를 트랜잭션 단위로 압축하고 각각의 데이터 처리 역시 이렇게 압축한 트랜잭션 단위로 처리하게 됩니다.
배치를 가장 잘 설명할 수 있는 예시를 살펴보면, 많은 사람들이 은행에 관련된 예시가 많습니다. 은행에는 실시간으로 처리해야 하는 OLTP 방식과 배치, 크게 2가지의 동작 기능을 가지고 있다고 볼 수 있습니다.
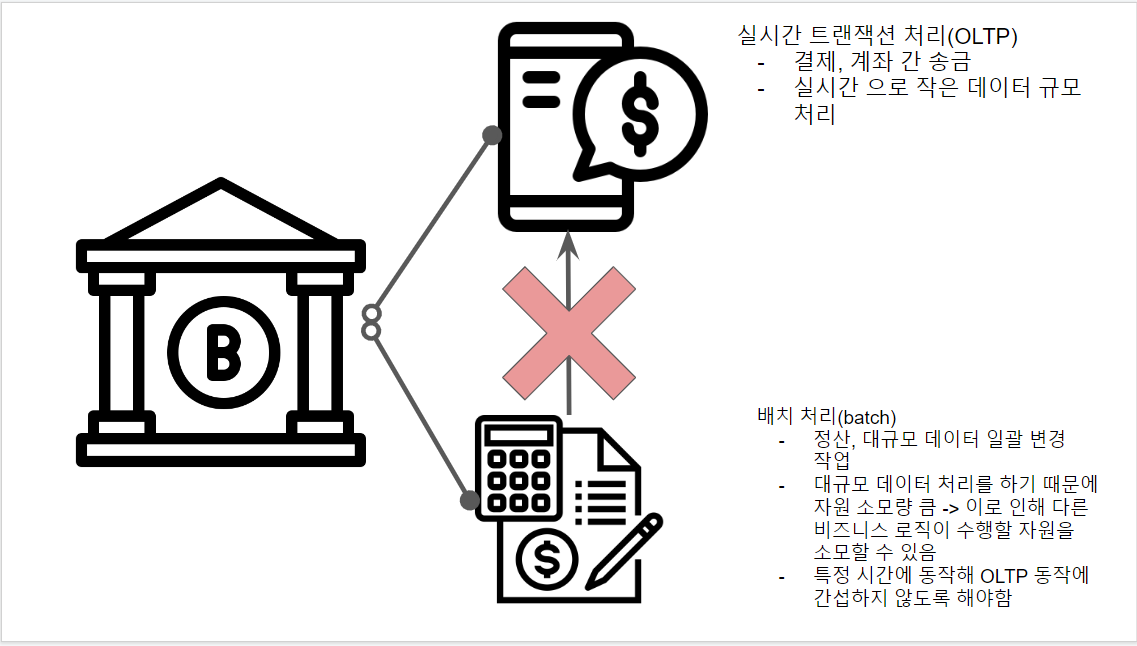
(은행의 송금 기능과 정산 기능, 아이콘 출처 : 은행 아이콘, 송금 아이콘, 정산 아이콘 이미지 출처 : 나)
그렇다면 이러한 은행의 많은 기능들 중 송금 기능과 정산 기능을 살펴봅시다. 송금은 데이터를 실시간으로 처리해야 하는 OLTP 방식입니다. 우리가 은행에서 송금을 할 때 우리가 보낸 돈이 다음 날에 이체되지 않습니다. 사용자의 요청에 실시간으로 처리하고 응답해야 하는 기능입니다. 간혹 여기서 배치와 혼동할 수 있는 부분이 있는데요, 실시간, 동시다발적으로 많은 요청들, 데이터가 들어와 처리해야 하니 이것도 배치로 불 수 있지 않느냐, 라고 물어볼 수 있습니다. 동시다발적으로 많은 데이터가 들어오지만, 이것을 한 번에 처리하지 않습니다. 하나의 요청에는 하나의 트랜잭션과 맞물려 처리하기 때문입니다. 즉, 순간적으로 많은 데이터를 처리하지만 처리하는 트랜잭션은 하나의 요청과 대응하기 때문에 데이터의 규모가 작아지게 됩니다.
정산 기능을 살펴봅시다. “대량의 데이터를, 특정 시간에, 일괄적으로 처리한다”라는 배치의 핵심 특징을 봅시다. 정산은 송금처럼 요청 데이터 하나에 대응하지만 데이터의 규모는 모든 회원을 대상으로 합니다. 이것이 “대량의 데이터”에 해당합니다.
이렇게 대용량의 데이터를 처리하게 되면 작업량 자체가 어마어마하게 많기 때문에 리소스를 많이 사용하게 됩니다. 그렇다면 실시간으로 데이터를 처리해야 하는 송금과 리소스를 많이, 오래 사용하는 배치가 동시에 진행된다고 생각해봅시다. 실시간 트랜잭션(송금)을 처리할 리소스가 없어 송금이 지연되거나 불가능해지는 상황이 발생할 것입니다. 이렇게 대규모 데이터 처리 작업의 경우 리소스를 점유하고 주요 비즈니스 로직의 동작을 방해하지 않게 하기 위해 특정 시간(비즈니스 로직의 동작이 덜 발생하는 시간)에 배치가 동작하게 되는 것입니다. 이것이 “특정 시간에”에 해당합니다.
데이터를 가져온 후 이 데이터를 나눠서 꾸준히 처리하는 것이 아니라 배치가 동작하는 시간에 한꺼번에 처리합니다. 이것이 “일괄적으로 처리한다”에 해당합니다.
배치 애플리케이션이 필요한 이유와 개념을 예시를 통해 살펴보았습니다. 이러한 배치 애플리케이션을 구현하기 위해서는 아래의 요소들을 고려해야 합니다.
- 대용량 데이터 : 배치 애플리케이션은 대량의 데이터를 가져오거나, 전달하거나, 계산하는 등의 작업이 있어야 합니다.
- 자동화 : 특정 상황을 제외하고 통상적으로 사용자의 개입 없이 실행 가능해야 합니다.
- 견고성 : 잘못된 데이터를 충돌 혹은 중단 없이 처리할 수 있어야 합니다.
- 신뢰성 : 로깅 혹은 알림을 통해 오류가 발생한 부분을 추적할 수 있어야 합니다.
- 성능 : 지정한 시간 내에 처리를 완료 하거나 배치 애플리케이션과 동시에 수행 하고 있는 다른 애플리케이션을 방해하지 않아야 합니다.
2. Spring batch
2-1. spring batch 소개
Spring batch가 등장하기 전에는 자바 진영에서 표준 배치 기술이 없었습니다. 사용자가 자바를 통해 배치의 기능과 동작을 직접 구현하거나 다른 프레임 워크에서 동작하는 배치 기능을 가져와서 사용했습니다.
그러나 점점 대규모 데이터 처리에 대한 수요가 늘어 났고 이에 따라 자바 기반의 배치 아키텍처인 Spring batch가 탄생하게 됩니다. 물론 단순한 자바 기반이 아니라 Spring 기반이기 때문에 DI, AOP, 서비스 추상화가 가능하기 때문에 등장하면서 많은 각광을 받습니다.
2-2. 주요 특징
Spring batch가 제공하는 기능들은 다양하지만 대표적인 부분으로 간추리자면 크게 4가지 요소로 볼 수 있습니다.
- Logging, 추적, 트랜잭션 관리, 작업 처리 통계, 리소스 관리 등 최적화 및 파티셔닝 기술을 통해 대용량의 레코드 처리 및 고성능 배치 작업을 할 수 있도록 서비스를 제공하는 필수적인 기능을 가지고 있습니다.
- spring batch의 가장 중요한 핵심 특징 중 하나는 바로 restartability 입니다. 배치 수행이 실패하면 데이터의 처음부터 배치를 수행하는 것이 아니라 실패한 지점부터 다시 배치를 실행합니다. 간단히 예를 들어보면 배치를 처리하던 중 3000번째의 데이터에서 배치 실패가 발생합니다. 이 때 배치가 다시 동작하면 3001번 데이터부터 배치 수행이 다시 시작하게 됩니다.
- 다른 핵심 특징으로는 중복 실행 방지가 있습니다. 배치가 성공적으로 수행된 후 동일한 parameter로 실행 시도 시 exception을 내보내 동일한 배치 동작을 연속적으로 수행하지 않도록 합니다.
- Spring batch는 그 자체로 주기적, 반복적 수행을 할 수 없습니다. 이는 우리가 Spring batch를 사용할 때 scheduler와 조합해서 사용하는 이유이기도 합니다. 그 중 대표적으로 Quartz와 같이 사용합니다. Spring batch는 대용량 데이터 배치 처리에 대한 기능을 제공하지만 scheduler로서 동작 기능이 없기 때문에 외부에서 scheduler에 의해 실행됩니다. 쉽게 생각하면 scheduler에 의해 Spring batch가 실행되는 구조라고 보면 됩니다.
위의 언급한 2, 3번 특징은 리소스 사용 측면에서 효율적입니다. 불필요한 작업들을 줄이고 리소스를 사용해야할 지점에서 사용함으로서 배치 애플리케이션의 무게를 좀 더 가볍게 만들어 줍니다. 그리고 이러한 특징은 많은 배치 애플리케이션 중 Spring batch를 선택하게 만드는 이유가 되기도 합니다.
2-3. 동작 시나리오 및 패턴
배치의 핵심 패턴은 3가지로 read, process, wirte 로 구성되어 있습니다.
- read : DB, 파일, 큐 등에서 대량의 데이터를 조회
- Process : 데이터를 가공함
- wirte : 가공된 데이터를 조회한 DB 혹은 다른 DB에 저장
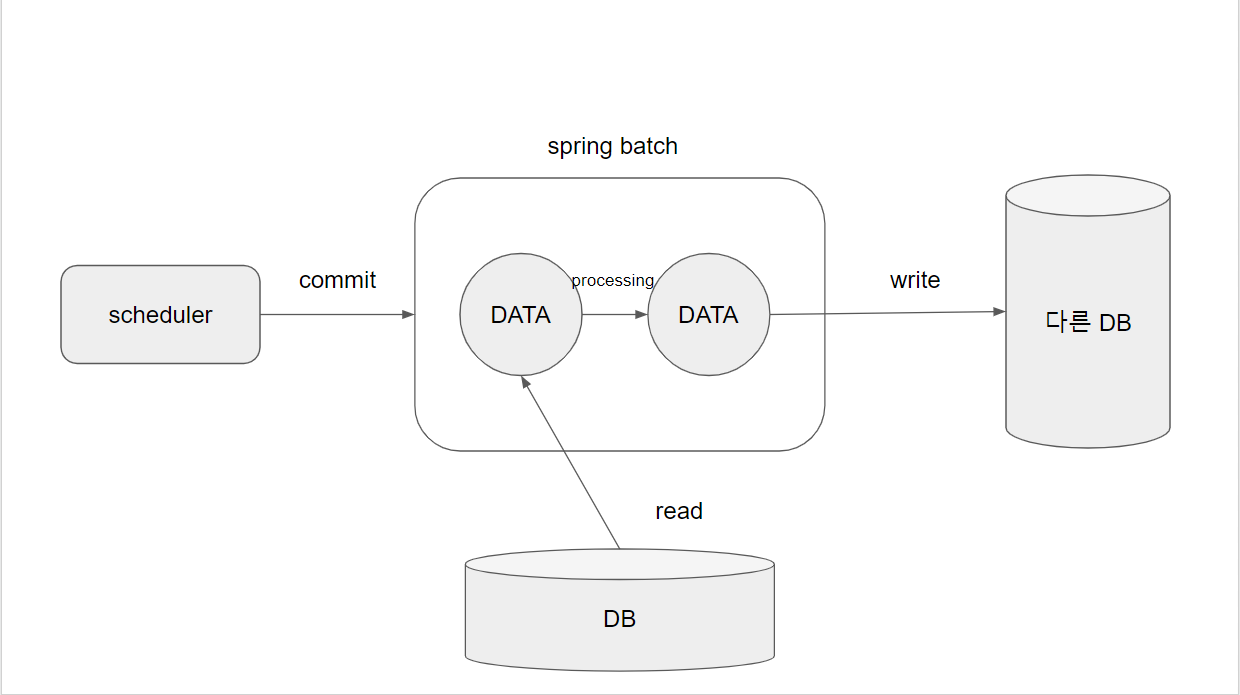
(spring batch의 동작 시나리오, 이미지 출처 : 나)
Sprng batch의 특징에서도 다뤘듯이 Spring batch는 scheduler에 의해 동작합니다. Spring batch는 DB에서 데이터를 read 하고 이렇게 조회한 데이터를 processing을 통해 가공합니다. 그리고 spring batch는 가공한 데이터를 다른 DB에 write합니다.
이러한 일련의 과정을 크게 보면 ETL 패턴이라고 부릅니다.
데이터를 추출하고(Extract) 가공하고(Transform) 다른 DB에 적재 혹은 저장(Load)합니다. 추출한 데이터를 청크 단위로 처리하는데 청크 기반이기 때문에 다양한 확장 기능들을 덧붙일 수 있습니다.
2-4. 왜 spring batch를 쓸까
먼저 자바 진영에서 Spring이 가지고 있는 위상을 생각해봅시다. 압도적인 1황에 위치해 있습니다. Spring batch는 Spring 기반이기 때문에 Spring의 기본적인 특징을 가지고 있습니다. 특히 우리 나라의 경우 자바 기반의 웹 개발은 Spring 위에서 만들어지는 경우가 대다수이기 때문에 보다 개발의 편의성을 더할 수 있습니다.
보다 깊이 들어가자면 우리가 웹 개발 시 Spring MVC를 사용하는 이유는 개발 과정에서 개발자가 이것 저것 고려할 부분 없이 오로지 비즈니스 로직을 개발하는데 집중할 수 있는 환경을 만들어주기 때문입니다. Spring batch도 마찬가지입니다. 우리는 배치 애플리케이션 구현 시 비즈니스 로직 외에 부가적으로 신경 써야할 부분이 많습니다. 이 때 Spring batch는 Spring MVC처럼 개발자들이 온전히 비즈니스 로직의 개발에만 집중할 수 있도록 합니다. 이와 연결되는 사항 중 하나로 바로 확장성과 안정성을 볼 수 있습니다. 과거 메인 프레임 방식이나 배치를 커스텀으로 개발해서 처리 했던 방식은 배치 내 Job들의 병렬 처리 시 고려할 사항이 많았습니다. 결국 이로 인해 배치 프로그램의 확장성과 안정성이 떨어지는 결과를 초래했고 Sping batch는 개발자들이 더 이상 이러한 부분에서 고민하지 않도록 만들어 준 것입니다.
워크로드의 조정 또한 용이한데 Spring Cloud Data Flow를 통해 GUI로 각각의 테스크를 조정할 수 있습니다.
더불어 Spring batch는 오픈소스입니다. 많은 기능들을 제공해주는 Spring batch를 아무 비용 없이 공짜로 사용할 수 있다는 것, 이것도 중요한 장점 중 하나라고 볼 수 있겠습니다.(ㅋㅋㅋㅋ)
2편에서 다룰 내용은 Spring batch의 구성 요소 및 상세 계층들을 살펴볼 예정입니다.
*REFERENCE
https://jojoldu.tistory.com/324?category=902551
https://limkydev.tistory.com/140
https://velog.io/@jch9537/한-줄-용어배치Batch란
https://heekng.tistory.com/171
https://yongku.tistory.com/entry/스프링-배치Spring-Batch와-Quartz
https://sjh836.tistory.com/187
https://www.fwantastic.com/2019/12/spring-batch-intro.html
