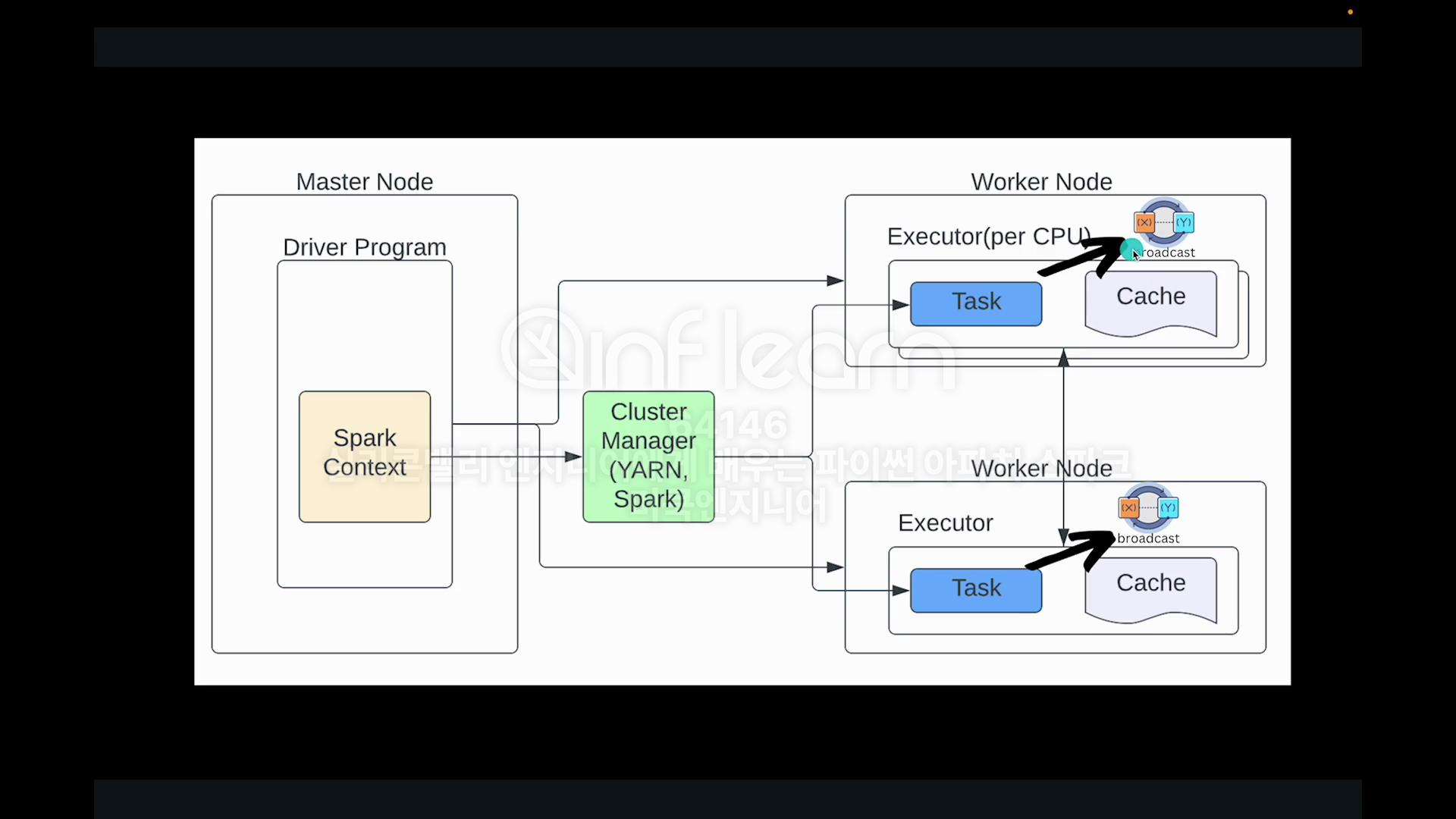
Broadcast 란 ?
PySpark에서 broadcast 변수는 클러스터의 모든 노드에 캐시되어 작업(task)에서 효율적으로 접근할 수 있는 읽기 전용 변수입니다. 큰 데이터셋을 여러 작업에서 공유해야 할 때 유용하게 사용됩니다.
broadcast 변수의 장점:
성능 향상: 큰 데이터셋을 네트워크를 통해 반복적으로 전송하는 대신, 각 노드에 한 번만 복사하여 캐싱하므로 네트워크 오버헤드를 줄이고 작업 속도를 향상시킵니다.
메모리 효율성: broadcast 변수는 모든 노드에서 공유되므로 각 노드의 메모리 사용량을 줄일 수 있습니다.
broadcast 변수의 단점:
읽기 전용: broadcast 변수는 변경할 수 없습니다.
크기 제한: 너무 큰 데이터셋을 broadcast 변수로 사용하면 메모리 부족 문제가 발생할 수 있습니다.
예제, broadcast join
# 참고: df 형변환
dat = dat.withColumn("id2", f.col("id2").cast("String"))
dat.printSchema()
meta = {
"1100":"천재",
"3801":"바보",
"2030":"보통",
"3021":"준수",
"9382":"비범"
}
#step1 등록
meta_dict = spark.sparkContext.broadcast(meta)
#step2 함수 생성
def get_name(id):
return meta_dict.value[id]
#step3 udf 등록
meta_udf = f.udf(get_name)
#step4 사용
dat2 = dat.withColumn("name", meta_udf(f.col("id2")))
단일 테스트 불가 ? 불가 ...
PySpark UDF는 DataFrame에 적용하기 전에 단독으로 실행하여 결과를 확인하는 것이 불가능합니다. UDF는 Spark 실행 환경에서 DataFrame의 각 행에 대해 분산 처리되도록 설계되었기 때문에, Spark 컨텍스트 외부에서 직접 호출할 수 없습니다.
meta = {
1100: "engineer",
2030: "developer",
3801: "painter",
3021: "chemistry teacher",
9382: "priest"
}
meta_dict = spark.sparkContext.broadcast(meta)
def get_name(id):
return meta_dict.value[id]
meta_udf = f.udf(get_name)
meta_udf(1100)바로 불러 올 순 없을까 ?
PySpark DataFrame에서 직접 Python 딕셔너리를 사용하여 withColumn 연산을 수행할 수는 없습니다.이유:
분산 처리 환경: PySpark는 분산 처리 환경에서 작동하며, DataFrame은 여러 노드에 분산되어 저장될 수 있습니다. Python 딕셔너리는 단일 노드에서만 접근 가능하므로 모든 노드에서 일관된 결과를 보장할 수 없습니다.
데이터 타입 불일치: PySpark DataFrame의 열은 특정 데이터 타입을 가지고 있지만, Python 딕셔너리는 다양한 타입의 값을 포함할 수 있습니다. 이러한 데이터 타입 불일치는 예상치 못한 동작이나 오류를 유발할 수 있습니다.
참고
실리콘 엔지니어에게 배우는 파이썬 아파치 스파크
