TIFF란?
TIFF란?
- Tag Image File Format의 줄임말
- 래스터 그래픽(픽셀)과 이미지 정보를 저장하는데 사용되는 컴퓨터 파일
- 사용자가 고쳐서 쓸 수 있는 유연함이 특징
특징
- 확장자
.tiffor.tif - 무손실 파일 압축 형식으로 파일 크기가 크며 이미지 품질이 손실되지 않음
구성
- IFH(Image File Header), IFD(Image File Directory) 및 비트맵 데이터를 세 섹션으로 포함
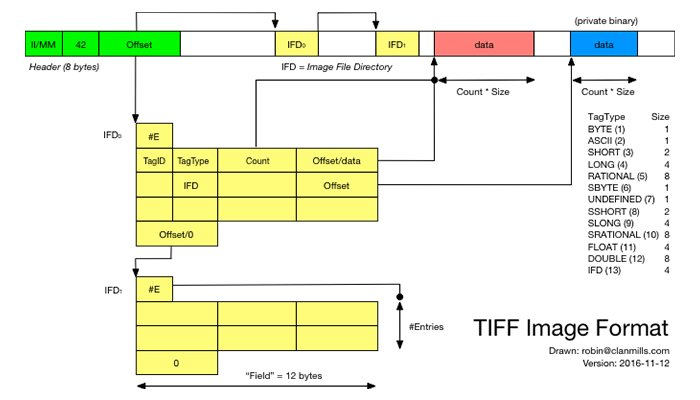
- 아래 내용은 bloodguy님 블로그에서 퍼온 내용입니다!
물리적 구성
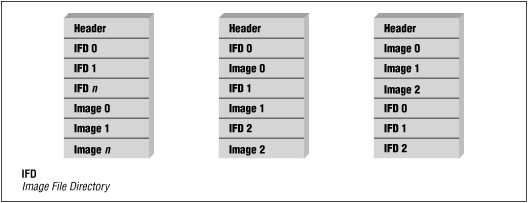
논리적 구성
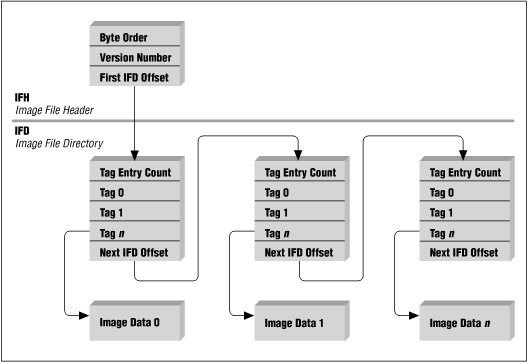
Image File Header (IFH)
typedef struct _TiffHeader
{
WORD Identifier;
/* Byte-order Identifier (2byte)
49 49 (Little Endian) 혹은 4D 4D (Big Endian) => Tiff*/
WORD Version; /* TIFF version number (always 2Ah)
00 2A (Little Endian) 혹은 2A 00 (Big Endian)(2byte)*/
DWORD IFDOffset; /* Offset of the first Image File Directory*/
} TIFHEAD;Image File Directory (IFD)
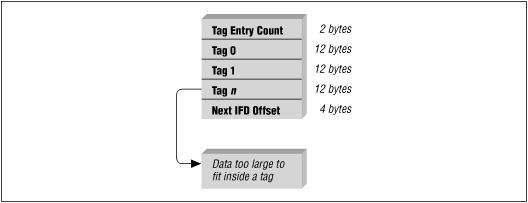
- 각 페이지의 헤더같은 존재, 일정한 위치와 형태를 지니지 않음.
- 하나의 TIFF에는 최소 1개의 IFD 존재
typedef struct _TifIfd
{
WORD NumDirEntries; /* Number of Tags in IFD (2바이트)*/
TIFTAG TagList[];
/* 태그 배열 태그는 이미지 크기, 컬러, 압축 등의 정보를 가지고 있음.
각 태그는 12바이트의 크기를 지님. */
DWORD NextIFDOffset;
/* 다음 IFD의 offset 정보.
만약 다음 IFD가 없다면 00 00 00 00 의 값을 가짐.(4byte)*/
} TIFIFD;Tags
typedef struct _TifTag
{
WORD TagId; /* The tag identifier(2byte) */
WORD DataType; /* 데이터 아이템의 타입(2byte) */
DWORD DataCount; /* 태그 데이터 안의 아이템 갯수(4byte) */
DWORD DataOffset; /* 데이터 아이템의 byte offset(4byte) */
} TIFTAG;Strips & Tiles
-
TIFF 에서 이미지 데이터를 구성하는 방식
-
Strips는 가로로 나누어진 1차원 데이터로, 이미지의 연속된 행을 담고 있음
-
Strips는 이미지를 일렬로 분할하여 처리하고 액세스하는데 효과적이지만, 전체 스트립을 읽어야 한다는 단점이 있습니다.
-
Tiles는 Strips와 달리 사각형 형태의 2차원 데이터로, 작은 비트맵 조각으로 이루어져 있습니다.
-
Tiles는 이미지를 작은 조각으로 분할하여 필요한 부분만 처리하고 액세스할 수 있게 해줍니다. 또한, 압축 알고리즘을 사용할 때 Tiles는 압축 해제를 최적화하는 데 도움이 됩니다.
라이브러리
- tifffile
- write by tifffile
from tifffile import imsave
import numpy as np
# create data
d = np.ndarray(shape=(10,20), dtype=np.float32) # also supports 64bit but ImageJ does not
d[()] = np.arange(200).reshape(10, 20)
# save 32bit float (== single) tiff
imsave('test.tif', d) #, description="hohoho")- write by pillow
from PIL import Image
import numpy as np
# create data
d = np.ndarray(shape=(10,20), dtype=np.float32)
d[()] = np.arange(200).reshape(10, 20)
im = Image.fromarray(d, mode='F') # float32
im.save("test2.tiff", "TIFF")
tifffile.imwrite(str(name[0])+"_compressed.tif", prediction_stack_16, metadata={'axes': 'XYZC'}, compression ='zlib')
tifffile.imwrite("_compressed.ome.tif", prediction_stack_16,imagej=True, resolution=(1./0.22, 1./0.22), metadata={'spacing': 0.72, 'unit': 'um', 'axes': 'ZCYX'}, compression ='zlib')
