⭐⭐BST는 어떤 자료구조 인가요?
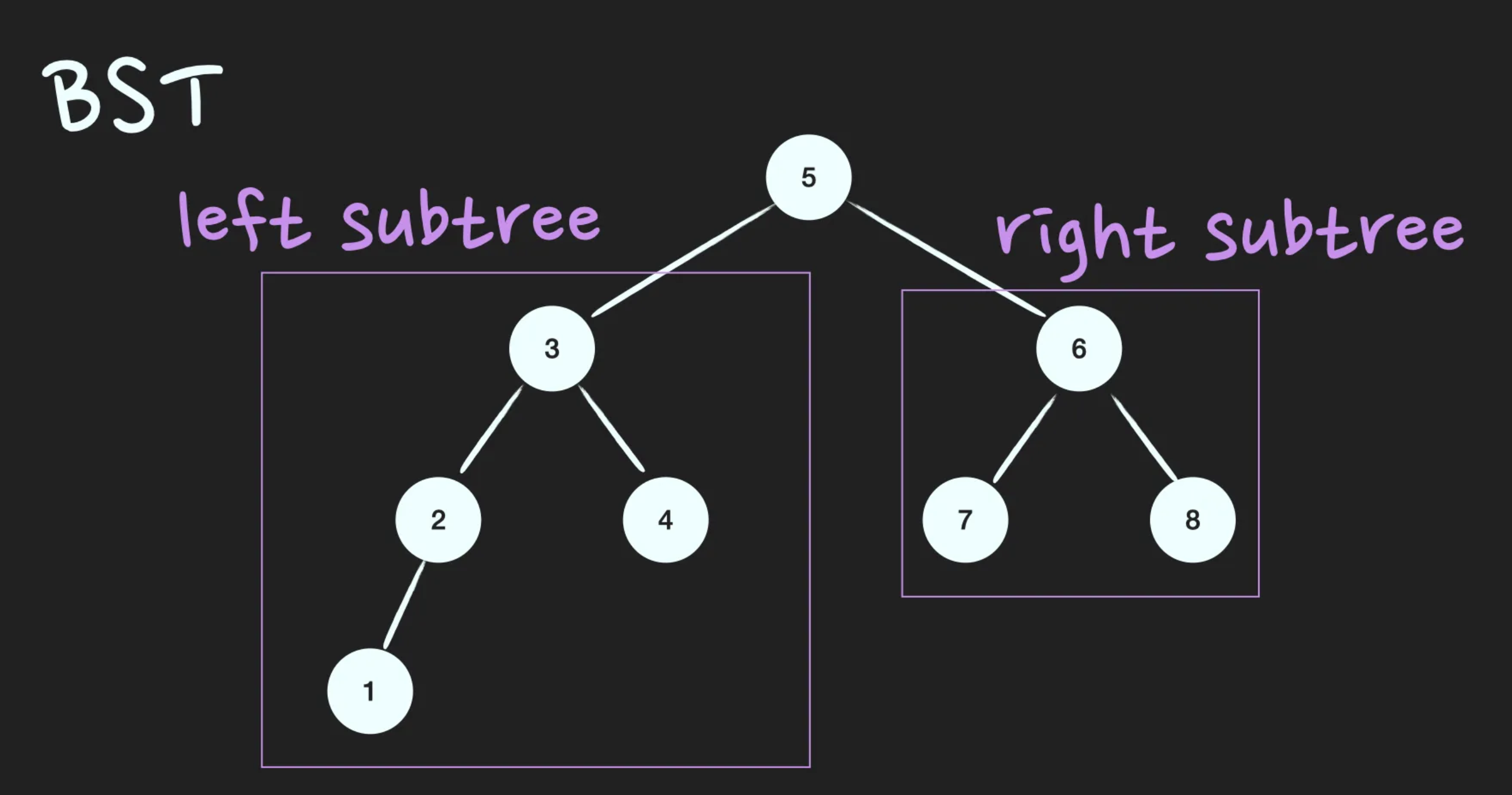
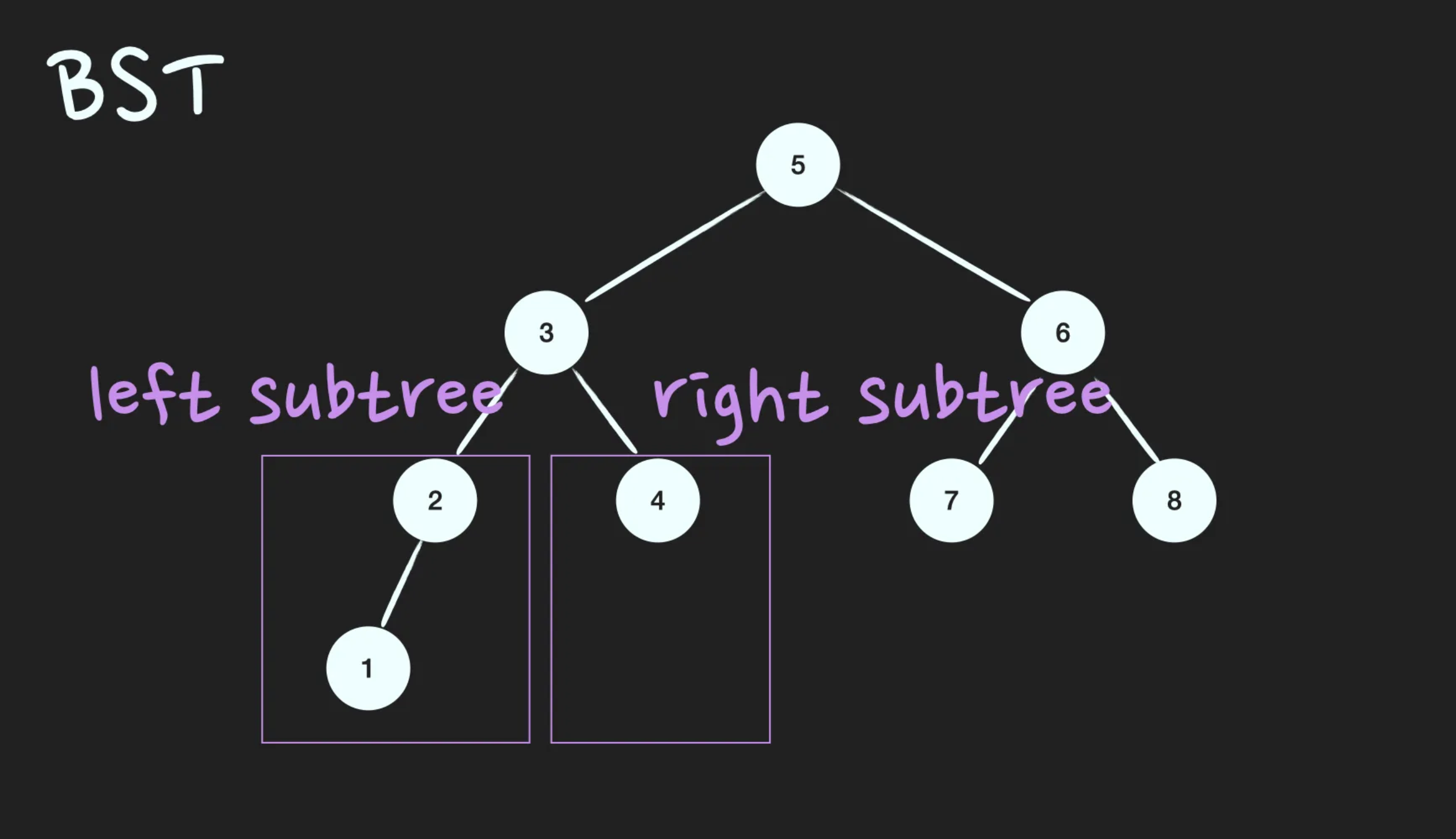
이진탐색트리(Binary Search Tree; BST)는 정렬된 tree입니다. 어느 node를 선택하든 해당 node의 left subtree에는 그 node의 값보다 작은 값들을 지닌 node들로만 이루어져 있고, node의 right subtree에는 그 node의 값보다 큰 값들을 지닌 node들로만 이루어져 있는 binary tree입니다.
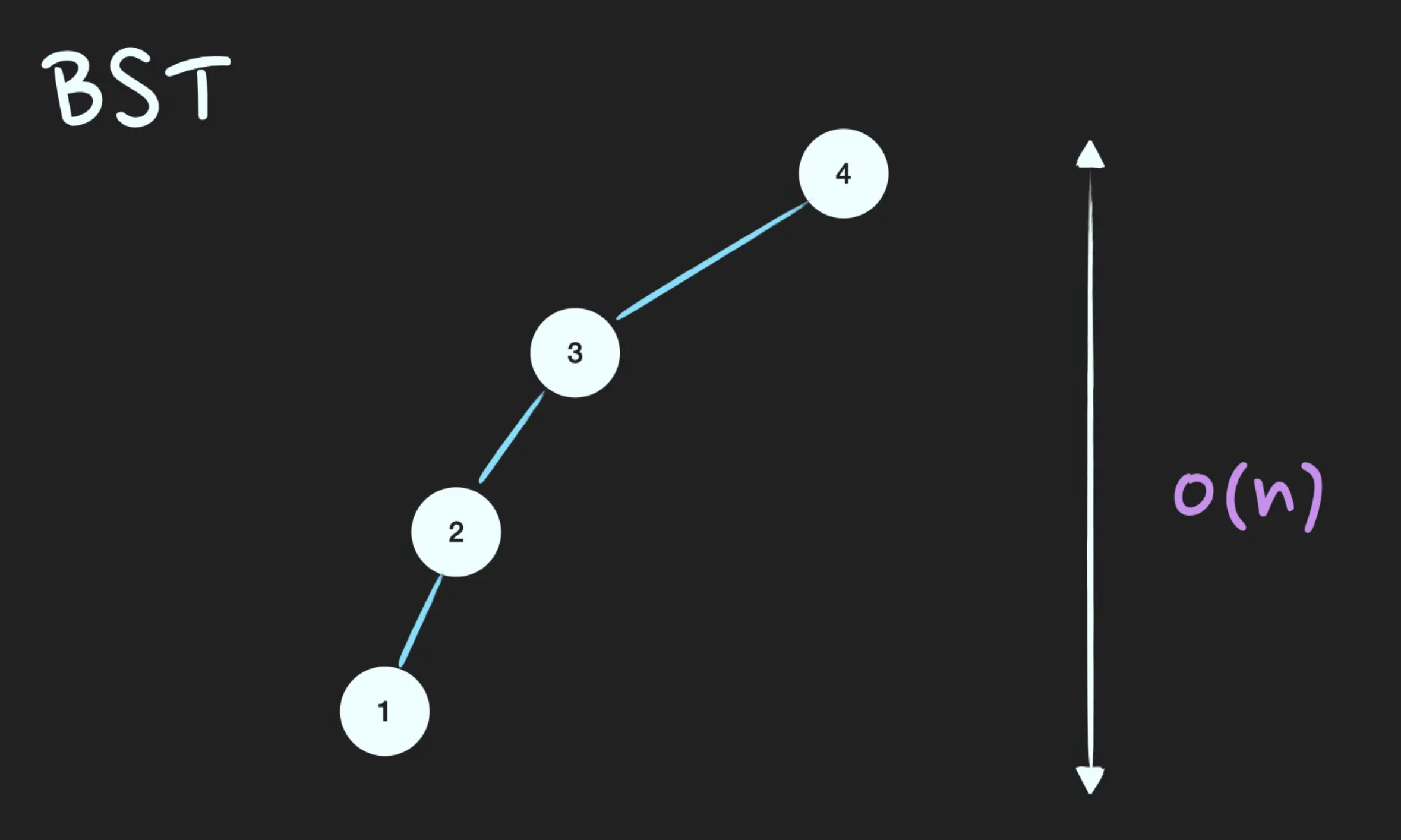
검색과 저장, 삭제의 시간복잡도는 모두 이고, worst case는 한쪽으로 치우친 tree가 됐을 때 입니다.
BST
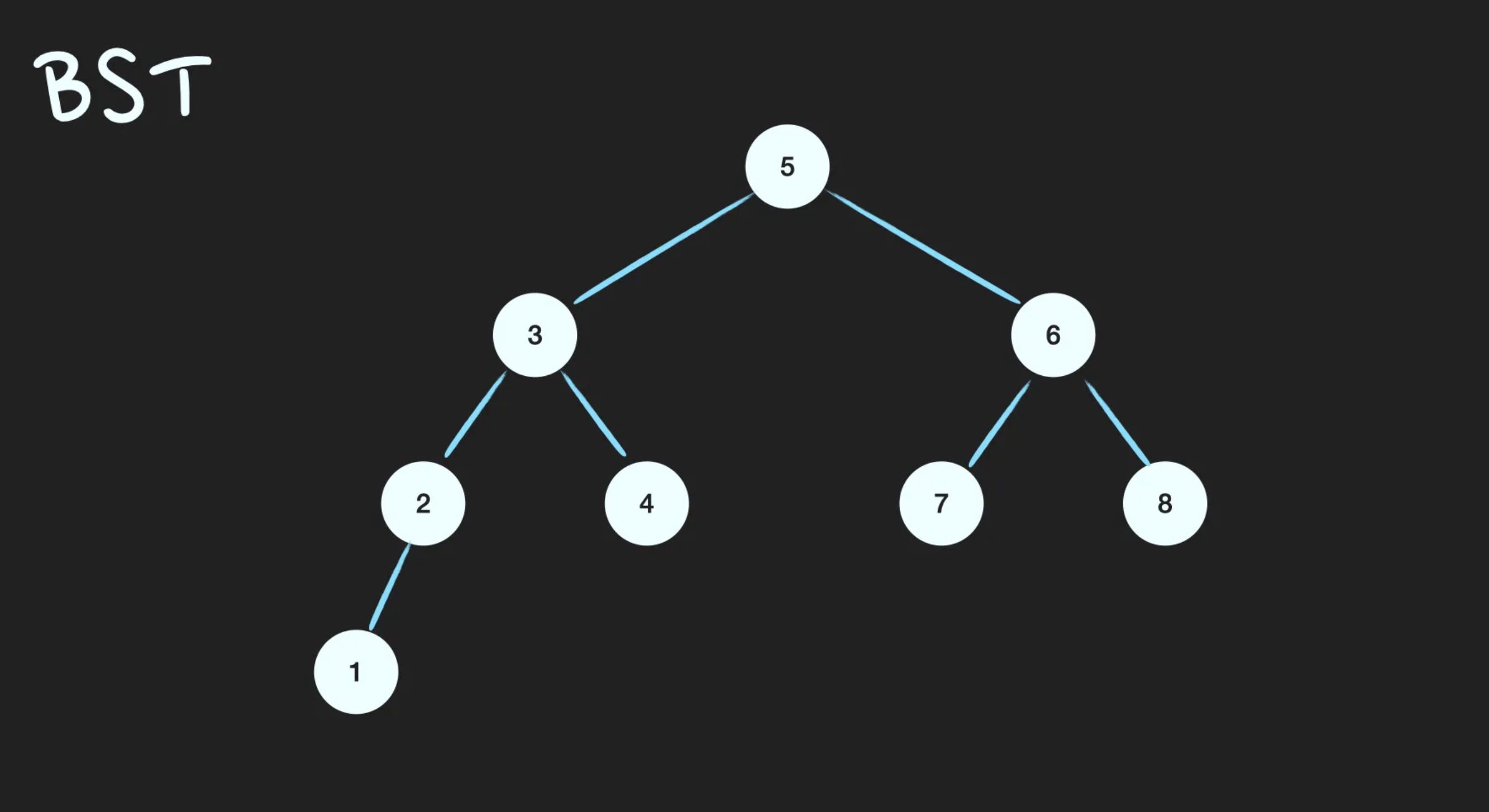
BST 조건
- root node의 값보다 작은 값은 left subtree에, 큰 값은 right subtree에 있다.
- subtree도 1번 조건을 만족한다.(Recursive)
이진트리(Binary tree)는 어떤 자료구조 인가요?
모든 node의 child nodes의 갯수가 2 이하인 트리를 이진 트리라고 합니다.
BST의 worst case 시간복잡도는 입니다. 어떠한 경우에 worst case가 발생하나요?
균형이 많이 깨져서 한 쪽으로 치우친 BST의 경우에 worst case가 됩니다. 이렇게 되면 Linked list와 다를게 없어집니다. 따라서 탐색시에 이 아니라 이 됩니다.
그럼 해결방법은 무엇인가요?
자가 균형 이진 탐색 트리(Self-Balancing BST)는 알고리즘으로 이진 트리의 균형이 잘 맞도록 유지하여 높이를 가능한 낮게 유지합니다. 대표적으로 AVL트리와 Red-black tree가 있습니다. JAVA에서는 hashmap의 seperate chaning으로써 Linked list와 Red-black tree를 병행하여 저장합니다.
⭐⭐ Hash table는 어떤 자료구조 인가요?
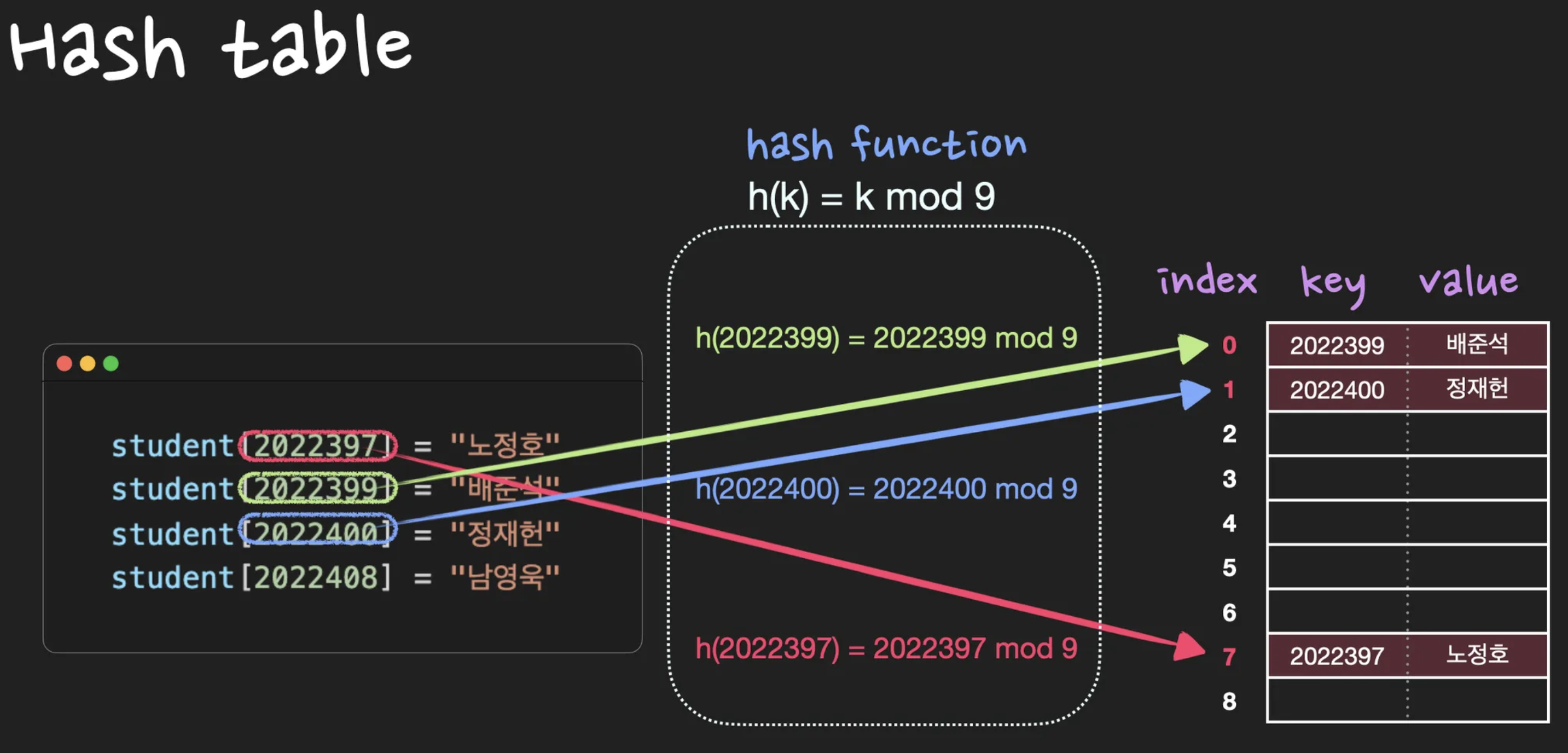
hash table은 효율적인 탐색(빠른 탐색)을 위한 자료구조로써 key-value쌍의 데이터를 입력받습니다. hash function 에 key값을 입력으로 넣어 얻은 해시값 를 위치로 지정하여 key- value 데이터 쌍을 저장합니다. 저장, 삭제, 검색의 시간복잡도는 모두 입니다.
Direct-address Table
Direct-address Table(직접 주소화 테이블)이란, key 값으로 k를 갖는 원소는 index k에 저장하는 방식입니다.
key: 출석번호, value: 이름
(3, 노정호)
(5, 배준석)
(6, 정재헌)
(7, 남영욱)
직접 주소화 방법으로 통해 key-value 쌍의 데이터를 저장하고자 하면 많은 문제가 발생합니다.
- 불필요한 공간 낭비
key: 학번, value: 이름
(2022390, 노정호)
(2022392, 배준석)
(2022393, 정재헌)
(2022401, 남영욱)
- key가 다양한 자료형을 담을 수 없게 됨
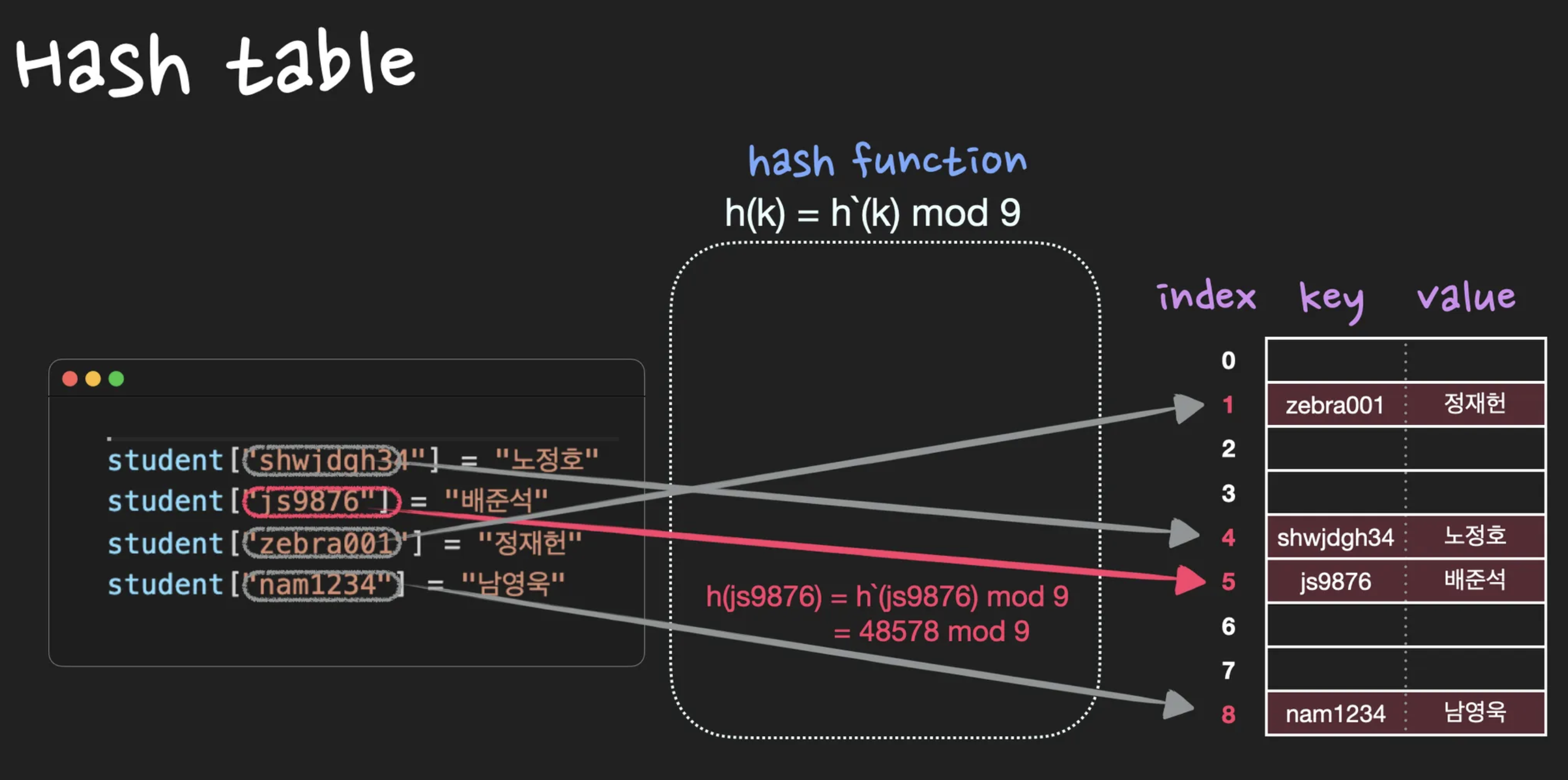
key: ID, value: 이름
(nossi8128, 노정호)
(js9876, 배준석)
(zebra001, 정재헌)
(nam1234, 남영욱)
Hash table
(key, value) 데이터 쌍을 저장하기 위한 방법으로 직접 주소화 방법이 잘 맞지않습니다. hash table은 hash function 를 이용해서 (, )를 index: 에 저장합니다. 이 때, “키 값을 갖는 원소가 위치 에 hash된다.” 또는 “는 키 의 해시값이다”라고 표현합니다. key는 무조건 존재해야 하며, 중복되는 key가 있어서는 안됩니다.
한편, hash table을 구성하고 있는, (key, value)데이터를 저장할 수 있는 각각의 공간을 slot 또는 bucket이라고 합니다.
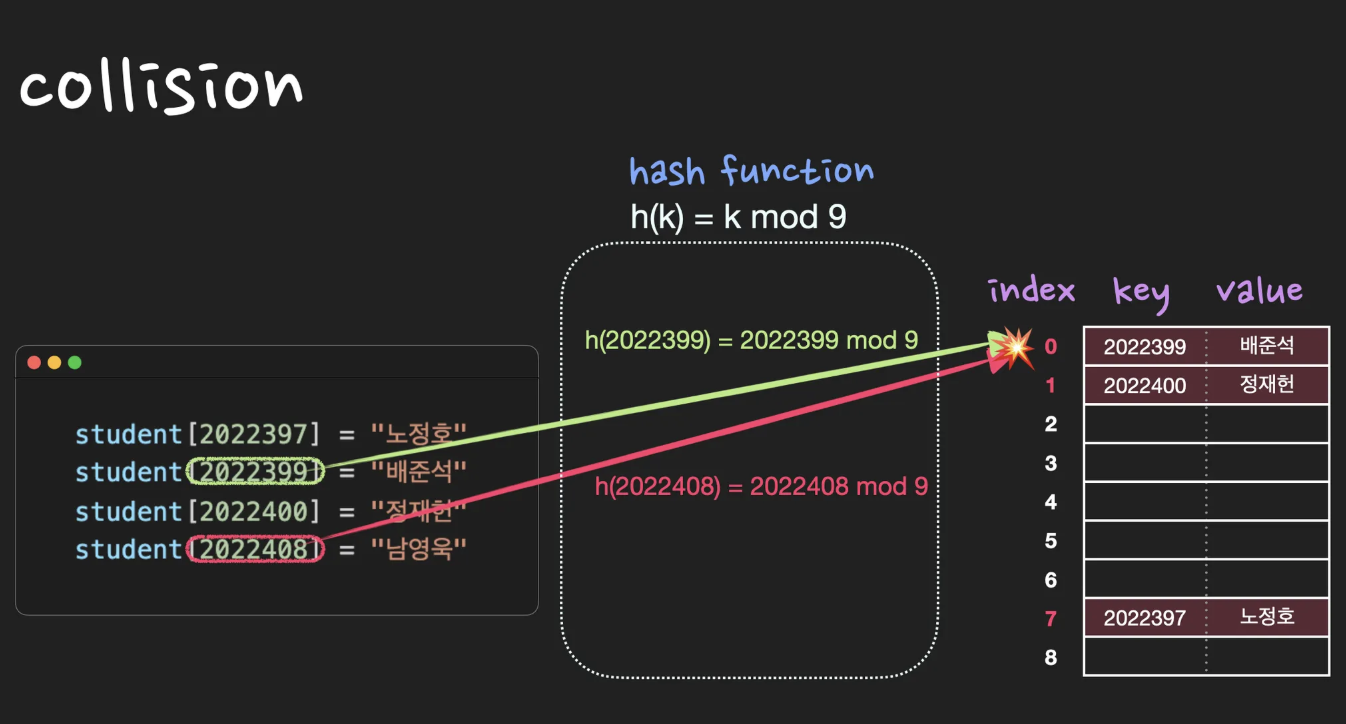
Collision
collision이란 서로 다른 key의 해시값이 똑같을 때를 말합니다. 즉, 중복되는 key는 없지만 해시값은 중복될 수 있는데 이 때 collision이 발생했다고 합니다. 따라서 collision이 최대한 적게 나도록 hash function을 잘 설계해야하고, 어쩔 수 없이 collision이 발생하는 경우 seperate chaining 또는 open addressing등의 방법을 사용하여 해결합니다.
시간복잡도와 공간효율성
시간복잡도는 저장, 삭제, 검색 모두 기본적으로 이지만, collision으로 인하여 최악의 경우 이 될 수 있습니다.
공간효율성은 떨어집니다. 데이터가 저장되기 전에 미리 저장공간(slot, bucket)을 확보해야 하기 때문입니다. 따라서 저장공간이 부족하거나 채워지지 않은 부분이 많은 경우가 생길 수 있습니다.
좋은 hash function의 조건은 뭘까요?
각 상황마다 good hash function은 달라질 수 있으나 대략적인 기준은 연산 속도가 빨라야 하고, 해시값이 최대한 겹치지 않아야 합니다.
⭐⭐⭐⭐ Hash table에서 collision이 발생하면 어떻게 되나요? 해결방법엔 뭐가 있을까요?
collision이 발생할 경우 대표적으로 2가지 방법으로 해결합니다.
첫 번째, open addressing 방식은 collision이 발생하면 미리 정한 규칙에 따라 hash table의 비어있는 slot을 찾습니다. 빈 slot을 찾는 방법에 따라 크게 Linear Probing, Quadratic Probing, Double Hashing으로 나뉩니다.
두 번째, separete chaining 방식은 linked list를 이용합니다. 만약에 collision이 발생하면 linked list에 노드(slot)를 추가하여 데이터를 저장합니다.
Open addressing
open addressing 방식은 collision이 발생하면 미리 정한 규칙에 따라 hash table의 비어있는 slot을 찾습니다. 추가적인 메모리를 사용하지 않으므로 linked list 또는 tree자료구조를 통해 추가로 메모리 할당을 하는 separate chaining방식에 비해 메모리를 적게 사용합니다.
Separate chaining
Separate chaining 방식은 linked list(또는 Tree)를 이용하여 collision을 해결합니다. 충돌이 발생하면 linked list에 노드(slot)를 추가하여 데이터를 저장합니다.
