프로젝트 요구사항
진행하고 있는 사이드 프로젝트의 요구사항이 다음과 같다.
[전체 게시물 조회]
- 사용자가 살고 있는 동/면/리 의 게시물을 최신순으로 조회한다.
- 페이지네이션
- 한 페이지 당 6개씩(무한스크롤 방식 x)
- 한 번에 여러 페이지를 건너 뛸 수 있다.
- 게시물 정보에 제목, 가격, 생성일자, 게시물 상태(거래마감 or 거래진행중), 삭제여부 포함
Cursor VS Offset
페이지네이션을 구현할 수 있는 방식은 크게 2가지 Cursor기반과 Offset기반이 있다. 요구사항에 따르면 무한스크롤 방식이 아니며, 사용자는 본인이 원하는 페이지로 이동할 수 있다. 그렇기 때문에 Cursor 방식보다는 Offset 방식으로 구현하는 것이 요구사항에 더 부합하다고 생각했다.
물론 Offset방식은 중복 조회문제가 있지만, 무한스크롤 형식도 아닌 단순 게시판형이기 때문에 중복 조회문제 문제가 크게 치명적이지 않다고 생각한다.
Offset 기반 페이지네이션 구현
위의 요구사항을 바탕으로 SQL문을 작성해보자.
1) Offset으로 게시물 목록 첫 페이지 조회
Limit와 Offset을 활용해 게시물의 첫 페이지를 조회해보자.
SELECT b.id, b.createAt, b.stuffName, b.stuffCategory, b.status, b.imageUrl, b.region_id
FROM board b
WHERE b.region_id = 1 and b.deleteAt is NULL
ORDER BY b.id DESC
LIMIT 6 OFFSET 0;게시물 첫 페이지 조회 결과
총 1,100,000개의 게시물이 있을때 첫 페이지를 조회하면, 가장 최근에 생성된 게시물 총 6개가 반환되는 결과를 확인할 수 있다.

첫 페이지 조회 시, 실행시간은 얼마 걸릴까?
실제 쿼리 실행속도와 성능을 확인하기 위해 Explain Analyze로 actual time과 cost를 분석해보자.
-> Limit/Offset: 6/800000 row(s) (cost=28798 rows=0) (actual time=5063..5063 rows=6 loops=1)
-> Filter: (b.deleteAt is null) (cost=28798 rows=54506) (actual time=1.47..5042 rows=800006 loops=1)
-> Index lookup on b using FK_c1a9c8841c26109b8f60dbcb72d (region_id=1) (reverse) (cost=28798 rows=545056) (actual time=1.47..5005 rows=816407 loops=1)다이어그램으로 보면 다음과 같다.
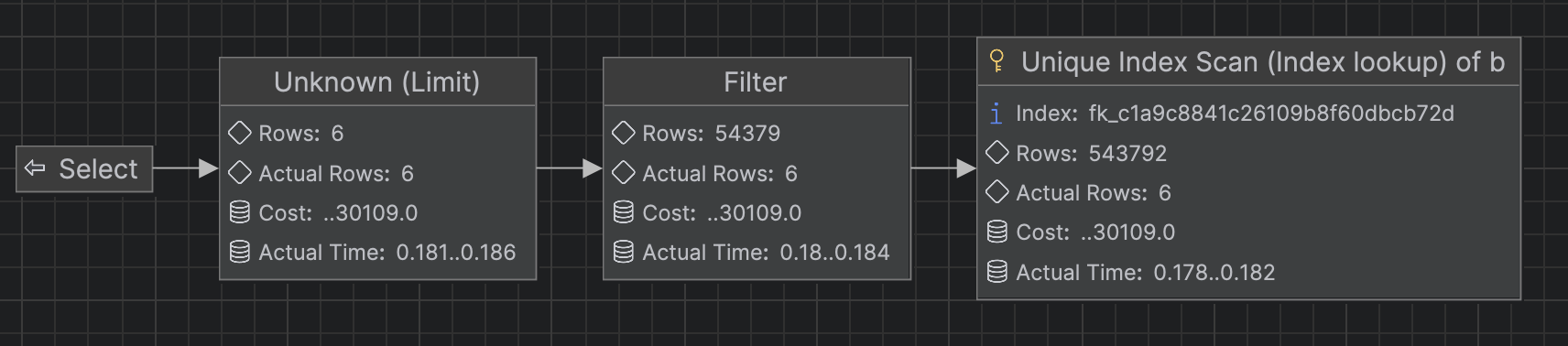
첫 페이지를 조회할 경우 실행시간은 0.186ms(0.000186s)로 조회 속도가 상당히 빠르다는 것을 확인할 수 있다.
2) Offset으로 뒤쪽 페이지 조회
실제 서비스에서는 10개, 100개의 게시물이 아니라 수백만, 수천만의 게시물들이 존재할 것이다. 그렇다면 이런 경우에는 쿼리 실행 속도는 어떨까?
그렇다면 게시물의 끝 쪽 페이지를 조회해보자.
SELECT b.id, b.createAt, b.stuffName, b.stuffCategory, b.status, b.imageUrl, b.region_id
FROM board b
WHERE b.region_id = 1 and b.deleteAt is NULL
ORDER BY b.id DESC
LIMIT 6 OFFSET 80000;끝 페이지 조회 시, 실행시간은 얼마 걸릴까?
마찬가지로 분석 결과 다음과 같다.
-> Limit/Offset: 6/800000 row(s) (cost=28798 rows=0) (actual time=5063..5063 rows=6 loops=1)
-> Filter: (b.deleteAt is null) (cost=28798 rows=54506) (actual time=1.47..5042 rows=800006 loops=1)
-> Index lookup on b using FK_c1a9c8841c26109b8f60dbcb72d (region_id=1) (reverse) (cost=28798 rows=545056) (actual time=1.47..5005 rows=816407 loops=1)다이어그램으로도 확인해보자.
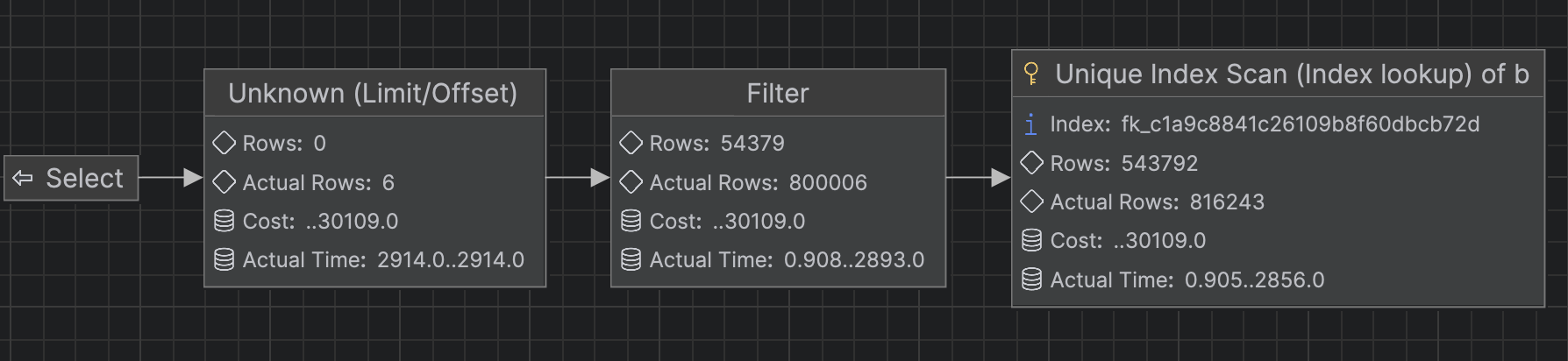
첫 페이지 조회 시 0.186ms(0.000186s) → 끝 페이지 조회 시 5063ms(5.063s)로 확실히 끝 페이지로 가면 갈 수록 쿼리 실행 속도가 느려진 것을 확인할 수 있다. 그 이유는 무엇일까?
Offset은 뒤로 갈 수록 느려진다
Limit/Offset을 확인해보면 Limit/Offset: 6/800,000 row(s) 으로 조회하고자 하는 데이터는 6개지만 Offset 방식의 특성상 800,006~816,407개의 데이터를 추가적으로 조회해 조회 속도가 느려졌다.
즉, 대용량 데이터일 경우에는 쿼리에 상당한 영향을 미치며 즉 쿼리 실행 속도가 증가한다는 치명적인 단점이 있다.
3) 커버링 인덱스를 활용한 Offset
정리를 해보자면 Offset 방식으로 페이지네이션을 구현하고자 할 때, 데이터가 많을 경우 끝 페이지 부근의 조회속도는 상당히 저하되는 것을 확인할 수 있다. 그렇다면 어떻게 해결할 수 있을까? 그 방법이 바로 커버링 인덱스를 적용하는 것이다.
커버링 인덱스란?
커버링 인덱스는 쿼리에 사용되는 모든 칼럼을 가지고 있는 인덱스를 의미한다. 다시 말하자면 SELECT, WHERE, ORDER BY, LIMIT, GROUP BY 등에서 사용되는 모든 컬럼이 인덱스 컬럼 안에 다 포함되는 경우이다.
간단한 예시를 들어보겠다. 아래의 SQL문은 커버링 인덱스가 적용되었다. 이 쿼리문에서는 WHERE절과 SELECT 사용된 컬럼은 오직 id 뿐이다. id 컬럼은 기본적으로 클러스터 인덱스 이기 때문에 커버링 인덱스가 적용되었다고 말할 수 있다.
SELECT id
FROM user
WHERE id = 1;커버링 인덱스 장점
커버링 인덱스를 사용하면 인덱스에 필요한 데이터들이 전부 다 포함되어 있기 때문에, 실제 테이블을 읽지 않고 인덱스만 읽어 SQL문을 전부 처리할 수 있다. 그러므로 추가적인 디스크I/O 가 소요되지 않기 때문에 데이터 조회 시간이 단축된다.
커버링 인덱스를 적용한 Offset 페이지네이션
가장 먼저 쿼리문에 사용되는 모든 컬럼들을 전부 인덱스에 포함시켜보자.
CREATE INDEX idx_board_on_region_deleted_id
ON board (region_id, deleteAt, id, createAt, stuffName, status, imageUrl);
아래의 쿼리문은 SELECT, WHERE, ORDER BY에 있는 모든 컬럼 값들이 인덱스에 걸려 있기때문에 커버링 인덱스가 적용되었다고 말할 수 있다.
SELECT b.id, b.createAt, b.stuffName, b.status, b.imageUrl, b.region_id
FROM board b
WHERE b.region_id = 1 AND b.deleteAt IS NULL
ORDER BY b.id DESC
LIMIT 6 OFFSET 800000;위의 SQL문 말고, 서브쿼리를 사용하여 SQL문을 실행할 수 있는데 결과는 같다.
SELECT b.id, b.createAt, b.stuffName, b.status, b.imageUrl, b.region_id
FROM (
SELECT id
FROM board
WHERE region_id = 1 AND deleteAt IS NULL
ORDER BY id DESC
LIMIT 6 OFFSET 800000
) AS sub
JOIN board b ON b.id = sub.id;
메인쿼리의 FROM 절의 내부에 서브쿼리를 생성해 일시적으로 뷰를 생성하는 방식으로 구성했다. 커버링 인덱스로 페이지네이션을 한 결과를 뷰(임시 테이블)로 만들어 board 테이블과 join해 데이터를 가져온다.
그렇다면 쿼리 실행속도는 어떨까?
커버링 인덱스를 활용한 Offset 실행 결과
분석 결과를 확인해보자.
-> Nested loop inner join (cost=717130 rows=0) (actual time=228..228 rows=6 loops=1)
-> Table scan on sub (cost=186979..186979 rows=0) (actual time=228..228 rows=6 loops=1)
-> Materialize (cost=186977..186977 rows=0) (actual time=228..228 rows=6 loops=1)
-> Limit/Offset: 6/800000 row(s) (cost=186977 rows=0) (actual time=228..228 rows=6 loops=1)
-> Filter: (board.deleteAt is null) (cost=186977 rows=534217) (actual time=0.122..206 rows=800006 loops=1)
-> Covering index lookup on board using idx_board_on_region_deleted_id (region_id=1, deleteAt=NULL) (reverse) (cost=186977 rows=534217) (actual time=0.121..168 rows=800006 loops=1)
-> Single-row index lookup on b using PRIMARY (id=sub.id) (cost=0.992 rows=1) (actual time=0.0039..0.00393 rows=1 loops=6)
다이어그램으로도 확인해보면 아래와 같다.
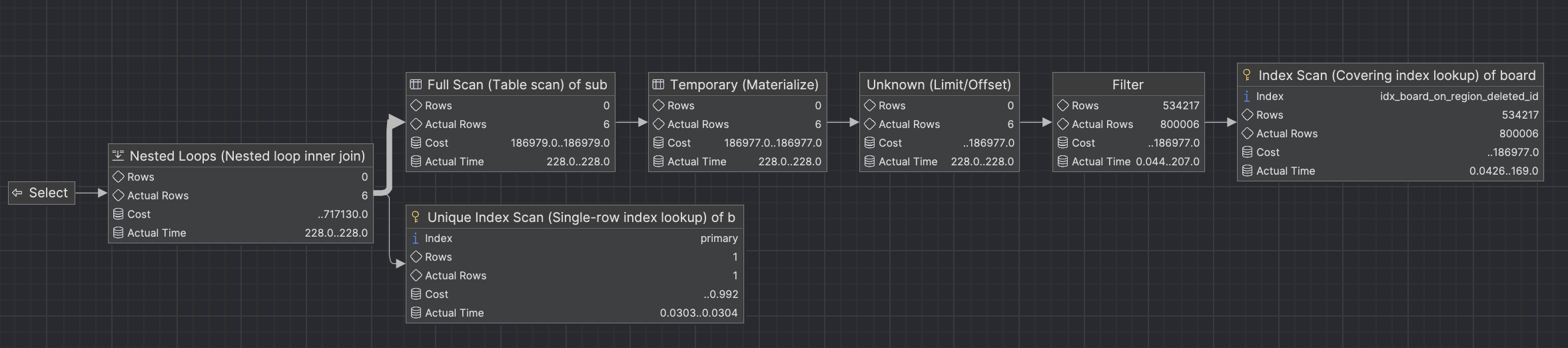
커버링 인덱스를 적용한 결과, Offset이 800,000 일 경우 실행시간은 228ms(0.228s)이다. 커버링 인덱스를 적용하기 전인 5063ms(5.063s) → 228ms(0.228s) 로 단축시켰다.
커버링 인덱스로 Offset 페이지네이션 정리
마지막으로 정리를 해보자.
위의 결과들을 바탕으로 커버링 인덱스를 사용한다면 인덱스 자체에서 모든 데이터를 검색할 수 있기때문에 추가적으로 테이블을 조회할 필요가 없어진다. 즉, 디스크 I/O 작업을 줄이기 때문에 Offset이 아무리 높더라도 인덱스만 조회하기 때문에 쿼리의 속도가 빨라진다.
하지만.. 커버링 인덱스의 한계..?
커버링 인덱스는 쿼리 성능을 향상 시킬 수 있는 아주 좋은 방법이다. 하지만 내가 조회하고자 하는 모든 컬럼을 인덱스에 포함시켜야 한다. 즉, 인덱스가 많아질 수 있다는 것이다.
인덱스가 많아진다는 것은 인덱스의 크기가 커진다는 것이며 이는 인덱스를 저장하기 위한 공간이 더 필요하다는 것이다. 인덱스를 유지하기 위해서는 비용이 들기때문에 이 부분도 고려를 해봐야한다.
Cursor와 Offset에 대한 개인적인 생각
여담으로 대부분이 알고 있듯이 Cursor 페이징 기법이 Offset 보다 쿼리 성능면이며, 데이터 중복조회 문제를 해결할 수 있기 때문에 Cursor 기반으로 구현을 하자고 이야기를 많이 한다. 물론 나도 그 부분은 동의하는 부분이다.
하지만 요구사항에 따라서 Offset 페이징 기법을 적용해야 할 때가 있을 수도 있다. 요구사항에서 Offset을 적용하지 않아도 되는 경우라면 Cursor로 구현하는 것도 쿼리 성능면에서 나쁘지 않다 생각한다. 물론 조회 조건이 너무 까다로워 진다면 그 부분도 고려를 해봐야겠다. 즉 무조건적으로 Cursor 페이징을 사용하는 게 아니라 요구사항이나 조회조건을 보고 판단해야 한다고 생각한다.
만약 나와 같이 Offset 기반의 페이징 기법을 적용해야 하는 요구사항이 있다면 커버링 인덱스를 적용해 보는 것도 좋은 경험이 될 것이다. 다만 위에서 언급했듯이 커버링 인덱스를 사용해야 한다면 인덱스가 많아진다는 한계가 있기 때문에, 어떤 컬럼을 꼭 보여줘야 할 지 한 번쯤 생각해보고 최대한 적은 컬럼을 커버링 인덱스로 적용하는 것이 좋겠다 라는 개인적인 생각으로 글을 마치겠다.

일전에 고민해보았던 내용인데 글 잘 읽었습니다~