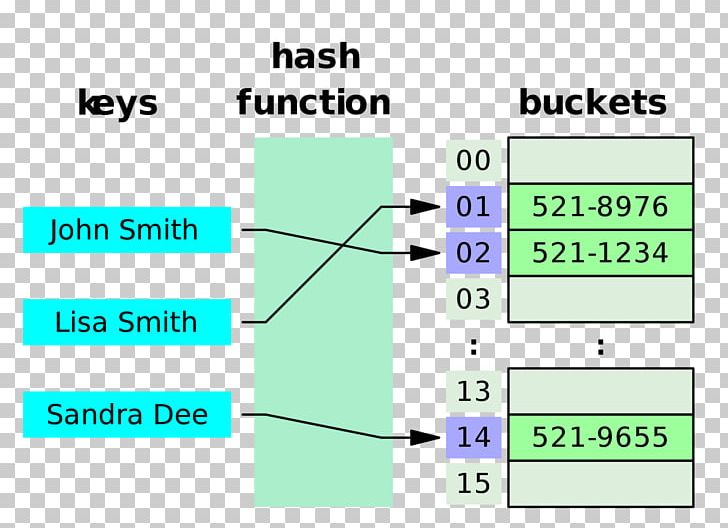
Hash Table
F(key) -> HashCode -> Index -> Value
검색하고자하는 키값을 입력받아서 해쉬함수를 돌려서 반환받은 해쉬코드를 배열의 인덱스로 환산해서 데이터에 접근하는 방식의 자료구조.
Hash Table의 특징
검색 속도가 빠르다.
해쉬 함수를 통해 만든 해쉬코드는 정수.
배열 공간을 고정된 크기만큼 만들어 놓고 해쉬코드를 배열의 개수로 나머지 연산을 해서 배열에 나눠 담는다. -> 해쉬코드 자체가 배열 방의 인덱스로 사용되기 떄문에 검색 자체를 할 필요가 없다. 해쉬코드로 바로 데이터의 위치에 다이렉트로 접근이 가능하다.
Hash 함수의 특징
- 항상 내가 가지고 있는 어레이의 크기 안에서 값이 나와야 한다. (0 ~ length-1 안의 값만 반환시켜야 함.)
- 언제든지 넣었을 떄 같은 값이 나와야 한다. 일정한 값이 나와야 한다.
- 해쉬 함수는 저장하는 것이 아니다. 기억을 가지고 있지 않다. 그냥 그때 그때 값을 주면 값을 내뱉을 수 있어야 한다.
충돌을 해결 하는 법
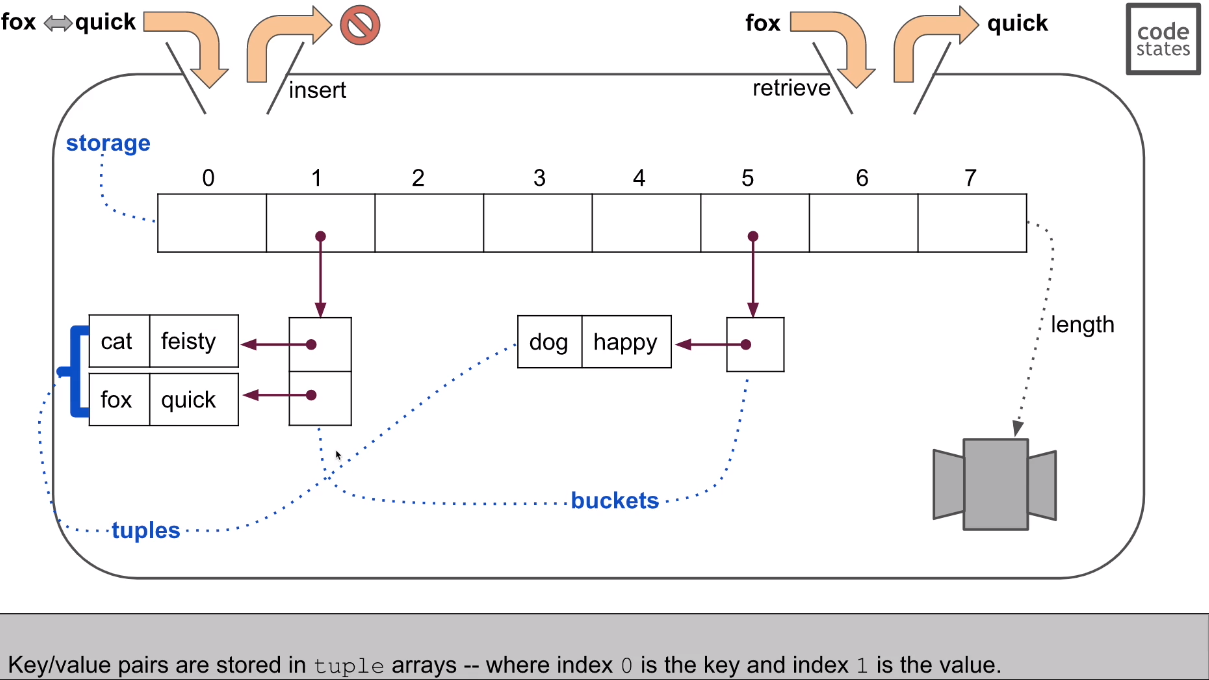
- 또다른 어레이를 만듬. (buckets에 쌓임. 한개의 인덱스에 계속 쌓임)
- 그 어레이에서 다시 다른 레퍼런스를 바라보게 한다. 각각의 튜플을 만든다.(tuples) 항상 0번째는 키 1번쨰는 value로 약속을 만든다.
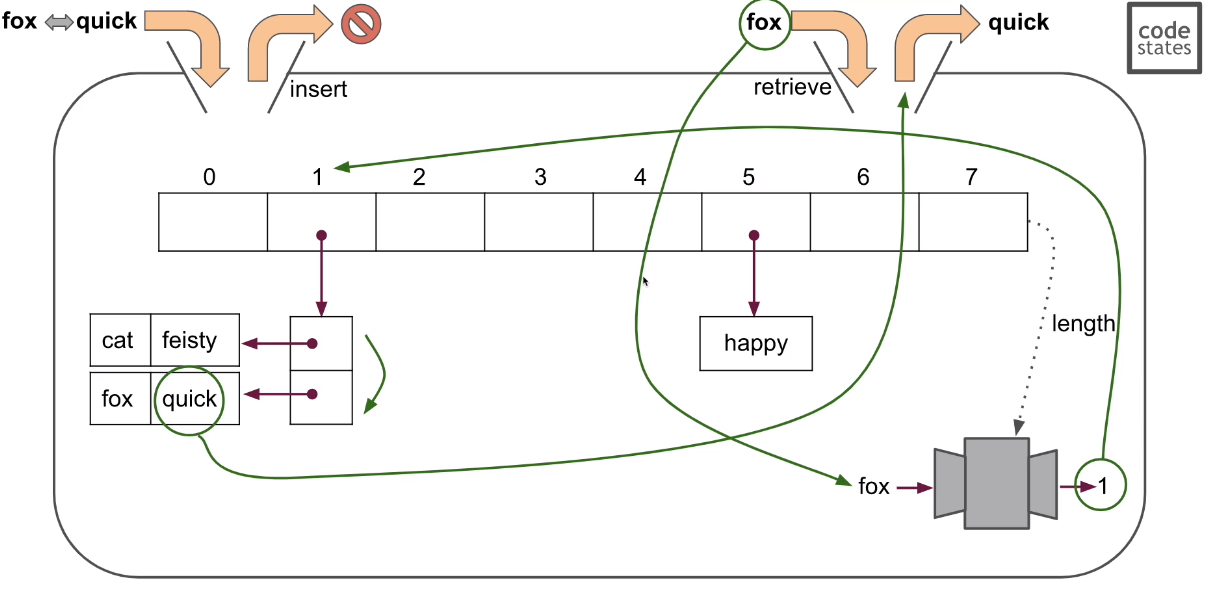
- fox를 해쉬함수에 넣어서 1이 나왔고 1에서 보니 여러개가 있고 0번째를 확인해보니 fox가 있다. 그것의 1번째 값을 뱉어준다.
Hash Table Resizing
- 해쉬테이블은 storage의 사이즈가 25% ~에서 75% 일때 효과적으로 운영된다.
- 75% 가 되려고 하면 storage의 사이즈를 2배로 늘려준다.
- 25% 가 되려고 하면 storage의 반으로 줄여준다.
- constant time을 유지해준다.

개발블로그