변경전 지역 ERD
지역기반 관련 어플리케이션을 만들던 도중 지역을 확장하는 과정에서 여러 고민이 들었다. 지역을 확장하기 전에는 <서울특별시-강남구>, <경기도-수원시> 까지 저장하는 지역 데이터베이스를 설계했다.
아래의 ERD처럼 Province 테이블에는 서울특별시, 경기도, 제주특별자치도..등 대분류 정보가 들어가 있으며 City 테이블에는 강남구, 수원시, 하남시와 같은 시/군/구 정보를 저장했다. 그리고 Province와 City의 관계는 1:N으로 설정을 했다.

지역 데이터 마이그레이션 문제
<서울특별시-강남구-역삼동>, <서울특별시-강남구-청담동>… 과 같이 동/면/리 까지 지역을 확장하는 데 있어서 지역 테이블을 설계하는 것이 참으로 어렵다 생각이 든 이유는 아래와 같다.
지역마다 형식이 다르다?!
- 구가 없는 경우
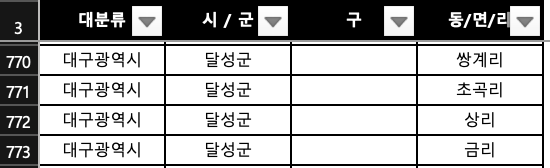
- 시/군이 없는 경우
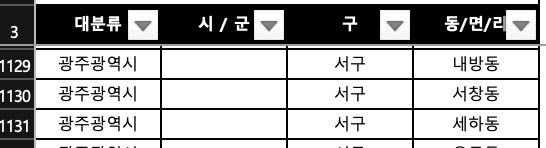
- 전부 있는 경우
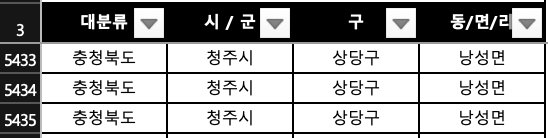
- 같은 대분류에서도 시/군 과 구의 여부가 다른 경우
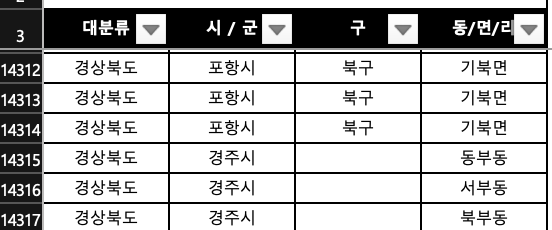
지역 데이터의 형식이 다양하기 때문에 지역마다 구조가 달라질 수 있다. 즉, 단위별로 데이터를 분리할 경우 데이터베이스 설계가 굉장히 복잡해진다. 두 번째로는 지역테이블을 여러개로 쪼갠다면 전체 지역 정보를 조회하기 위해서는 여러 테이블들과 join을 해야 하는 상황이 생기며 이는 데이터를 조회하는 데 있어서 복잡도와 성능이 저하된다.
그래서 아래와 같은 아이디어를 생각했다.
계층형으로 지역 데이터를 구조화: 부모-자식 관계
하나의 테이블로 지역 데이터를 저장할 수 있는 방법을 생각해 본 결과 자기참조로 데이터를 저장할 수 있다.
자기참조란 테이블 내에서 한 레코드가 다른 레코드를 참조하는 것을 말한다.
1) self join(자기참조) 방식
첫 번째로는 self join으로 데이터를 저장하는 방법도 있겠다. 이 방법으로 설계할 경우 데이터베이스의 설계는 간단해진다. 하지만 이 방법의 문제점은 Depth가 깊어질 경우 각 Depth를 순회하기 위해 많은 self join을 해야한다. 즉, 쿼리의 복잡성이 증가한다.
이를 해결하기 위해서, SQL의 WITH RECURSIVE의 특수 구문을 사용하면 된다.
2) Tree(materialized-path) 방식
두 번째 방식은 Tree Entity를 만들어서 사용하는 방식이다. 나는 NestJS의 @Tree()의 여러 방식 중 에서 materialized-path로 구현하였다.
다음은 TypeORM으로 설계한 Region이다.
import { Column, Entity, PrimaryGeneratedColumn, Tree, TreeChildren, TreeParent } from "typeorm";
@Entity()
@Tree('materialized-path')
export class Region {
@PrimaryGeneratedColumn()
id: number;
@Column()
name: string;
@TreeParent()
parent: Region;
@TreeChildren()
children: Region[];
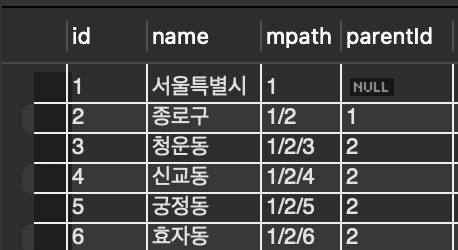
}데이터베이스에서는 다음과 같이 저장이 된다.
Materialized path를 줄여서 mpath라고 부르겠다. mpath는 현재 노드가 거쳐온 경로들을 전부 저장한다.
데이터가 아래와 같다면
- 서울특별시(Pk:1)
- 종로구(Pk:2)
- 청운동(Pk:3)
- 신교동(Pk:4)
- 강남구(Pk:5)
- 역삼동(Pk:6)
- 종로구(Pk:2)
서울특별시의 mpath는 1, 종로구의 mpath는 1,2 청운동의 mpath는 1,2,3이다.
데이터베이스에는 mpath와 자기참조 방식과 같은 부모 노드의 pk를 저장한 parentId 총 4개의 컬럼으로 구성되어있다.
왜 Tree(materialized-path)로 설계했는가?
위에서 언급했지만 총 2가지의 방법이 있고 나는 두 번째 방법으로 지역 데이터를 설계했다.
Materialized Path는 한 번의 조회로 해당 노드의 전체 경로를 바로 파악할 수 있어서 쿼리 속도가 첫 번째 방식에 비해 빠르다. 하지만 트리 구조이기 때문에 데이터가 업데이트 되면 모든 노드의 경로들을 업데이트 해야 한다는 단점이 있다.
WITH RECURSIVE을 활용한 첫 번째 방법은 데이터가 자주 업데이트 되는 상황에서 매우 효율적이다. Materialized Path와 다르게 부모 노드만 바꾸면 되기 때문이다.
내가 저장하고자 하는 데이터는 지역 데이터다. 데이터 특성상 새로 추가되거나 삭제될 일이 드물다. 즉, 데이터 업데이트가 거의 일어나지 않는다. 그래서 Materialized Path을 택했다.
