house_price.csv
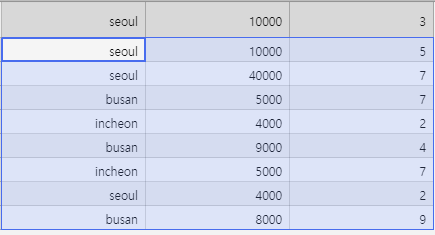
가격대별 평균 갯수 구하기( 도시 무시 해도 될듯 ? )
서울 1만원짜리 3개, 1행
서울 1만원짜리 5개, 2행
-> 1만원짜리 평균 4개
서울 4만원짜리 7개, 3행
-> 4만원짜리 평균 7개
인천 4천원자리 2개, 서울 4천원짜리 2개, 8행
-> 4천원짜리 평균 2개
import pyspark
sc = pyspark.SparkContext.getOrCreate()
test_file = "file:///home/jovyan/work/sample/house_price.csv"
lines = sc.textFile(test_file)
def parse_line(line: str):
city, price, count = line.split(',')
return (int(price), int(count))
lines = sc.textFile(test_file)
price_count = lines.map(parse_line)
# [(10000, 3), (10000, 5), (40000, 7), (5000, 7), (4000, 2), (9000, 4), (5000, 7), (4000, 2), (8000, 9)]
sum_of_count = price_count.mapValues(lambda count: (count, 1))\
.reduceByKey(lambda a, b: (int(a[0]) + int(b[0]), int(a[1]) + int(b[1])))
# ('10000', (3, 1)), ('10000', (5, 1)) ...
# [('10000', (8, 2)), ('4000', (4, 2)), ('9000', ('4', 1)), ('8000', ('9', 1)), ('40000', ('7', 1)), ('5000', (14, 2))]
avg_by_count = sum_of_count.mapValues(lambda total_count: int(total_count[0]) / total_count[1])
results = avg_by_count.collect()
print(results)

다소Good한 데이터 엔지니어