합성곱 신경망(CNN)을 이용한 이미지 분류(image classification)
1. 라이브러리
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt2. 데이터(CIFAR-10) 불러오기
# CIFAR10: 클래스 10개를 가진 이미지 데이터
# 'plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # tensor로 바꾸고, normalize (RGB 채널)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=8, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8, shuffle=False)3. GPU 설정
# CPU/GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f'{device} is available.')
#result
cuda:0 is available.4. CNN 모델 구축
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 입력 채널수 3, 출력 채널수 6, 필터크기 5x5 , stride=1(defualt)
self.pool1 = nn.MaxPool2d(2, 2) # 필터크기 2, stride=2
self.conv2 = nn.Conv2d(6, 16, 5) # 입력 채널수 6, 출력 채널수 16, 필터크기 5x5 , stride=1(defualt)
self.pool2 = nn.MaxPool2d(2, 2) # 필터크기 2, stride=2
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 피쳐맵 16개를 일렬로 피면 16*5*5개의 노드가 생성
# 반드시 같아야함
self.fc2 = nn.Linear(120, 10) # 120개 노드에서 클래스의 개수인 10개의 노드로 출력
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x))) # conv1 -> ReLU -> pool1
x = self.pool2(F.relu(self.conv2(x))) # conv2 -> ReLU -> pool2
x = x.view(-1, 16 * 5 * 5) # 5x5 피쳐맵 16개를 일렬로 만든다.
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
net = Net().to(device) # 모델 선언
print(net) # 피쳐의 크기: 32 -> 28 ->14 -> 10 -> 5
#result
Net(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=10, bias=True)
)5. 모델 학습
criterion = nn.CrossEntropyLoss() # CrossEntropyLoss는 softmax 계산까지 포함되어 있음
# 모델의 마지막 output node에 별도의 활성화 함수를 사용하지 않아도 됨
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)
loss_ = [] # 그래프를 그리기 위한 loss 저장용 리스트
n = len(trainloader) # 배치 개수
for epoch in range(10): # 10번 학습을 진행 (epoch -> batch)
running_loss = 0.0
for i, data in enumerate(trainloader, 0): # batch
inputs, labels = data[0].to(device), data[1].to(device) # 배치 데이터
optimizer.zero_grad()
outputs = net(inputs) # 예측값 산출
loss = criterion(outputs, labels) # 손실함수 계산
loss.backward() # 손실함수 기준으로 역전파 선언
optimizer.step() # 가중치 최적화 # 이 구조도 계속 사용
# print statistics
running_loss += loss.item()
loss_.append(running_loss / n)
print('[%d] loss: %.3f' %(epoch + 1, running_loss / len(trainloader)))
print('Finished Training')
#result
[1] loss: 1.730
[2] loss: 1.371
[3] loss: 1.219
[4] loss: 1.120
[5] loss: 1.044
[6] loss: 0.985
[7] loss: 0.938
[8] loss: 0.896
[9] loss: 0.855
[10] loss: 0.824
Finished Training6. loss plot 그리기
plt.plot(loss_)
plt.title("Training Loss")
plt.xlabel("epoch")
plt.show()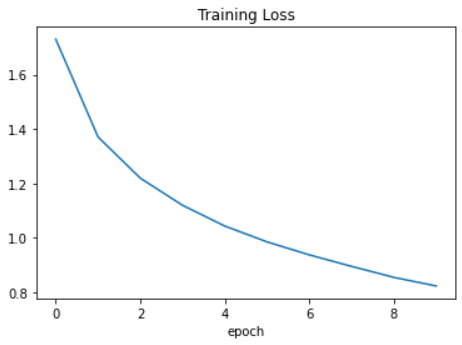
7. 모델 저장하기
PATH = './models/cifar_net.pth' # 모델 저장할 경로
torch.save(net.state_dict(), PATH) # 모델 저장! (파라미터 정보)8. 모델 불러오기
# 모델 불러오기는 엄밀히 말하자면 모델의 파라미터를 불러오는 것. 따라서 모델의 뼈대를 먼저 선언하고 (같은 모델)
# 모델의 파라미터를 불러와 pretrained model을 만든다 ! (이런 걸 pretrained)라고 함
net = Net().to(device) # 모델 선언
net.load_state_dict(torch.load(PATH)) # 모델 파라미터 불러오기
#result
<All keys matched successfully> # 이게 나오면 정상적으로 잘 되는 것9. 모델 평가
# 평가 데이터를 이용해 정확도를 구해보자
# output은 미니배치의 결과가 산출되기 때문에 for문을 통해서 test 전체의 예측값을 구한다.
correct = 0
total = 0
with torch.no_grad(): # 평가에서는 no_grad() 매우 중요
for data in testloader: # batch 개수 만큼
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # predicted는 max 값의 좌표 (indices 보여줌)
total += labels.size(0) # 개수 누적(총 개수)
correct += (predicted == labels).sum().item() # 누적(맞으면 1, 틀리면 0으로 합산)
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
#result
Accuracy of the network on the 10000 test images: 63 %
pppanghyun