
*이 글은 2022년 1월~2월 진행한 스터디를 옮긴 글입니다.
22.01.10 원형연결리스트 정리
원형연결리스트의 특징
- 마지막 노드의 링크가 첫번째 노드를 가리킴. 모든 노드가 연결된 형태. 즉, 모든 노드의 link는 NULL이 아님. *그림은 Head와 Tail을 나눴지만 나는 Head를 Tail 위치에 두는 것으로 구현함.
- 헤드포인터가 마지막 노드를 가리키게끔 구성하면 첫번째 노드도 알기 쉽고 마지막 노드도 알기 쉬움.
- 노드가 1개인 원형리스트는 자기 자신을 가리키는 link를 가짐.
원형연결리스트 관련 연산
- 노드의 삽입
👉 원형 연결리스트의 **중간 노드**로 삽입하는 경우
```cpp
void insert_node_middle(Node* new_node, Node*pre) {
if (Head == NULL) {
new_node->link = new_node;
Head = new_node;
}
else if (pre == NULL) {
new_node->link = Head->link;
Head = new_node;
}
else {
new_node->link = pre->link;
pre->link = new_node;
if (Head == pre) {
Head = new_node;
}
}
}
```
👉 원형 연결리스트의 **첫 노드**로 삽입하는 경우
```cpp
void insert_node_front(Node*new_node) {
if (Head == NULL) {
new_node->link = new_node;
Head = new_node;
}
else {
new_node->link = Head->link;
Head->link = new_node;
}
}
```
👉 원형 연결리스트의 **마지막 노드**로 삽입하는 경우
```cpp
void insert_node_rear(Node* new_node) {
if (Head == NULL) {
new_node->link = new_node;
Head = new_node;
}
else {
new_node->link = Head->link;
Head->link = new_node;
Head = new_node;
}
}
```- 노드의 삭제
👉 선행노드가 있는 경우 노드 삭제
```cpp
void removed_node(Node* pre) {
Node* removed;
if (Head == NULL || Head->link == Head)Head = NULL;
else {
removed = pre->link;
pre->link = removed->link;//pre->link=pre->link->link도 가능함
if (Head == removed)Head = pre;
}
}
```
👉 특정 값을 가진 데이터 삭제
```cpp
void removed_node_key(int key) {
if (Head == NULL)return;
else if ( (Head->link == Head) && (Head->data = key) ) {
Head = NULL;
}
else {
Node* pre = Head;
do{
if (pre->link->data== key) {
Node* removed = pre->link;
/*왜 새로운 노드를 굳이 추가하냐면 removed로 설정된 값이 계속 변하기 때문에 임의의 노드에 저장하는 것*/
pre->link = removed->link;
if (Head == removed) Head = pre;
return;
}
pre = pre->link;
} while (pre != Head);
}
}
```- 노드의 출력
**//do-while문 사용하는 이유에 대해 생각해보기** void print_node() { if (Head == NULL) { cout << "empty node" << endl; } else { Node* list = Head; do { cout << list->link->data << endl; list = list->link; } while (list != Head); } }
- 전체 코드
**//원형연결리스트 복습** #include<iostream> using namespace std; class Node { public: int data; Node* link; }; Node* Head;//리스트의 마지막노드를 가리킴 **/*선행노드를 아는 경우*/** void insert_node_A(Node*pre,Node*new_node) { if (Head == NULL) { new_node->link = new_node; Head = new_node; } else { new_node->link = pre->link; pre->link = new_node; if (pre == Head) { Head = new_node; } } } **/*선행노드를 모르는 경우(마지막)*/** void insert_node_B(Node* new_node) { if (Head == NULL) { new_node->link = new_node; Head = new_node; } else { new_node->link = Head->link; Head->link = new_node; Head = new_node; } } **/*선행노드를 모르는 경우(처음)*/** void insert_node_C(Node* new_node) { if (Head == NULL) { new_node->link = new_node; Head = new_node; } else { new_node->link = Head->link; Head->link = new_node; } } **/*특정 값의 노드 삭제*/** void delete_node(int key) { if (Head == NULL)return; else if (Head->link==Head&&Head->data==key) { Head = NULL; } else { Node* list = Head; do { if (list->link->data == key) { Node* removed = list->link; list->link = removed->link; if (Head==removed) { Head = list; } return; } list = list->link;//논리적오류 이유: 반복 조건을 if문 안에 넣어버림.^^; } while (list != Head); } } **/*원형연결리스트의 출력*/** void print_node() { if (Head == NULL) { cout << "empty node" << endl; } else { Node* list = Head; do { cout << list->link->data << endl; list = list->link; } while (list != Head); } } **void main() {** Head = NULL; int answer; int del; for (int i = 0; i < 3; i++) { cout << "노드의 데이터를 입력하세요: "; cin >> answer; Node* new_node = new Node; new_node->data = answer; new_node->link = NULL; insert_node_B(new_node); } print_node(); cout << "삭제할 데이터를 입력하세요: "; cin >> del; delete_node(del); print_node(); }
22.01.11 이중연결리스트 정리(22.01.12내용추가)
이중연결리스트의 특징
- 하나의 노드가 선행노드와 후속노드에 대한 두개의 링크를 가짐. 그러므로 양방향 검색이 가능해서 더 간단한 연산으로 삽입/삭제 등이 가능해짐. 그러나 구현이 복잡하다는 단점이 존재.
- 이중연결리스트+원형리스트+헤드노드를 혼합한 형태로 구현함. Head와 link의 값이 NULL인 경우를 배제하는 방식. 코드 짤 때 더 편리하게 짤 수 있음.
- 헤드노드란? 데이터를 가지지 않고 단지 삽입/삭제 코드를 간단히 짤 목적으로 만든 노드임. 헤드포인터와 별개의 노드!!! (단, 헤드포인터는 항상 헤드노드를 가리키게 짤거임)
- 정리해보면 이중연결리스트를 사용하기 편하게 변형해서 얻는 이점은 NULL값을 가지는 포인터가 없어지고 앞/뒤 검색이 모두 가능해진다는 점.
이중연결리스트 관련 연산
- 노드의 구조
class Node{ public: int data; Node*llink; Node*rlink; **//생성자** Node() { llink = rlink = NULL; } Node(int value) { data = value; llink = rlink = NULL; } };
- 노드의 삽입
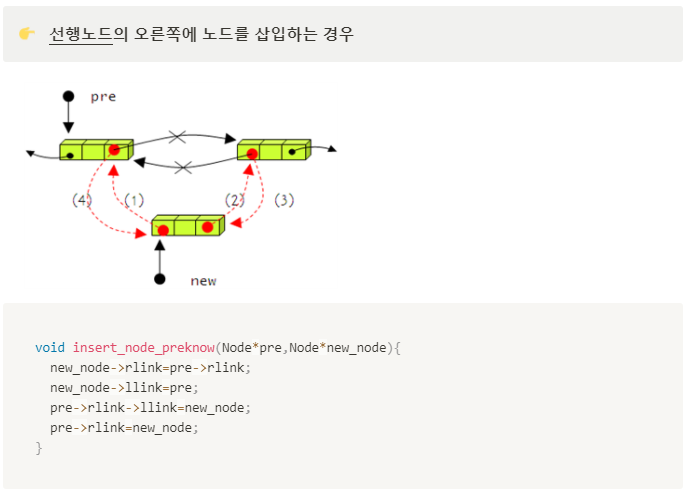

- 노드의 삭제
**/*특정 데이터를 가진 노드 삭제*/** void delete_node(int key) { for (Node* list = Head->rlink; list != Head; list = list->rlink) { if (list->data == key) { list->llink->rlink = list->rlink; list->rlink->llink = list->llink; break; } } }
- 노드의 출력
void print_node() { cout << "[리스트의 내용 출력]" << endl; for (Node* list = Head->rlink; list !=Head; list = list->rlink){ cout << list->data << endl; } }
- 전체 코드
**//이중연결리스트 구현 #include<iostream> using namespace std; //이중연결리스트(원형리스트+헤드노드) class Node { public: int data; Node* llink; Node* rlink; }; Node* Head=NULL; /*선행노드를 아는 경우 노드삽입*/ void insert_node_A(Node*pre,Node*new_node) { new_node->rlink = pre->llink; new_node->llink = pre; pre->rlink->llink = new_node; pre->rlink = new_node; } /*선행노드 모르는 경우 첫 노드(헤드노드 제외) 삽입*/ void insert_node_B(Node* new_node) { new_node->llink = Head; new_node->rlink = Head->rlink; Head->rlink->llink = new_node; Head->rlink = new_node; } /*선행노드 모르는 경우 리스트 마지막에 노드에 삽입*/ void insert_node_C(Node* new_node) { new_node->rlink = Head; new_node->llink = Head->llink; Head->llink->rlink = new_node; Head->llink = new_node; } /*특정 데이터를 가진 노드 삭제*/ void delete_node(int key) { for (Node* list = Head->rlink; list != Head; list = list->rlink) { if (list->data == key) { list->llink->rlink = list->rlink; list->rlink->llink = list->llink; break; } } } /*노드 출력*/ void print_node() { cout << "[리스트의 내용 출력]" << endl; for (Node* list = Head->rlink; list !=Head; list = list->rlink){ cout << list->data << endl; } } void main() { //헤드노드 생성 Head = new Node; Head->data = NULL; Head->llink = Head; Head->rlink = Head; int ans; int data; for (int i = 0; i < 3; i++) { cout << "데이터의 값을 입력해주세요: "; cin >> ans; Node* new_node = new Node; new_node->data = ans; new_node->rlink = NULL; new_node->llink = NULL; insert_node_C(new_node); } print_node(); cout << "삭제할 값: "; cin >> data; delete_node(data); print_node(); }**
프로그래머스 1단계 크레인문제 풀이
-
참고x(논리적오류발생)
#include <string> #include <vector> #include <cmath> /* 1. moves가 갖고있는 값을 선택함(열) 2. 같은 열 내에서 행의 값이 0이 아닌 가장 큰 인덱스를 찾음. 3. 해당 인덱스의 값을 can에 넣고 해당 인덱스의 값은 0으로 바꿈. 4. 반복을 수행하는 과정에서 연속적으로 중복인 원소가 존재하면 해당 인덱스 두개를 삭제해야 함. 5. 삭제할 때 답에 2씩 더함. */ using namespace std; int solution(vector<vector<int>> board, vector<int> moves) { int answer = 0; vector<int> can; //board의 제곱근 구하여 N의 값을 찾는다 int idx=sqrt(board.size()); //int j: 열(moves가 갖고있는 값) //int i: 상하로 행 탐색(4-3-2-1-0 원소값 중 0이 아닌 값을 발견하면 리턴 종료) for(int j=0;j<moves.size();j++){ for(int i=idx-1;i==0;i--){ if((board[i][moves[j]-1])!=0){ can.push_back(board[i][moves[j]-1]); //한번 크레인에 선택된 원소는 0으로 처리 board[i][moves[j]-1]=0; } } } if(can.size()>=2){ for(int k=can.size()-1;k==0;k--){ if(can[k]==can[k-1]){ answer+=2; can.erase(can.begin()+k , can.begin()+k-1); } } } return answer; } -
참고 후 수정
#include <string> #include <vector> /* 1. moves가 갖고있는 값을 선택함(열) 2. 같은 열 내에서 행의 값이 0이 아닌 가장 큰 인덱스를 찾음. 3. 해당 인덱스의 값을 can에 넣고 해당 인덱스의 값은 0으로 바꿈. 4. 반복을 수행하는 과정에서 연속적으로 중복인 원소가 존재하면 해당 인덱스 두개를 삭제해야 함. 5. 삭제할 때 답에 2씩 더함. */ using namespace std; int solution(vector<vector<int>> board, vector<int> moves) { int answer = 0; vector<int> can; //int j: 열(moves가 갖고있는 값) //int i: 상하로 행 탐색(4-3-2-1-0 원소값 중 0이 아닌 값을 발견하면 리턴 종료) for(int j=0;j<moves.size();j++){ for(int i=0;i<board[0].size();i++){ if((board[i][moves[j]-1])!=0){ can.push_back(board[i][moves[j]-1]); //한번 크레인에 선택된 원소는 0으로 처리 board[i][moves[j]-1]=0; if(can.size()>=2 && can[can.size()-1]==can[can.size()-2]){ can.pop_back(); can.pop_back(); answer+=2; } break; } } } return answer; } -
관련 STL 정리*
- C++ STL
Vector란
-
Vector는 동적 배열 구조를 C++로 구현한 것. 맨 끝에서 삽입 및 삭제가 일어나고 Queue로 이해하면 됨
-
동적으로 크기가 변하고 메모리가 연속적이기 때문에 자동으로 배열의 크기를 조절할 수 있고 유연하게 객체의 추가 및 삭제가 가능함
-
중간 데이터를 삭제할수도 있음. vector의 erase함수를 통해 가능. 그러나 삭제가 빈번히 일어나는 경우에는 vector보단 연결리스트를 쓰는 것을 추천.
Vector의 선언 방법
-
#include헤더파일 포함해야 함.
-
vector<data_type>name; 으로 선언함.
1) Vector의 크기를 정하지 않은 경우
vector<변수 타입> 이름;
vector<int> v;2) Vector의 크기를 정하는 경우
vector<변수 타입> 이름(크기);
아래 예제와 같이 기본값이 0인 사이즈 10인 벡터 v를 선언함.
vector<int> v(10); vector<string> v2(5);3) Vector의 크기를 정하고 데이터를 초기화할 경우
vector<변수 타입> 이름(크기, 초기화 상수);
크기 10의 벡터에 1로 초기화하고 싶은 경우 아래의 방법과 같이 선언함.
vector<int> v(10,1);
vector 멤버함수
/*아래의 설명은 벡터를 다음과 같이 선언했다고 가정함*/ vector<int>v;<1. 원소 접근>
1) v[idx]
v[idx] 형태로 idx번째의 원소를 참조.
2) v.at(idx)
벡터 v의 idx번째 원소를 참조.
3) v.front(), v.back()
v.front() : Vector의 첫번째 원소를 참조.
v.back() : Vector의 마지막 원소를 참조.
4) v.begin(), v.end()
v.begin() : iterator로 접근 시 vector의 맨 첫번째 데이터 위치를 가리킴.
v.end() : iterator로 접근 시 vector의 맨 마지막 데이터 위치의 다음을 가리킴.
<2. 삽입/ 삭제>
1) v.push_back(데이터);
벡터 v의 데이터 타입에 맞는 데이터(정수, 문자열, 문자 등등) 를 맨 끝에 삽입.
2) v.pop_back();
벡터 v의 맨 끝 데이터를 삭제. 아래는 push_back, pop_back을 사용한 예제!
vector<int> v; v.push_back(10); v.push_back(20); v.pop_back();3) v.insert(데이터 위치, 데이터);
벡터 v의 원하는 위치(2)에 데이터(3)를 삽입하고 싶은 경우 v.insert(2,3) 으로 선언.
vector<int> v; v.push_back(10); v.push_back(20); v.push_back(30); v.insert(2,40);4) v.erase(iter)
반복자인 iter을 통해 원소 위치에 접근하여 벡터 v의 데이터를 삭제.
v.begin() 위치의 데이터를 삭제하고 싶은 경우 아래와 같이 사용.
vector<int> v; v.push_back(10);//0 v.push_back(20);//1 v.push_back(30);//2 auto iter = v.begin(); v.erase(iter); //v.erase(v.begin())
<3. 크기(사이즈) 함수>
1) v.size() : 현재 벡터 v의 원소 갯수(크기)를 리턴.
2) v.capacity() : 할당된 벡터의 원소 갯수(크기)를 리턴.
3) v.resize(n) , v.resize(n,10)
v.resize(n) : 벡터를 원래 크기에서 N 크기로 변경.
v.resize(n,10) : 벡터를 크기 N으로 변경하며 데이터를 10으로 초기화.
4) v.empty() 벡터 v가 비어있는 지 확인. 현재 비어있는 경우 True 를 반환하고 비어있지 않을 경우 False를 리턴.
<4. for문, iterator로 접근하는 Vector>
1) for 문 : 인덱스 기반 원소 접근
다음과 같이 반복문을 선언하여 v[i] 형태로 원소를 접근할 수 있음.
vector<int> v; v.push_back(10); v.push_back(20); v.push_back(30); v.push_back(40); for(int i=0;i<v.size();i++){ cout << v[i] << endl; }출력 결과
벡터에 데이터를 삽입한 순서대로 10 20 30 40 이 출력되는 모습을 볼 수 있음.
10 20 30 402) Iterator 을 통한 원소 접근
-
범위 기반 반복문을 통해 벡터 v 원소를 출력하기
-
iterator 를 통해 v.begin() 부터 v.end() 까지 원소 출력하기
vector<int> v; v.push_back(10); v.push_back(20); v.push_back(30); v.push_back(40); for (auto iter : v) { cout << iter << endl; } for (auto iter = v.begin(); iter < v.end() ; iter++ ) { cout << *iter << endl; }출력 결과
벡터에 데이터를 삽입한 순서대로 10 20 30 40 이 출력되는 모습을 볼 수 있음.
10 20 30 40 10 20 30 403) 벡터가 비어있을 때까지 벡터 끝의 원소 출력
vector<int> v; v.push_back(10); v.push_back(20); v.push_back(30); v.push_back(40); while (!v.empty()) { cout << v.back() << endl; v.pop_back(); }출력 결과
벡터에 데이터를 삽입한 순서와 반대로 40 30 20 10 이 출력되는 모습을 볼 수 있음.
40 30 20 10
-
- C++ STL
stack이란
-
대표적인 LIFO구조. 젤 마지막에 넣은 데이터가 제일 처음 빠져나옴. 강화할 때 강화 실패하면 직전 단계로 돌아가는 느낌.
stack의 선언 방법
-
#include 헤더파일을 포함해야 함.
-
stack<data_type>name; 으로 선언함.
#include<stack> stack<int>stack;
stack 멤버함수
1) 스택에 데이터 추가하기
스택이름.push(데이터) 형태로 데이터를 추가.
stack.push(element)2) 스택에 데이터 삭제하기
스택이름.pop(데이터) 형태로 스택의 top 데이터를 삭제.
stack.pop()3) 스택의 제일 위(탑, top) 데이터 반환
스택이름.top() 형태로 제일 최상위 데이터를 반환.
stack.top()4) 스택의 사이즈 반환
스택이름. size() 형태로 스택의 현재 사이즈를 반환.
stack.size()5) 스택이 비어있는 지 확인
스택이름.empty() 형태로 스택이 비어있는 지 확인.
stack.empty()6) 스택 SWAP : 두 스택의 내용 바꾸기
스택1과 스택2 두 스택의 내용을 바꾸고 싶은 경우, 내장된 swap 함수를 사용.
swap(스택1 이름, 스택2 이름) 형태로 두 스택의 내용을 바꿈.
swap(stack1 , stack2)
-
- C++ STL
-
후기
-
벡터 함수 중 push_back() 말고 pop_back()도 있다는 아주 중요하고도 당연한..! 개념을 알게 됨. (stl에 대해 정리해야 겠다고 느낌. 문제에 쓴 stl부터 천천히 정리하자.)
-
pop함수를 알기 전까지 erase함수를 통해 구현하고 있었음. 이 함수는 마지막 원소가 아니라 내가 지정한 인덱스를 지울수 있어서 유용함. but 간단한 연산에 사용하기 까다로웠음. (인자에 begin()이나end()를 써서 연산해야 됨) →erase함수를 빈번한게 사용해야되는 경우는 애초부터 자료형을 연결리스트 형태로 구성하는게 좋음.
-
분명 세운 식은 맞는 것 같은데 자꾸 실행하면서 오류가 나서 이유를 생각해봄. 나랑 비슷한 코드였는데 잘 실행되는 사람의 코드와 내 코드를 비교함.
- 함수에 괄호를 안 붙이는 실수를 함. ^^;;;;;;z
- i사용한 for문에서 원래는 가감식으로 짰었는데 증감식으로 짰을 때 내가 짰던 알고리즘이 정상적으로 작동했음. 즉 반대로 짰던것임. 이유는?
- 방금 깨달은건데 2차원배열 board의 구성을 착각하고 있었음. 당연히 아래→위 순서로 인덱스가 커지겠거니 하고 마음대로 추측하고 있었음. 그런데 주어진 배열을 생각해보니 위→아래 순서로 인덱스가 커짐. 왜냐하면 주어지는 board배열에 0인 원소가 위에서부터 있음. 이래서 확신하고 작성한 코드를 몇시간동안 붙잡고 있었던 것.
- 이런 기본적인 실수 안하도록 배열의 기본부터 탄탄히 다지도록 하자!
-
