

⭐️ Redis
특징
- 고성능 Key-Value 구조의 저장소
- 비정형 데이터를 저장, 관리하기 위한 오픈 소스 기반의 NoSQL
- In-Memory 데이터 구조를 가진 저장소
- 휘발성 - DB, Cache, Message Queue, Shared Memory 용도로 사용됨
- 웹 서버의 부담을 획기적으로 줄이고, 고속으로 데이터 제공이 가능
인메모리(In-Memory)
- 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용하는 방법
- RAM에 데이터를 저장하게 되면 메모리 내부에서 처리가 되므로 데이터를 저장/조회할 때 하드디스크를 오고가는 과정을 거치치 않게 되어 속도가 빠르다
- 그러나 서버의 메모리 용량을 초과하는 데이터를 처리할 경우, RAM의 특성인 휘발성에 따라 데이터가 유실될 수 있다.
기존 DB가 있는데도 Redis를 추가로 사용하는 이유가 무엇일까?
DB는 데이터를 디스크에 직접 저장하기 때문에 서버에 문제가 발생하더라도 데이터가 손실되지 않는다는 장점이 있다.
그러나 데이터가 필요할때마다 디스크에 접근해야 하기 때문에 사용자가 많아지고 데이터 접근이 많아질수록 부하가 심해지고 속도가 느려질 수 있다. 이런 경우 캐시 서버를 도입해야하는데 캐시 서버로 이용할 수 있는 것이 Redis이다.
위에서 말했듯이 Redis는 In-Memory 데이터 구조를 가졌기 때문에 매번 디스크를 거치치 않고도 캐시 서버에 저장둔 값을 바로 가져올 수 있다. 이런 특징 덕분에 DB의 부하를 줄이고 서비스의 속도 향상도 노릴 수 있다.
📌 Redis의 특징
-
Key, Value 구조
-
빠른 처리 속도
-
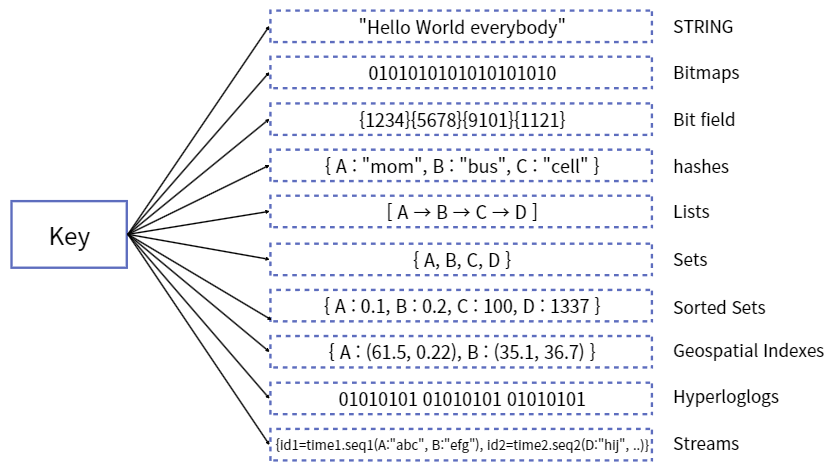
Data Type(Collection)을 지원
-
개발의 편의성, 생산성이 좋아지고 난이도가 낮아짐
-
AOF, RDB 방식
- 인메모리 데이터 저장소가 가지는 휘발성의 특징으로 데이터가 유실될 경우를 방지하여 백업 기능을 제공- AOF (Append On File) 방식
- Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태 - RDB (Snapshotting) 방식
- 순간적으로 메모리에 있는 내용 전체를 디스크에 담아 영구 저장하는 방식
https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
https://server-talk.tistory.com/489
https://velog.io/@pjh612/Redis의-백업RDB-AOF-알아보기
- AOF (Append On File) 방식
-
Redis Sentinel 및 Redis Cluster를 통한 자동 파티셔닝을 제공
- Master와 Slabes로 구성하여 여러대의 복제본을 만들 수 있고, 여러대의 서버로 읽기를 확장 가능파티셔닝(Partitioning)
- 다수의 Redis 인스턴스가 존재할 때 데이터를 여러 곳으로 분산 시키는 기술
- 각 Redis 인스턴스는 전체 키 중 자신에게 할당된 일부 파티션의 키들만 관리하게 된다.
https://kr-blog.gihwan.com/61
https://velog.io/@always/Redis-운영-방식-Cluster-vs-Sentinel-어떤-것을-선택해야-할까
-
다양한 프로그래밍 언어 지원
-
싱글 스레드
- 한번에 하나의 명령만 수행이 가능하므로 Race Condition이 거의 발생하지 않음
Race Condition
- 공유 자원에 대해 여러 프로세스가 동시에 접근을 시도할 때, 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태
- 즉, 두 개의 스레드가 하나의 자원을 놓고 서로 사용하려고 경쟁하는 상황에서 발생
- 프로그램의 일관성과 정확성을 손상시킬 수 있음
📌 Redis 사용 시 주의할 점
- 시간 복잡도
- Single Threaded(싱글 스레드) 사용으로 한 번에 하나의 명령만 수행이 가능흐므로 처리 시간이 긴 요청의 경우 장애가 발생 - 메모리 단편화
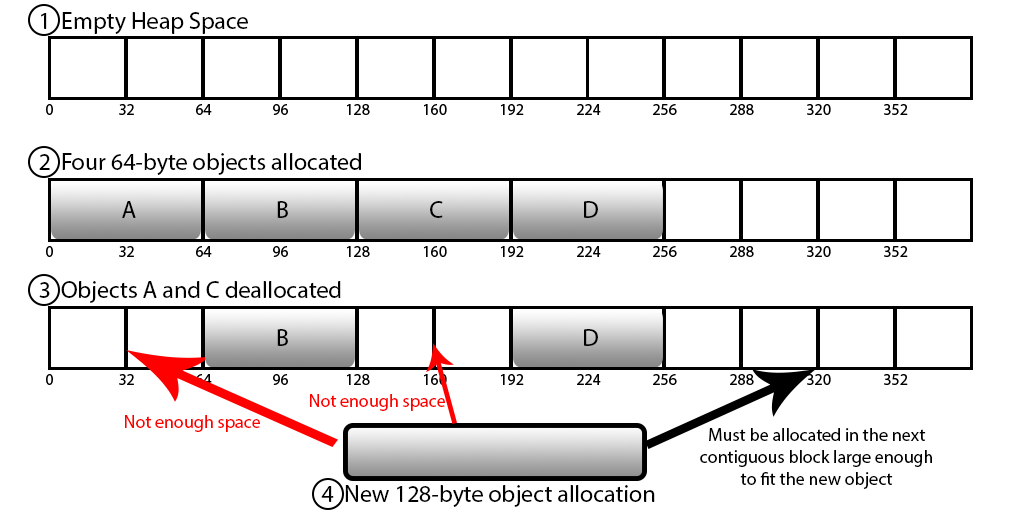
- 크고 작은 데이터를 할당하고 해제하는 과정에서 메모리의 파편화가 발생하여 응답 속도가 느려질 수 있다.
메모리 단편화 (Memory Fragmentation)
RAM에서 메모리를 할당받고 해제하는 과정에서 위와 같은 부분 부분마다 빈 공간이 생기는데, 새로운 메모리 할당 시에 사용 가능한 메모리가 충분하지만 메모리의 크기만큼의 부분이 없어 마지막 부분에 할당되어 메모리 낭비가 심하게 된다.이 현상이 계속되면 실제 physical 메모리가 커져 프로세스가 죽는 현상이 발생할 수도 있으므로, redis를 사용시에 메모리를 적당히 여유있게 사용하는 것이 좋다.
참고: ✏️ [OS] 외부 단편화와 내부 단편화란?
⭐️ Spring Boot에서 Redis 사용하기
Spring Boot에서 spring-data-redis 라이브러리를 활용해서 Redis를 사용하는 방법이 존재한다.
📌 Java의 Redis Client
Java의 Redis Client는 크게 두 가지가 있다.
- Jedis
- Lettuce
원래는 Jedis를 많이 사용했지만, 멀티 쓰레드 불안정, Pool 한계 등등 여러가지 단점과 Netty 기반으로 비동기 지원이 가능한 Lettuce의 장점 덕분에 Lettuce로 추제가 넘어가고 있었다.
현재 Spring Boot 2.0 이후부터는 Jedis가 기본 클라이언트에서 deprecated 되고 Lettuce가 탑재되었다.
Spring Session에서 Jedis 대신 Lettuce를 사용하는 이유
📌 Spring Boot에서 Redis 설정
Spring Boot에서 Redis를 사용하는 방법은 두 가지가 있다.
- RedisRepository
- RedisTemplate
build.gradle
'''
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
'''
application.yml
spring:
redis:
host: localhost
port: 6379yml 파일에 host, port를 설정한다. localhost:6379는 기본값이기 때문에 따로 변경하지 않았다면 위 설정을 사용하면 된다.
하지만 일반적으로 운영 서버에서는 별도의 Host를 사용하기 때문에 값을 이렇게 별도의 값을 세팅하고 Configuration에서 Bean에 등록해준다.
@Configuration
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
}Redis를 사용한 기본 Configuration이다.
application.yml에 설정한 값을 @Value 어노테이션으로 주입하다.
[RedisRepository]
Spring Data Redis의 RedisRepository를 이용하면 간단하게 Domain Entity를 Redis Hash로 만들 수 있다.
다만 트랜잭션을 지원하지 않기 때문에 트랜잭션을 적용하고 싶다면 RedisRemplate을 사용해야 한다.
Entity
@Getter
@RedisHash(value = "people", timeToLive = 30)
public class Person {
@Id
private String id;
private String name;
private Integer age;
private LocalDateTime createdAt;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
this.createdAt = LocalDateTime.now();
}
}- Redis에 저장할 자료구조인 객체를 정의한다.
- 일반적인 객체 선언 후 @RedisHash를 붙이면 된다.
- value: Redis의 keyspace 값으로 사용된다.- timeToLive: 만료 시간을 초단위로 설정할 수 있다. 기본값을 만료시간이 없다.
- @Id 어노테이션은 붙은 필드가 Redis Key 값이 되며 null로 세팅하면 랜덤값이 설정된다.
- keyspace와 합쳐져서 레디스에 저장된 최종 키 값은 keyspace:id가 된다.
Repository
public interface PersonRedisRepository extends CrudRepository<Person, String> {
}Test
@SpringBootTest
public class RedisRepositoryTest {
@Autowired
private PersonRedisRepository repo;
@Test
void test() {
Person person = new Person("Park", 20);
// 저장
repo.save(person);
// `keyspace:id` 값을 가져옴
repo.findById(person.getId());
// Person Entity 의 @RedisHash 에 정의되어 있는 keyspace (people) 에 속한 키의 갯수를 구함
repo.count();
// 삭제
repo.delete(person);
}
}- JPA와 동일하게 사용할 수 있다.
- 여기서는 id 값을 따로 설정하지 않아서 랜덤한 키 값이 들어간다.
- 저장할 때 save()를 사용하고 값을 조회할 때 findById()를 사용한다.
[RedisTemplate]
RedisTemplate을 사용하면 특정 Entity 뿐만 아니라 여러가지 원하는 타입을 넣을 수 있다.
template을 선언한 후 원하는 타입에 맞는 Operations을 꺼내서 사용한다.
config 설정 추가
@Configuration
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<?, ?> redisTemplate() {
RedisTemplate<?, ?> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
}RedisTemplate에 LettuceConnectionFactory을 적용해주기 위해 설정해준다.
Test
@SpringBootTest
public class RedisTemplateTest {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Test
void testStrings() {
// given
ValueOperations<String, String> valueOperations = redisTemplate.opsForValue();
String key = "stringKey";
// when
valueOperations.set(key, "hello");
// then
String value = valueOperations.get(key);
assertThat(value).isEqualTo("hello");
}
@Test
void testSet() {
// given
SetOperations<String, String> setOperations = redisTemplate.opsForSet();
String key = "setKey";
// when
setOperations.add(key, "h", "e", "l", "l", "o");
// then
Set<String> members = setOperations.members(key);
Long size = setOperations.size(key);
assertThat(members).containsOnly("h", "e", "l", "o");
assertThat(size).isEqualTo(4);
}
@Test
void testHash() {
// given
HashOperations<String, Object, Object> hashOperations = redisTemplate.opsForHash();
String key = "hashKey";
// when
hashOperations.put(key, "hello", "world");
// then
Object value = hashOperations.get(key, "hello");
assertThat(value).isEqualTo("world");
Map<Object, Object> entries = hashOperations.entries(key);
assertThat(entries.keySet()).containsExactly("hello");
assertThat(entries.values()).containsExactly("world");
Long size = hashOperations.size(key);
assertThat(size).isEqualTo(entries.size());
}
}- 위에서부터 차례대로 Strings, Set, Hash 자료구조에 대한 Operations이다.
- RedisTemplate을 주입받은 후에 원하는 Key, Value 타입에 맞게 Operations을 선언해서 사용할 수 있다.
- 가장 흔하게 사용되는 RedisTemplate<String, String>을 지원하는 StringRedisTemplate 타입도 따로 있다.
출처
Lettuce Reference Guide
Spring Data Redis Reference
Spring Data Redis Reference - Redis Repositories
Redis - In-Memory 알아보기
우아한 테크 세미나 유튜브
