TL;DR: "대략 맞으면 되는" 줄 알았던 랭킹 데이터에서 가장 많은 설계 판단이 필요했다.
0. "이 순위는 어떻게 정해지는 걸까?"
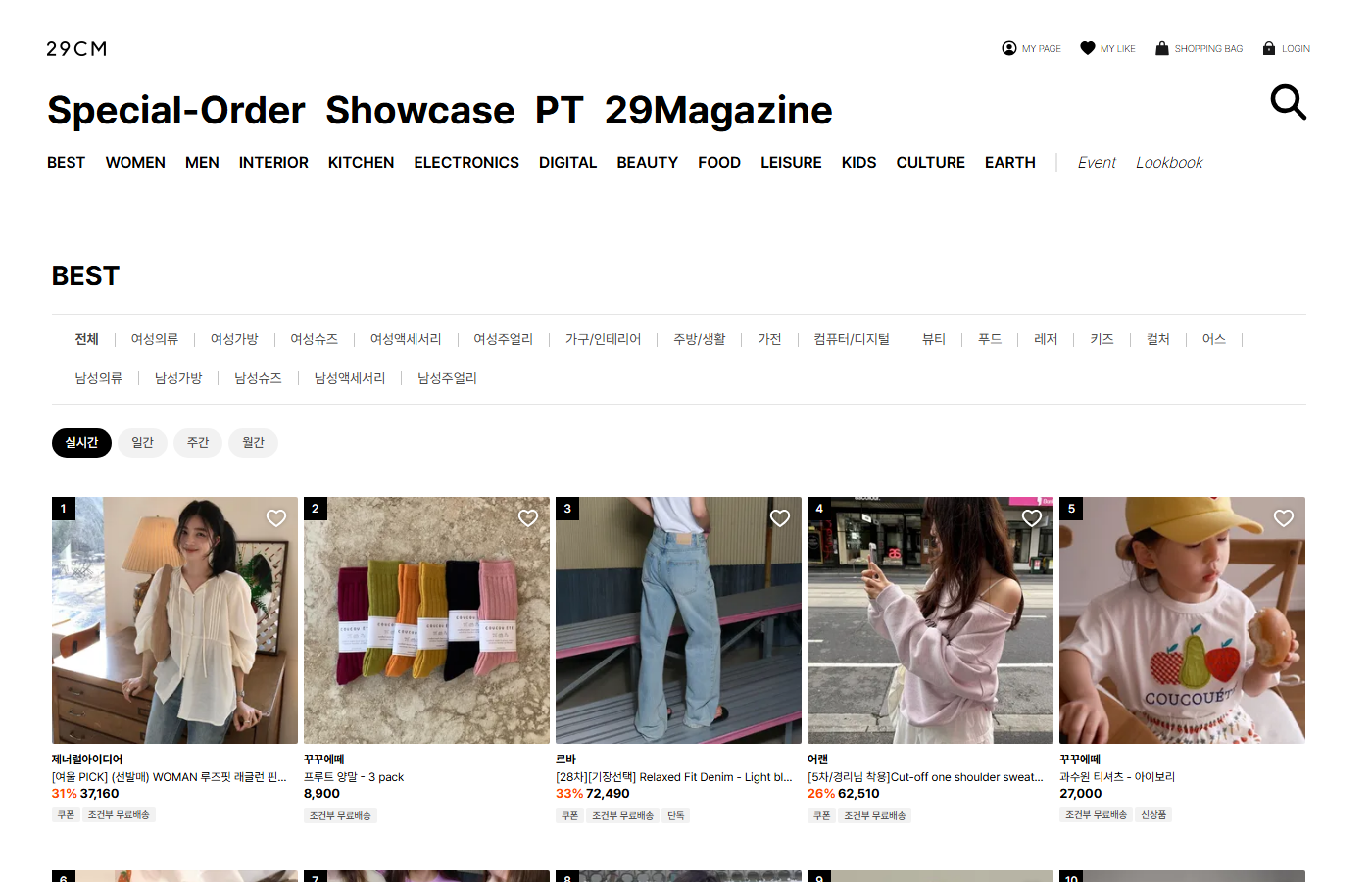
29CM BEST 페이지. 이 순위는 어떻게 정해지는 걸까?
이 글에서 사용한 실험 환경은 Spring Boot + Redis ZSET 기반 학습용 프로젝트입니다. Score 방식/가중치 조합별 순위 변동을 비교했습니다. 29CM API 분석은 브라우저 개발자 도구의 Network 탭을 통해 공개된 요청/응답 구조를 관찰한 것이며, 내부 구현에 대한 단순 추정을 포함하고 있으니 오해 없길 바랍니다!
29CM의 BEST 탭을 보면 상품들이 순위별로 나열되어 있다. 매일 들어가면서도 한 번도 의심해본 적 없는 화면이었다.
이 순위는 어떻게 정해지는 걸까?
단순히 판매량 순일까? 그렇다면 289만원짜리 르메르 크로와상 백 1개와 3만2천원짜리 포터리 캔들 100개 중 뭐가 위에 와야 할까? 인스타에서 난리인 탬버린즈 퍼퓸과 조회수 30이지만 꾸준히 팔리는 커먼프로젝츠 스니커즈 중 누가 더 "인기 있는" 건가?
스터디에서 Redis ZSET 기반 랭킹 시스템 과제를 받았을 때, 이 궁금증이 다시 떠올랐다. 과제를 시작하기 전에, 실제 서비스는 어떻게 하고 있는지 먼저 뜯어보고 싶었다.
오케이 우선 까보자!
난 개발자니까(?) 궁금한 건 직접 까봐야 직성이 풀린다. 그래서 F12를 눌렀다. BEST 페이지의 Network 탭을 보니 display-bff-api라는 BFF 서버로 POST 요청이 가고 있었다.
{
"facets": {
"periodFacetInput": { "type": "HOURLY" },
"rankingFacetInput": { "type": "POPULARITY" }
},
"userSegment": { "gender": "F", "age": "THIRTIES" }
}이걸 보고 좀 놀랐다. 내가 생각한 랭킹은 "전체 상품에 점수 매기고 정렬"이라는 단일 축이었는데, 29CM은 5가지 차원으로 랭킹을 쪼개고 있었다.
| 차원 | 옵션 |
|---|---|
| 기간 | 실시간 / 일간 / 주간 / 월간 |
| 정렬 | 인기순 / 판매순 |
| 성별 | 여성 / 남성 |
| 연령 | 전체 / 20대 / 30대 / ... |
| 카테고리 | 전체 / 여성의류 / 남성가방 등 21개 |
특히 눈에 띈 건 두 가지였다.
첫째, "인기순(POPULARITY)"과 "판매순(SALES)"이 분리되어 있다. 나는 이 둘을 하나의 가중치 공식으로 섞으려고 했는데, 29CM은 아예 별개의 랭킹으로 취급하고 있었다. 인기와 판매는 섞는 게 아니라 나누는 거였나?
둘째, 응답에 score 필드가 없다. rank, score, weight 같은 필드가 하나도 없다. 배열의 인덱스가 곧 순위다. 서버에서 점수를 계산하고, 정렬된 결과만 내려주고, 클라이언트에는 "이 순서대로 보여줘"만 전달한다. 랭킹 알고리즘이 완전히 서버에 캡슐화되어 있는 셈이다.
그리고 flag.29cm.co.kr이라는 Feature Flag 서버(Unleash)로 요청이 가는 것도 보였다. 주제에 벗어날 수 있지만 궁금함을 못 참고 찾아보니까 랭킹 알고리즘을 A/B 테스트때 비교 실험을 위해 사용한다고 한다ㅎㅎ 알고리즘을 바꿔도 프론트 배포 없이 서버에서 스위칭할 수 있는 구조로 보인다.
여기까지 뜯어보고 나니 궁금증이 구체적으로 정리됐다. POPULARITY와 SALES를 왜 분리했을까? 시간 단위는 왜 4가지나 필요할까? 점수를 왜 클라이언트에 안 보여줄까?
답을 머리로만 추측하기보단, 직접 만들어보면서 부딪혀야 체감할 수 있을 것 같았다. 간단한 학습 프로젝트를 하나 세팅하고, 29CM에서 떠오른 궁금증들을 하나씩 실험해보기로 했다.
1. Score 설계 — 같은 데이터로 1위가 세 번 바뀌었다
상황: ZINCRBY에 뭘 넘길 것인가
랭킹 시스템을 만들려면 가장 먼저 답해야 하는 질문이 있다. "점수를 어떻게 계산할 것인가?"
Redis ZSET 기반 랭킹의 핵심은 결국 이 한 줄이다.
ZINCRBY ranking:all:20260410 ??? productId이 ??? 자리에 뭘 넣느냐. 29CM의 POPULARITY가 내부적으로 어떤 계산을 하는지는 알 수 없지만, 최소한 "조회 = 0.1점, 좋아요 = 0.3점, 주문 = 금액 × 0.5" 같은 가중치 합산 방식은 있을 거라고 가정했다. 실험 프로젝트에서 이 가정을 검증해보기로 했다.
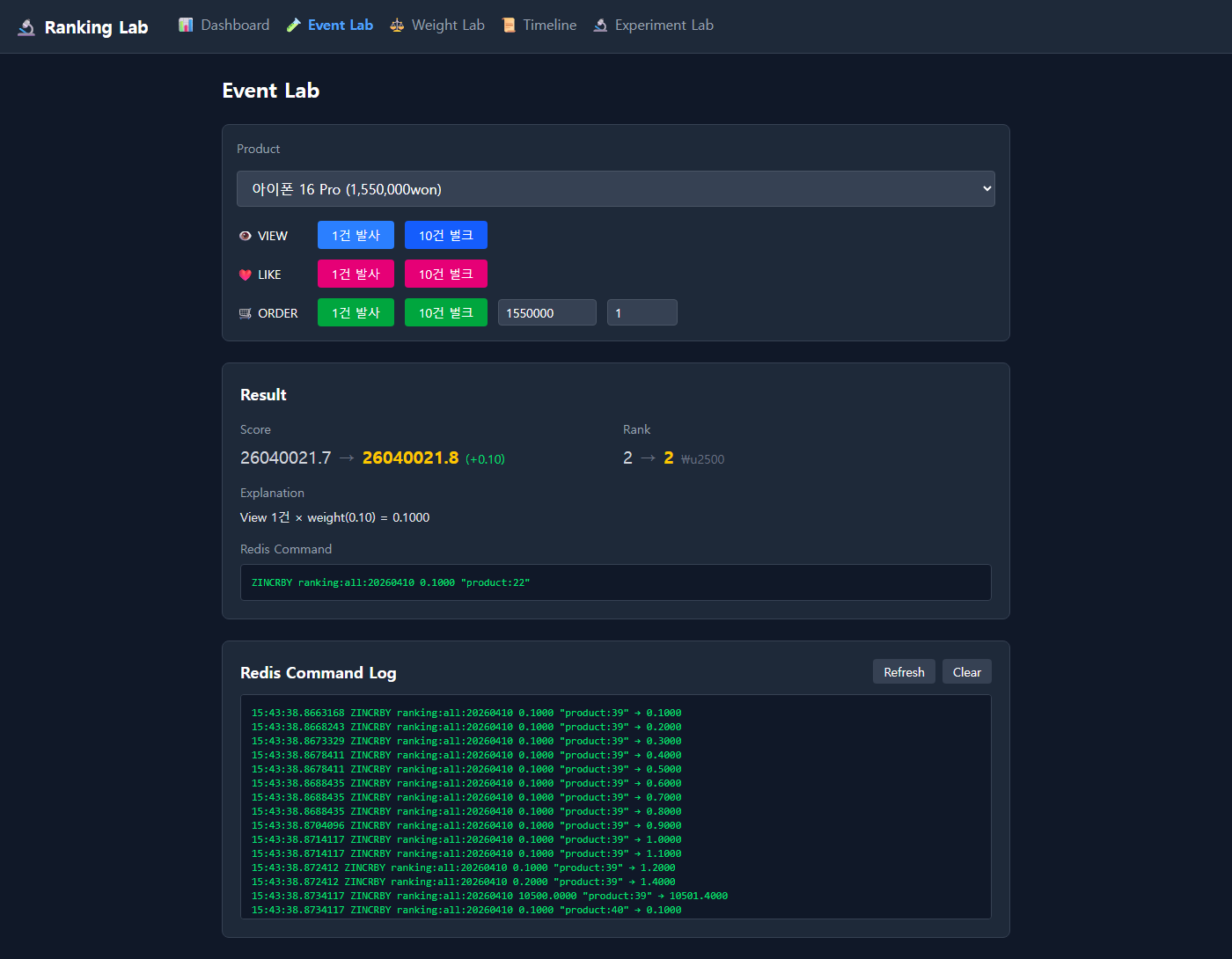
이벤트 1건이 ZINCRBY 명령 하나로 변환된다. View 1건 × weight(0.10) = 0.1000 — 이 0.1이 어떤 의미를 가지는지가 이 글의 핵심이다.
29CM처럼 다양한 성격의 상품이 섞인 상황을 만들기 위해, 20개 상품을 6가지 프로파일로 분류했다.
STAR(르메르 백, 아크네 머플러) — 조회 200 / 좋아요 40 / 주문 15 ← 고가 디자이너, 꾸준히 팔림
RISING(메종키츠네 니트, 가니 원피스) — 조회 350 / 좋아요 60 / 주문 5 ← 떠오르는 브랜드, 구매 고민 중
VIRAL(탬버린즈 퍼퓸, 논픽션 향수) — 조회 500 / 좋아요 80 / 주문 3 ← 인스타 바이럴, 구매 전환 낮음
STEADY_SELLER(커먼프로젝츠, 에어팟) — 조회 30 / 좋아요 5 / 주문 25 ← 조용히 꾸준히 팔림
VALUE_HIT(무신사 콜라보, 뉴발란스) — 조회 40 / 좋아요 8 / 주문 35 ← 가성비 한정판, 주문 많음
LONGTAIL(빈티지 안경테, 핸드메이드) — 조회 10 / 좋아요 2 / 주문 1 ← 니치 취향이 비율로 4,069건의 이벤트를 생성하고, 가중치는 동일(View 0.2, Like 0.3, Order 0.5)하게 고정한 채 Score 계산 방식만 바꿔봤다.
같은 가중치에 Score Type만 LINEAR / LOG / COUNT로 달리 설정하고 Compare.
고민 1: 금액을 그대로 쓰면 안 되나?
처음에는 당연히 금액을 그대로 넣었다. ORDER Score = price × quantity × weight. 주문금액이 크면 점수가 높고, 그게 인기 아닌가? 결과를 보고 생각이 바뀌었다.
| 순위 | 상품 | 프로파일 | 총점 | 주문 점수 비중 |
|---|---|---|---|---|
| 1 | 르메르 크로와상 백 | STAR | 21,675,040 | 99.99% |
| 2 | 아크네 머플러 | STAR | 4,425,041 | 99.99% |
| 3 | 뉴발란스 993 | VALUE_HIT | 3,346,011 | 99.99% |
조회 636건을 기록한 탬버린즈 퍼퓸(VIRAL)은 6위에도 못 들었다. 조회 점수 127.2점은 르메르 백의 주문 점수 21,675,000점 앞에서 0.0006%다. 조회수가 아무리 높아도, 289만원짜리 가방 하나 사간 기록 앞에서는 존재감이 없다.
29CM BEST에 들어갔는데 르메르 백, 아크네 머플러, 커먼프로젝츠만 쭉 보인다고 생각해보자. 인스타에서 난리인 탬버린즈 퍼퓸은 한참 내려야 나온다. 이게 "인기 상품"인가?
고민 2: "그러면 가중치를 바꾸면 되지 않나?"
우선 가중치를 조정하면 되지 않나? 라는 직관이 먼저 머리에 꽂혔다. 그래서 조회 가중치를 0.9까지 올리고 주문 가중치를 0.1로 내려봤다.
| 설정 | View | Like | Order | 1위 |
|---|---|---|---|---|
| 구매 중심 | 0.1 | 0.1 | 0.8 | 르메르 크로와상 백 |
| 관심도 중심 | 0.5 | 0.4 | 0.1 | 르메르 크로와상 백 |
| 균등 배분 | 0.33 | 0.34 | 0.33 | 르메르 크로와상 백 |
TOP 5가 전부 동일했다. 가중치 슬라이더를 아무리 움직여도 꿈쩍도 안 했다.
왜 그런지 계산하면 바로 보인다. Order 가중치를 0.1로 내려도 289만 × 0.1 = 289,000점. View 가중치를 0.5로 올려도 1건 × 0.5 = 0.5점. 스케일 자체가 다른데 가중치는 비율만 바꾸는 거니까, 트럭 위에 모래알을 올리는 것과 같다. 가중치를 조절한다는 건 모래알의 크기를 바꾸는 것에 불과했다.
결국 "가중치를 잘 조정하면 된다"는 내 전제가 틀렸다. 문제는 가중치가 아니라 스케일이라는 쪽으로 접근할 수 있게 되었다.
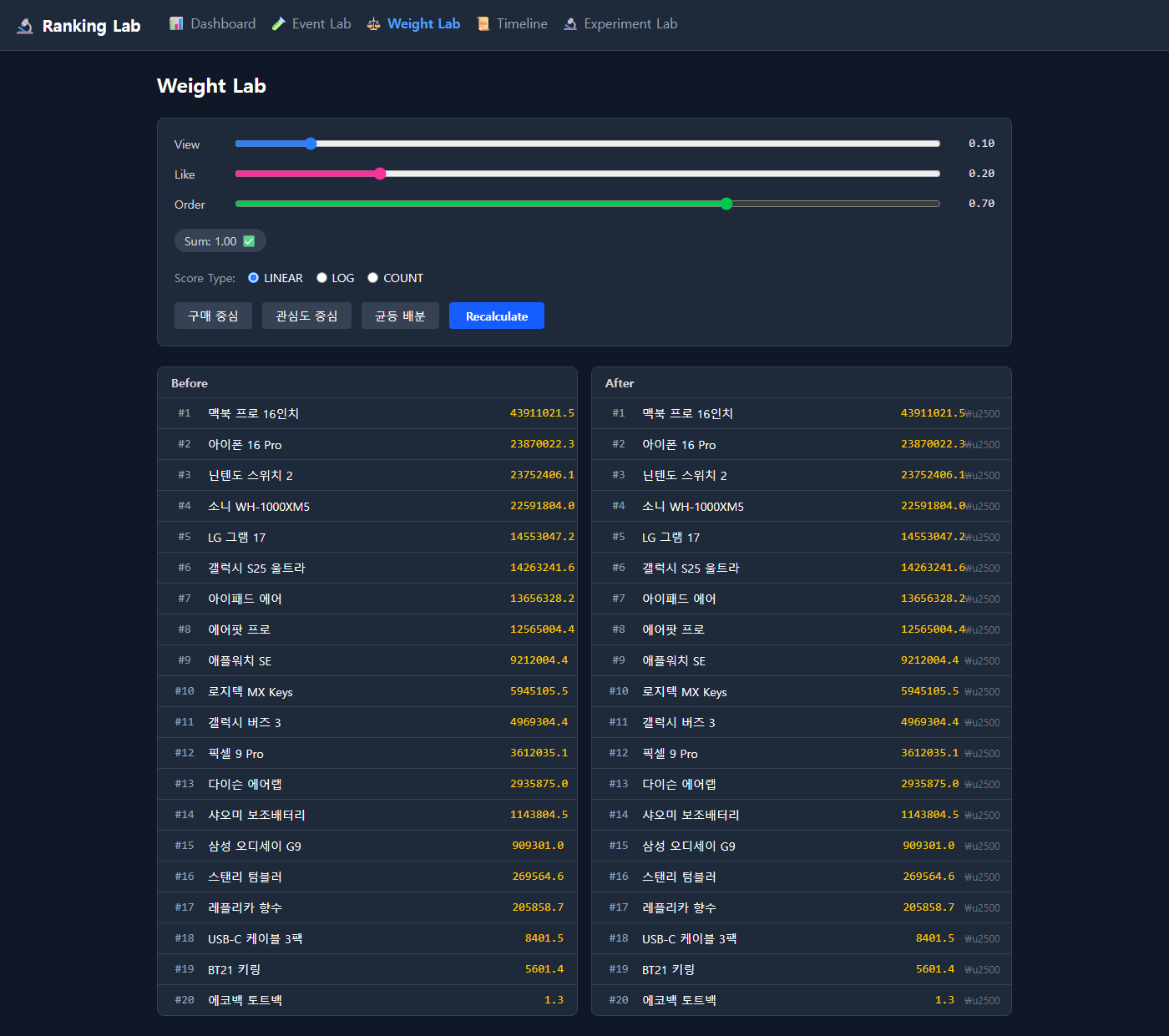
View 가중치를 올리고 Order를 내려도 순위가 동일하다. 금액 스케일이 가중치를 압도한다.
해결: 정규화 — log를 씌우면 어떻게 되나?
스케일이 문제라면 스케일을 맞추면 된다. 스케일을 줄일 수 있는 간단한 테크닉인 log를 씌워봤다.
ORDER Score = log(price × quantity) × weight| 순위 | 상품 | 프로파일 | 총점 | 주문건수 |
|---|---|---|---|---|
| 1 | 뉴발란스 993 | VALUE_HIT | 244.4 | 34 |
| 2 | 무신사 콜라보 재킷 | VALUE_HIT | 223.3 | 41 |
| 3 | 커먼프로젝츠 스니커즈 | STEADY_SELLER | 208.0 | 29 |
순위가 완전히 뒤집혔다. 르메르 백은 9위로 밀려났다.
log(2,890,000) = 14.9 vs log(198,000) = 12.2. 289만원과 19.8만원이 15 vs 12로 압축된다. 금액의 "비싸다"는 시그널은 살아있지만, 이제 그 차이가 작아졌기 때문에 주문 건수 34건 vs 15건이 순위를 뒤집을 수 있게 된다.
그런데 여기서 또 고민이 생겼다. "비싼 건 원래 더 높아야 하는 거 아닌가?" 맞는 말 같지만, 생각해보면 3만원짜리 포터리 캔들을 100개 사간 것이 289만원짜리 르메르 백 1개보다 더 "인기 있는" 것 아닌가? 매출을 밀어주고 싶은 건 "인기"가 아니라 비즈니스 의도다.
둘은 다르다.
그렇다면 금액을 완전히 빼면 어떤 세상이 될까? 한 번 더 밀어봤다.
ORDER Score = 1.0 × weight (금액 무시, 건수만)| 순위 | 상품 | 프로파일 | 총점 | 조회수 |
|---|---|---|---|---|
| 1 | 탬버린즈 퍼퓸 | VIRAL | 145.8 | 636 |
| 2 | 논픽션 향수 | VIRAL | 124.6 | 524 |
| 3 | 이솝 핸드크림 | VIRAL | 111.6 | 441 |
VIRAL이 상위를 독식했다. 조회수 636건이지만 주문은 3건뿐인 탬버린즈가 1위. 29CM BEST가 이러면? "사람들이 많이 봤지만 안 사는 상품" 순위가 된다. 이것도 좀 아닌 것 같다는 생각이 들었다.
29CM은 이 문제를 어떻게 풀었을까?
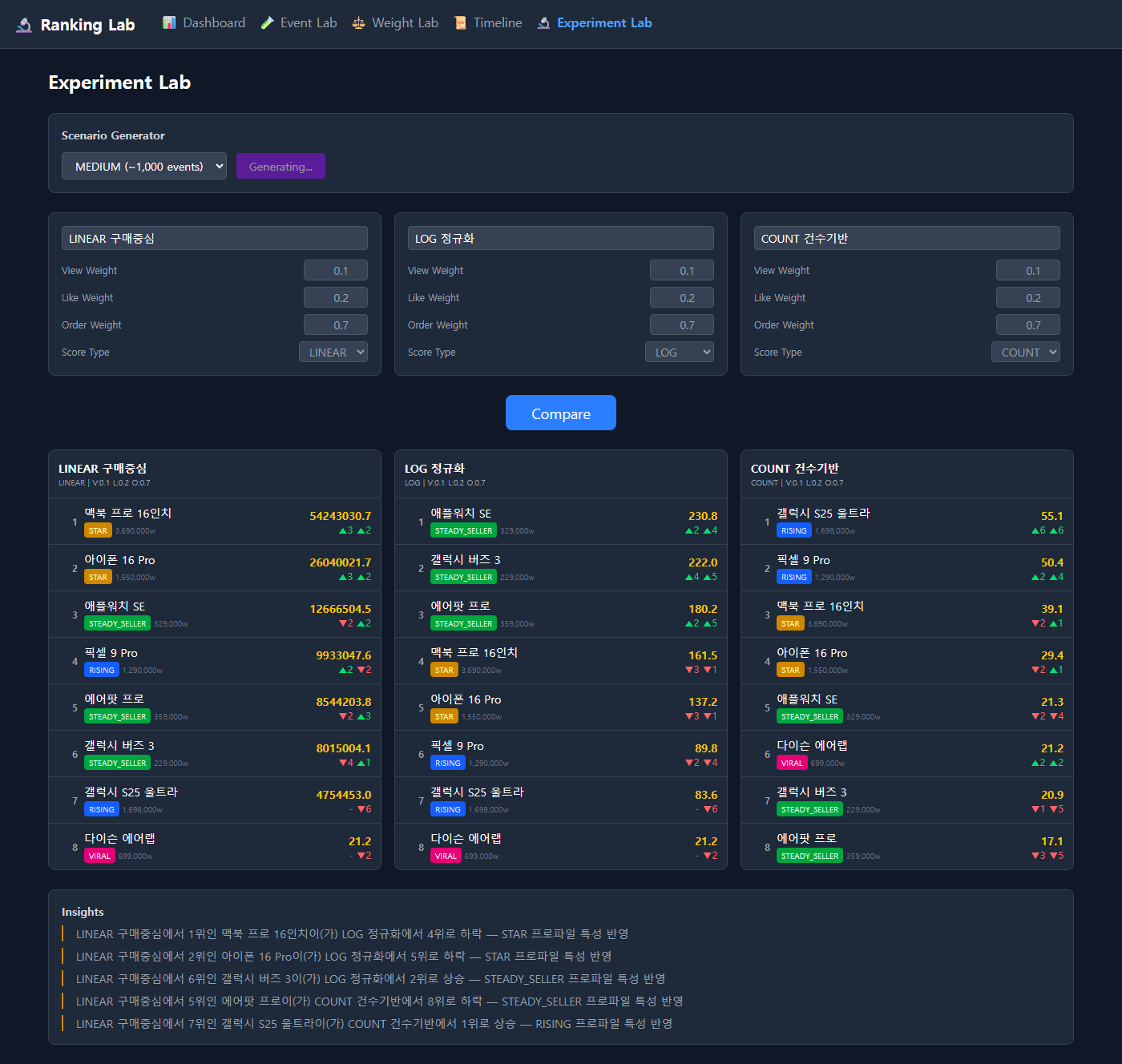
같은 데이터, 같은 가중치. Score 방식만 바꿨을 때의 3-way 비교.
| Score 방식 | 1위 | 이 랭킹이 의미하는 것 |
|---|---|---|
| LINEAR | 르메르 크로와상 백 (STAR) | 매출 기여도 순위 |
| LOG | 뉴발란스 993 (VALUE_HIT) | 구매 인기 순위 |
| COUNT | 탬버린즈 퍼퓸 (VIRAL) | 관심도/트렌드 순위 |
같은 데이터에서 1위가 세 번 바뀌었다. 어느 방식이 "정답"인지는 엔지니어가 정할 수 있는 게 아니다.
그런데 여기서 §0에서 살펴본 29CM의 API가 떠올랐다. 29CM은 이 문제를 "하나의 공식에 섞는" 대신 "인기순(POPULARITY)"과 "판매순(SALES)"을 분리해서 해결하고 있었다. 인기와 매출을 가중치로 타협하지 않고, 아예 별개의 랭킹으로 제공한다. 사용자가 탭 하나로 전환할 수 있게.
내 실험에서 LINEAR(매출)와 COUNT(관심도)가 완전히 다른 세계를 보여줬으니까, 이걸 하나로 섞는 것 자체가 어쩌면 잘못된 접근이었던 거다. 29CM의 POPULARITY가 내부적으로 어떤 Score 방식을 쓰는지는 알 수 없지만, 적어도 SALES와 분리한 건 현명한 판단이라고 느꼈다.
그리고 29CM이 Feature Flag(Unleash)를 쓰고 있다는 것도 시사점이 있다. Score 방식은 한 번 정하면 끝이 아니라 계속 실험하고 바꿀 수 있는 구조여야 한다는 뜻이다. A/B 테스트로 POPULARITY에 LOG를 쓸지 COUNT를 쓸지를 데이터 기반으로 결정할 수 있다. 코드 배포 없이 서버에서 스위칭하면 되니까.
결국 "인기 = 무엇?"은 한 번의 합의로 끝나는 게 아니라, 지속적으로 실험하며 조정하는 것이었다. 처음에 "가중치만 잘 잡으면 되겠지" 하고 가볍게 생각했던 게 좀 부끄러웠다.
2. 저장소 선택 — 왜 Redis ZSET인가
Score 공식이 정해졌다고 끝이 아니다. 이 점수는 이벤트가 발생할 때마다 갱신되고, 사용자가 BEST 페이지를 열 때마다 정렬된 결과로 조회되어야 한다. "계산된 점수를 어디에 저장하고, 어떻게 꺼내올 것인가" — 이제 저장소를 고를 차례다.
고민: RDB로 하면 안 되나?
처음 떠오른 건 당연히 RDB였다. product_metrics 테이블에 view_count, like_count, sale_amount 컬럼이 있으니까. SELECT * FROM product_metrics ORDER BY score DESC LIMIT 20이면 끝 아닌가?
문제는 score가 계산된 값이라는 거다.
score = view * 0.2 + like * 0.3 + log(order_amount) * 0.5이걸로는 인덱스를 걸 수가 없다. "그러면 total_score 컬럼을 만들어서 미리 계산해두면?" — 물론 가능하다. 실제로 트래픽이 적은 서비스라면 이 방식으로 충분하다.
그런데 이벤트가 올 때마다 UPDATE product_metrics SET total_score = ... WHERE product_id = ?를 해야 한다. 이 UPDATE는 행 락을 건다. 29CM BEST 페이지를 수십만 명이 동시에 보고 있는데, 누군가 상품을 조회할 때마다 UPDATE가 발생한다? 은행 창구가 하나인데 잔고 조회하는 사람과 입금하는 사람이 같은 줄에 서 있는 꼴이다.
"그러면 Materialized View는?" — 주기적으로 갱신하는 방식이라 실시간성이 떨어진다. 5분 간격으로 갱신하면 5분 동안은 바이럴 상품이 반영이 안 된다. 30초 간격이면 DB 부하가 올라간다. 어디서 타협할 것인가가 또 고민이 된다.
해결: ZSET — 쓰는 순간 정렬이 끝나는 구조
Redis ZSET은 이 구조를 근본적으로 바꾼다.
| RDB (computed column) | Redis ZSET | |
|---|---|---|
| 점수 갱신 | UPDATE (행 락, O(1)이지만 락 경쟁) | ZINCRBY (O(logN), 락 없음) |
| 정렬 조회 | ORDER BY (인덱스 있어도 락 대기 가능) | ZREVRANGE (이미 정렬된 상태) |
| 동시성 | 락 경쟁 | 단일 스레드, 자연스러운 직렬화 |
| 실시간성 | UPDATE 즉시 반영이지만 락 경쟁 | ZINCRBY 즉시 반영, 락 경쟁 없음 |
ZINCRBY를 실행하면 점수 증가와 동시에 Skip List에서 위치가 재정렬된다. 조회 시에는 이미 정렬된 결과를 꺼내기만 하면 된다. 입금하는 순간 잔액이 정렬까지 끝나는 구조다.
트레이드오프: 메모리와 영속성
ZSET을 선택하면 포기하는 것도 있다.
메모리: ZSET의 member(상품 ID) + score(점수)가 전부 메모리에 올라간다. 상품 20개면 문제없지만, 10만 개 상품이라면? member당 대략 64바이트 내외로, 10만 개 기준 약 6MB. 이 정도면 Redis 메모리에서 문제가 되지는 않는다. 다만 29CM처럼 성별 × 연령 × 카테고리별 랭킹을 각각 관리하면 키 수가 늘어난다. 성별 2 × 연령 5 × 카테고리 21 × 기간 4 = 840개 키. 이건 서비스 규모에 따라 판단할 부분이다.
영속성: Redis가 죽으면 랭킹 데이터가 날아간다. 이건 좀 무서운 시나리오인데, 생각해보면 product_metrics 테이블이 RDB에 있으니까 ZSET은 언제든 재구축이 가능하다. RDB가 Source of Truth이고, ZSET은 조회 최적화된 캐시인 셈이다. Redis가 날아가면 잠깐 랭킹이 비지만, 새 이벤트가 들어오면서 자연스럽게 다시 쌓인다. 즉시 복구가 필요하면 RDB 기반으로 배치 재구축을 돌리면 된다.
29CM이 API 응답에 score를 노출하지 않는 것도 이 맥락에서 이해가 된다. 점수 자체는 내부 구현이고, 언제든 알고리즘을 바꿀 수 있다. 클라이언트는 "이 순서대로 보여줘"만 알면 된다. 저장소가 ZSET이든 RDB든 Elasticsearch든, 프론트는 영향 없다.
결국 ZSET은 "정렬 + 실시간 갱신"에 최적화된 대신 영속성을 RDB에 위임하는 구조다. 이걸 이해하고 나면 "Redis 날아가면 어떡해?"라는 걱정이 좀 줄어든다.
3. Key 설계 — 시간을 어떻게 다룰 것인가
저장소로 ZSET을 선택했으니, 이제 구체적인 사용법을 정해야 한다. ZINCRBY로 점수를 넣는 건 해결됐고, 다음 질문은 "어떤 키에 넣을 것인가"다. 이 키 설계에서 시간이라는 변수가 들어온다.
상황: 어제의 인기 상품이 영원히 1위
ranking:all 하나의 키에 점수를 계속 누적하면 어떻게 되나?
29CM에서 6개월간 누적 조회 50,000을 기록한 르메르 백과, 오늘 하루 인스타 바이럴을 타서 500을 기록한 탬버린즈 퍼퓸이 있다고 치자. 르메르가 항상 위에 있다. 오늘의 트렌드를 보여줘야 하는 BEST 페이지에서 이건 문제다.
도서관 인기 도서 랭킹을 개관 이후 전체 대출 횟수로 매기는 것과 같다. 해리포터가 20년간 1위를 독식하고, 이번 주 화제작은 영원히 상위에 오를 수 없다.
고민: 시간 윈도우를 어떤 단위로 끊을 것인가
키를 분리하면 된다는 건 금방 떠올렸다. 문제는 어떤 단위로 끊느냐다.
29CM의 API를 다시 보니 답의 힌트가 있었다. periodFacetInput.type이 HOURLY / DAILY / WEEKLY / MONTHLY 4가지를 지원한다. 시간 단위를 하나만 고르는 게 아니라 여러 단위를 동시에 제공하고 있었다.
각 단위의 트레이드오프를 생각해봤다.
시간별 키 (ranking:all:2026041015): 트렌드 반영이 가장 빠르다. 근데 오후 3시에 BEST 페이지를 열면 3시 키에 데이터가 10건밖에 없다. 20개 상품 중 이벤트가 들어온 3개만 랭킹에 뜨고 나머지는 빈 화면. 29CM이 HOURLY를 지원하는 건 아마 충분한 트래픽이 있으니까 가능한 거다.
주간 키 (ranking:all:2026W15): 안정적이지만 월요일에 터진 바이럴 상품이 금요일에야 상위에 올라온다. 트렌드를 반영하기엔 느리다.
일별 키 (ranking:all:20260410): 하루 동안의 이벤트가 충분히 쌓이면서도, 어제의 트렌드가 오늘을 지배하지 않는다. 학습 프로젝트 규모(20개 상품)에서는 이게 가장 적절한 단위라고 판단했다.
29CM은 4가지를 다 제공하지만, 그건 트래픽 규모가 있으니까 가능한 거고, 서비스 초기나 소규모 서비스에서는 일별 하나로 시작하는 게 현실적이다. 필요하면 나중에 주간/월간을 추가하면 된다.
해결: 일별 키 + TTL + 콜드 스타트 보완
ranking:all:20260410 ← 오늘
ranking:all:20260409 ← 어제
ranking:all:20260408 ← 그제 (TTL 만료 → 자동 삭제)
일별 키 ranking:all:20260410. TTL은 약 48시간.
TTL을 왜 24시간이 아니라 48시간으로 잡았냐면, 두 가지 이유가 있다.
첫째, "어제의 BEST"를 조회할 수 있어야 한다. "어제 뭐가 인기 있었지?"라는 질문에 답하려면 어제 키가 남아있어야 한다.
둘째, 콜드 스타트 때문이다. 자정이 되면 ranking:all:20260411이 새로 생기는데, 당연히 비어있다. 새벽 1시에 "오늘의 인기상품"을 열면 아무것도 안 뜬다. 이 빈 랭킹 상태가 새벽 내내 계속된다.
해결책으로 ZUNIONSTORE를 써서 전날 점수의 일부를 다음날 키에 복사한다.
ZUNIONSTORE ranking:all:20260411 1 ranking:all:20260410 WEIGHTS 0.1트레이드오프: carry-over 비율과 실행 시점
이 10%라는 숫자도 고민이 됐다.
0%면? 자정에 완전 리셋. 깔끔하지만 새벽 내내 빈 랭킹이다. 29CM이 새벽에도 접속자가 꽤 있는 서비스라면 이건 좀 곤란하다.
50%면? 어제 1위가 오늘도 거의 1위로 시작한다. 콜드 스타트 문제는 없지만, 그러면 "오늘의 트렌드"를 보여주겠다면서 어제의 관성이 반나절을 지배한다. 키를 분리한 의미가 퇴색된다.
10%면? 새벽에 빈 화면은 피하면서도, 오전 중으로 오늘의 이벤트가 어제의 잔재를 충분히 밀어낸다. 정확한 숫자는 서비스의 트래픽 패턴에 따라 조정해야 한다. 새벽 트래픽이 거의 없는 서비스라면 5%로도 충분하고, 24시간 트래픽이 고른 서비스라면 20%가 나을 수도 있다.
실행 시점을 자정이 아니라 23:50으로 잡은 이유도 있다. ZUNIONSTORE는 목적지 키를 통째로 덮어쓰기 때문이다. 만약 자정 이후 00:05에 실행하면, 0:00~0:05 사이에 새벽 쇼핑족이 발생시킨 이벤트가 이미 내일 키에 쌓여있는데, ZUNIONSTORE가 그걸 덮어써버린다. 10분 먼저 실행하면 아직 내일 키에 이벤트가 없으니 안전하다.
4. DB-Redis 정합성 — 의도적으로 포기하는 정확도
여기까지 오면 파이프라인 전체가 보인다. Score 공식이 정해졌고(§1), ZSET에 저장하기로 했고(§2), 일별 키로 시간을 끊는다(§3). 이제 남은 건 이벤트가 발생했을 때 데이터가 실제로 흘러가는 경로다. 여기서 두 저장소 — RDB와 Redis — 사이의 정합성 문제가 등장한다.
상황: 한 이벤트, 두 곳에 쓰기
사용자가 상품을 조회하거나 구매하면:
1. DB의 product_metrics에 기록 (@Transactional)
2. Redis ZSET에 ZINCRBY 실행
문제는, Redis 연산은 Spring @Transactional 밖에 있다는 것이다.
고민: DB는 성공했는데 Redis가 실패하면?
이런 시나리오를 생각해봤다. 탬버린즈 퍼퓸에 View 이벤트 100건이 들어왔는데, 그 중 3건에서 Redis 커넥션이 순간적으로 끊겼다고 치자.
DB에는 View 100건이 정확히 기록됐지만, ZSET에는 97건만 반영됐다. 탬버린즈의 ZSET 점수가 실제보다 0.3점 낮다 (3건 × 0.1). 전체 점수가 145.8인 상황에서 0.3점 — 0.2% 오차다.
이게 문제가 되나? 결제 금액이었다면 3건 누락은 난리가 나겠지만, 랭킹에서 탬버린즈가 1위 대신 잠깐 2위가 됐다가 다음 이벤트 몇 건 들어오면 자연스럽게 복구된다.
처음에는 "분산 트랜잭션으로 묶어야 하나?" 싶었다. 2PC(Two-Phase Commit)를 쓰면 DB와 Redis가 항상 일치하도록 보장할 수 있다. 그런데 2PC의 비용을 생각해보면:
- 매 이벤트마다 prepare → commit 2번 왕복
- Redis나 DB 어느 한쪽이 느려지면 전체가 느려짐 (가장 느린 참가자 속도에 수렴)
- Coordinator 장애 시 전체 블로킹
0.2% 오차를 막겠다고 모든 이벤트에 이 비용을 지불할 것인가?
해결: Eventual Consistency — "대략 맞으면 된다"
| 데이터 | 정합성 요구 | 전략 | 이유 |
|---|---|---|---|
| 결제 금액 | 1원도 틀리면 안 됨 | Strong Consistency | 돈은 정확해야 한다 |
| 재고 수량 | 초과 판매 방지 | Pessimistic Lock | 마이너스 재고는 사고다 |
| 랭킹 순위 | 대략 맞으면 됨 | Eventual Consistency | 3위가 잠깐 4위여도 아무도 모른다 |
Redis 실패 시 로그만 남기고 넘어간다. 다음 이벤트에서 자연스럽게 보정된다. 도서관 인기 순위를 집계하는데 은행 수준의 정합성을 요구하는 건 오버다.
트레이드오프: "대략"의 범위를 정하기
다만 "대략 맞으면 된다"가 모든 실패를 무시해도 된다는 뜻은 아니다.
Redis가 3건 누락하는 건 괜찮다. 근데 Redis가 1시간 동안 죽어있었다면? 그 사이 수천 건의 이벤트가 ZSET에 반영 안 됐다면 랭킹이 심하게 어긋난다.
그래서 두 가지 안전장치를 생각했다.
1) 실패 로그 모니터링: Redis ZINCRBY 실패율이 일정 임계값(예: 분당 10건)을 넘으면 알림을 쏜다. 단건 실패는 무시하되, 연속 실패는 Redis 장애 징후이므로 대응이 필요하다.
2) 정기 보정 배치: 하루에 한 번, RDB의 product_metrics 기준으로 ZSET 점수를 재계산하는 배치를 돌린다. 이러면 누적 오차가 24시간 이상 지속되지 않는다. 어차피 일별 키를 쓰니까, 새 키를 만들 때 RDB 기준으로 초기화하면 자연스럽게 보정된다.
결국 Eventual Consistency의 핵심은 "얼마나 eventual인가"의 범위를 명시적으로 정하는 것이다. "대략 맞으면 됨"이 면죄부가 아니라, "단건 실패는 허용하되, 1시간 이상의 불일치는 자동 복구한다"처럼 구체적인 기준이 필요하다.
마무리- 결국 29CM보다 나은 랭킹 시스템은 만들지 못했다
학습용 프로젝트의 최종 랭킹 보드. 20개 상품 × 4,069건 이벤트의 결과.
솔직히 말하면, 29CM보다 나은 랭킹 시스템은 만들지 못했다. 애초에 만들 수 있을 거라 생각한 것 자체가 문제였다.
처음에 F12를 눌렀을 때는 "별거 아니네, 나도 만들 수 있겠는데?"라는 자신감이 있었다. 가중치 공식 하나 만들고 ZSET에 넣으면 되는 거 아닌가? 그런데 직접 만들어보니, 매 단계에서 생각이 틀렸다.
| 단계 | 내가 생각한 것 | 직접 부딪혀보니 |
|---|---|---|
| §1 Score 설계 | 가중치만 잘 잡으면 된다 | 스케일이 안 맞으면 가중치는 무의미했다 |
| §1 랭킹 분리 | 인기와 매출을 하나의 공식으로 섞으면 된다 | 29CM이 POPULARITY와 SALES를 분리한 이유를 체감했다 |
| §3 시간 단위 | 시간 단위 하나만 정하면 된다 | HOURLY/DAILY/WEEKLY/MONTHLY 4가지가 필요한 이유가 있었다 |
| §0 세분화 | 전체 랭킹 하나면 된다 | 성별 × 연령 × 카테고리 세분화 없이는 의미 있는 "인기"를 정의할 수 없었다 |
| §4 정합성 | DB-Redis 정합성을 완벽히 맞춰야 한다 | 3위가 잠깐 4위여도 아무도 모른다는 걸 깨달았다 |
29CM이 5차원으로 랭킹을 쪼갠 건 과잉 설계가 아니었다. 하나의 Score 공식으로 "인기 상품"을 정의하려는 순간 매출과 관심도가 충돌하고, 시간 윈도우 하나로 "오늘의 트렌드"를 잡으려는 순간 서비스마다 적절한 단위가 다르다. "인기"라는 질문 자체가 단일 답을 가질 수 없기 때문에, 5차원으로 쪼갤 수밖에 없었던 거다. 그 안에서 아마 내가 모르는 수많은 테스트가 있었을 거 같다. A/B테스트나 뭔가 다양한 수치를 잡을 수 있는 방법론이 있을 거 같다는 생각도 든다.
결국 랭킹 시스템 설계 판단에는 항상 "이 도메인에서 무엇을 포기할 수 있는가?"라는 질문이 먼저라는 것을 느꼇다. 정확도를 포기할 수 있으면 Eventual Consistency로 시스템이 단순해지고, 금액 스케일을 포기할 수 있으면 log 정규화로 의미 있는 랭킹이 나온다. 시간 정보를 포기하면 키 관리가 단순해지지만 트렌드를 잃는다. 모든 걸 다 잡으려면 29CM처럼 5차원이 되는 전략을 선택할 수도 있고, 그게 비지니스에서 원하는 복잡도 라는 것을 느꼈다.
