현실에서의 딥러닝 학습은 수 시간 ~ 수 일이 넘어가는 경우가 많다. 이런 경우 서버 연결 오류와 같은 예상치 못한 일로 작업이 중단되는 경우가 가끔 일어난다 (쌍욕 나옴)
따라서, 현재 학습 중인 모델의 정보를 저장하는 것은 '매우' 중요한 일이다. 이때 모델의 정보가 제대로 저장되었다면 다시 중단한 시점부터 학습을 재개하거나 학습이 완료된 모델을 불러올 수 있다.
1. 라이브러리 설치
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# ANN
import torch
from torch import nn, optim # torch 내의 세부적인 기능
from torch.utils.data import DataLoader, Dataset # 데이터를 모델에 사용
import torch.nn.functional as F # torch 내의 세부적인 기능
# Loss
from sklearn.metrics import mean_squared_error # Regression 문제의 평가
# Plot
import matplotlib.pyplot as plt # 시각화 도구2. 데이터 불러오기 ('인공 신경망' 게시물에서 사용했던 scaled data)
# 데이터를 넘파이 배열로 만들기
X = df.drop('Price', axis=1).to_numpy() # 데이터프레임에서 타겟값(Price)을 제외하고 넘파이 배열로 만들기
Y = df['Price'].to_numpy().reshape((-1,1)) # 데이터프레임 형태의 타겟값을 넘파이 배열로 만들기
3. 넘파이 데이터를 Tensor 형태의 dataset 만들기
class TensorData(Dataset):
def __init__(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data)
self.y_data = torch.FloatTensor(y_data)
self.len = self.y_data.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len4. Train / Test Split & Dataloader 생성
# 전체 데이터를 학습 데이터와 평가 데이터로 분할 (test = 0.5)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5)
# 학습 데이터, 시험 데이터 배치 형태로
trainsets = TensorData(X_train, Y_train)
trainloader = torch.utils.data.DataLoader(trainsets, batch_size=32, shuffle=True)
testsets = TensorData(X_test, Y_test)
testloader = torch.utils.data.DataLoader(testsets, batch_size=32, shuffle=False)5. 학습할 모델 생성 (regressor)
입력층 1개(노드 13개=변수의 개수), 은닉층 2개, 출력층 1개
class Regressor(nn.Module):
def __init__(self):
super().__init__() # 모델 연산 정의
self.fc1 = nn.Linear(13, 50, bias=True) # 입력층(13) -> 은닉층1(50)으로 가는 연산
self.fc2 = nn.Linear(50, 30, bias=True) # 은닉층1(50) -> 은닉층2(30)으로 가는 연산
self.fc3 = nn.Linear(30, 1, bias=True) # 은닉층2(30) -> 출력층(1)으로 가는 연산
self.dropout = nn.Dropout(0.2) # 연산이 될 때마다 20%의 비율로 랜덤하게 노드를 없앰
def forward(self, x): # 모델 연산
x = F.relu(self.fc1(x)) # Linear 계산 후 활성화 함수 ReLU를 적.
x = self.dropout(F.relu(self.fc2(x))) # 은닉층2에서 드랍아웃을 적용
x = F.relu(self.fc3(x)) # Linear 계산 후 활성화 함수 ReLU를 적용
return x
# 주의 사항
# 드랍아웃은 과적합(overfitting)을 방지하기 위해 노드의 일부를 배제하고 계산하는 방식
# 절대로 출력층에 사용 X6. 모델, 손실함수, 최적화 방법 (학습 전)
# weight_decay는 L2 정규화에서의 penalty 정도를 의미
model = Regressor()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-3)
pret = 0 # 0 = pretrained model이 없다는 뜻
# 깨알 skill !!!!!
if pret == 1:
checkpoint = torch.load ('./models/4-4reg.pt')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
loss_ = checkpoint['loss']
ep = checkpoint['epoch']
ls = loss_[-1]
print(f"epoch={ep}, loss={ls}")
ep = ep + 1
else:
ep = 0
ls = 1 # loss 가 1 미만이면 best loss 기준으로 모델을 저장 (개인 취향)
loss_ = [] # 그래프를 그리기 위한 loss 저장용 리스트 7. 학습 진행 및 저장 및 시각화 (.pt 형태로 학습된 모델의 정보 저장!)
n = len(trainloader)
for epoch in range(ep, 2000):
running_loss = 0.0
for i, data in enumerate(trainloader, 0): # 무작위로 섞인 32개 데이터가 있는 배치 들어옴
inputs, values = data # data에는 X, Y가 들어있다.
optimizer.zero_grad() # 최적화 초기화
outputs = model(inputs) # 모델에 입력값 대입 후 예측값 산출
loss = criterion(outputs, values) # 손실 함수 계산
loss.backward() # 손실 함수 기준으로 역전파 설정
optimizer.step() # 역전파를 진행하고 가중치 업데이트
running_loss += loss.item() # epoch 마다 평균 loss를 계산하기 위해 배치 loss를 더한다.
l = running_loss/n # loss
loss_.append(l) # MSE(Mean Squared Error) 계산
if l < ls: # torch.save를 사용해서 딕셔너리 사용해서 저장
torch.save({'epoch': epoch,
'loss': loss_,
'model': model.state_dict(),
'optimizer': optimizer.state_dict()
}, './models/4-4reg.pt')
print('Finished Training')
plt.plot(loss_)
plt.title("Training Loss")
plt.xlabel("epoch")
plt.show()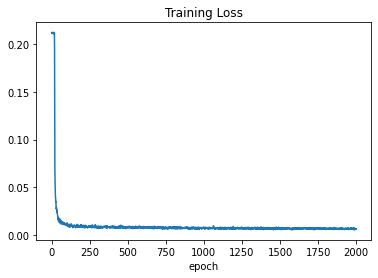
8. 저장된 모델 불러오기
pret = 1 # 1 = pretrained model이 있다는 뜻
if pret == 1:
checkpoint = torch.load ('./models/4-4reg.pt') # 경로에서 .pt 파일 불러오기
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
loss_ = checkpoint['loss']
ep = checkpoint['epoch']
ls = loss_[-1]
print(f"epoch={ep}, loss={ls}")
ep = ep + 1
else:
ep = 0
ls = 1 # loss 가 1 미만이면 best loss 기준으로 모델을 저장
loss_ = [] # 그래프를 그리기 위한 loss 저장용 리스트 9. 학습된 모델 불러와서 평가하기
def evaluation(dataloader):
predictions = torch.tensor([], dtype=torch.float) # 예측값을 저장하는 텐서
actual = torch.tensor([], dtype=torch.float) # 실제값을 저장하는 텐서
with torch.no_grad():
model.eval() # 평가를 할 때에는 .eval() 반드시 사용해야 한다.
for data in dataloader:
inputs, values = data
outputs = model(inputs)
predictions = torch.cat((predictions, outputs), 0) # cat을 통해 예측값을 누적
actual = torch.cat((actual, values), 0) # cat을 통해 실제값을 누적
rmse = np.sqrt(mean_squared_error(predictions, actual)) # sklearn을 이용하여 RMSE 계산
return rmse
# 평가 시 .eval()을 사용해야 하는 이유
# 평가 시에는 온전한 모델로 평가를 해야하는데 .eval()이 아닌 .train()인 경우 드랍아웃이 활성화 되어 있음
# 따라서 드랍아웃이나 배치 정규화 등과 같이 학습 시에만 사용하는 기술들을 평가 시에는 비활성화 해야만 하
# 매우중요 !! (모델의 구조가 완벽하게 같아야함)
checkpoint = torch.load ('./models/4-4reg.pt') # 저장된 딕셔너리
model.load_state_dict(checkpoint['model']) # LOAD!
#result
<All keys matched successfully> # 모든 구조가 같아야 이렇게 나옴10. Result
train_rmse = evaluation(trainloader) # 학습 데이터의 RMSE
test_rmse = evaluation(testloader) # 시험 데이터의 RMSE
print("Train RMSE: ",train_rmse)
print("Test RMSE: ",test_rmse)
# result
Train RMSE: 0.073735304
Test RMSE: 0.120262444학습의 흐름(for문)과 모델(Regressor) 부분을 주의 깊게 살펴보기

pppanghyun