깊은 K-평균 알고리즘 (Deep K-means algorithm)은 Autoencoder와 머신러닝의 군집화 기법인 K-means 알고리즘을 결합한 방법이다. 이 알고리즘 또한 label을 사용하지 않는 비지도 학습이다.

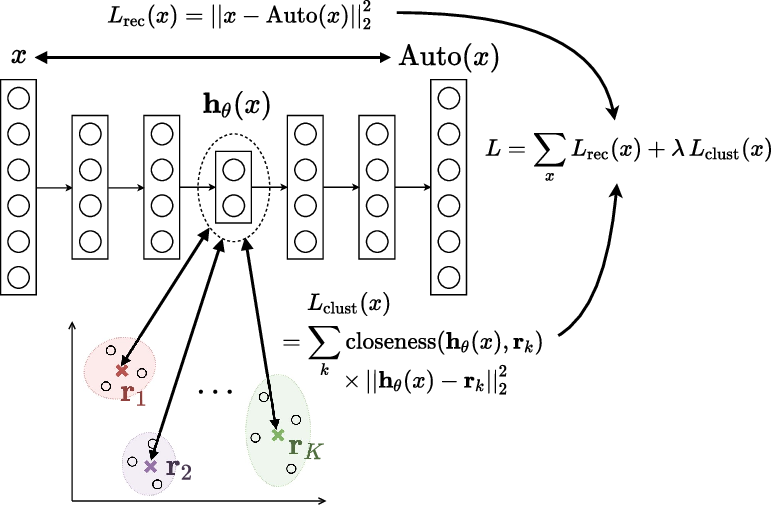
위의 Autoencoder 모델을 보면 input image -> latent vector -> reconstructed image 의 형태로 학습이 진행됨을 알 수 있다. 직관적으로 생각해보면 정상적으로 학습된 모델의 latent vector에는 input image의 정보가 함축되어 있음을 알 수 있다.
그렇다면, 이 latent vector(아래 그림에서는 h(x))에 함축된 정보를 통해 input image를 군집화 시키는 k-means clustering을 진행할 수 있는데, 이런 알고리즘을 K-평균 알고리즘이라 한다.
1. 라이브러리
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
import numpy as np
from scipy.optimize import linear_sum_assignment as linear_assignment
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
# CPU/GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f'{device} is available.')2. 데이터 불러오기 (latent size도 정의)
batch_size = 128
num_clusters = 10 # k-mean에서는 num cluster를 hyperparameter로 정의
latent_size = 10 # latent vector size
trainset = torchvision.datasets.MNIST('./data/', download=True, train=True, transform=transforms.ToTensor())
testset = torchvision.datasets.MNIST('./data/', download=True, train=False, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=True)3. 모델 정의 (flatten, deflatten, encoder, decoder, kmeans)
class Flatten(torch.nn.Module):
def forward(self, x):
batch_size = x.shape[0]
return x.view(batch_size, -1)
class Deflatten(nn.Module):
def __init__(self, k):
super(Deflatten, self).__init__()
self.k = k
def forward(self, x):
s = x.size()
feature_size = int((s[1]//self.k)**.5)
return x.view(s[0],self.k, feature_size, feature_size)
class Encoder(nn.Module):
def __init__(self, latent_size):
super(Encoder, self).__init__()
k = 16
self.encoder = nn.Sequential(
nn.Conv2d(1, k, 3, stride=2),
nn.ReLU(),
nn.Conv2d(k, 2*k, 3, stride=2),
nn.ReLU(),
nn.Conv2d(2*k, 4*k, 3, stride=1),
nn.ReLU(),
Flatten(), # linear 직전 flatten
nn.Linear(1024, latent_size),
nn.ReLU()
)
def forward(self, x):
return self.encoder(x)
class Decoder(nn.Module):
def __init__(self, latent_size):
super(Decoder, self).__init__()
k = 16
self.decoder = nn.Sequential(
nn.Linear(latent_size, 1024),
nn.ReLU(),
Deflatten(4*k), # linear 직후 deflatten
nn.ConvTranspose2d(4*k, 2*k, 3, stride=1), # (입력 채널 수, 출력 채널 수, 필터 크기, stride)
nn.ReLU(),
nn.ConvTranspose2d(2*k, k, 3, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(k, 1, 3, stride=2,output_padding=1),
nn.Sigmoid()
)
def forward(self, x):
return self.decoder(x)
class Kmeans(nn.Module):
def __init__(self, num_clusters, latent_size):
super(Kmeans, self).__init__()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.num_clusters = num_clusters
self.centroids = nn.Parameter(torch.rand((self.num_clusters, latent_size)).to(device))
def argminl2distance(self, a, b): # L2 distance
return torch.argmin(torch.sum((a-b)**2,dim=1),dim=0)
def forward(self, x):
y_assign = []
for m in range(x.size(0)):
h = x[m].expand(self.num_clusters,-1)
assign = self.argminl2distance(h, self.centroids)
y_assign.append(assign.item())
return y_assign, self.centroids[y_assign]4. 클러스터링 정확도 함수 정의
def cluster_acc(y_true, y_pred):
y_true = np.array(y_true)
y_pred = np.array(y_pred)
D = max(y_pred.max(), y_true.max()) + 1
w = np.zeros((D, D), dtype=np.int64)
for i in range(y_pred.size):
w[y_pred[i], y_true[i]] += 1
ind = linear_assignment(w.max() - w)
return sum([w[i, j] for i, j in zip(ind[0], ind[1])]) * 1.0 / y_pred.size
def evaluation(testloader, encoder, kmeans, device):
predictions = []
actual = []
with torch.no_grad():
for images, labels in testloader:
inputs = images.to(device)
labels = labels.to(device)
latent_var = encoder(inputs)
y_pred, _ = kmeans(latent_var) # y_assign
predictions += y_pred
actual += labels.cpu().tolist()
return cluster_acc(actual, predictions)5. 손실함수 및 최적화 방법 정의
encoder = Encoder(latent_size).to(device)
decoder = Decoder(latent_size).to(device)
kmeans = Kmeans(num_clusters, latent_size).to(device)
# Loss and optimizer
criterion1 = torch.nn.MSELoss()
criterion2 = torch.nn.MSELoss()
optimizer = torch.optim.Adam(list(encoder.parameters()) +
list(decoder.parameters()) +
list(kmeans.parameters()), lr=1e-3)6. 학습하기
# Training
T1 = 50
T2 = 200
lam = 1e-3
ls = 0.05
for ep in range(300):
if (ep > T1) and (ep < T2):
alpha = lam*(ep - T1)/(T2 - T1) # 1/100, 2/100, .., 99/100
elif ep >= T2:
alpha = lam
else:
alpha = lam/(T2 - T1)
running_loss = 0.0
for images, _ in trainloader:
inputs = images.to(device)
optimizer.zero_grad()
latent_var = encoder(inputs)
_, centroids = kmeans(latent_var.detach())
outputs = decoder(latent_var)
l_rec = criterion1(inputs, outputs)
l_clt = criterion2(latent_var, centroids)
loss = l_rec + alpha*l_clt
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
if ep % 10 == 0:
testacc = evaluation(testloader, encoder, kmeans, device)
print('[%d] Train loss: %.4f, Test Accuracy: %.3f' %(ep, avg_loss, testacc))
if avg_loss < ls:
ls = avg_loss
torch.save(encoder.state_dict(),'./models/dkm_en.pth')
torch.save(decoder.state_dict(),'./models/dkm_de.pth')
torch.save(kmeans.state_dict(),'./models/dkm_clt.pth')7. 시각화
encoder.load_state_dict(torch.load('./models/dkm_en.pth'))
decoder.load_state_dict(torch.load('./models/dkm_de.pth'))
kmeans.load_state_dict(torch.load('./models/dkm_clt.pth'))
#result
<All keys matched successfully>
with torch.no_grad():
for images, _ in testloader:
inputs = images.to(device)
latent_var = encoder(inputs)
outputs = decoder(latent_var)
input_samples = inputs.permute(0,2,3,1).cpu().numpy()
reconstructed_samples = outputs.permute(0,2,3,1).cpu().numpy()
break
columns = 10
rows = 5
print("Input images")
fig=plt.figure(figsize=(columns, rows))
for i in range(1, columns*rows+1):
img = input_samples[i-1]
fig.add_subplot(rows, columns, i)
plt.imshow(img.squeeze()) # squeeze()는 차원이 1인 차원을 제거
plt.axis('off')
plt.show()
print("Reconstruction images")
fig=plt.figure(figsize=(columns, rows))
for i in range(1, columns*rows+1):
img = reconstructed_samples[i-1]
fig.add_subplot(rows, columns, i)
plt.imshow(img.squeeze()) # squeeze()는 차원이 1인 차원을 제거
plt.axis('off')
plt.show()input image

Reconstruction image

8. 모델 결과 확인
predictions = []
actual = []
latent_features = []
with torch.no_grad():
for images, labels in testloader:
inputs = images.to(device)
labels = labels.to(device)
latent_var = encoder(inputs)
y_pred, _ = kmeans(latent_var)
predictions += y_pred
latent_features += latent_var.cpu().tolist()
actual += labels.cpu().tolist()
print(cluster_acc(actual, predictions))
# result
0.894linear sum이 뭔지 몰라서 찾아보니..


pppanghyun