
실무를 하다보면 "동시에 행동한다" 라는 말이 굉장히 어렵게 느껴질 떄가 있다. 이럴 때 어떤 생각을 가지고 어떤 관점으로 접근해야 하는지 이야기 해보려고 한다.
TL;DR "데이터가 사는 곳에서 잠가야(Lock) 한다."
동시에 일어난다는 것은...
카페에서 아이스 아메리카노 한 잔이 남았다.
두 명이 동시에 주문 버튼을 누르면 어떻게 될까?
일상에서는 별일 아니다. 점원이 "죄송합니다, 한 잔 남았는데요"라고 말하면 된다.
그런데 서버에서는 점원이 없다. 코드가 스스로 판단해야 한다.
결국 내가 판단해야 한다는 것인데, 어떻게 하는게 좋을까? 이번 기회에 동시성에 대하여 최대한 많이 생각해보려고 한다.
시간 → T1: 재고 읽기(1) → 주문 가능 판단 → 차감 → 저장(0)
T2: 재고 읽기(1) → 주문 가능 판단 → 차감 → 저장(0) ← 두 명 다 성공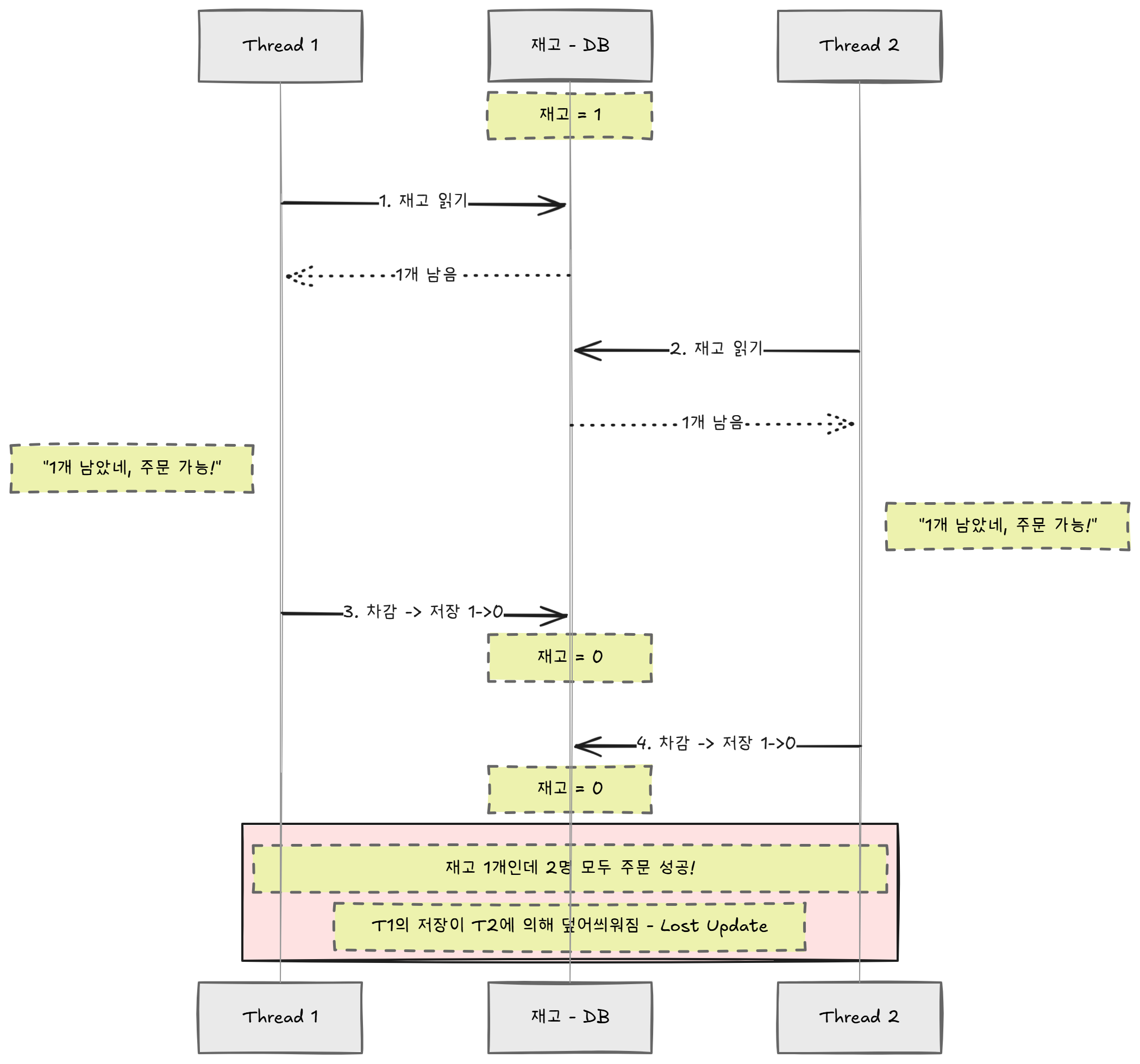
재고는 1개인데 2명이 주문에 성공했다. 이걸 Lost Update(갱신 손실) 문제라고 한다. "Lost"는 말 그대로 "잃어버린"이라는 뜻이다. T1이 저장한 변경이 T2에 의해 덮어씌워져서 사라진 것이다. 업데이트가 유실됐다.
"동시성 제어"라는 단어를 들으면 비관적 락, 낙관적 락, 분산 락 같은 용어가 쏟아진다. 근데 솔직히 이 용어들이 서로 어떻게 연결되는지, 왜 하나로 안 되고 여러 가지가 필요한 건지 감이 안 왔다.
그래서 가장 원초적인 코드부터 시작해서, "이걸로 되나?" → "안 되네" → "그러면 이건?" 을 반복하면서 직접 부딪혀 보기로 했다.
이 글은 네 개의 키워드를 축으로 전개된다:
| 키워드 | 질문 |
|---|---|
| read-modify-write | 동시성 문제는 어디서 시작되는가? |
| 상호 배제 (mutual exclusion) | "한 번에 하나"를 보장하면 해결되는가? |
| 생명주기 불일치 | Java 락과 DB 트랜잭션을 합치면 왜 깨지는가? |
| 같은 레이어에서 제어 | DB 데이터를 안전하게 다루려면 어떻게 해야 하는가? |
고민의 시작

Step 1. 정말 터지긴 하는 걸까?
read-modify-write
읽고(read), 바꾸고(modify), 쓴다(write). 이 세 단계가 분리되어 있는 모든 연산은 그 사이에 다른 스레드가 끼어들 수 있다. 동시성 문제의 대부분은 이 패턴에서 시작된다.
동시성 문제에 대해 읽으면 "여러 스레드가 동시에 접근하면 문제가 생긴다"고 한다. 머리로는 이해가 되는데, 직접 본 적은 없다. 정말 터지는지부터 확인해보고 싶었다.
재고를 나타내는 가장 단순한 클래스를 만들고, 100개의 스레드로 동시에 차감해봤다.
public class Stock {
private int quantity;
public void decrease() {
int current = this.quantity; // read
this.quantity = current - 1; // write
}
}결과: 재고 0. 문제가 안 생긴다.
"뭐야, 괜찮은데?" 싶었다.
왜 안 터졌는가 — 그리고 왜 그게 더 무서운가
quantity--는 자바 코드로는 한 줄이지만, CPU 입장에서는 세 단계다:
1. 메모리에서 값을 레지스터로 읽고 (LOAD)
2. 레지스터에서 1을 빼고 (SUB)
3. 레지스터의 값을 메모리에 쓴다 (STORE)
이 세 단계 사이에 다른 스레드가 끼어들면 문제가 생긴다. 하지만 이 연산이 너무 빨라서 (나노초 단위) 100개 스레드 정도로는 끼어들 틈이 거의 없다.
여기서 중요한 점이 있다: 앞서 TDD를 통해 경험해 보았듯이 "테스트에서 안 터진다"는 것은 "문제가 없다"는 뜻이 아니다. 경합 조건(Race Condition)은 확률적이다. 로컬에서 100번 돌려도 안 터질 수 있지만, 운영 서버에서 초당 수천 요청이 들어오면 그 "낮은 확률"이 매일 발생한다.
실제 서비스에서는 단순히 quantity--가 아니다. DB에서 값을 읽고, 비즈니스 검증을 하고, 다시 저장하는 과정이 있고, 이 과정에 수 밀리초에서 수십 밀리초의 시간이 걸린다. 이 시간 간격을 시뮬레이션하면 어떻게 될까?
public void decreaseWithDelay() {
int current = this.quantity; // read: DB에서 재고를 읽어온다
Thread.sleep(1); // DB I/O + 비즈니스 로직 시뮬레이션
this.quantity = current - 1; // write: 계산된 값을 다시 저장한다
}결과:
[단순 decrease] 최종 재고: 0 — 연산이 빨라서 경합이 안 일어남
[지연 decrease] 최종 재고: 99 — 100번 차감했는데 1번만 반영됨!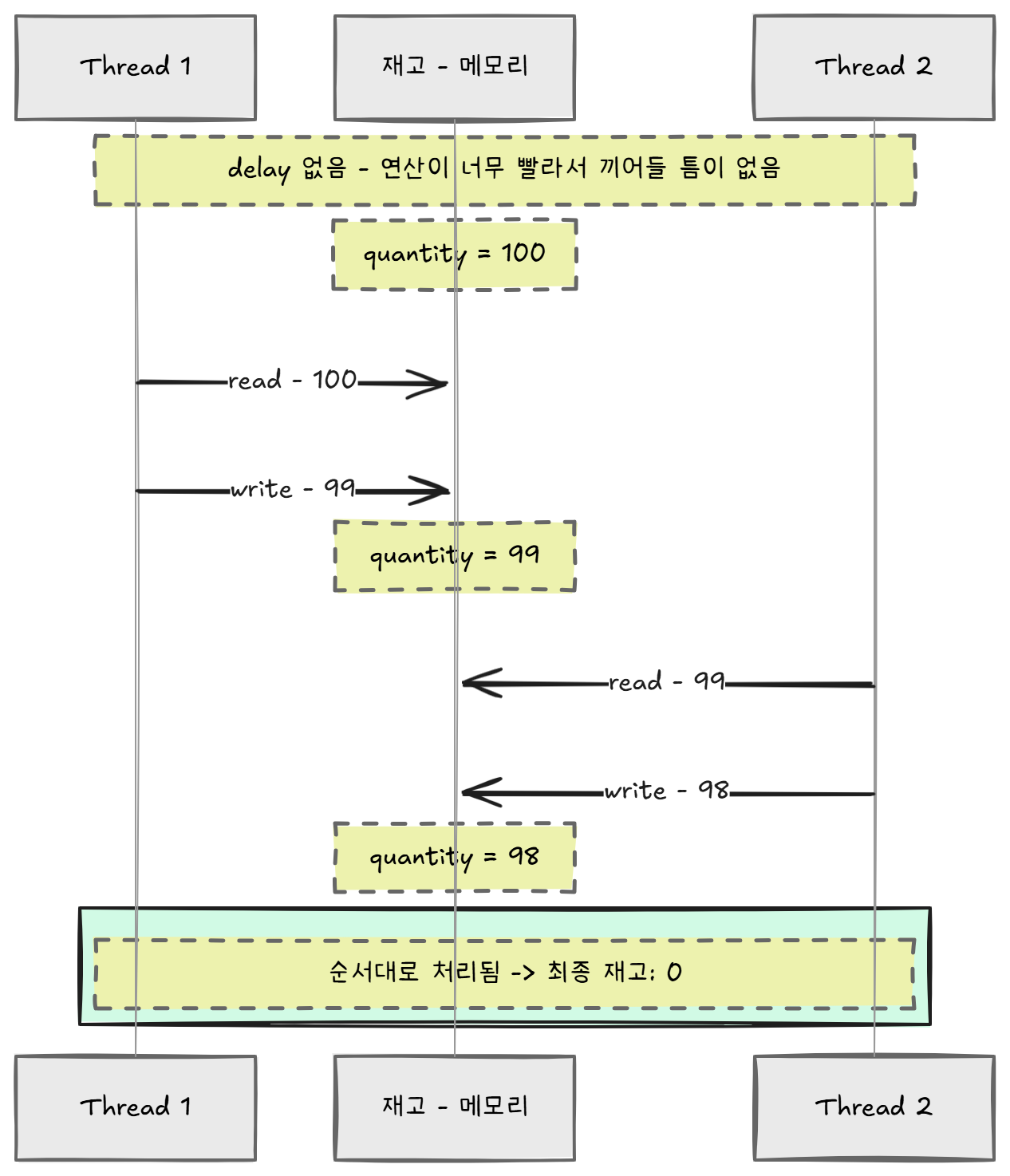
1밀리초. 고작 1ms의 간격으로 99건의 차감이 사라졌다.
왜 99건인지 뜯어보면 이렇다. 100개 스레드가 동시에 출발하면, 1ms의 sleep 동안 거의 모든 스레드가 current = 100을 읽는다. 그 다음 각자 100 - 1 = 99를 계산하고 저장한다. 100개의 스레드가 전부 99를 저장하니까, 최종 값은 99다. 마지막에 저장한 스레드 하나만 "반영"된 것처럼 보이는 거다.
이게 read-modify-write 패턴의 본질적 위험이다. 읽기와 쓰기가 분리된 모든 연산은 그 사이에 다른 스레드가 끼어들 수 있다. 문제가 실재한다는 걸 확인했으니, 이제 해결해야 한다.
Step 2. "한 번에 한 명만 들어오게 하면 되지 않나?"
핵심 키워드: 상호 배제 (mutual exclusion)
"Mutual"은 "서로의", "Exclusion"은 "배제". 서로를 배제한다 — 즉, 한 시점에 하나의 스레드만 임계 구간(critical section)에 존재할 수 있다는 원칙이다. read-modify-write를 쪼갤 수 없다면, 그 구간 자체에 한 명만 들어오게 하는 것이다.
문제의 원인은 명확하다. 여러 스레드가 동시에 read-write를 하니까 덮어쓰기가 발생한다. 그러면 한 번에 한 스레드만 실행하게 막으면 되지 않을까?
2-1. synchronized — "동기화하다"
"synchronize"는 "동기화하다, 시간을 맞추다"라는 뜻이다. 원래 "sync"는 "함께(syn) 시간(chronos)"이라는 그리스어 합성어다. 여러 스레드의 실행 시간을 맞춰서, 한 번에 하나만 실행되게 한다는 뜻이 이름에 들어 있다.
비유하자면 화장실 칸이 하나인데 사람이 여럿인 상황이다. 문에 잠금장치가 있어서 한 명이 들어가면 나올 때까지 나머지는 밖에서 대기한다.
그런데 이 잠금장치가 정확히 어떻게 작동하는 걸까?
Java의 모든 객체는 내부에 모니터(monitor)라는 것을 하나씩 가지고 있다. "Monitor"는 "감시자"라는 뜻이다. 이 감시자가 "지금 누가 들어와 있는지"를 추적한다. synchronized 블록에 진입하면 해당 객체의 모니터를 획득(acquire)하고, 블록이 끝나면 반납(release)한다. 모니터를 획득하지 못한 스레드는 BLOCKED 상태로 대기한다 — CPU를 사용하지 않고 OS 스케줄러에 의해 잠든다.
public class SynchronizedStockService {
private final Stock stock;
// 이 메서드에 synchronized를 붙이면,
// 이 객체(this)의 모니터를 획득해야만 진입할 수 있다.
public synchronized void decrease() {
stock.decreaseWithDelay();
}
}결과:
[synchronized] 최종 재고: 0 ✅
[synchronized 성능] 소요 시간: 217ms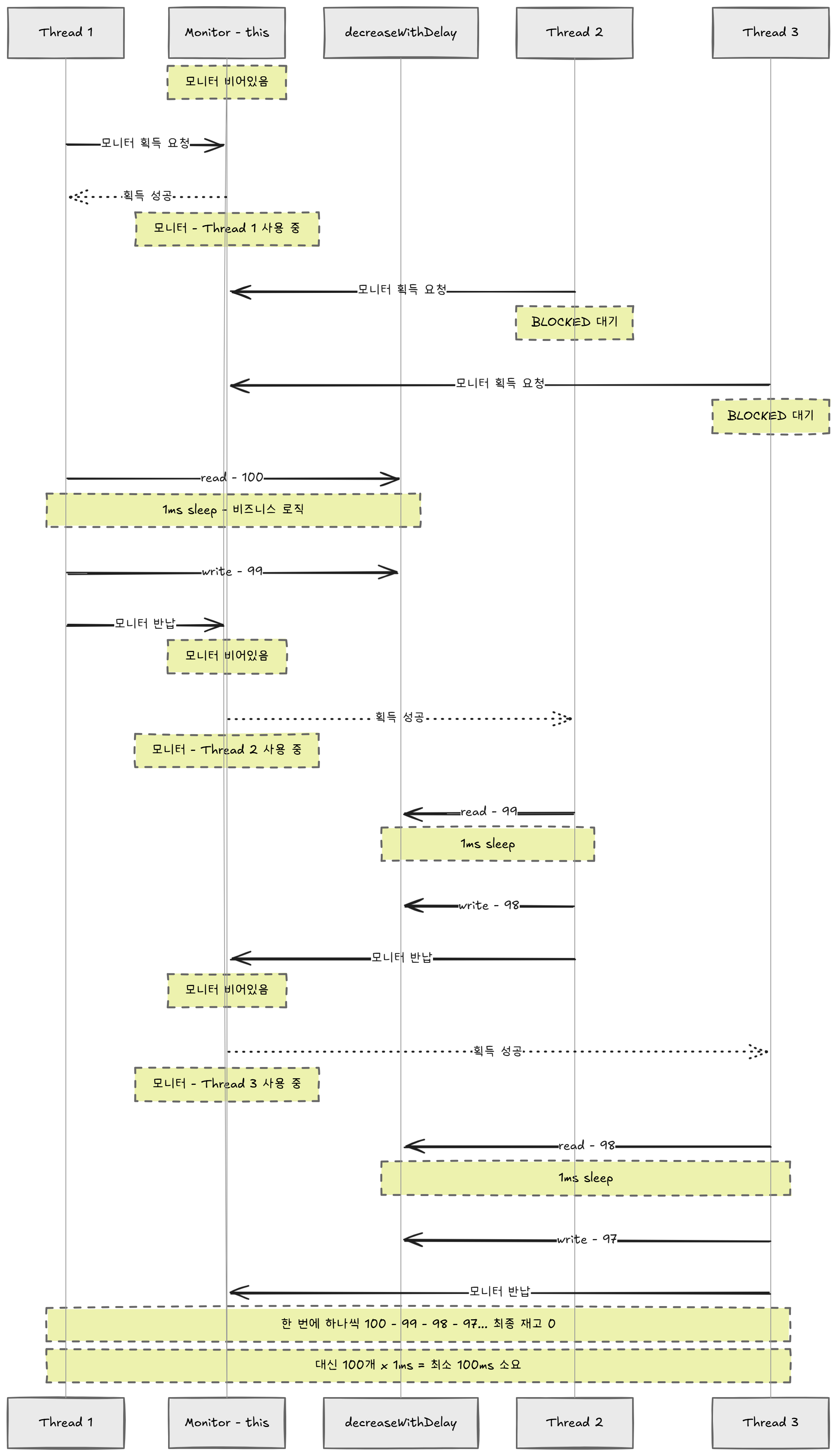
해결됐다! ...근데 217ms가 걸렸다. 100개의 요청이 한 줄로 서서 순차 처리되니까 (1ms × 100 + 오버헤드) 당연한 결과다.
여기서 두 가지 생각이 들었다.
첫 번째: "이렇게 느려도 괜찮은가? 기다리다 포기할 수는 없나?"
synchronized는 무한 대기다. 모니터를 획득할 때까지 영원히 기다린다. "5초 안에 안 되면 포기"같은 옵션이 없다. 앞에 100명이 서 있어도, 1000명이 서 있어도 무조건 기다린다.
실제 서비스에서 이건 위험할 수 있다. 뒤에 선 요청들이 스레드 풀을 점유한 채 대기하면, 다른 API 요청까지 처리 못하게 된다. "재고 차감 API 하나 때문에 서버 전체가 먹통"이 될 수 있다.
ReentrantLock의 tryLock이 이 문제를 해결한다. "Lock"은 "자물쇠", "Re-entrant"는 "다시 들어갈 수 있는"이라는 뜻이다. 이름에서 알 수 있듯이 같은 스레드가 이미 잡은 락을 다시 잡을 수 있다는 특성이 있지만 (참고로 synchronized도 그렇다), 핵심 차이는 "기다리되, 타임아웃을 걸 수 있다"는 점이다.
// tryLock — "try"라는 이름 자체가 "시도하다"라는 뜻.
// 성공하면 true, 실패하면 false를 반환한다. 예외를 던지지 않는다.
if (!lock.tryLock(5, TimeUnit.MILLISECONDS)) {
return false; // 5ms 안에 못 잡으면 포기하고 다른 처리 가능
}
try {
stock.decreaseWithDelay();
return true;
} finally {
lock.unlock(); // ⚠️ 반드시 finally에서 해제! 안 그러면 영원히 잠김
}[tryLock 5ms] 성공: 7건, 타임아웃: 93건
→ synchronized는 무한 대기하지만, tryLock은 '포기'할 수 있다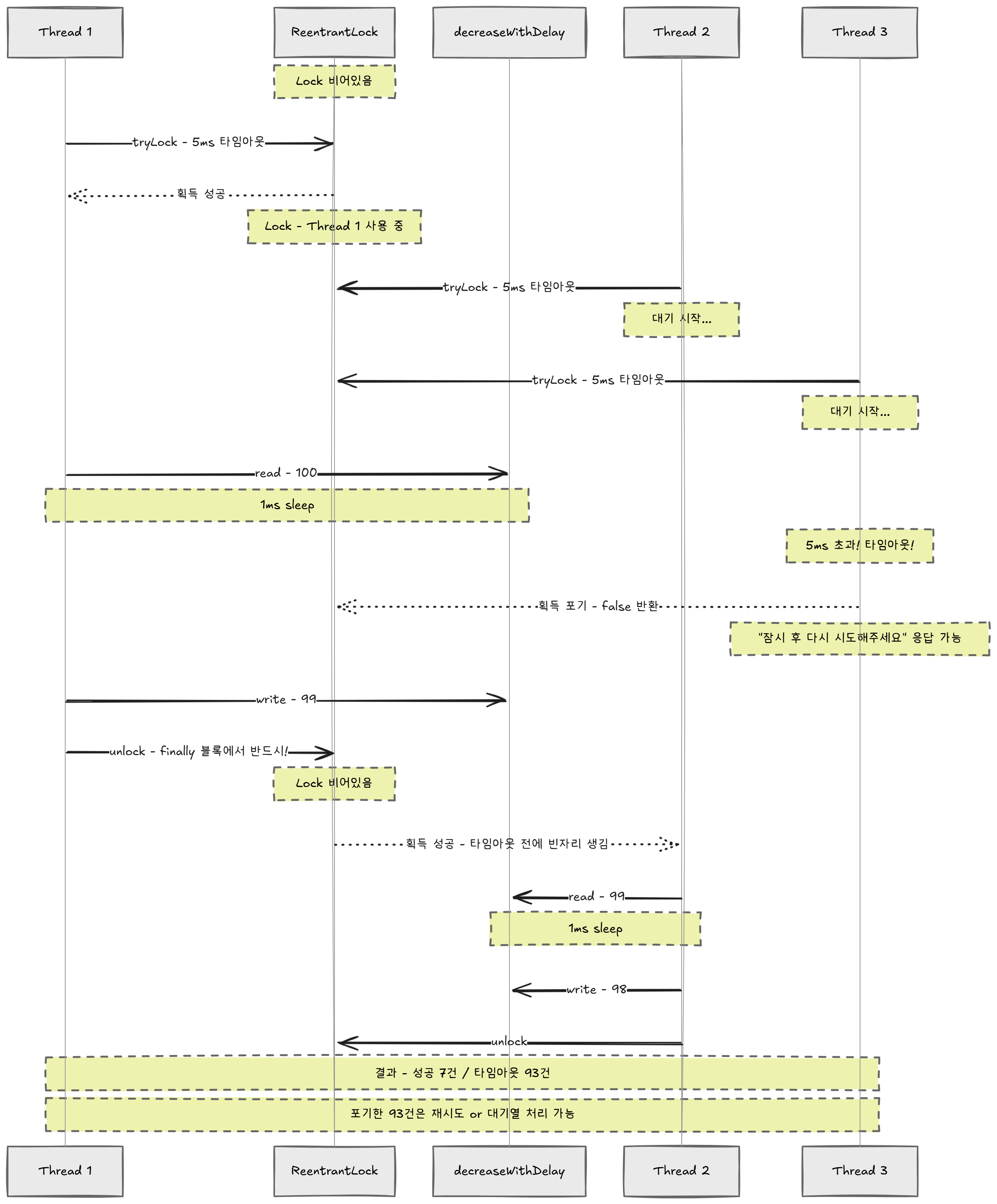
100건 중 7건만 성공하고 93건은 포기했다. 이 93건에 대해 "잠시 후 다시 시도해주세요"라고 응답하거나, 대기열에 넣는 등의 처리가 가능하다.
여기서 잠깐 주목할 점이 있다. lock.unlock()을 반드시 finally 블록에 넣어야 한다. synchronized는 블록이 끝나면 자동으로 모니터를 반납하지만, ReentrantLock은 명시적으로 unlock()을 호출해야 한다. 만약 예외가 터져서 unlock()을 건너뛰면? 그 락은 영원히 잠긴 채로 남는다. 다른 모든 스레드가 영원히 대기하게 된다. 이것이 "수동 잠금장치"의 대가다.
두 번째: "단순히 숫자 하나를 바꾸는 건데, 꼭 잠가야 하나?"
여기서 근본적인 질문이 떠올랐다. read-modify-write가 문제라면, 이 세 단계를 쪼갤 수 없는 하나의 연산으로 만들면 잠글 필요 자체가 없지 않을까?
"Atomic"은 그리스어 "atomos"에서 왔다. "a(not) + tomos(cut)" = "더 이상 쪼갤 수 없는"이라는 뜻이다. 물리학에서 "원자(atom)"가 "더 이상 나눌 수 없는 것"이라는 의미인 것과 같다. (물론 물리학에서는 원자도 쪼갤 수 있다는 걸 나중에 알게 됐지만, 프로그래밍에서의 atomic 연산은 진짜로 쪼갤 수 없다.)
AtomicInteger는 CAS(Compare-And-Swap)라는 CPU 레벨 명령어를 사용한다. CAS를 풀어 쓰면: "비교(Compare)하고 교환(Swap)한다." 구체적으로:
- "내가 마지막으로 본 값이 5였다" (expected = 5)
- "메모리에 있는 현재 값을 확인한다" (actual = ?)
- actual == expected이면 → 새 값(4)으로 교체 (이 비교+교체가 CPU 레벨에서 하나의 명령어로 실행된다)
- actual ≠ expected이면 → 누가 이미 바꿨다는 뜻 → 실패 → 다시 읽고 재시도
핵심은 3번이다. "비교"와 "교체"가 CPU의 단일 명령어(cmpxchg)로 실행되기 때문에, 중간에 다른 스레드가 끼어들 여지가 물리적으로 없다.
public class AtomicStock {
private final AtomicInteger quantity;
public void decrease() {
quantity.decrementAndGet();
// 내부적으로:
// do {
// int expected = current값;
// int newValue = expected - 1;
// } while (!CAS(expected, newValue)); // 실패하면 무한 재시도
}
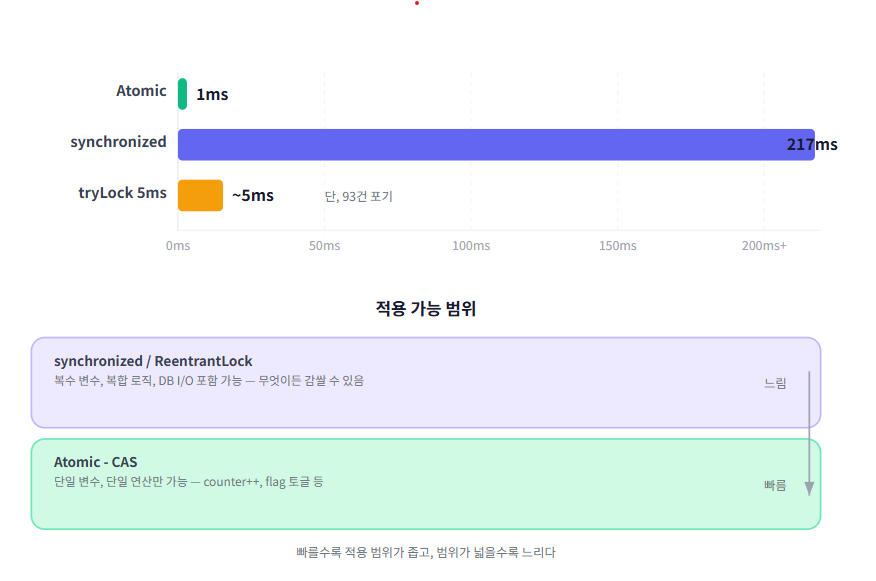
}[성능 비교]
Atomic: 1ms (락 없음, CAS)
synchronized: 209ms (모니터 락, 순차 실행)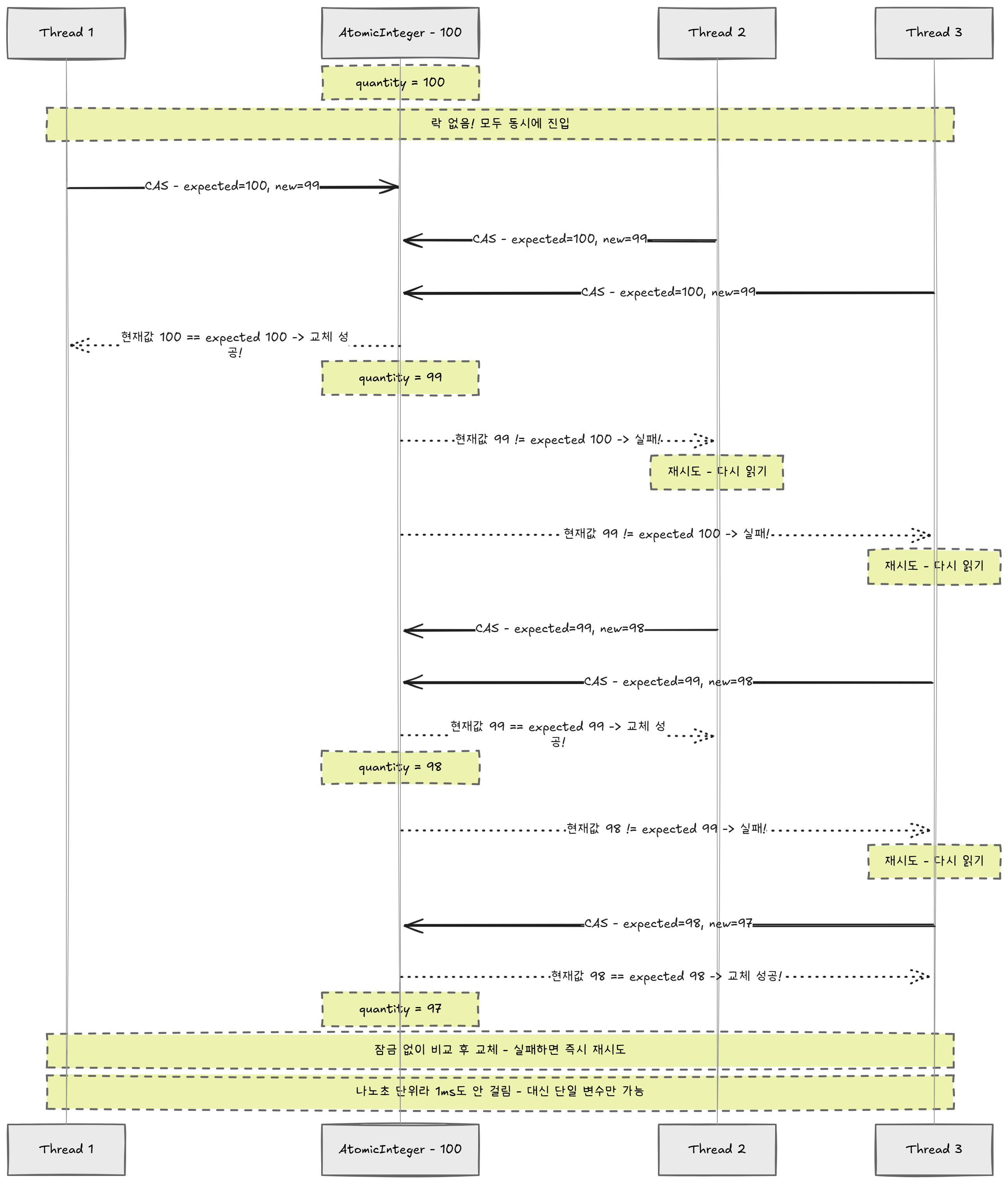
200배 빠르다. 잠그지 않으니까 대기 시간이 없다.
하지만 여기서 냉정하게 봐야 할 것이 있다. 이 테스트에서 Atomic이 빠른 건 delay가 없기 때문이다. AtomicInteger.decrementAndGet()은 메모리 연산만 하므로 나노초 단위로 끝난다. 반면 synchronized 테스트는 decreaseWithDelay()를 감싸므로 1ms × 100 = 최소 100ms가 걸린다. 공정한 비교가 아니다.
그보다 중요한 건 적용 범위의 차이다. AtomicInteger는 단일 변수에 대한 단일 연산에만 쓸 수 있다. 실제 서비스에서 "재고 확인 → 비즈니스 검증 → 차감 → 주문 생성"을 하나의 원자적 연산으로 만들 수는 없다. 또한 경합이 극심하면(수백 스레드가 동시에 같은 값을 바꾸려 하면) CAS 재시도가 반복되면서 오히려 성능이 나빠질 수 있다. 이걸 "CAS 스핀(spin)" 문제라고 한다.
정리하면:
| synchronized | ReentrantLock | Atomic (CAS) | |
|---|---|---|---|
| 잠그는 방식 | 암묵적 (JVM 모니터) | 명시적 (lock/unlock) | 안 잠금 (비교 후 교체) |
| 대기 방식 | 무한 대기 (BLOCKED) | 타임아웃 가능 (tryLock) | 재시도 루프 (스핀) |
| 해제 책임 | 자동 (블록 종료) | 수동 (finally에서 unlock) | 없음 |
| 적합한 경우 | 단순 임계 구간 | 세밀한 제어 필요 시 | 단일 변수 연산 |
| 위험 | 무한 대기로 인한 스레드 풀 고갈 | unlock 누락 시 영구 잠금 | 경합 심하면 스핀 폭주 |
잠깐 — "이건 잠그는 문제가 아닌데?"
여기까지 하고 나니, 다른 종류의 동시성 문제도 떠올랐다. 재고 차감은 "값을 변경"하는 UPDATE 문제다. 그런데 쿠폰 중복 발급은? "같은 유저가 같은 쿠폰을 두 번 받으면 안 된다"는 건 INSERT 중복 문제다.
이 두 문제는 본질이 다르다:
- UPDATE 문제: 같은 값을 여러 명이 동시에 바꾸려고 한다 → 락으로 순서를 보장해야
- INSERT 문제: 같은 데이터를 여러 명이 동시에 넣으려고 한다 → 중복 자체를 차단하면 됨
INSERT 중복이라면 락을 안 걸어도 된다. DB의 유니크 제약(Unique Constraint)이 원자적으로 중복을 차단해준다. "Constraint"는 "제약, 제한"이라는 뜻이다. DB 엔진이 INSERT를 실행할 때 유니크 조건을 원자적으로 검사하므로, 서버가 몇 대든 상관없이 중복이 차단된다.
@Table(uniqueConstraints = @UniqueConstraint(columnNames = {"coupon_id", "user_id"}))
public class CouponIssueEntity { ... }[유니크 제약] 100번 동시 발급 요청 → 성공: 1건, 중복 차단: 99건
→ 락 없이도 DB가 원자적으로 차단문제의 성격을 먼저 판별해야 한다. "같은 행위의 중복 방지"인가(→ 유니크 제약), "공유 자원의 값 변경"인가(→ 락). 도구를 고르기 전에 문제를 정확히 정의하는 게 먼저다.
Step 3. "이걸로 끝 아닌가?" — 아니었다
핵심 키워드: 생명주기 불일치 (lifecycle mismatch)
Java 락은 코드 블록에 종속되고, DB 트랜잭션은 프록시 호출에 종속된다. 두 메커니즘이 끝나는 시점이 다르면, 그 사이에 틈이 생긴다. 이 틈이 동시성 버그의 원인이 된다.
Step 2에서 synchronized로 문제를 해결했다. 로컬에서 테스트도 통과한다. "이걸로 충분하지 않나?" 라고 생각했다.
그런데 실제 서비스를 떠올리면 한 가지 전제가 깨진다. 서버가 1대가 아니라는 것이다.
"서버가 2대면 JVM이 다르니까 synchronized가 안 통한다" — 이건 많이들 아는 얘기다. 모니터는 JVM 내부에 있으므로 다른 JVM의 모니터는 서로 보이지 않는다. 당연하다.
근데 공부하다보니 서버가 1대인 상황에서도 synchronized가 안 통하는 경우를 직접 구현해보았는데 충격적이였다.
synchronized + @Transactional — 이 조합이 함정이다
Spring에서 DB를 사용하면 @Transactional을 붙인다. 그리고 동시성 제어를 위해 synchronized를 붙인다. 둘 다 붙이면 완벽할 것 같다.
@Service
public class DbStockService {
@Transactional
public synchronized void decrease(Long id) {
StockEntity stock = stockEntityRepository.findById(id).orElseThrow();
stock.decrease();
}
}직관적으로는 맞아 보인다. "트랜잭션도 걸고, 동시성도 제어하고, 완벽하잖아." 근데 결과를 보면:
[synchronized + @Transactional] 최종 재고: 49 (기대값: 0)
→ 100번 차감했는데 51건이 사라졌다!왜?
프록시(Proxy)가 뭔데?
이걸 이해하려면 "프록시"라는 단어부터 짚어야 한다. "Proxy"는 "대리인"이라는 뜻이다. Spring의 @Transactional은 원본 객체를 직접 호출하지 않고, 대리인(프록시)이 대신 호출하는 구조다.
왜 이렇게 만들었을까? @Transactional이 하는 일은 "메서드 실행 전에 트랜잭션을 시작하고, 메서드가 성공하면 커밋하고, 실패하면 롤백한다"는 것이다. 이 부가 기능을 비즈니스 코드와 분리하기 위해 프록시 패턴을 사용한다. 코드를 수정하지 않고도 트랜잭션을 적용할 수 있으니 편리하다.
하지만 이 설계에는 구조적 제약이 따른다. 프록시가 감싸는 범위와 synchronized가 잠그는 범위가 다르다:
실제 호출 순서:
호출자 → [Proxy: 트랜잭션 시작] → [synchronized: lock 획득] → 비즈니스 로직 → [synchronized: lock 반납] → [Proxy: 트랜잭션 커밋]
↑ 갭! ↑
lock은 풀렸는데 커밋은 여기서풀어 쓰면:
Thread 1:
[Spring Proxy: 트랜잭션 시작]
→ [synchronized lock 획득]
→ 재고 읽기(100) → 차감(99) → dirty checking으로 UPDATE 예약
→ [synchronized lock 반납] ← 여기서 Thread 2가 lock을 획득할 수 있다!
[Spring Proxy: 트랜잭션 커밋] ← UPDATE가 실제로 DB에 반영되는 시점
Thread 2:
[Spring Proxy: 트랜잭션 시작]
→ [synchronized lock 획득] ← Thread 1이 lock을 반납했으니 진입 가능
→ 재고 읽기(???) ← Thread 1의 커밋 전이므로 100을 읽음!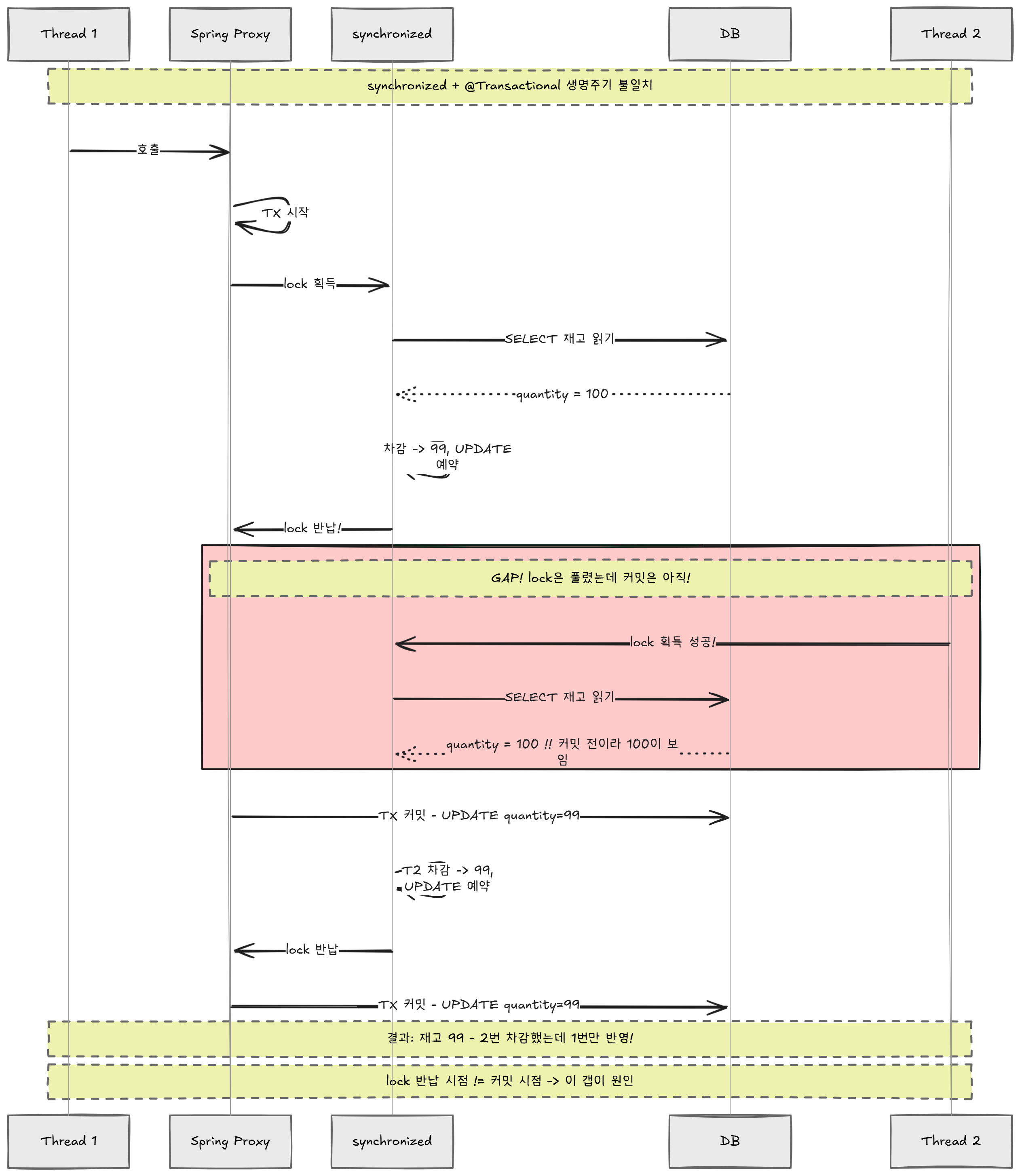
결국 synchronized는 메서드 본문에 걸리고, 프록시는 메서드 바깥에서 트랜잭션을 관리 한다는 것이다. lock을 반납하는 시점과 트랜잭션이 커밋되는 시점 사이에 갭이 존재한다. 이 찰나에 다른 스레드가 들어오면, 아직 커밋되지 않은 데이터(100)를 읽는다.
"그러면 이건 Spring의 설계 실수인가?"
그럴리가!! 이건 트레이드오프다.
Spring이 트랜잭션을 프록시 안쪽에서 시작하고 바깥쪽에서 커밋하는 이유는, "비즈니스 로직이 트랜잭션 관리 코드를 알 필요가 없다"는 관심사 분리 원칙 때문이다. 트랜잭션 시작/커밋/롤백을 프록시에 위임함으로써 비즈니스 코드는 순수하게 유지된다.
이 설계가 의미하는 것은: @Transactional 메서드 안에서 synchronized를 사용하는 것 자체가 잘못된 조합이라는 것이다. 두 메커니즘의 생명주기가 다르다. Java 락은 "코드 블록"의 생명주기를 따르고, DB 트랜잭션은 "프록시 호출"의 생명주기를 따른다. 이 불일치를 억지로 합치다보면 지금 같은 결과가 나와버린다.
격리 수준(Isolation Level)과의 관계
여기서 빼먹으면 섭섭한 포인트가 있다. Thread 2가 "커밋 전 데이터(100)를 읽는다"고 했는데, 이건 DB의 격리 수준(Isolation Level)에 따라 달라진다.
"Isolation"은 "격리, 분리"라는 뜻이다. 트랜잭션 간에 어디까지 서로를 격리시킬 것인가를 정하는 설정이다.
대부분의 DB 기본 설정은 READ COMMITTED다. 이름 그대로 "커밋된 것만 읽는다"는 뜻이다. Thread 1이 99로 바꿔놨어도 아직 커밋하지 않았으므로, Thread 2에게는 이전에 커밋된 값(100)이 보인다.
만약 격리 수준을 REPEATABLE READ(반복 가능한 읽기)로 올리면? MySQL/MariaDB의 기본 설정이 이건데, 이 경우에도 Lost Update 문제는 막지 못한다. REPEATABLE READ는 "내가 트랜잭션 시작 시점에 본 스냅샷을 계속 본다"는 것이지, 다른 트랜잭션의 UPDATE를 막는 것이 아니기 때문이다.
이것이 의미하는 바는 크다: Java 레벨의 동시성 제어와 DB 트랜잭션은 서로 다른 레이어에서 작동한다. synchronized는 "이 코드 블록에 한 번에 하나"를 보장하지만, DB 커밋 타이밍까지는 제어하지 못한다. 격리 수준을 올려도 Lost Update는 막지 못한다. 합쳐서 쓰면 두 보장이 어긋나면서 의도대로 동작하지 않는다.
그러면 어떻게 해야 하는가? DB 데이터를 다루는 동시성 문제는 DB 레벨에서 제어해야 한다.
Step 4. "DB가 직접 잠그게 하자"
같은 레이어에서 제어하자
DB 데이터의 동시성 문제는 DB 레벨에서 해결해야 한다. 데이터가 사는 곳과 락이 사는 곳이 같아야, 생명주기가 일치하고 틈이 사라진다.
Java 락이 DB 트랜잭션과 어긋나는 것이 문제라면, 아예 DB 자체가 제공하는 락을 쓰면 된다. DB 락은 트랜잭션과 생명주기가 같으므로, "lock 반납과 커밋 사이의 갭" 문제가 구조적으로 발생하지 않는다.
DB 레벨의 동시성 제어에는 두 가지 철학이 있다. 재미있는 건, 이 두 철학이 이름에 그대로 드러난다는 것이다.
4-1. 비관적 락(Pessimistic Lock) — "충돌 날 거야. 미리 잠가"
"Pessimistic"은 "비관적인"이라는 뜻이다. 라틴어 "pessimus(최악의)"에서 왔다. "최악의 상황(충돌)이 일어날 거라고 가정"하고, 미리 잠가버린다.
도서관에서 책을 빌리는 게 아니라 열람실에서 독점 사용하는 것이다. "이 책 내가 보는 동안 다른 사람한테 주지 마세요." 다른 사람은 내가 반납할 때까지 그 책을 볼 수도 없다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT s FROM StockEntity s WHERE s.id = :id")
Optional<StockEntity> findByIdWithPessimisticLock(@Param("id") Long id);
// 실행되는 SQL: SELECT * FROM stock WHERE id = 1 FOR UPDATE;FOR UPDATE가 핵심이다. 이 두 단어는 "업데이트를 위해(잠근다)"라는 뜻이다. 이 키워드가 붙은 SELECT는 단순히 읽기만 하는 게 아니라, "나 이 행을 곧 수정할 거니까 다른 트랜잭션은 건드리지 마"라는 의사 표시다. 해당 행에 대해 다른 트랜잭션의 FOR UPDATE / UPDATE / DELETE가 블로킹된다.
[MariaDB 콘솔 테스트]
비관적 락(FOR UPDATE)의 동작 확인:
터미널 1:
START TRANSACTION;
SELECT * FROM stock WHERE id = 1 FOR UPDATE; -- 행을 잠금.
결과: quantity = 100 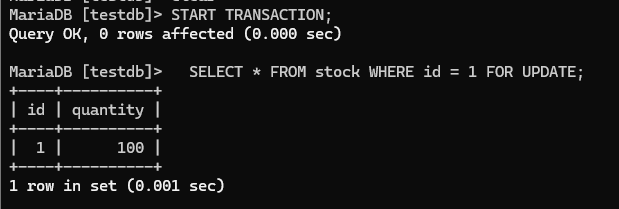
터미널 2:
START TRANSACTION;
SELECT * FROM stock WHERE id = 1 FOR UPDATE; -- 대기!
-- 터미널 1이 커밋하거나 롤백할 때까지 여기서 블로킹됨 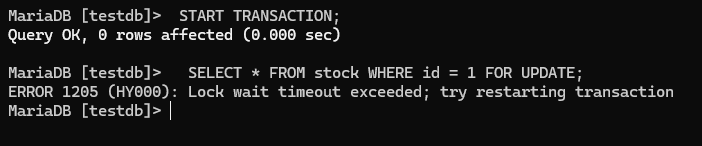
터미널 1:
UPDATE stock SET quantity = 99 WHERE id = 1;
COMMIT; -- 이 순간 터미널 2의 SELECT가 실행됨! 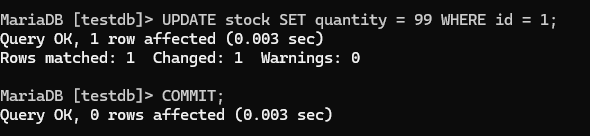
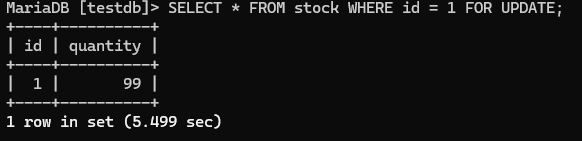
터미널 2:
-- 이제서야 결과가 나옴: quantity = 99 (터미널 1이 커밋한 값!)
UPDATE stock SET quantity = 98 WHERE id = 1;
COMMIT;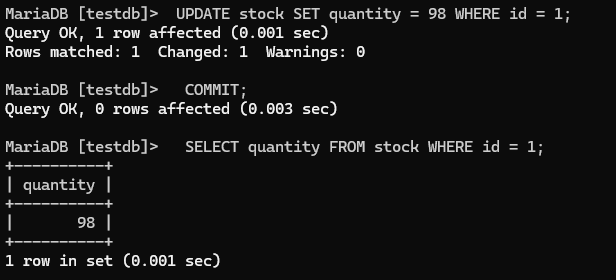
최종 확인:
SELECT quantity FROM stock WHERE id = 1; -- 결과: 98
-- 100 - 1 - 1 = 98. 정확!
추가 실험1) — FOR UPDATE 없이 같은 순서로 하면?:
→ 터미널 2의 SELECT가 대기 없이 바로 실행되고, 100을 읽는다
→ 결과: 99. 1건 손실.
추가 실험2) — 일반 SELECT는 FOR UPDATE와 관계없이 잘 된다:
터미널 1이 FOR UPDATE로 잠근 상태에서:
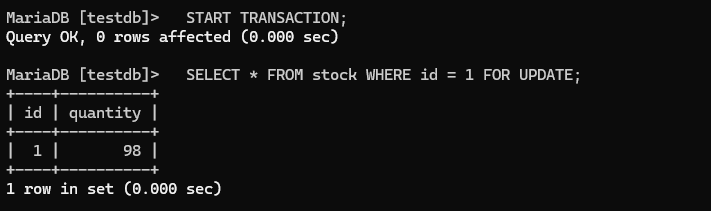
터미널 2: SELECT * FROM stock WHERE id = 1; -- 대기 없이 바로 보임!
→ FOR UPDATE는 "다른 FOR UPDATE/UPDATE/DELETE"만 블로킹한다
→ 일반 읽기는 차단하지 않는다 (Non-blocking read)
-->
결과:
[결과 비교]
synchronized + @Transactional: 재고 48 (Lost Update 발생)
비관적 락 (FOR UPDATE): 재고 0 (정확) ✅왜 비관적 락은 성공하는가?
이건 Step 3의 문제를 정확히 뒤집어 보면 이해가 된다:
- synchronized: lock 반납 → (갭) → 커밋. lock의 생명주기 ≠ 트랜잭션의 생명주기
- FOR UPDATE: lock 획득 → ... → 커밋과 동시에 lock 반납. lock의 생명주기 = 트랜잭션의 생명주기
DB 락은 트랜잭션에 종속된다. 트랜잭션이 끝나야 (COMMIT 또는 ROLLBACK) 락도 풀린다. 그래서 "lock은 풀렸는데 아직 커밋이 안 됐어"라는 상황 자체가 불가능하다.
하지만 비관적 락에도 무조건 좋은 건 아니다. 진지하게 고민해야 할 것들이 있다:
데드락(Deadlock) — "서로 기다리기"
"Dead"는 "죽은", "Lock"은 "잠금". 죽은 잠금이다. T1이 A행을 잠그고 B행을 기다리는데, T2가 B행을 잠그고 A행을 기다리면 → 둘 다 영원히 대기. DB는 데드락을 감지하면 한쪽 트랜잭션을 강제 롤백한다.
커넥션 풀 고갈
잠긴 행을 기다리는 트랜잭션은 DB 커넥션을 물고 있는 채로 대기한다. 대기 요청이 많아지면 커넥션 풀의 모든 커넥션이 대기에 묶이고, 새로운 요청은 커넥션조차 얻지 못한다. 재고 차감 API 하나 때문에 서버 전체가 멈출 수 있다.
처리량(Throughput) 제한
잠긴 동안 다른 트랜잭션은 줄 서서 대기한다. 동시 처리의 장점을 포기하는 것이다.
"그러면 잠그지 않는 방법은 없나?" — 있다.
4-2. 낙관적 락(Optimistic Lock) — "충돌 안 날 거야. 나중에 확인할게"
"Optimistic"은 "낙관적인"이라는 뜻이다. 라틴어 "optimus(최선의)"에서 왔다. "최선의 상황(충돌 없음)을 가정"하고, 잠그지 않는다. 대신 저장할 때 "내가 읽었던 버전이 아직 그대로인지" 확인한다.
비관적 락과 이름이 정확히 대칭인 게 재밌다:
- Pessimistic (pessimus = 최악) → "최악을 가정" → 미리 잠근다
- Optimistic (optimus = 최선) → "최선을 가정" → 나중에 확인한다
구글 독스에서 같은 문단을 두 사람이 동시에 수정할 때 "충돌이 발생했습니다"라고 알려주는 것과 비슷하다. 미리 막지는 않지만, 덮어쓰기는 방지한다.
@Entity
public class OptimisticStockEntity {
@Version // JPA가 자동으로 버전 관리
private Long version;
private int quantity;
}
// JPA가 생성하는 SQL:
// UPDATE optimistic_stock SET quantity = 99, version = 2
// WHERE id = 1 AND version = 1;
//
// 이 SQL을 해석하면:
// "id가 1이고 version이 내가 읽은 것(1)과 같은 행만 업데이트해줘"
// → 누가 이미 바꿨으면 version이 달라져 있으므로 0행이 영향받음
// → JPA가 이걸 감지해서 OptimisticLockException을 던짐[MariaDB 콘솔 테스트]
낙관적 락의 WHERE version = ? 동작 확인:
사전 준비:
CREATE TABLE optimistic_stock (id BIGINT PRIMARY KEY, quantity INT, version BIGINT);
INSERT INTO optimistic_stock VALUES (1, 100, 0);터미널 1:
START TRANSACTION;
SELECT * FROM optimistic_stock WHERE id = 1; -- quantity=100, version=0
터미널 2:
START TRANSACTION;
SELECT * FROM optimistic_stock WHERE id = 1; -- quantity=100, version=0 (바로 읽힘! 잠기지 않았으니까) 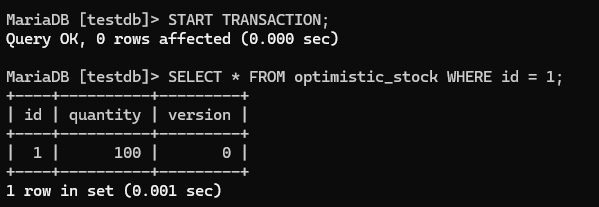
UPDATE optimistic_stock SET quantity = 99, version = 1 WHERE id = 1 AND version = 0;
-- Query OK, 1 row affected
COMMIT;
터미널 1:
UPDATE optimistic_stock SET quantity = 99, version = 1 WHERE id = 1 AND version = 0;
-- Query OK, 0 rows affected ❌ (version이 이미 1로 바뀌었으므로!)
-- → "0 rows affected"가 뜨는게 일반적(하단 스크린샷은 mariaDB의 자체적인 낙관락 감지 내장 기능 때문에 발생한 에러[innodb_snapshot_isolation]). 이것이 낙관적 락의 충돌 감지다.
ROLLBACK;
결론!!:
- 비관적 락: SELECT 시점에 블로킹 → 다른 트랜잭션이 대기 → 순차 처리
- 낙관적 락: SELECT 자유 → UPDATE 시점에 version으로 충돌 감지 → 실패 시 재시도
-->
결과:
[재시도 없음] 성공: 24건, 실패(OptimisticLockException): 76건
[재시도 있음] 성공: 100건, 최종 재고: 0, 소요 시간: 317ms ✅재시도 없이는 76%가 실패했다. 왜 76%인지 생각해보면 이렇다: 100개 스레드가 동시에 version 0을 읽고, UPDATE를 시도한다. DB는 이 UPDATE들을 하나씩 처리하는데, 첫 번째 UPDATE가 version을 1로 올리면 나머지 99개의 WHERE version = 0 조건이 모두 실패한다. 그 중 일부가 재시도 없이도 성공한 건, 실행 타이밍이 겹치지 않아서 운 좋게 통과한 것이다.
재시도 로직을 추가하면 결국 모두 성공하지만, 317ms가 걸렸다.
그러면 비관적 vs 낙관적, 어느 게 더 빠른 건가?
단순히 "비관적이 느리다" 또는 "낙관적이 빠르다"고 말할 수 없다. 충돌 빈도에 따라 역전된다.
- 충돌이 드물 때: 낙관적 락이 유리하다. 대부분의 요청이 충돌 없이 성공하므로, 잠그는 오버헤드가 없는 만큼 빠르다.
- 충돌이 잦을 때: 비관적 락이 유리하다. 낙관적 락은 "실패 → 재시도 → 또 실패 → 또 재시도"를 반복하면서 DB에 불필요한 쿼리를 계속 날린다. 비관적 락은 한 번 대기하면 한 번에 성공한다.
쉽게 말하면: 비관적 락은 "줄 서서 기다리기"이고, 낙관적 락은 "뽑기 실패하면 다시 줄 서기"다. 줄이 짧으면 뽑기가 빠르지만, 줄이 길면 순서대로 기다리는 게 낫다.
보다 더 자세하게 나의 관점을 정리한 흐름도를 적어본다.
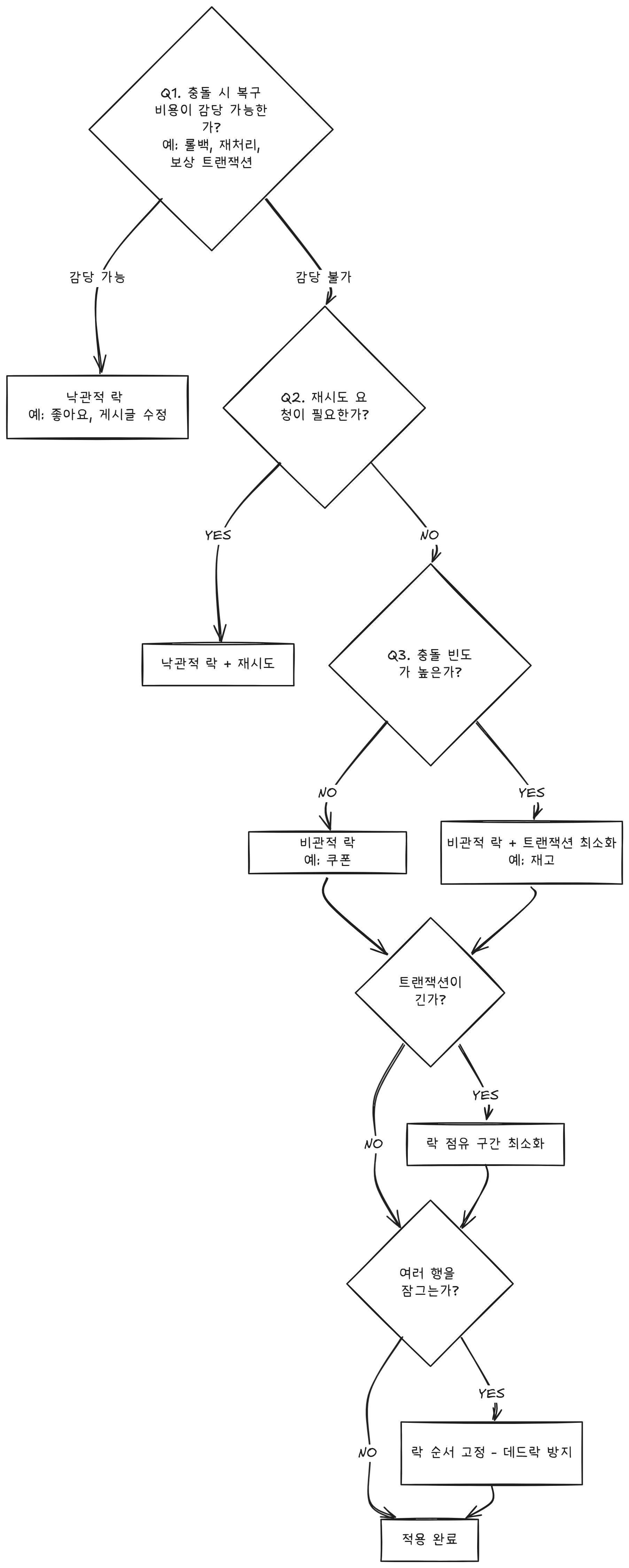
| 상황 | 추천 | 이유 |
|---|---|---|
| 게시글 수정 (동시 수정 드묾) | 낙관적 | 같은 글을 동시에 수정할 확률 낮음 |
| 선착순 쿠폰 100장 발급 | 비관적 | 동시 요청 폭주 → 낙관적이면 재시도 지옥 |
| 상품 재고 차감 (보통 트래픽) | 낙관적 + 재시도 | 적당한 경합, 재시도로 커버 가능 |
| 상품 재고 차감 (초당 수천) | 비관적 또는 분산 락 | 경합이 너무 심하면 DB 락도 한계 |
두 번째 함정 — Spring 프록시 자기 호출
재시도 로직을 구현하다가 또 함정에 빠졌다. 처음에는 같은 서비스 클래스 안에 재시도 메서드를 넣었다.
// ❌ 이렇게 하면 안 된다
@Service
public class OptimisticStockService {
@Transactional
public void decrease(Long id) { ... }
public boolean decreaseWithRetry(Long id, int maxRetries) {
for (int retry = 0; retry <= maxRetries; retry++) {
try {
this.decrease(id); // ← 문제: this = 원본 객체, 프록시가 아님!
return true;
} catch (ObjectOptimisticLockingFailureException e) { ... }
}
}
}
테스트 결과: 재고가 100 그대로. 한 건도 차감되지 않았다.
원인은 Step 3과 같은 맥락이다. this.decrease()는 자기 자신(원본 객체)의 메서드를 직접 호출한다. Spring 컨테이너에서 주입받은 것은 프록시(대리인)인데, this는 프록시가 아니라 원본이다. 프록시를 거치지 않으니 @Transactional이 작동하지 않고, 트랜잭션 없이 JPA가 동작하면 변경 감지(dirty checking)와 flush가 제대로 일어나지 않는다.
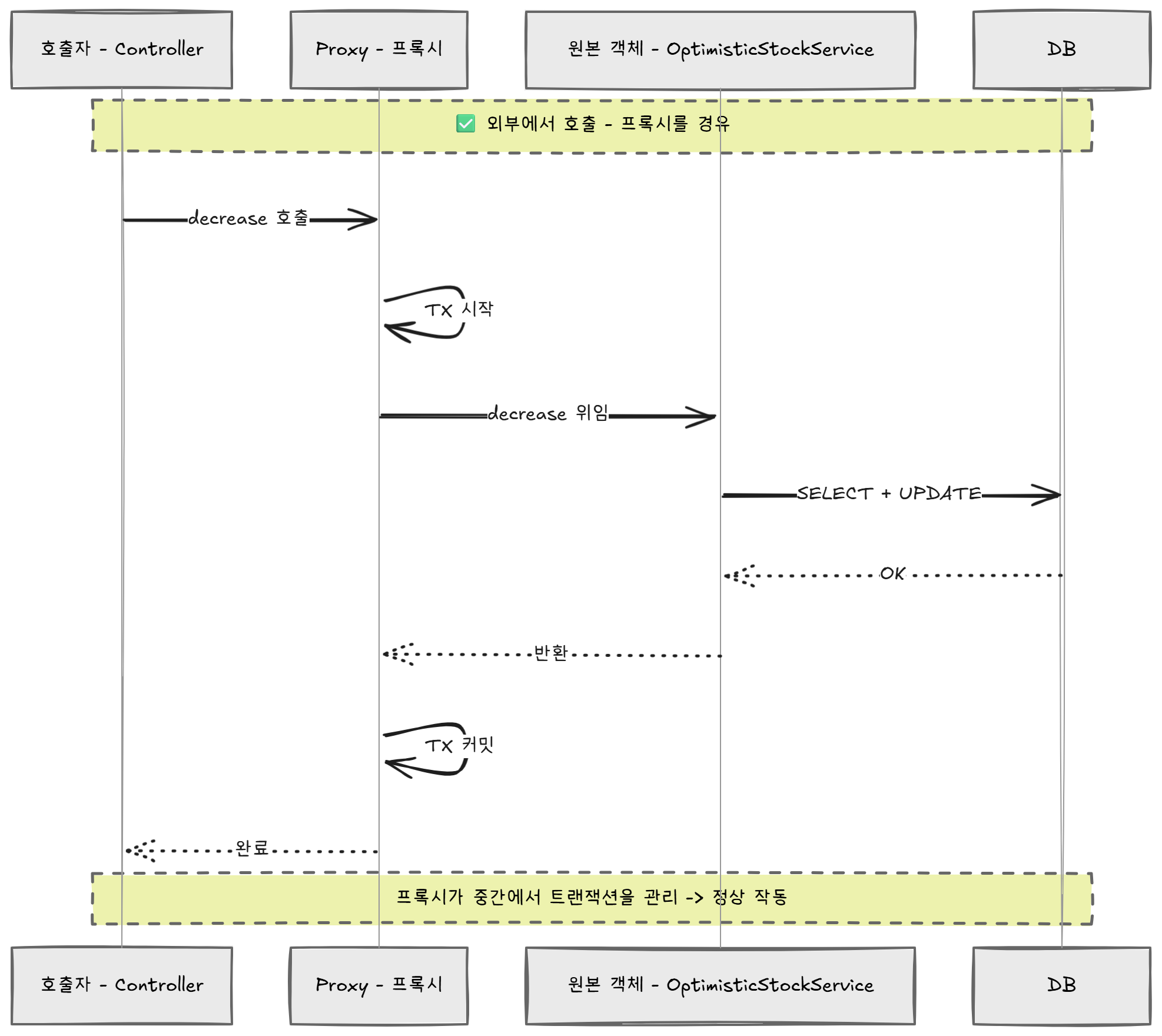
외부에서 호출: 호출자 → [Proxy: 트랜잭션 시작] → 원본 객체.decrease() → [Proxy: 커밋] ✅
자기 호출: 원본 객체.decreaseWithRetry() → this.decrease() ← 프록시를 우회! ❌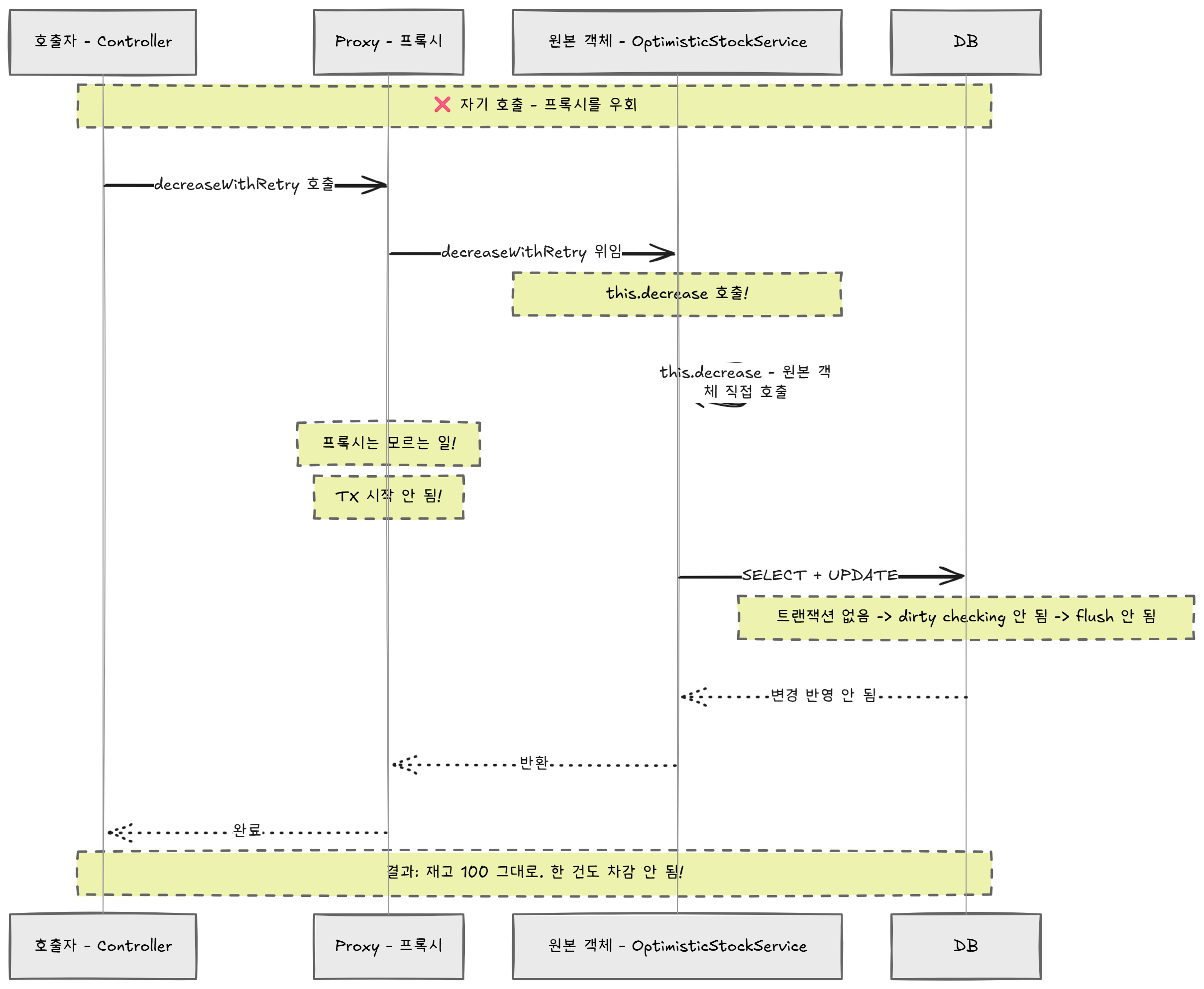
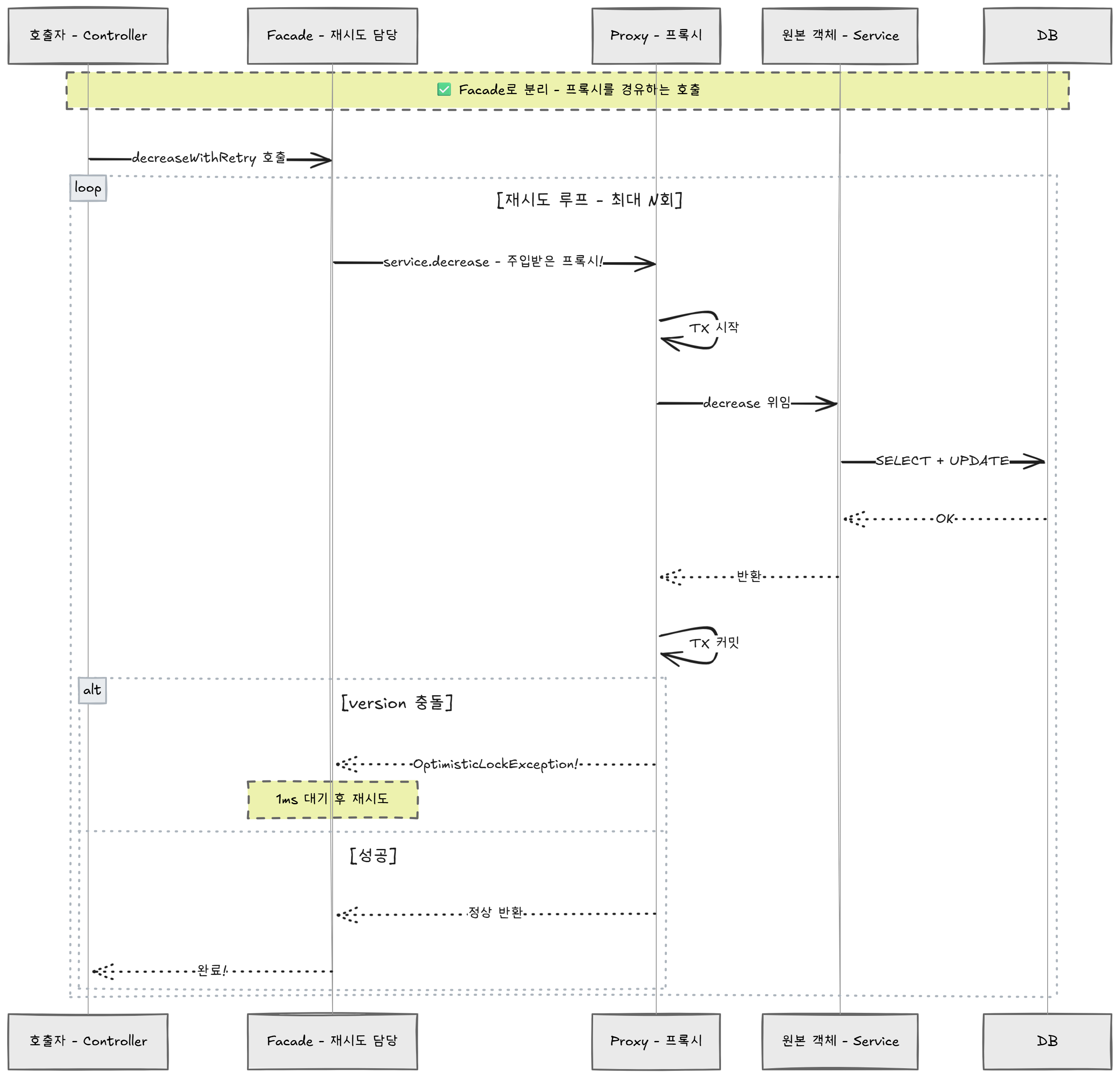
해결: 별도 빈(Facade)으로 분리하여 프록시를 통해 호출한다.
"Facade"는 "건물의 정면(앞면)"이라는 뜻이다. 복잡한 내부 구조를 감추고, 외부에 깔끔한 인터페이스를 제공하는 패턴이다. 여기서는 "재시도 로직"이라는 복잡성을 분리하는 역할을 한다.
@Component
public class OptimisticStockFacade {
private final OptimisticStockService service; // 주입받은 것 = 프록시
public boolean decreaseWithRetry(Long id, int maxRetries) {
for (int retry = 0; retry <= maxRetries; retry++) {
try {
service.decrease(id); // ← 프록시를 통한 호출 → @Transactional 작동!
return true;
} catch (ObjectOptimisticLockingFailureException e) {
Thread.sleep(1); // 잠시 대기 후 재시도
}
}
}
}
이건 동시성 제어만의 문제가 아니다. Spring AOP 기반 기능 전체에 해당하는 제약이다. @Transactional, @Cacheable, @Async, @Retryable — 전부 프록시 기반이므로, 같은 클래스 안에서 자기 호출하면 무효화된다. "프록시"라는 단어의 뜻을 기억하면 자연스럽다: 대리인은 외부에서 호출할 때만 대리 역할을 한다. 내부에서 자기한테 말하는 건 대리인이 끼어들 수 없다.
그래서, 언제 뭘 쓰는가?
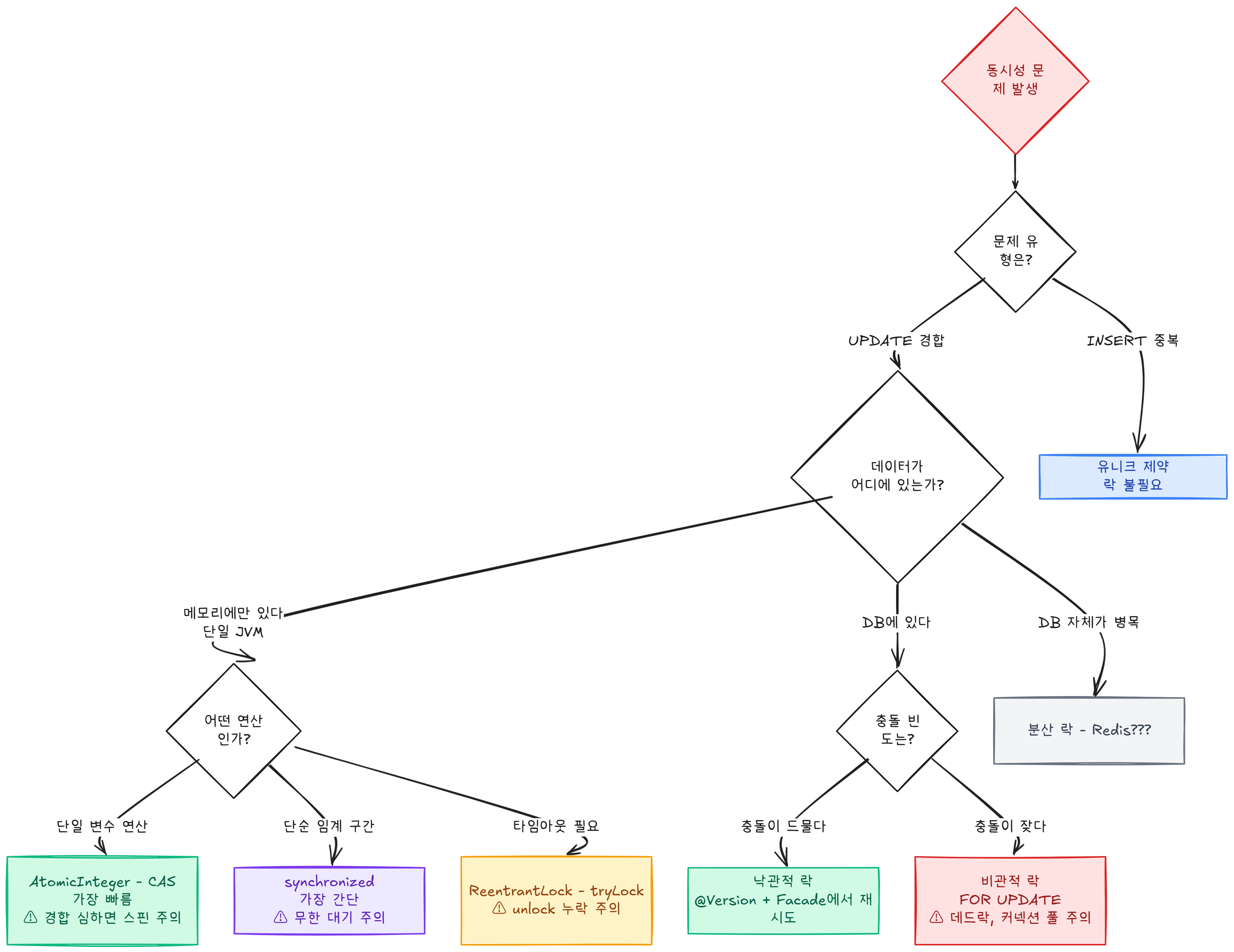
Step 1~4를 거치면서 네 개의 키워드가 자연스럽게 판단 기준으로 연결된다:
1. "데이터가 어디에 있는가?" — 같은 레이어에서 제어 (Step 3~4에서 느꼈다!)
- 메모리에만 있다 (단일 JVM) → Java 락 (synchronized, ReentrantLock, Atomic)
- DB에 있다 → DB 락 (비관적 락, 낙관적 락)
- 섞지 마라. Java 락으로 DB 데이터를 제어하면 생명주기 불일치로 깨진다 (Step 3).
- 데이터가 사는 곳과 락이 사는 곳을 일치시켜야 한다.
2. "충돌이 얼마나 자주 일어나는가?" — 상호 배제의 전략을 정한다
- 거의 안 일어난다 → 낙관적 (잠그지 않고 나중에 확인, 실패 시 재시도)
- 자주 일어난다 → 비관적 (미리 잠가서 한 번에 성공)
- 교차점이 있다. 충돌 빈도가 어느 수준을 넘으면 낙관적의 재시도 비용이 비관적의 대기 비용을 초과한다.
3. "문제의 성격이 뭔가?" — read-modify-write인가, INSERT 중복인가?
- 같은 값을 동시에 바꾸려는 것 (UPDATE) → 락
- 같은 데이터를 동시에 넣으려는 것 (INSERT 중복) → 유니크 제약
- 도구를 고르기 전에 문제를 정확히 정의하는 게 먼저다.
동시성 문제가 있다
│
├─ 문제 유형은?
│ ├─ UPDATE 경합 → 아래 판단으로
│ └─ INSERT 중복 → 유니크 제약 (락 불필요)
│
├─ 데이터가 메모리에만 있는가? (단일 JVM)
│ ├─ 단일 변수 연산 → AtomicInteger (CAS, 가장 빠름, 경합 심하면 스핀 주의)
│ ├─ 단순 임계 구간 → synchronized (가장 간단, 무한 대기 주의)
│ └─ 타임아웃 필요 → ReentrantLock (tryLock, unlock 누락 주의)
│
├─ 데이터가 DB에 있는가?
│ ├─ 충돌이 드물다 → 낙관적 락 (@Version + Facade에서 재시도)
│ └─ 충돌이 잦다 → 비관적 락 (FOR UPDATE, 데드락/커넥션 풀 주의)
│
└─ DB 자체가 병목인가?
└─ 분산 락 (Redis) — 다음 글에서 다룰 예정결론
| Step | 시도 | 결과 | 핵심 키워드 | 깨달은 점 |
|---|---|---|---|---|
| 1 | 락 없이 실행 | 재고 99 | read-modify-write | 1ms 간격이면 충분히 터진다. 테스트 통과 ≠ 문제 없음 |
| 2-1 | synchronized | 재고 0, 217ms | 상호 배제 | 모니터 락으로 해결되지만, 무한 대기의 대가 |
| 2-2 | ReentrantLock | 7건 성공, 93건 포기 | 상호 배제 | tryLock으로 "포기"할 수 있다. unlock 누락 주의 |
| 2-3 | AtomicInteger | 재고 0, 1ms | 상호 배제 (CAS) | 잠그지 않아 빠르지만, 단일 변수 + 경합 적을 때만 |
| 2-UK | 유니크 제약 | 1건만 발급 | 문제 정의 | UPDATE와 INSERT는 다른 문제. 도구 전에 문제 정의가 먼저 |
| 3 | synchronized + @Transactional | 재고 49 | 생명주기 불일치 | 프록시 생명주기 ≠ 락 생명주기. 레이어를 섞으면 깨진다 |
| 4-1 | 비관적 락 (FOR UPDATE) | 재고 0 | 같은 레이어에서 제어 | DB 락 = 트랜잭션에 종속. 생명주기 일치로 갭 없음 |
| 4-2 | 낙관적 락 + 재시도 | 재고 0, 317ms | 같은 레이어에서 제어 | 충돌 감지 + 재시도. 빈도에 따라 비관적과 역전 |
이제까지의 네 개의 키워드를 다시 정리해보면:
1. read-modify-write — 동시성 문제의 진원지
모든 것은 여기서 시작됐다. 읽기와 쓰기가 분리된 순간, 그 사이에 다른 스레드가 끼어들 수 있다. 1ms의 간격으로 99건이 사라지는 것을 직접 보고 나니, "테스트 통과 ≠ 문제 없음"이라는 말이 체감됐다. 동시성 문제는 확률적이다. 구조적으로 안전한지를 따로 판단해야 한다.
2. 상호 배제 (mutual exclusion) — 가장 직관적인 해답, 그리고 그 한계
read-modify-write를 atomic하게 만들 수 없다면, 한 번에 하나만 들어오게 막으면 된다. synchronized, ReentrantLock, AtomicInteger — 모두 상호 배제의 변형이다. 하지만 이것만으로는 DB 트랜잭션이 개입하는 순간 무너진다.
3. 생명주기 불일치 (lifecycle mismatch)
synchronized + @Transactional 관련 함정이 이번에 배운 새로운 지식이였다. lock은 코드 블록에 종속되고, 트랜잭션은 프록시에 종속된다. 두 메커니즘이 끝나는 시점이 다르면, 그 찰나의 갭에서 정합성이 깨진다. "왜 안 되는지"를 이해하려면 프록시가 뭔지, 왜 Spring이 그렇게 설계했는지까지 따라가야 했다.
4. 같은 레이어에서 제어 — 데이터가 사는 곳이 어디?
결국 답은 단순했다. 데이터가 사는 곳에서 제어해야 한다. 메모리 데이터는 Java 락으로, DB 데이터는 DB 락으로. 비관적 락은 트랜잭션과 생명주기가 같아서 갭이 없고, 낙관적 락은 버전으로 충돌을 감지한다. 섞으면 깨진다.
5. 그런데 이제 DB에서 락 감당이 안된다면?
분산락과 REDIS에 대하여 추가적으로 다뤄볼 예정이다.

그리고 돌이켜보니 단어에 정답이 있었다.
단어의 뜻을 따라가면 개념이 연결된다. Pessimistic(최악을 가정), Optimistic(최선을 가정), Atomic(쪼갤 수 없는), Proxy(대리인), Monitor(감시자), Isolation(격리), Constraint(제약) — 용어를 외우는 게 아니라 뜻을 이해하면, 새로운 개념을 만나도 이름에서 힌트를 얻을 수 있다는 인사이트도 깨닫게 되었다.

시퀀스 다이어그램이 있어서 눈에 쏙쏙 들어오네요 ...