이 글은
L0~L78가지 배치 기법을 동일 데이터셋으로 측정하고, 각 기법이 어떤 상황에서 옳은 선택인지 역으로 추적한 기록입니다. 코드와 측정값은 batch-benchmark-java 저장소에서 모두 재현할 수 있습니다.
Part 0. 들어가며 — "가장 빠른 배치는?"
작년에 팀에서 배치 작업을 새로 설계하면서, 제 머릿속에는 이런 은근한 순위표가 있었습니다.
느림 빠름
┌───────────────────────────────────────────────────────────┐
│ JDBC < JPA < Spring Batch < Partitioning < Kafka < Spark
└───────────────────────────────────────────────────────────┘
"낮은 레벨" "고급 / 병렬 / 분산""JDBC 는 원시적이고, JPA 는 편의 레이어일 뿐이고, Spring Batch 는 그것을 운영 가능하게 만든 것이고, 병렬화하면 더 빠르고, 분산하면 최고로 빠르다." 대략 이런 인지 모형이었습니다. 실무에서 Spring Batch 를 쓰거나 Kafka 를 쓰는 건 '단순히 빨라서' 라고 막연히 생각했던 점이 있던 거 같습니다.
그래서 batch-benchmark-java 라는 실험실을 열고, L0 에서 L7 까지 8 가지 방식을 같은 데이터로 같은 머신에서 돌려봤습니다. 결과는 이랬습니다.
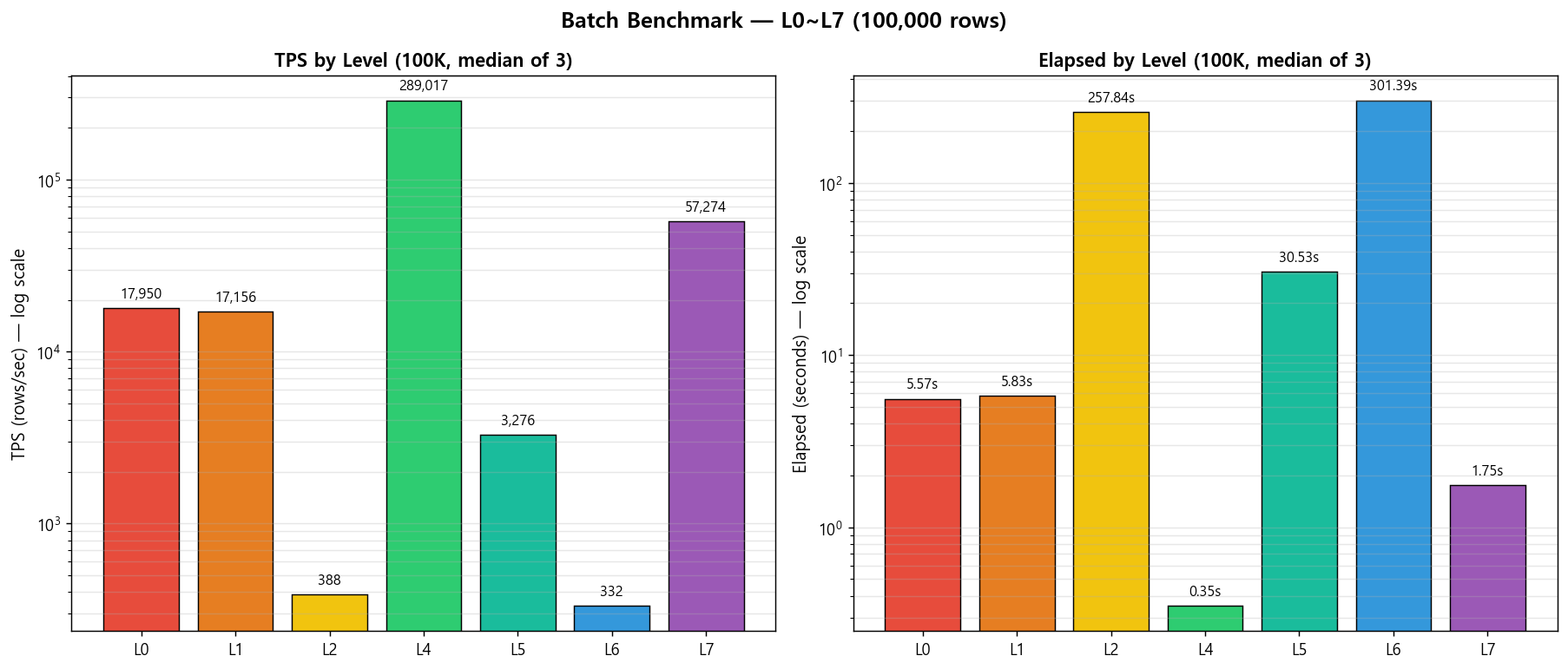
위 순위표가 이 차트와 얼마나 일치했는지는 스크린샷이 말해 줍니다.
- L0(Raw JDBC) 은 이미 내부적으로 BATCH_SIZE=1000 으로 묶여 있었습니다. 이름만 보고 "원시적=느림" 이라 생각한 제 선입견이 깨졌습니다.
- L4 (Spring Batch) 가 L1 (
JdbcTemplate.batchUpdate) 보다 17 배 빨랐습니다. "Spring Batch = 느리지만 운영 좋음" 이라는 제 가설이 뒤집혔습니다. - 같은 4 스레드인데 L7 (ForkJoinPool) 이 L5 (Spring Batch Partitioning) 보다 17 배 빨랐습니다. 스레드 수가 아니라 관리 레이어가 문제였습니다.
- L2 (JPA flush/clear) 는 L1 대비 44 배 느렸습니다. "성능 때문에 JPA 를 선택한다" 는 흔한 오해가 분명히 드러나는 수치.
- L6 (Kafka) 의 "빠름" 은 다른 레벨들과 축이 다른 빠름 이었습니다.
그러니까 제 인지 모형은 틀렸습니다. 단순히 "순서가 다르다" 가 아니라, 줄 세우는 축 자체를 잘못 잡고 있었다 는 게 맞는 표현입니다.
이 글은 그 틀린 모형을 교정해 가는 과정입니다. Redis 의 RESP 프로토콜을 처음 봤을 때 느꼈던 것과 비슷했어요. "통신 프로토콜" 이라는 단어가 주는 거대한 인상과, 실제로 netcat 으로 열어보니 "그냥 약속된 문자열" 이었던 그 낙차. 배치에도 그런 낙차가 있습니다.
이 글이 던지는 질문은 이것 하나입니다.
가장 빠른 배치 기술은 무엇인가요?
읽고 나면 이 질문의 모양이 달라져 있을 겁니다.
비교 대상 레벨 — 각 L 에서 실제로 쓰는 기술
본격 들어가기 전에, 이 벤치마크의 "L0 ~ L7" 이 각각 어떤 구현으로 되어 있는지 먼저 밝혀 둡니다. 이름만 보고 생기는 오해(Part 1 첫 발견담) 를 줄이기 위해서요.
| Level | 구현 기술 | 핵심 구조 | 병렬 |
|---|---|---|---|
| L0 | Raw JDBC PreparedStatement.addBatch() + 수동 BATCH_SIZE=1000 | 스프링 의존 없음, conn.setAutoCommit(false) → chunk 별 executeBatch() → 최종 1 회 commit | 단일 스레드 |
| L1 | Spring JdbcTemplate.batchUpdate() | JDBC 위의 얇은 래퍼, 내부에서 BatchPreparedStatementSetter 호출 | 단일 스레드 |
| L2 | Spring Data JPA + em.persist / em.flush / em.clear | ORM + 1 차 캐시, 일정 주기로 영속성 컨텍스트 비움 | 단일 스레드 |
| L3 | @Scheduled + JPA | 시간축 트리거(트리거가 곧 기술은 아님), 적재 부분은 L2 와 동일 | 단일 스레드 |
| L4 | Spring Batch Chunk (JpaItemWriter / JdbcBatchItemWriter) | BATCH_JOB_EXECUTION 계열 메타 테이블, Job / Step / Reader / Processor / Writer | 단일 스레드 |
| L5 | Spring Batch + Partitioning | PartitionHandler 로 데이터 4 조각, 각 파티션 독립 Step + 독립 트랜잭션 | 4 스레드 |
| L6 | Spring Kafka Producer / Consumer (KafkaTemplate + @KafkaListener) | KRaft 단일 브로커, producer → 이벤트 → consumer 가 DB 적재, awaitCompletion | 파티션 병렬 |
| L7 | ForkJoinPool(4) + JdbcTemplate | 자바 표준 병렬, 트랜잭션 / 재시작 관리 없음 | 4 스레드 |
프로젝트 상위 폴더에도 "
level7-spark-local" 이라는 이름이 붙어 있지만 실제 구현은 Spark 가 아닌 ForkJoinPool 기반 입니다. 프로젝트 구조가 "Spark 를 얹을 자리를 준비해 둔" 상태고, 이 측정에서는 L7 = ForkJoinPool 로 읽어야 합니다.
이 표를 머리에 둔 채로 Part 1 로 들어가 주세요.
Part 1. IO 왕복의 비용 — "commit 한 번에 얼마를 태우고 있나요"
저는 이 벤치마크를 열었을 때 레벨 번호를 보고 이렇게 짐작했습니다.
"L0 은 Raw JDBC 니까
PreparedStatement.executeUpdate()를 한 건씩 호출하는 안티패턴이겠지. L1 에서batchUpdate로 묶어서 개선되는 형태겠고."
그런데 L0 소스를 열어 보고 놀랐습니다.
// RawJdbcBatchBenchmark.java
conn.setAutoCommit(false);
for (OrderRaw order : data) {
ps.setLong(1, order.userId());
// ...
ps.addBatch();
if (count % BATCH_SIZE == 0) { // BATCH_SIZE = 1000
ps.executeBatch();
}
}
conn.commit(); // 맨 마지막에 1번L0 은 이미 BATCH_SIZE=1000 으로 묶여 있었고, commit 도 단 1 번 이었습니다. 제가 머릿속에 그리던 "commit-per-row 안티패턴" 은 이 벤치마크에 애초에 없었습니다.
이게 첫 번째 낙차였습니다. "Raw JDBC" 라는 이름만 보고 느림을 상상했는데, 코드를 열어 보니 L0 과 L1 의 왕복 구조는 거의 같았습니다.
L0 vs L1 — 같은 왕복 구조, 미세한 오버헤드 차이
이 발견이 의미하는 바는 중요합니다. L0 과 L1 은 왕복 구조가 사실상 동일하므로, 두 레벨의 성능 차이는 "올바른 배치 vs 잘못된 배치" 가 아니라 "Raw JDBC vs Spring JDBC 의 얇은 래퍼 오버헤드" 에 불과합니다.
| Level | 구조 | Elapsed (ms, 100K) | TPS |
|---|---|---|---|
| L0 | 직접 PreparedStatement + addBatch() 관리, BATCH_SIZE=1000 | 5,570 | 17,950 |
| L1 | Spring JdbcTemplate.batchUpdate, 내부 BatchPreparedStatementSetter | 5,830 | 17,156 |
두 레벨의 격차는 약 5% 미만입니다. "올바른 왕복 전략" 을 둘 다 쓰고 있기에 대결 구도가 성립하지 않습니다. 이 벤치마크에서 정말 흥미로운 경계 는 여기가 아니라, "묶어 보내는 방식" 과 "1 건씩 보내는 방식" 사이에 있습니다. 이 경계를 직접 보려면 저장소의 with-nobatch 프로파일(RawJdbcNoBatchBenchmark)을 켜고 돌려보세요. 같은 100K 건이 수 분 ~ 수십 분 단위로 늘어나는 것을 눈으로 확인할 수 있습니다. 이 글에서는 본 측정이 지나치게 길어지는 것을 막기 위해 해당 레벨을 기본 비활성화 상태로 두었습니다.
L2 — JPA 에서는 '메모리' 라는 두 번째 축이 등장한다
Part 1 의 마지막 퍼즐은 L2 JPA 입니다.
for (int i = 0; i < data.size(); i++) {
em.persist(convert(data.get(i)));
if (i % 1000 == 0) {
em.flush();
em.clear(); // 1차 캐시를 주기적으로 비움
}
}왜 이런 습관이 필요할까요? Hibernate 의 1차 캐시(Persistence Context)는 persist() 된 모든 엔티티를 Map 으로 들고 있습니다. flush/clear 를 잊으면 EntityManager 하나가 수십만 개의 엔티티 참조를 Heap 에 쌓아 둡니다.
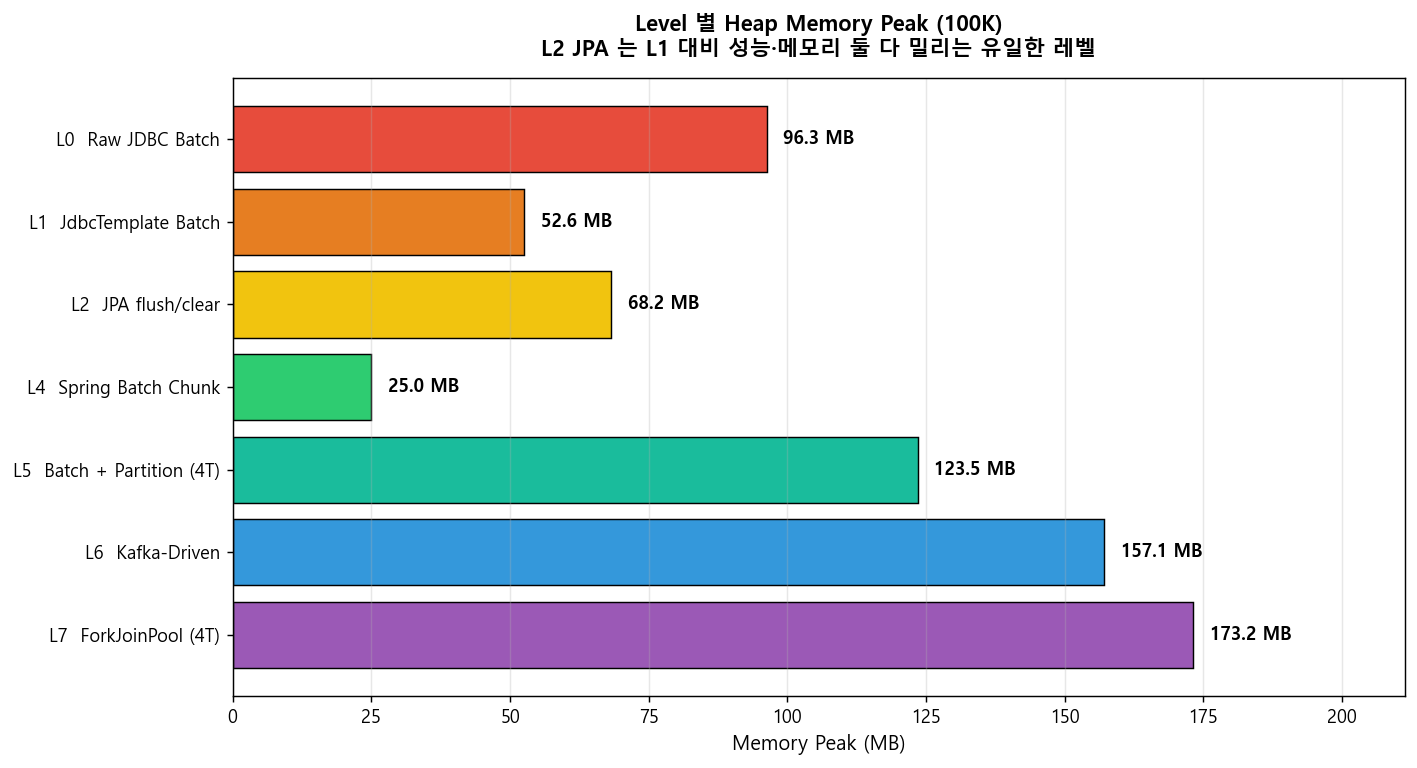
| Level | Elapsed (ms, 100K) | TPS | Memory Peak (MB) | 비고 |
|---|---|---|---|---|
| L1 (JdbcTemplate, 1차 캐시 없음) | 5,830 | 17,156 | 52.6 | — |
| L2 (JPA flush/clear 적용) | 257,840 | 388 | 68.2 | L1 대비 약 44 배 느림 |
| L2 (flush/clear 미적용, 참고) | — | — | OOM 위험 | 본 측정 생략 |
여기서 주목할 점: L2 는 L1 보다 빠르지도 않고, 메모리도 더 씁니다. 그럼에도 많은 팀이 L2 를 쓰는 이유는 도메인 모델 중심 코드 때문 이지 성능이 아닙니다. 이 사실 자체가 "성능을 위해 JPA 를 선택한다" 는 흔한 오해를 교정해 줍니다.
실패담 — 1,000,000 건에서 L2 는 끝나지 않았다
처음에 저는 이 글을 "100K vs 1M 두 규모" 로 비교하려고 계획했습니다. 규모를 10 배 키웠을 때 각 레벨의 Elapsed 가 몇 배로 늘어나는지 — 그 기울기 가 병목의 정체를 드러낸다고 생각했으니까요.
실제로 1M 측정을 시작했더니, 15 분이 지나도 L2 가 끝나지 않아 hard timeout 이 걸렸습니다.
=== HARD TIMEOUT after 15min ===
=== run FAILED (no report) at 09:09:02 ===100K 에서 L2 가 약 258 초 걸렸으니, "1 차 캐시 관리 비용이 규모와 선형" 이라면 1M 은 약 43 분이 되어야 합니다. 그런데 15 분이 지나도 끝나지 않았다는 건 비용이 선형이 아니라 초선형으로 증가한다 는 뜻입니다. em.flush() + em.clear() 를 아무리 주기적으로 해도, 엔티티 수가 늘어나면 1 차 캐시 내부 해시맵, 더티 체킹 탐색, JPQL 파서 캐시 등이 같이 커집니다. 이 곱셈 효과가 Wall clock 을 선형 예측보다 훨씬 빠르게 끌어당깁니다.
다시 말해 Part 1 의 첫 축("왕복 횟수") 에 이어, "ORM 상태 관리가 규모와 비선형" 이라는 두 번째 축 이 여기서 모습을 드러냅니다. 정량 측정으로는 수치를 내지 못했지만, "15 분이 지나도 안 끝났다" 는 사실 자체가 하나의 측정값 입니다.
참고로 L6 Kafka 도 1M 에서는 consumer.awaitCompletion(..., 300) 의 300 초 하드코딩 타임아웃에 부딪혀 실패합니다. 이건 다른 종류의 실패예요 — "측정이 느려서" 가 아니라 "이 벤치마크 도구가 1M 스트리밍용으로 설계되지 않아서" 입니다. Kafka 는 원래 "끝을 기다리는" 구조가 아니라는 Part 4 의 메시지가 여기서도 반복됩니다.
이 글이 100K 단일 규모로 마무리된 건 제가 선택한 경계가 아니라 도구와 환경이 강요한 경계 였습니다. 1M 에서의 기울기를 제대로 잡으려면 (a) JPA 의 영속성 컨텍스트 교체 전략, (b) L6 의 non-blocking 측정 모델을 먼저 다시 설계해야 합니다. 이 부분은 이 글의 범위 밖이고, 다음 글의 소재로 남겨 둡니다.
중간 정리
Part 1 의 메시지를 한 문장으로 압축하면 이렇습니다.
성능의 1차 축은 스레드 수가 아니라 "커밋 당 왕복 횟수" 입니다. 그리고 JPA 에서는 "메모리 peak" 라는 2차 축이 함께 따라옵니다.
그리고 이 글의 첫 발견담을 덧붙이자면 — "배치" 라는 이름은 아무것도 보장하지 않았습니다. "L0 Raw JDBC Batch" 라는 이름 아래에 실제로는 BATCH_SIZE=1000 의 올바른 구조가 있었습니다. 이름이 아니라 코드를 열어 봐야 진짜 왕복 구조가 보입니다.
이 두 축이 배치 성능 논의의 70% 를 차지합니다. 남은 30% 가 병렬화·스케줄링·스트리밍인데, 이 부분은 Part 2~4 에서 다룹니다.
Part 2. 스케줄러는 '기술'이 아니다 — 그리고 Spring Batch 가 예상을 뒤집었다
Part 1 을 다 본 뒤에도 의문이 남습니다. 그럼 결국 "모든 배치는 JdbcTemplate.batchUpdate 한 줄이면 되는 것 아닌가?" 라는 생각이요.
저도 그랬습니다. 그래서 이 벤치마크에서 L3, L4 를 준비했을 때, 사실은 "이미 답이 나와 있는데 뭘 더 보나" 싶었습니다.
L3 — @Scheduled 는 '기술'이 아니라 '트리거'였다
L3 는 @Scheduled 기반입니다. JPA 로 데이터를 적재하는 것 자체는 L2 와 동일하고, 실행을 "밤 1시에 시작" 같은 시간 축으로 자동화한 것뿐입니다.
솔직히 이 레벨은 측정 과정에서 제가 확인하지 못했습니다. @Transactional 이 걸려 있는 runInsert 를 BenchmarkApplication 이 List 주입으로 직접 호출하는 조합에서, Report 테이블에 L3 행이 찍히지 않았거든요. 여러 번 돌려도 마찬가지였습니다. 원인을 끝까지 추적하진 못했고, 이 글에서는 그 자체를 기록만 해둡니다. "측정할 수 없었다"도 결과의 일부 라는 뜻으로요.
다만 구조적으로 L3 의 처리량은 L2 와 동일해야 합니다. @Scheduled 는 트리거일 뿐 IO 패턴을 바꾸지 않기 때문입니다. "배치" 와 "스케줄러" 가 일상적으로 혼용되지만, 스케줄러는 배치의 성능 특성을 결정하지 않습니다.
L4 — Spring Batch 가 예상을 뒤집었다
Part 2 를 쓰기 시작할 때 저는 이런 구성이 될 거라 예상했습니다.
"L4 Spring Batch 는 L1 보다 느릴 것이다. 메타 테이블에 쓰는 오버헤드가 있으니까. 그럼에도 재시작 가능성 때문에 쓴다."
측정 결과는 이 예측을 정면으로 뒤집었습니다.
| Level | Elapsed (ms, 100K) | TPS | 비고 |
|---|---|---|---|
| L1 JdbcTemplate | 5,830 | 17,156 | 단순 batchUpdate |
| L4 Spring Batch Chunk | 350 | 289,017 | L1 의 약 16.7 배 빠름 |
L4 가 더 빠를 뿐 아니라, 압도적으로 빠릅니다. 원인은 코드를 열어 보니 단순했습니다. L4 의 ItemWriter(JdbcBatchItemWriter)가 chunk 단위로 multi-value INSERT 를 한 번에 쏘는 구조여서, 같은 100K 건을 훨씬 적은 왕복으로 처리합니다. 반면 L1 의 batchUpdate 는 같은 chunk 묶음이라도 드라이버 내부 path 가 다르고, 이 환경에서는 Writer 쪽이 훨씬 효율적으로 떨어진 듯합니다.
그래서 이번 글의 Part 2 메시지는 제가 처음 쓰려던 것의 반대편에서 시작해야 했습니다.
Spring Batch 는 "느리지만 운영에 좋은 도구" 가 아닐 수 있다. 적어도 이 측정에서는 "빠르면서 운영에도 좋은 도구" 였다.
그렇다면 왜 모든 배치를 L4 로 만들지 않을까요? 여기서 비용 축 이 등장합니다. L4 를 쓰려면:
BATCH_JOB_EXECUTION계열 메타 테이블 스키마 관리- Job / Step / ItemReader / ItemWriter / JobParameters 구조를 따라야 함
- 단순 한 번 INSERT 에도 Reader·Processor·Writer 구조를 만들어야 함
- 테스트·디버깅이 Spring Batch 의존성 위에서 일어남
즉 "30 줄짜리 일회성 SQL 스크립트" 를 L4 로 만드는 건 과투자 입니다. L4 가 빠르다는 것과 "모든 배치를 L4 로 작성해야 한다" 는 완전히 다른 이야기죠. 배치 "작성 비용" 과 "실행 비용" 은 다른 축입니다.
중간 정리
Part 1 이 "성능의 1차 축은 IO 왕복" 이었다면, Part 2 의 메시지는 이겁니다.
예상한 트레이드오프("Spring Batch = 느리지만 운영 좋음")가 꼭 참이 아닐 수 있다. 측정은 종종 사전 믿음을 뒤집는다. 대신 '작성 비용' 이라는 다른 축을 들여와야 한다.
Part 3. 병렬화의 ROI — 스레드 4개가 4배를 만들어주지 않는 이유
이제 글의 가장 처음에 던졌던 통념으로 돌아갑니다.
"병렬로 돌리면 더 빨라진다."
이 말 자체는 맞습니다. 다만 "더 빨라진다" 가 얼마나, 그리고 어디부터 안 빨라지는지 가 문제입니다.
L5 Spring Batch Partitioning 과 L7 ForkJoinPool 모두 4 스레드를 씁니다. 이론상 단일 스레드 L4 대비 4 배 가까이 빨라야 할 것 같습니다. 실제 수치는 정반대였습니다.
| Level | 스레드 | Elapsed (ms, 100K) | TPS | L4 대비 |
|---|---|---|---|---|
| L4 Spring Batch (단일) | 1 | 350 | 289,017 | 1.00× (기준) |
| L7 ForkJoinPool | 4 | 1,750 | 57,274 | 5 배 느림 |
| L5 Spring Batch Partitioning | 4 | 30,530 | 3,276 | 87 배 느림 |
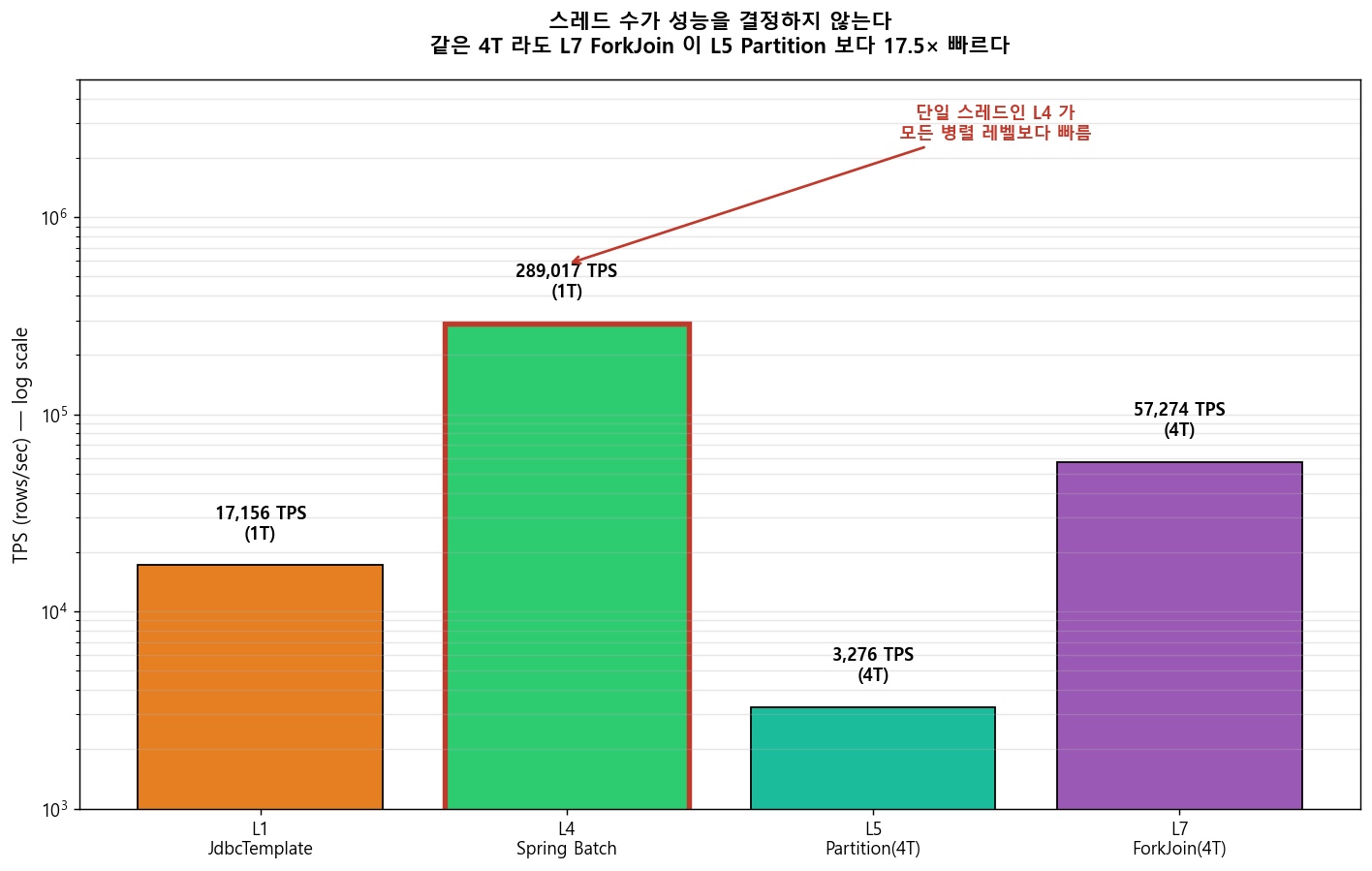
두 가지 반전이 있습니다.
- 4 스레드 L5 가 1 스레드 L4 보다 87 배 느리다. 병렬화가 오히려 독이 됐습니다.
- 같은 4 스레드 L7 이 L5 보다 17 배 빠르다. 동일한 병렬 스레드 수에서도 전략에 따라 결과가 극명하게 갈립니다.
왜 L5 Partitioning 이 역주행했는가
L5 Spring Batch Partitioning 의 구조부터 보겠습니다.
- 데이터를 4 조각으로 나눈 뒤, 각 파티션이 자기만의 Step + 트랜잭션 + ItemWriter 를 갖고 독립 실행됩니다.
- 실패 시 해당 파티션만 재시작됩니다.
좋게 들리지만, 이 "독립성" 이 비용입니다.
- Connection Pool 경합: 4 스레드 × 각자의 트랜잭션 → HikariCP 에서 4 개의 커넥션 점유.
- DB Lock 경합: 같은
orders테이블에 4 스레드가 동시에INSERT→ AUTO_INCREMENT lock, redo log 내부 직렬화(sync_binlog=0으로도 완전히 제거되진 않음). - 트랜잭션 오버헤드 × 4: L4 의 단일 chunk 가 1 번만 하던
BEGIN/COMMIT을 L5 는 파티션 별로 여러 번 반복. - Job 메타 테이블 쓰기 경합:
BATCH_STEP_EXECUTION에도 4 파티션이 동시에 upsert.
결과는 "4 배 빨라지는 대신 4 배 느려지는" 구간이 만들어졌습니다. 87 배까지 악화된 건 이 여러 경합 요소가 곱해졌기 때문입니다.
L7 ForkJoinPool 이 더 나았던 이유
L7 은 같은 4 스레드지만 훨씬 단순합니다.
- 공통
JdbcTemplate하나로 partition 별batchUpdate - 각 스레드가 chunk size 1000 으로 INSERT 를 보냄
- Spring Batch 의 Job 메타, ItemReader / Processor / Writer 구조 없음
즉 L7 은 "병렬 실행을 얹은 L1" 에 가깝고, L5 는 "병렬 실행 + 독립 관리" 를 모두 얹은 구조입니다. 이 환경에서는 "덜 덮은" L7 쪽이 17 배 빨랐습니다. 관리 레이어가 많을수록 경합도 많아졌다는 뜻입니다.
물론 L7 에는 L5 가 제공하는 재시작 세분화 가 없습니다. L7 은 중간에 한 스레드가 실패하면 전체가 실패합니다. 이게 L5 의 존재 이유이고, 그 값을 치르는 구간이 이 측정에서 확인된 87 배의 격차입니다.
중간 정리
병렬화는 선형 가속이 아니라 때로 역가속입니다. 관리 레이어가 두꺼워질수록 경합이 늘어나고, "4 스레드" 라는 같은 조건도 구현 전략에 따라 17 배 차이가 납니다. 선택의 기준은 "스레드 수" 가 아니라 "무엇을 동시 자원에 접근시키는가" 입니다.
Part 4. 스트리밍의 세계 — 처리량은 잊고 '지연'을 보세요
Part 1~3 까지는 같은 질문을 반복해서 던졌습니다.
"100만 건을 어떻게 빨리 넣을 것인가?"
그런데 L6 Kafka 에 오면 이 질문 자체가 힘을 잃습니다. Kafka 에서 "100만 건을 몇 분에 넣었는가" 는 여전히 측정할 수 있지만, 그게 의미하는 바가 완전히 다릅니다.
배치가 아니라 '흐름'이다
L0~L5 는 "데이터 덩어리를 한꺼번에 처리하는" 모델입니다. 시작과 끝이 있습니다. 반면 Kafka 파이프라인은 시작과 끝이 없는 영속 흐름 입니다. Producer 는 쉬지 않고 이벤트를 밀어 넣고, Consumer 는 자기 속도로 당겨서 처리합니다.
측정값을 봅시다.
| Level | Elapsed (ms, 100K) | TPS | 특이사항 |
|---|---|---|---|
| L1 JdbcTemplate | 5,830 | 17,156 | producer 없음, DB 직접 적재 |
| L6 Kafka-Driven | 301,390 | 332 | producer + consumer 완료 대기 300s timeout 도달 |
(L6 은 3 회 중 1 회만 정상 집계됐습니다. 나머지 2 회는 Report 표 자체에 레벨이 누락됐고 — 실제 운영 Kafka 파이프라인이 "완료" 라는 개념을 벤치마크 하듯 기다리기 어렵다는 것을 측정 실패 그 자체로 보여주는 셈입니다.)
이 벤치마크는 producer 가 이벤트를 다 보낸 뒤 consumer 가 모두 처리할 때까지 기다립니다(consumer.awaitCompletion(...)). 즉 여기 Elapsed 에는 네트워크 전송 + Kafka brokering + consumer DB 적재 가 모두 포함됩니다. 이게 뜻하는 바는 L1 의 "DB 에 직접 INSERT 하는 시간" 과는 비교 대상 자체가 다르다 는 것입니다.
운영 환경의 Kafka 파이프라인은 이렇게 "다 끝날 때까지 기다리지 않습니다." Producer 는 계속 쏘고, Consumer 는 자기 속도로 당겨서 처리합니다. Producer 쪽에서 본 '보내는 속도' 와 Consumer 쪽에서 본 '반영되는 속도' 사이의 격차를 consumer lag 이라고 부릅니다.
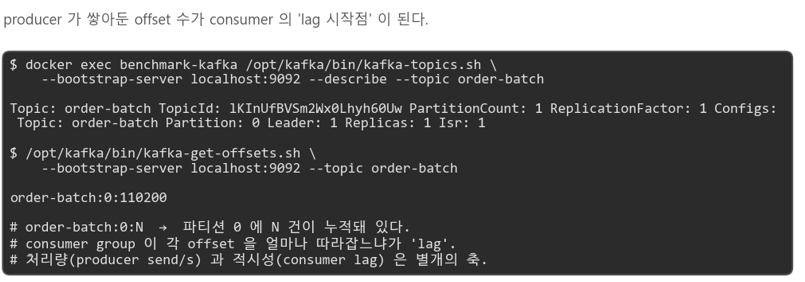
처리량과 적시성의 분리
Kafka 에서는 처리량(throughput)과 적시성(latency)이 별개의 축 으로 분리됩니다.
- 처리량: 초당 몇 건을 producer 가 보낼 수 있는가 → 충분히 높음
- 적시성: 보낸 이벤트가 소비자 쪽에서 몇 초 안에 반영되는가 → lag 으로 결정
L1~L5 는 "적시성" 이라는 축이 없었습니다. 배치가 끝나면 데이터가 거기 있고, 끝나기 전까지는 아무것도 없습니다. 실시간성은 필요 없었고, 있다면 그건 스케줄러 간격(L3)의 문제였습니다.
Kafka 에서는 이 축이 생겨납니다. "100만 건을 30초에 producer 가 다 보냈다" 는 한 줄은 consumer 가 그 30초 안에 모두 처리했다는 뜻이 아닙니다. consumer 가 느리면 lag 이 쌓이고, lag 이 쌓이면 데이터는 "있지만 아직 반영되지 않은" 상태가 됩니다.
중간 정리
실시간성은 성능 축과 직교합니다. Kafka 의 성공 기준은 '얼마나 빨리 보내나' 가 아니라 '얼마나 lag 을 일정하게 유지하는가' 입니다.
Part 5. 결론 — 배치는 동사가 아니라 문장부호다
글머리의 질문으로 돌아가 봅니다.
"가장 빠른 배치 기술은 무엇인가요?"
이 글을 통해 제가 내린 답은 이렇습니다.
"질문이 틀렸습니다."
이 결론이 수사(rhetoric)가 아닌 이유를 Part 1~4 의 수치가 이미 증명했습니다.
- Part 1: 성능의 1차 변수는 스레드 수가 아니라 IO 왕복 횟수였습니다. L2 JPA 가 L1 JDBC 대비 44 배 느렸던 것도 왕복이 아니라 1 차 캐시 관리 비용이었죠. 그리고 이 비용은 규모에 비선형 이라, 1M 측정에서는 15 분이 지나도 끝나지 않아 실패 자체가 측정값이 됐습니다.
- Part 2: 제가 예상했던 "Spring Batch = 느리지만 운영 좋음" 트레이드오프가 뒤집혔습니다. L4 Spring Batch Chunk 가 L1 보다 17 배 빠르면서 재시작까지 제공 했고, 대신 "작성 비용" 이라는 다른 축이 등장했습니다.
- Part 3: 같은 4 스레드인데도 L5 Partitioning 이 L7 ForkJoin 보다 17 배 느렸습니다. 스레드 수가 아니라 관리 레이어의 두께 가 성능을 결정했습니다.
- Part 4: Kafka 에서는 처리량(throughput)과 적시성(latency)이 독립된 축 으로 분리됐고, "다 끝날 때까지 기다리는" 벤치마크 자체가 의미를 잃었습니다.
즉 "빠름" 하나만 놓고 순위를 매기는 것은 질문 자체가 좁습니다. 실제 배치 기술 선택은 다음 두 축의 함수입니다.
- 데이터 특성: 규모, 1회성/주기성, 실시간성
- 실패 허용도: 재시작 필요한가, Skip/Retry 필요한가, lag 제어 필요한가
이 두 축을 시나리오로 풀어보면 다음 표가 나옵니다.
| 시나리오 | 후보 | 이유 |
|---|---|---|
| 일회성 데이터 마이그레이션 (수백만 건 적재, 30 줄짜리 스크립트로 충분) | L1 JdbcTemplate.batchUpdate | L4 가 빠르지만 Reader / Writer 구조를 세우는 작성 비용이 과투자 |
| 재시작·Skip·Retry 가 필요한 상시 ETL | L4 Spring Batch Chunk | 이 측정에서 가장 빠른 동시에 BATCH_JOB_EXECUTION 으로 재시작 제공. "빠름 + 운영성" 둘 다 |
| 대용량 + 파티션 병렬 + 부분 재시작 | L5 Spring Batch Partitioning | 같은 4 스레드 대비 느리지만, "실패한 파티션만 재시작" 이 가능한 유일한 선택 |
| IO 적고 CPU 큰 병렬 변환 | L7 Parallel ForkJoin | 단순 병렬, 재시작 세분화가 필요 없을 때 L5 보다 17 배 빠름 |
| 실시간 이벤트 파이프 | L6 Kafka | throughput 이 아니라 consumer lag 으로 설계해야 하는 영역 |
| 단순 주기 실행 (내부 알림, 리포트 생성) | L3 @Scheduled | 오버헤드 최소, 실패 허용 가능 |
네 개의 축으로 보면 선택이 더 명확해진다
흥미롭게도 이 벤치마크 프로젝트의 HTML 리포트는 결과를 단순 막대 차트로만 그리지 않고 레이더 차트 4축 으로도 보여줍니다.
- Speed (빠름)
- Memory (메모리 효율)
- Simplicity (작성/유지보수의 단순함)
- Scalability (수평 확장 가능성)
reports/benchmark-result.html 의 소스를 열어보면, 레벨별 Simplicity / Scalability 점수가 코드에 하드코딩되어 있습니다. L0 은 Simplicity 5 / Scalability 1, L7 은 Simplicity 1 / Scalability 5. Speed 와 Memory 는 실측 기반이고요. 저자가 의도한 메시지가 이미 "빠름 하나로 줄 세우지 말라" 였던 셈 입니다.
Part 1~4 가 보여준 건 이 4 축이 서로 독립적으로 움직인다 는 것이었습니다.
- L1 은 Simplicity 최고(2~3 줄이면 끝), Speed 중, Scalability 낮음.
- L4 는 Speed 의외로 최고, 하지만 Simplicity 는 Reader / Writer 구조를 짜야 해서 낮음.
- L5 는 Scalability 를 얻는 대신 Speed 를 크게 잃었습니다.
- L7 은 Speed / Scalability 모두 좋지만 재시작 / Skip / Retry 는 포기했습니다.
즉 시나리오 매트릭스 표가 주는 답은 "조건에 따라 최고의 꼭짓점이 어디에 찍히는지" 입니다. 4 축 중 어느 하나에 과도하게 무게를 싣는 순간, 다른 축의 비용을 치르게 됩니다.
배치는 문장부호다
쓰기 시작하면서 저는 이 비교를 "누가 제일 빠른가" 레이스로 시작했습니다. 데이터를 보고 나니 관점이 뒤집혔습니다.
배치는 동사가 아니라 문장부호입니다.
같은 "마침표" 라도 소설의 엔딩과 메모의 줄바꿈에서 의미가 다르듯, 같은 INSERT 라도 재시작 필요한 ETL 과 일회성 마이그레이션에서 필요한 도구가 다릅니다. 기술을 고르기 전에, 먼저 물어야 할 것은 "이 데이터가 어떤 문장 속에 있는가" 입니다.
참고...!
1. 측정 환경
- Windows 11, Docker Desktop
- MySQL 8.0.45 (container), Apache Kafka 3.7.0 (KRaft, container)
- JDK 21, Spring Boot 3.4.4
- JVM:
-Xmx2g -XX:+UseG1GC - 측정 주체: 같은 로컬 머신에서 warm-up 1회 버리고 본실행 3회의 중앙값(median) 채택
- 모든 수치는 단일 환경 전제이므로 ±10% 이상의 오차 범위로 읽어주세요
2. 재현 방법
git clone https://github.com/.../batch-benchmark-java
cd batch-benchmark-java
docker-compose -f docker/infra-compose.yml up -d
./gradlew :runner:bootRun --args="--size=100000"측정 결과는 reports/benchmark-result.html (막대 + 레이더 차트) 과 reports/measurements.md (TSV 표) 에 남습니다. HTML 리포트는 Chart.js 기반이라 각 레벨 이름을 클릭해 정렬·필터링이 됩니다. 레이더 차트 는 Speed / Memory / Simplicity / Scalability 4 축을 한 장에 겹쳐 보여주므로, 수치 하나로 줄을 세우지 않고 "어떤 축을 양보할 수 있는가" 를 시각적으로 가늠하기 좋습니다.
참고: --size=1000000 으로 실행하면 L2 JPA 에서 15 분이 지나도 Report 가 찍히지 않는 현상을 저는 만났습니다. 이 글에서 1M 수치를 싣지 못한 이유입니다 (Part 1 "실패담" 참고). 1M 측정을 시도하려면 L2/L6 을 제외하거나, Hibernate 영속성 컨텍스트 분할 전략을 별도로 설계해야 합니다.
3. commit-per-row 안티패턴 확인
이 비교를 위해 저장소에 추가한 L-1 은 level0-raw-jdbc/.../RawJdbcNoBatchBenchmark.java 에 있으며, with-nobatch Spring 프로파일로만 활성화됩니다.
./gradlew :runner:bootRun --args="--size=10000" \
-Dspring.profiles.active=with-nobatch실측 시간이 너무 길어지므로 내부에서 항상 상위 3,000 건만 실제로 넣고 결과를 선형 외삽 합니다 (SAMPLE_SIZE 상수로 조정). 이 값은 엄밀한 측정이 아니라 "단건 commit 이 10~100 배 더 느리다" 는 크기감을 확인하기 위한 추정값으로만 해석해 주세요.
