
내용 소개
- relational data model (관계형 데이터 모델)이란?
- domain, attribute, tuple 개념
- relation, relational database 개념
- relation 특징 소개
- null의 의미
- key 개념과 종류
- constraints 개념과 종류
⭐️ Relational data Model이란?
Relational?
Relational Data Model을 이해하기 위해서는 Relational이란 무엇인지 알아야합니다. Relational은 수학에서 나온 개념입니다..
우선 설명에 필요한 배경지식 먼저 설명하겠습니다.
set
- 서로 다른 elements를 가지는 collection
- 중복된 elements를 가지지 않는다.
- 하나의 set에서 elements의 순서는 중요하지 않다. 또한 중복된 elements를 가지지 않는다.
- e.g. {1, 3, 11, 4, 7}
set에 대한 개념을 이해했으니까 이제 수학에서 relation이 무엇을 의미하는지 알아봅시다.
📌 수학에서 말하는 Relation

set A는 elements 1, 2를 가지고 있고, set B는 elements p, q, r를 가지고 있습니다.
이제 set A에서 하나의 엘리먼트를 고르고, set B에서 하나의 엘리먼트를 골라서 두 개의 엘리먼트로 페어를 만들어보겠습니다.
(1, p}, (1, q), (1, r), (2, p) ... 등이 만들어질 수 있습니다.
이처럼 가능한 모든 페어에 조합을 수학으로는 어떻게 표현할까요?
Cartesian product - A X B 로 표현합니다.
갑자기 Cartesian product가 왜 나오지? 생각할 수도 있습니다.
왜냐하면 수학에서 말하는 relation이 Cartesian product와 관련이 있기 때문입니다.
이전에 설명한 A X B의 부분 집합은 binary relation이라고 하고, A X B에 대한 Caresian product에 부분 집합이 됩니다.
이것이 바로 수학에서 말하는 Relation의 개념입니다.
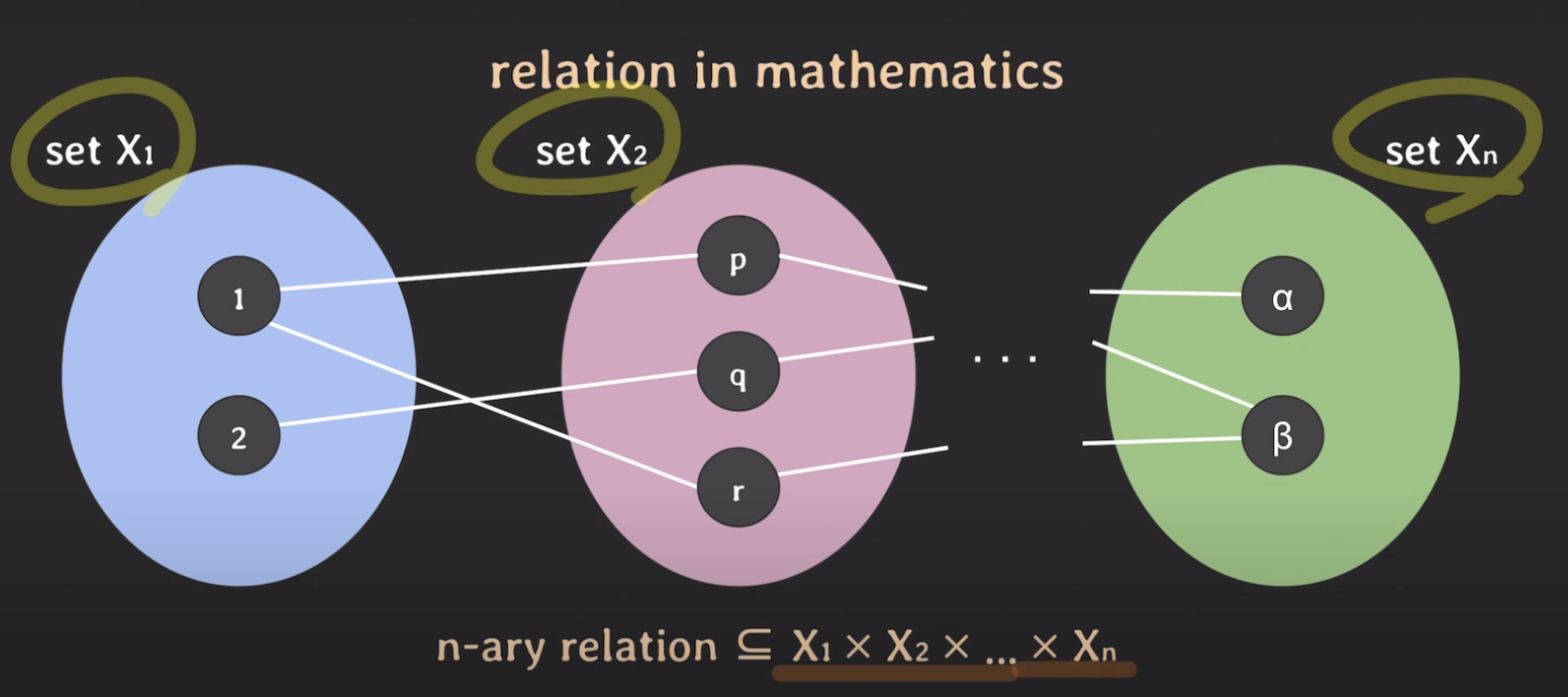
그럼 이 개념을 확장시켜 보겠습니다.
지금의 예시는 set이 2개뿐이지만 set이 계속 늘어나서 n개의 set이 있다고 했을 때 이것에 대한 Cartesian product는 X1 x X2 x ... x Xn으로 표기합니다.
이때의 Relation은 어떻게 표기하냐면 n-ary relation으로 표기합니다.
그리고 1 - p - alpha, 1 - r - beta 등의 리스트는 각각 튜플로 부를 수 있습니다.
- n개의 집합에 대한 튜플이기 때문에 n-tuple 이라고 부릅니다.
여기까지 고생하셨습니다. 이제 정리를 해보겠습니다.
정리
수학에서의 relation은
- subset of Caresian product이다.
- 혹은 set of tuples이다.
📌 Relational Model에서의 Relation
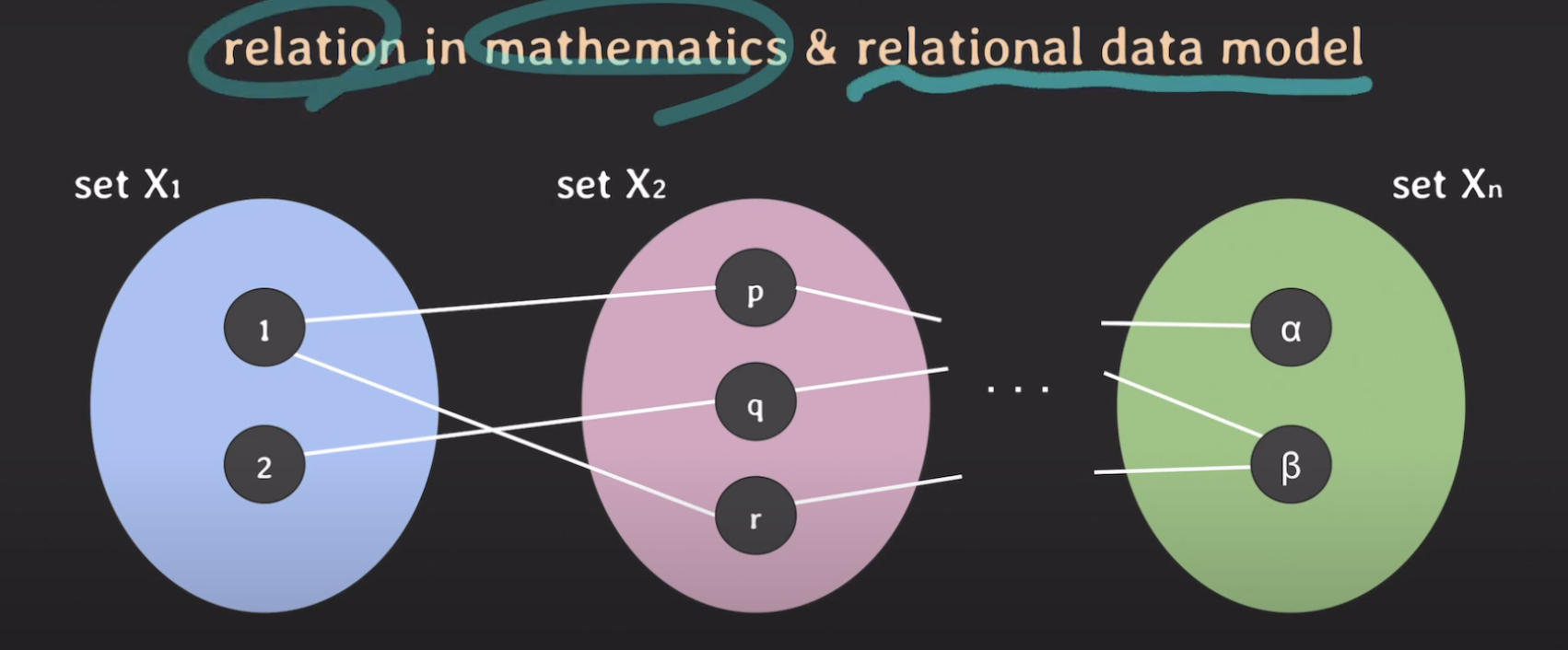
수학에서의 Relation에 대해 알아봤으니 이제 Relational data model에서 Relation이 어떻게 적용되는지 알아보겠습니다.
먼저 Set부터 알아봅시다.
Relational data model에서 set은 도메인을 의미합니다.
여기서 도메인은 element 또는 value들의 집합입니다.
또한 각 도메인마다 set X1처럼 이름도 붙일 수 있습니다. 그리고 튜플 또한 가지며 전체 도메인 집합을 Relation이라고 합니다.
학생들의 정보를 저장하는 student relation을 예를 들어 Relational data model을 이해해 보겠습니다.
설명에 앞서 student relation에 관련된 도메인을 정의하겠습니다.
domain 정의하기
- students_ids: 학번 집합, 7자리 integer 정수
- human_names: 사람 이름 집합, 문자열
- university_grades: 대학교 학년 집합, {1, 2, 3, 4}
- major_names: 대학교에서 배우는 전공 이름 집합
- phone_numbers: 핸드폰 번호 집합
정의된 domain을 가지고 stdent relation을 만들어 봅시다.
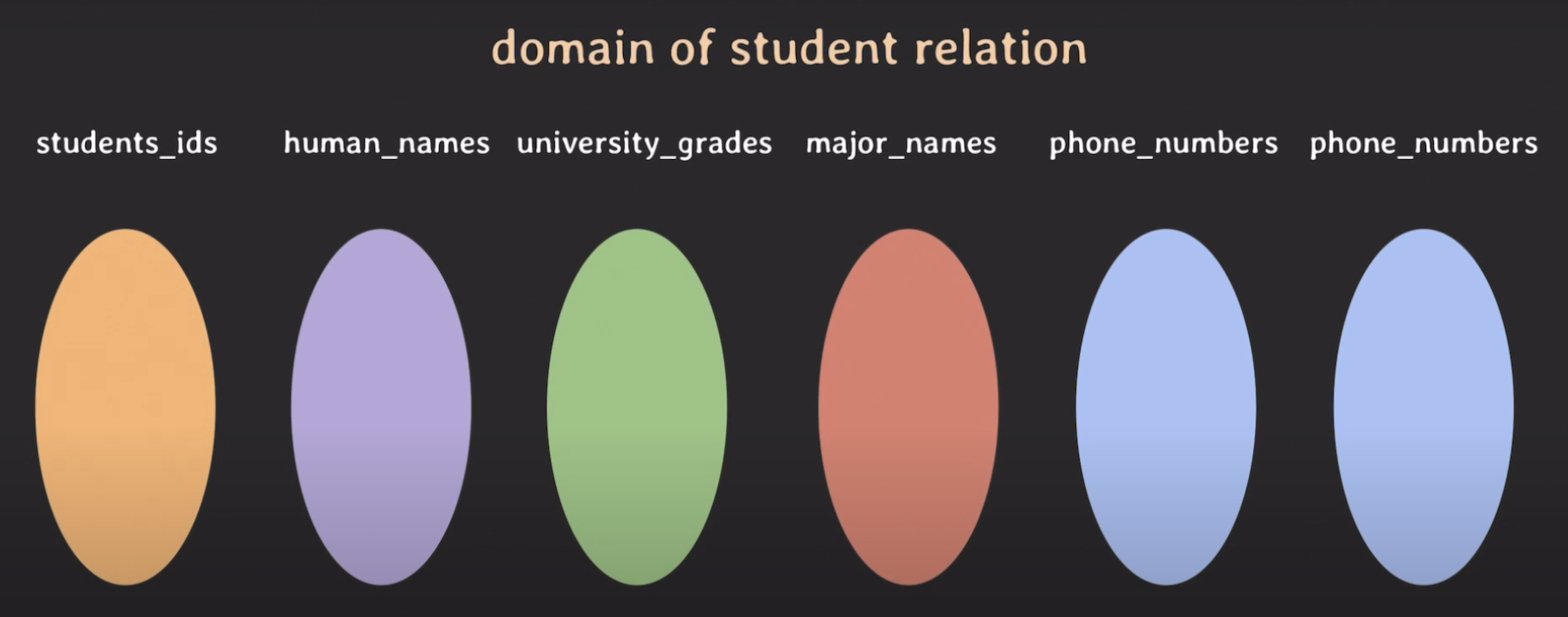
최대한 수학적 모델과 비슷하게 해보겠습니다.
사진을 잘 보시면 phone_numbers가 두 번 나타납니다. student relation을 데이터 모델을 통해서 나타내려고 하다 보니까 학생의 비상연락망 또한 가지고 있어야 되겠다는 생각이 있어 하나의 domain을 추가했습니다.
같은 domain이지만 사용되는 목적과 역할이 다릅니다. 이런 역할을 표시해주기 위해서 Relational data model에서는 추가적으로 익숙한 개념이 등장합니다.
바로 attribute입니다. 각각의 도메인들이 Relation에서 어떤 역할을 수행하는지 역할에 이름을 붙여주는데 그게 바로 attribute입니다. attribute를 추가해보겠습니다.
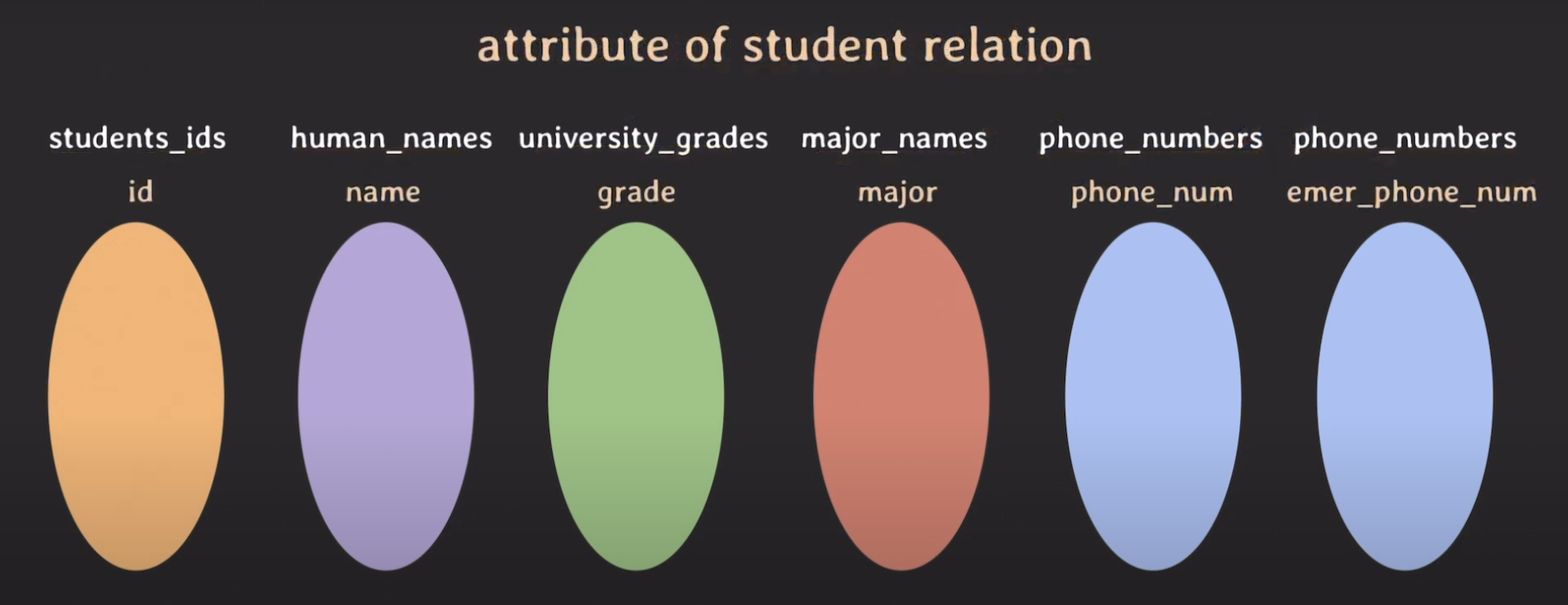
attrubute를 지정해줬습니다. attribute가 Relation에서 어떤 의미인지 이해가 되시나요?
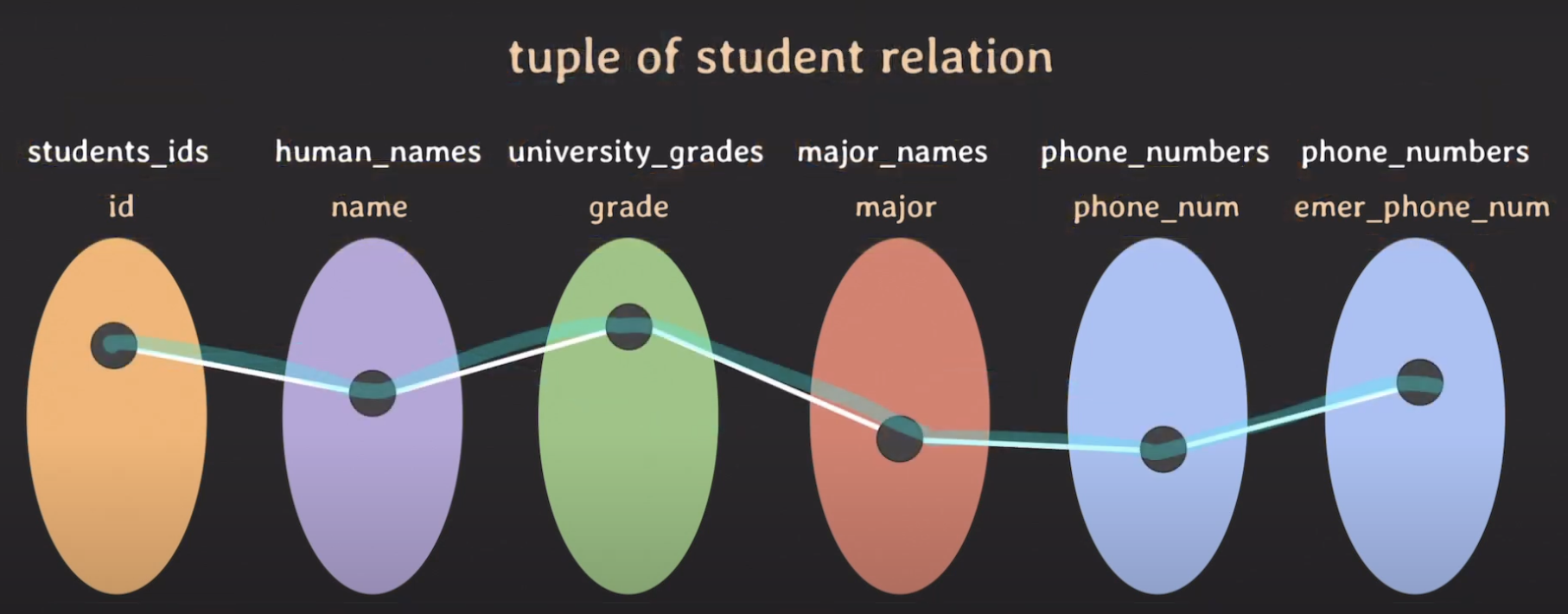
각각의 도메인은 값들의 집합이기 때문에 도메인마다 값들이 있을 것이고, 값들 중에서 실제로 데이터로서 존재하는 튜플들이 다 있을 겁니다. 그래서 student relation에서는 튜플이 사진처럼 표시가 됩니다.
그러나 Relational data model을 표현할 때 그림으로 잘 표현하지는 않습니다.
가장 잘 표현할 수 있는 방법은 테이블입니다. 그래서 Relational data model을 테이블이라고 많이 소개하는 것입니다.
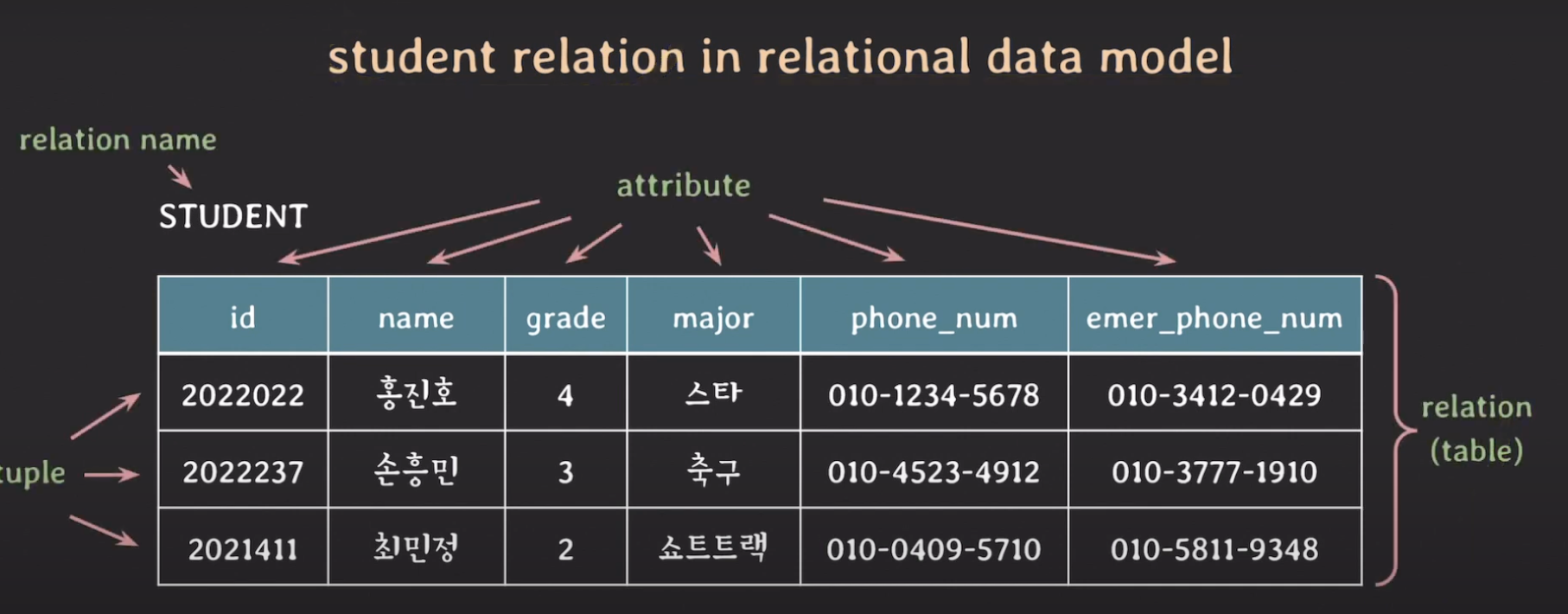
Relation을 data model에서는 위 사진처럼 테이블로 표시가 됩니다.
여기서 id, name 등이 각각 attribute가 되는 것입니다.
그리고 attribute 각각의 값들로 이루어진 리스트, 그것을 tuple이라고 합니다.
Relational data model에서의 주요 개념 정리
| 주요 개념 | 설명 |
|---|---|
| domain | set of atomic values |
| domain name | domain 이름 |
| attribute | domain이 relation에서 맡은 역할 이름 |
| tuple | 각 attribute의 값으로 이루어진 리스트. 일부 값을 NULL일 수 있다. |
| relation | set of tuples |
| relation name | relation의 이름 |
📌 Relation schema
- relation의 구조를 나타낸다.
- relation 이름과 attributes 리스트로 표기된다.
- e.g. STUDENT(id, name, grade, major, phone_num, emer_phone_num)
- attributes와 관련된 constranints도 포함한다.
📌 degree of a relation
- relation schema에서 attribute의 수
- e.g. STUDENT(id, name, grade, major, phone_num, emer_phone_num) -> degree 6
📌 Relational database
- relational data model에 기반하여 구조화된 database
- relational database는 여러 개의 relations로 구성된다.
relational database schema
- relation schemas set + integrity constraints set
자 여기까지 오시면 Relation이 어떤 의미인지 파악을 하셨을거고 왜 Relation이라고 부르는지 이해가 될겁니다. 이제 Relation의 특징을 살펴봅시다.
⭐️ Relation 특징
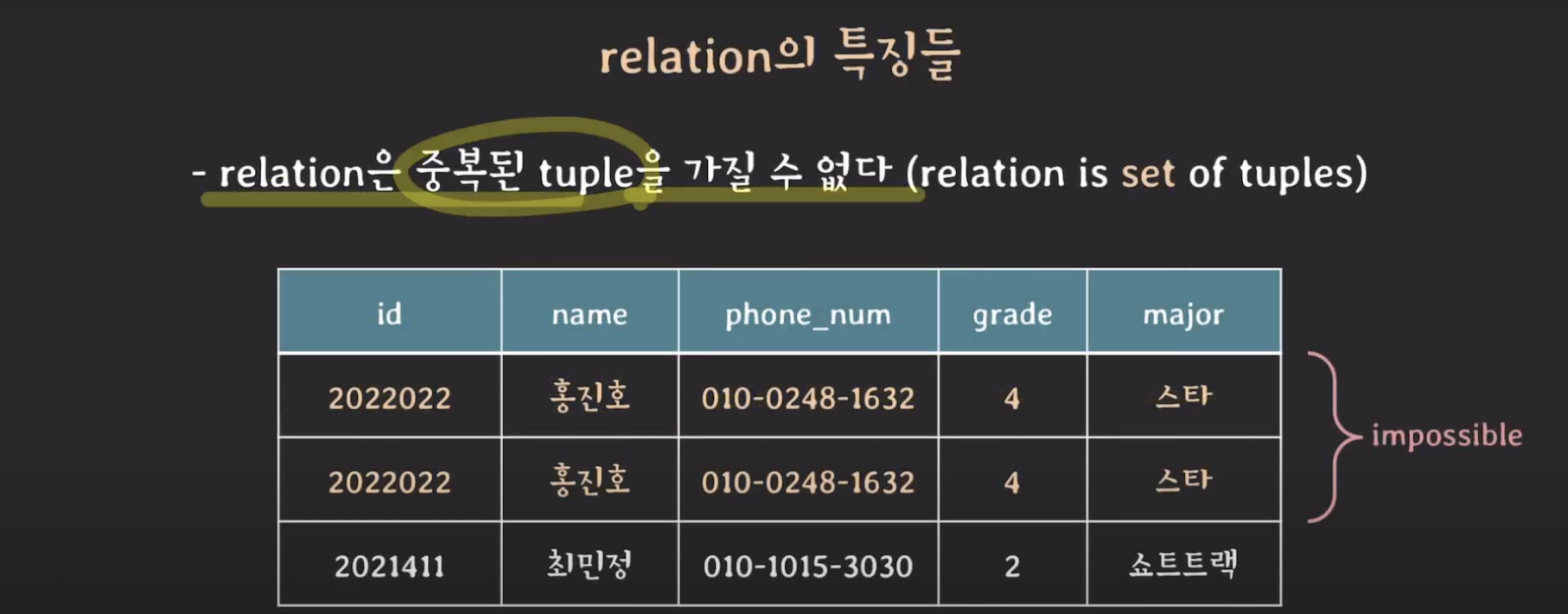
-
우선 Relation은 중복된 tuple을 가질 수 없다. (relation is set of tuples)
-
relation의 tuple을 식별하기 위해 attribute의 부분 집합을 key로 설정한다.
-
relation에서 tuple의 순서는 중요하지 않다.
-
하나의 relation에서 attribute의 이름은 중복되면 안된다.
-
하나의 tuple에서 attribute의 순서는 중요하지 않다.
-
attribute는 atomic 해야 한다. (composite or multivalued attribute 허용 X)
⭐️ NULL의 의미
- 값이 존재하지 않는다.
- 값이 존재하나 아직 그 값이 무엇인지 알지 못한다.
- 해당 사항과 관련이 없다.
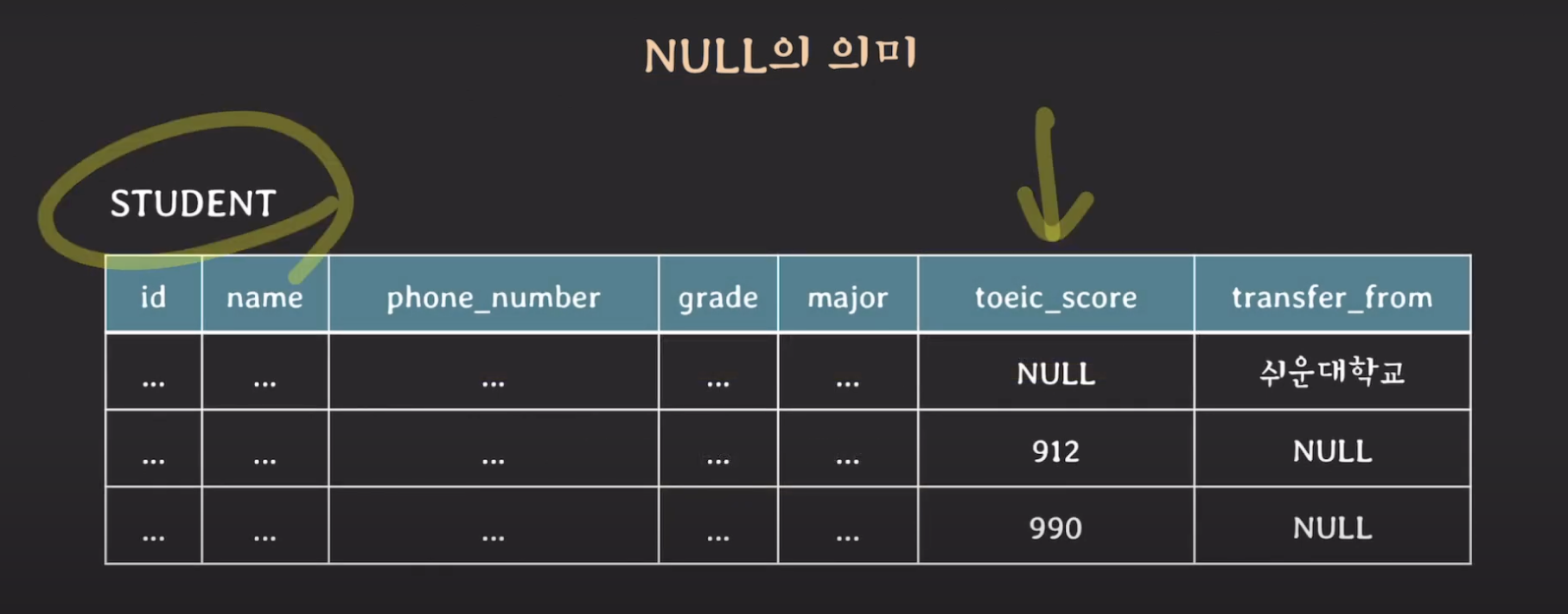
예를 들어서 student Relation에서 토익 점수를 저장한다고 해봅시다. 여기서 토익 점수에 NULL이 있는데 이것이 의미하는 값은 여러가지를 의미할 수 있습니다.
- 아직 토익 시험을 치지 않아서 값이 없는 경우
- 시험을 봤지만 아직 점수를 제출하지 않은 경우
- 토익 시험이 필요 없는 경우
등의 경우가 있습니다. 이해가 되시나요?
Null은 중의적인 의미를 가집니다. Null 하나로서 여러가지 의미가 표현이 될 수 있습니다. 따라서 NULL은 가능하면 사용하지 않는 것이 좋습니다.
⭐️ Key 개념과 종류
superkey
-
relation에서 tuples를 unique하게 식별할 수 있는 attributes set
- e.g. PLAYER(id, name, team_id, ...)의 superkey는
{id, name, team_id, ...}, {id, name}, {name, team_id,...}, ... etc
- e.g. PLAYER(id, name, team_id, ...)의 superkey는
candidata key*
- 어느 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 superkey
- key or minimal superkey
- e.g. PLAYER(id, name, team_id, back_number...)의 candidate key는 {id}, {team, id, back_number}
primary key
- relation에서 tuples를 unique하게 식별하기 위해 선태고딘 candidate key
- e.g. PLAYER(id, name, team_id, back_number, brith_data)의 primary key는 {id}, {team_id, back_number}
unique key
- primary key가 아닌 candidate keys
- alternate key
- e.g.PLAYER(id, name, team_id, back_number...)의 unique key는 {team_id, back_number}
foreign key
- 다른 relation의 PK를 참조하는 attributes set
- e.g.PLAYER(id, name, team_id, back_number, birth_data)와 TEAM(id, name, manger)가 있을 때 foreign key는 PLAYER의 {team_id}
⭐️ Constrains의 개념과 종류
- relational database의 relations들이 언제나 항상 지켜줘야 하는 제약 사항
implicit constrains
- relational data model 자체가 가지는 constraints
- relation은 중복되는 tuple을 가질 수 없다.
- relation 내에서는 같은 이름의 attribute를 가질 수 없다.
schema-based constraints
- 주로 DDL을 통해 schema에 직접 명시할 수 있는 constraints
- DDL에 관해서는 지난 글을 확인해주세요!
- explicit constraints
domain constraints
- attribute의 value는 해당 attribute의 domain에 속한 value여야 한다.
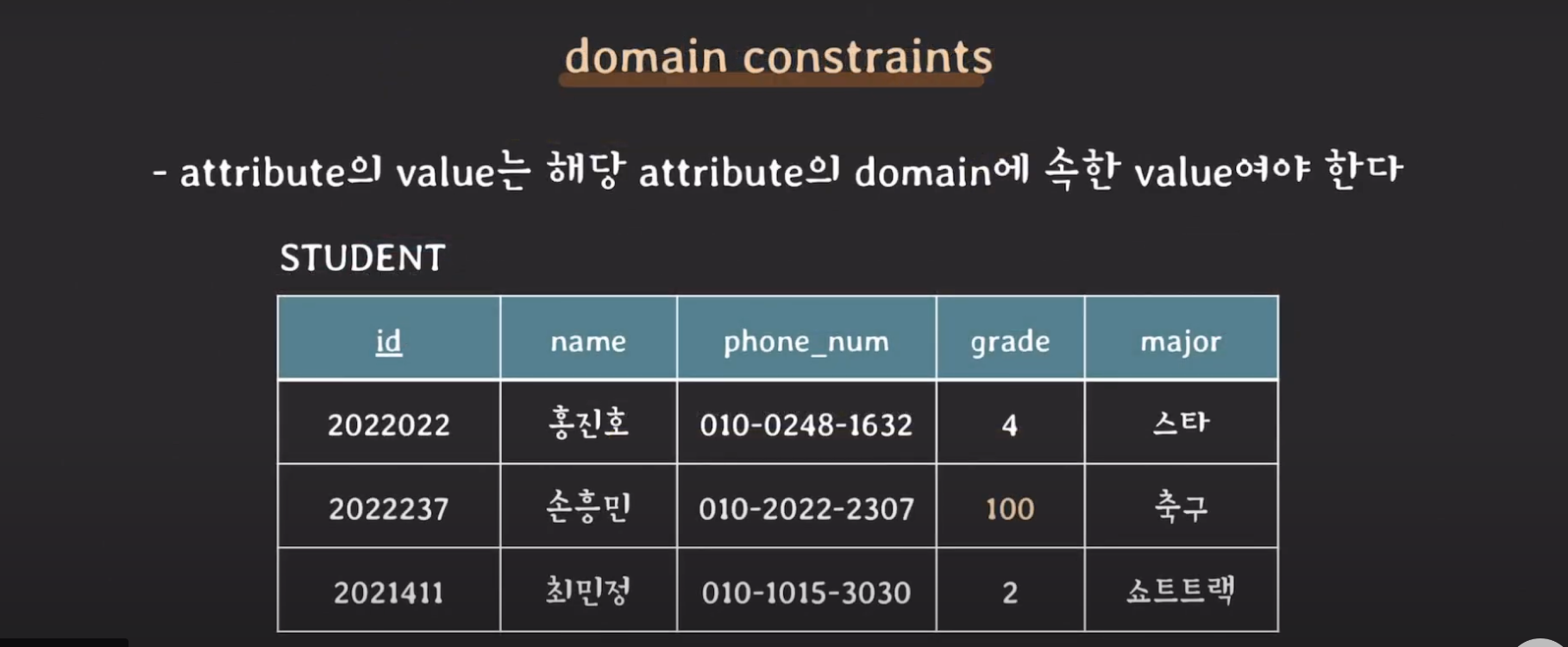
grade는 학년인데 100학년은 말이 안되죠?
key constraints
- 서로 다른 tuples는 같은 value의 key를 가질 수 없다.
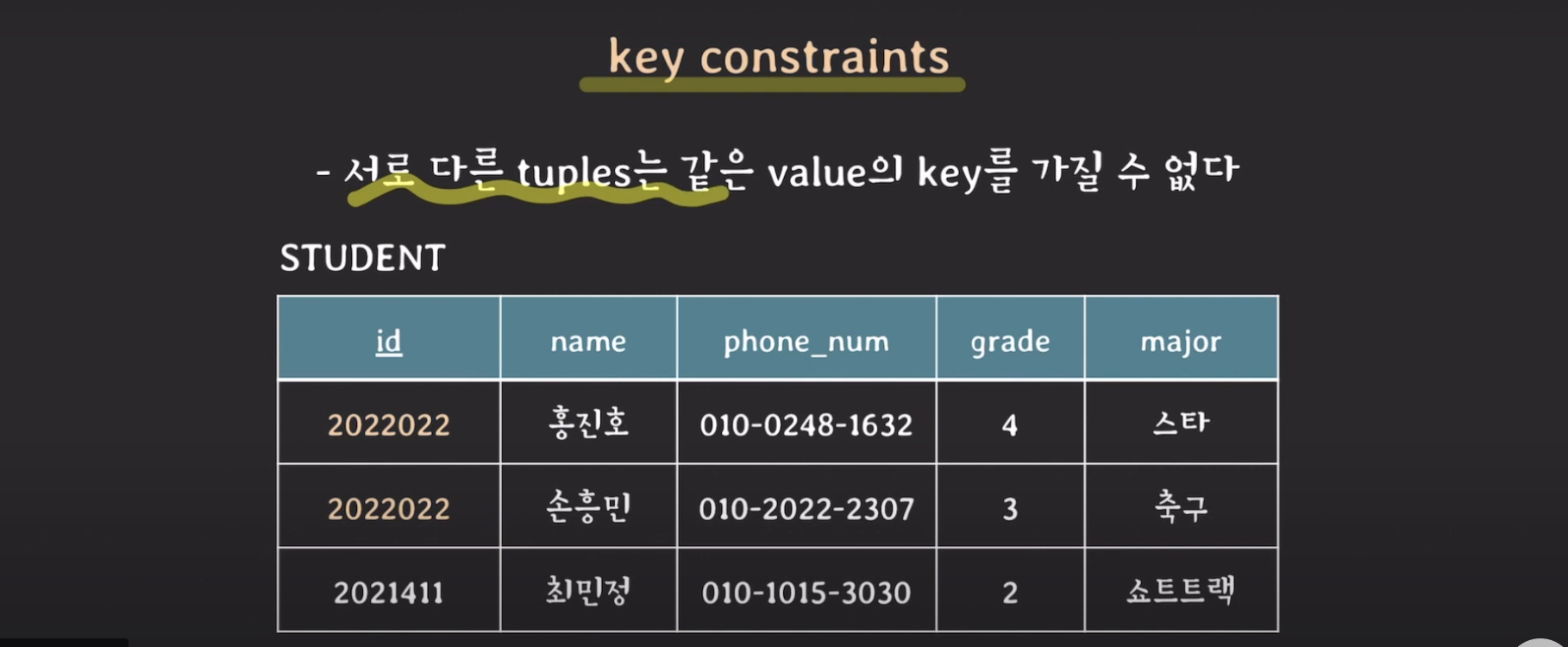
사진을 보면 홍진호에 대한 튜플과 손흥민에 대한 튜플의 id가 같습니다. 이런 경우를 key constraints가 제약을 하는 것입니다.
NULL value constrain
- attribute가 NOT NULL로 명시됐다면 NULL을 값으로 가질 수 없다.
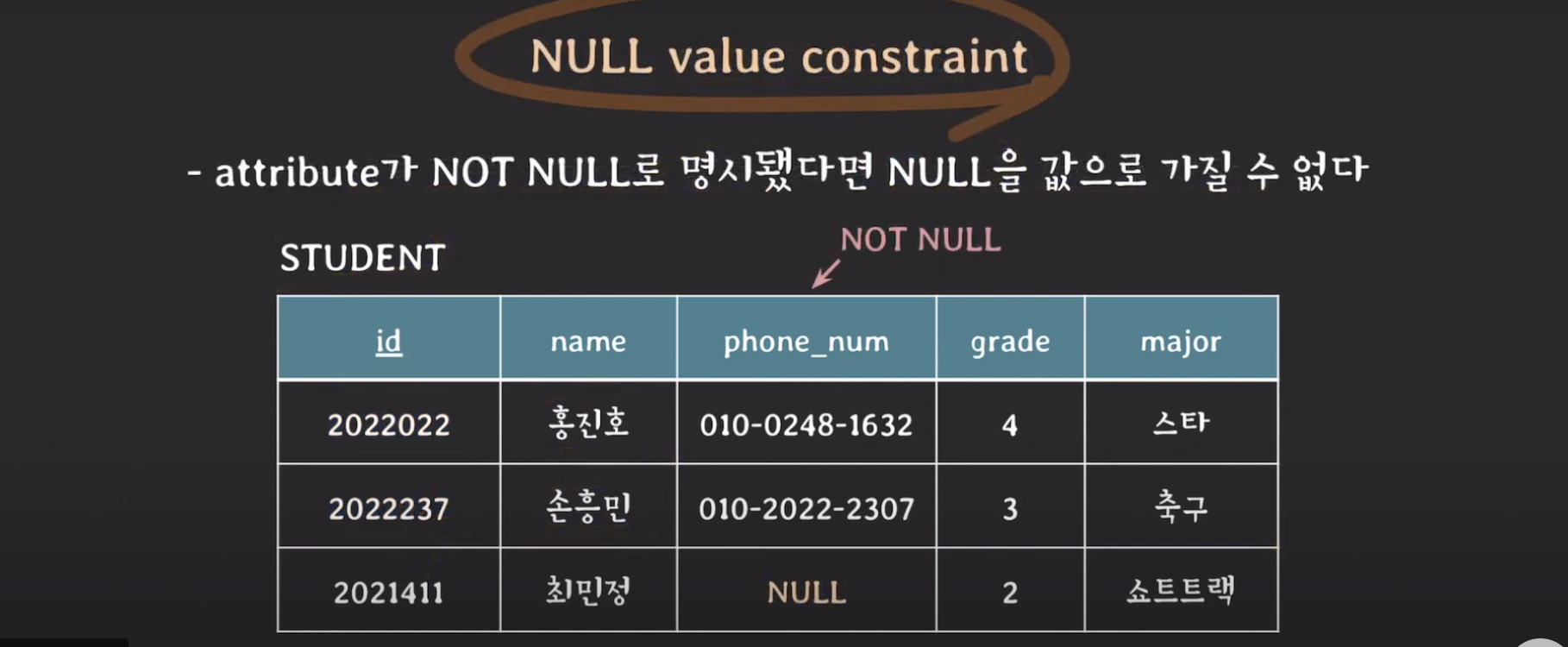
사진을 보면 phone_num attribute가 NOT NULL로 명시가 됐는데 null값을 가지는 튜플이 존재합니다. 이런 경우 NULL value constrain를 위반합니다.
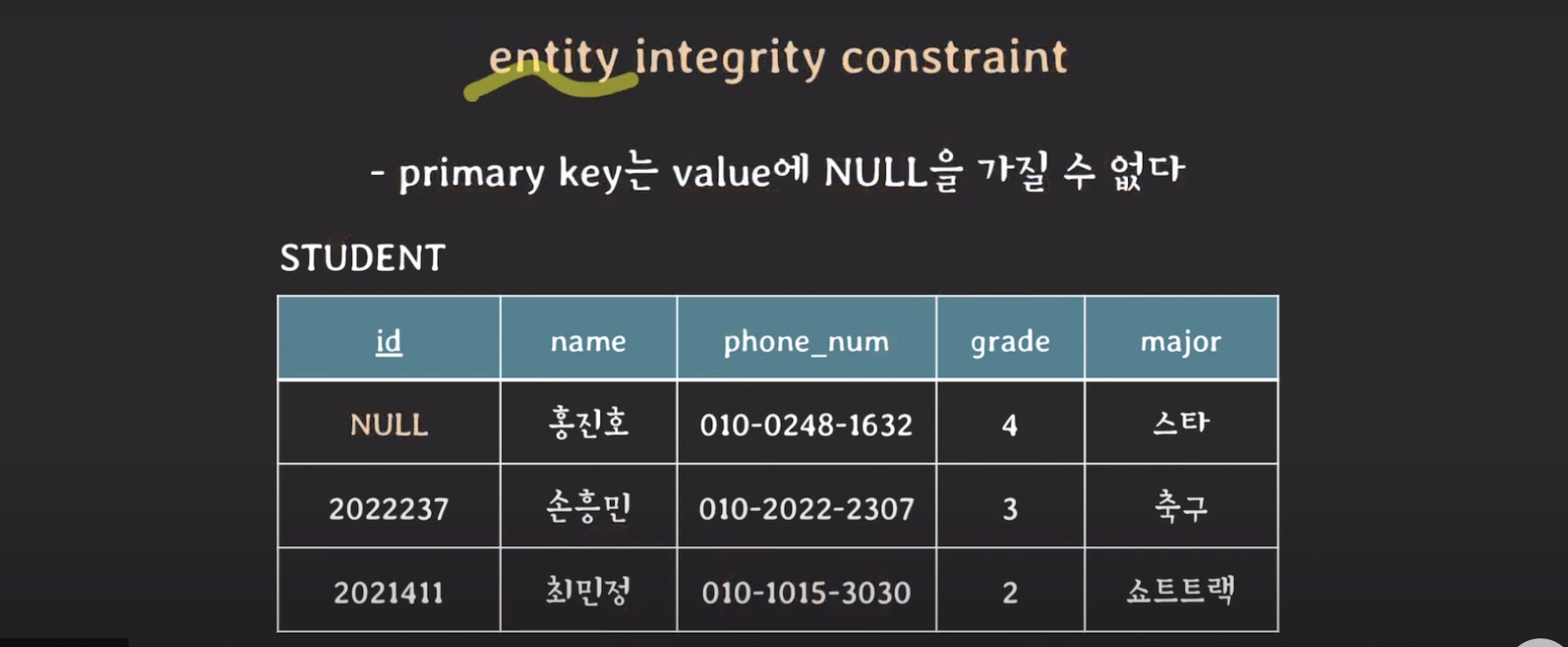
entity integrity constraint
- primary key는 value에 NULL을 가질 수 없다.
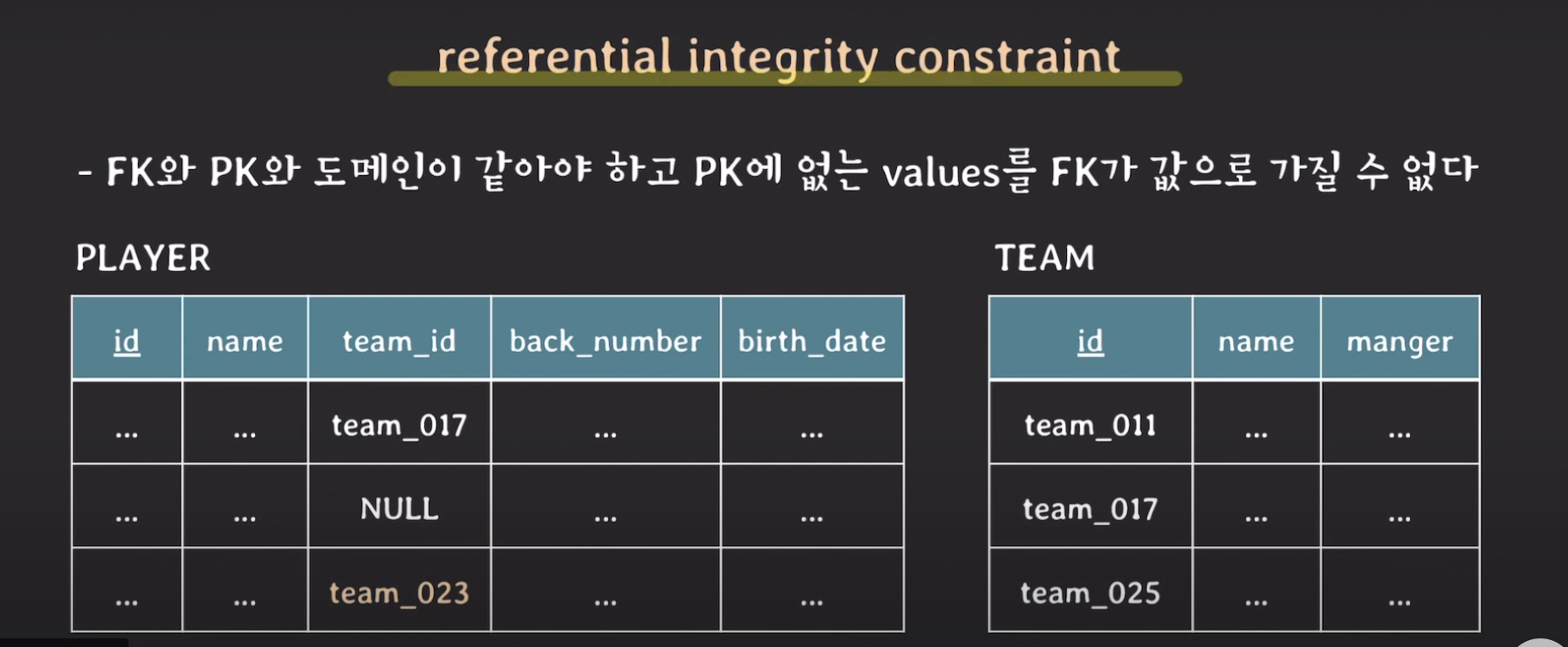
**referential integrity constraint
- FK와 PK와 도메인이 같아야 하고 PK에 없는 values를 FK가 값으로 가질 수 없다.
Constraint를 두는 이유
데이터베이스가 일치된 형태로, 데이터의 일관성을 보장하기 위해서 사용되는 개념입니다.
실제로 서비스 단에서 구현을 하다 보면 이 컨텐츠를 위반하는 경우가 발생하면 주로 에러가 발생하게 됩니다.
출처
글에 사용된 내용 및 사진은 모두 아래 영상의 자료입니다.
유튜브-쉬운코드
시니어 백엔드 개발자가 알려주는 데이터베이스 개론 & SQL
