TL;DR: "스프링 없이 CRUD 4개쯤이야"로 시작했는데, Socket 추상화 너머에 OS 커널이 통째로 떠받치고 있다는 것과, 그 위에 짜는 코드의 95%는 HTTP 스펙 처리라는 것을 연달아 깨달았다.
0. "스프링 없이도 웹 서버를 만들 수 있나?"
강의 서비스 백엔드를 처음부터 짜보는 과제를 받았다. 회원 가입과 강의 업로드만 되면 되는 가벼운 프로젝트라서, 일단 강의 자체를 다루는 CRUD 네 개만 있으면 충분했다.
POST /lectures— 강의 등록PUT /lectures— 강의 수정DELETE /lectures— 강의 삭제GET /lectures— 강의 목록
평소라면 @RestController 하나 만들고 끝낼 일이다. 그런데 한 단계 뒤로 물러나니까 이런 질문이 떠올랐다.
"스프링이 없으면 웹 서버를 어떻게 만들지?"
@GetMapping이 사라지고, HttpServletRequest도 못 쓰고, 톰캣도 없다고 치자. 자바 표준 라이브러리만으로 8080 포트를 열고 HTTP 요청을 받으려면 어떻게 해야 하는가? 이 질문에 즉답이 안 나온다는 게 살짝 부끄러웠다. 매일 쓰는 도구의 바닥이 어떻게 생겼는지도 모른 채 그 위에 코드를 쌓고 있었던 셈이다.
1. 가장 원시적인 출발점 — ServerSocket
자바에는 네트워크 요청을 직접 받을 수 있는 도구가 표준 라이브러리 안에 이미 들어 있다. java.net.ServerSocket이다. 검색 몇 번 따라가니 이런 코드가 나왔다.
public class Main {
public static void main(String[] args) {
try (final ServerSocket serverSocket = new ServerSocket(8080)) {
while (true) {
try (final Socket clientSocket = serverSocket.accept()) {
final BufferedReader in = new BufferedReader(
new InputStreamReader(clientSocket.getInputStream()));
final PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);
// HTTP 요청 읽기
final String request = in.readLine();
System.out.println("요청: " + request);
// HTTP 응답 전송
out.println("HTTP/1.1 200 OK");
out.println("Content-Type: text/html; charset=UTF-8");
out.println();
out.println("<html><body><h1>안녕하세요, 자바 웹 서버입니다!</h1></body></html>");
}
}
} catch (final IOException e) {
System.err.println("error = " + e.getMessage());
}
}
}이걸 실행하고 브라우저에서 localhost:8080을 치면 정말로 "안녕하세요, 자바 웹 서버입니다!"가 뜬다. 스프링도, 톰캣도, 어떤 프레임워크도 없이.
처음 봤을 때 좀 어이가 없었다. out.println("HTTP/1.1 200 OK") 같은 줄이 어떻게 HTTP 응답이 되는 거지? 그냥 문자열을 PrintWriter로 출력하는 코드인데. in.readLine()이 어떻게 브라우저가 보낸 "GET / HTTP/1.1"을 정확히 가져오는 거고? 자바 코드 어디에도 패킷이나 TCP 같은 건 안 보이는데.
답을 풀려면 Socket이라는 추상화 너머를 봐야 했다. 평소엔 그냥 import해서 쓰던 그 클래스 말이다.
2. Socket이 뭔데? — OS 커널이 떠받치는 추상화
깨달음 1: Socket은 "양방향 바이트 파이프" 추상화다
자바의 java.net.Socket은 OS 커널이 관리하는 TCP 연결의 한쪽 끝을 가리키는 핸들이다. 더 정확히는, 커널의 파일 디스크립터를 감싼 얇은 자바 래퍼다.
clientSocket.getInputStream() // 이 연결로 들어오는 바이트
clientSocket.getOutputStream() // 이 연결로 나가는 바이트여기서 "들어오는/나가는 바이트"는 자바가 직접 처리하는 게 아니다. 자바는 그저 커널에게 "이 파이프에서 N 바이트 읽어줘", "이 파이프에 N 바이트 써줘"라고 시스템 콜로 부탁할 뿐이다. 실제로 바이트를 옮기는 일 — 패킷 라우팅, 재전송, 순서 맞추기, 흐름 제어 — 은 모두 커널이 한다.
그러니까 이 한 줄,
final ServerSocket serverSocket = new ServerSocket(8080);은 새로운 객체를 만든다기보다 커널에게 "8080 포트로 들어오는 TCP 연결을 받겠다"고 등록하는 시스템 콜에 가깝다. accept() 도 마찬가지로 "다음 연결이 완성될 때까지 기다려달라"는 부탁이다. 자바가 만드는 건 그 부탁의 결과로 받은 핸들 객체뿐이다.
내 가정은 "Socket이 그냥 객체 하나겠거니"였다. 직접 들여다보니 그건 커널이 관리하는 거대한 시스템에 대한 한 줄 요약 인터페이스였다. 그래서 자바 코드가 짧을 수 있었던 거였다.
깨달음 2: 텍스트가 전선을 타려면 네 겹의 봉투가 씌워진다
그러면 우리가 쓴 out.println("HTTP/1.1 200 OK") 의 텍스트는 어떻게 브라우저까지 가는가? 커널이 그걸 그대로 케이블에 흘려보내는 건 아니다. 네 겹의 봉투가 차례로 씌워진다.
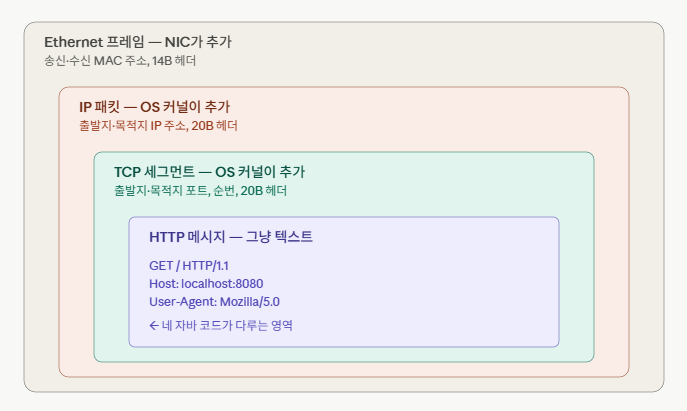
| 계층 | 봉투에 담기는 정보 | 누가 처리 |
|---|---|---|
| 애플리케이션 (HTTP) | "HTTP/1.1 200 OK\r\n..." 텍스트 | 자바 코드 |
| 전송 (TCP) | 출발지/목적지 포트, 순번, 재전송 정보 (20B 헤더) | OS 커널 |
| 네트워크 (IP) | 출발지/목적지 IP 주소 (20B 헤더) | OS 커널 |
| 링크 (Ethernet) | 송신/수신 MAC 주소 (14B 헤더), 전기·전파 신호 변환 | NIC + 드라이버 |
각 계층은 "위 계층이 만든 데이터 통째"를 자기 봉투의 본문에 넣고, 자기 헤더를 앞에 붙인다. 결과적으로 케이블에 흐르는 건 네 겹으로 감싸진 바이트 묶음이다. 이걸 캡슐화(encapsulation) 라고 한다.
받는 쪽은 정확히 반대 순서다. 브라우저 NIC가 신호를 받아 Ethernet 봉투를 뜯고, 커널이 IP 봉투를 뜯고, TCP 봉투를 뜯고, 그제서야 가장 안쪽 HTTP 텍스트가 브라우저 애플리케이션에 도달한다. 우리 자바 서버 쪽도 마찬가지로, in.readLine() 이 가장 안쪽 텍스트를 받기 전에 커널이 이미 세 겹의 봉투를 다 벗겨놓았다.
즉,
in.readLine()이 "GET / HTTP/1.1"을 돌려주는 건 마법이 아니라, OS 커널이 Ethernet/IP/TCP 봉투를 다 벗기고 가장 안쪽 텍스트만 자바에게 건네줬기 때문이다. 자바 코드 한 줄 뒤에 이 정도의 시스템이 깔려 있었다.
누가 무엇을 했나 — 정리
new ServerSocket(8080) 부터 out.println(...) 까지, 표면 코드 뒤에서 실제로 무슨 일이 일어났는지 한 줄씩 짚어보면 이렇다.
| 자바 코드 | 실제로 일어난 일 |
|---|---|
new ServerSocket(8080) | 커널에 "8080 포트 열어달라" 시스템 콜 등록 |
accept() | 커널이 TCP 3-way handshake 끝낼 때까지 대신 기다림 |
clientSocket.getInputStream() | 커널이 이미 풀어놓은 가장 안쪽 바이트(HTTP 텍스트)에 접근 |
out.println(...) | 커널이 받은 바이트를 TCP 세그먼트 → IP 패킷 → Ethernet 프레임으로 차례로 감싸 NIC에 전달 |
우체국 비유로 묶으면 깔끔하다. 우리는 정해진 양식의 편지지에 글만 쓰는 사람이다. 봉투 씌우고, 주소 적고, 트럭에 싣고, 운송하는 일은 모두 우체국(OS 커널)과 운송망(NIC, 라우터)이 처리한다. 평소에 안 보인다고 해서 일을 안 하는 게 아니었다.
여기까지 알고 나서야 비로소 §1의 의문이 풀렸다. out.println 이 작동한 건 마법이 아니라, Socket이라는 추상화가 OS 커널의 거대한 시스템을 "양방향 바이트 파이프"라는 한 줄 요약 인터페이스로 가려주고 있었기 때문이다. 그러면 CRUD 4개도 어렵지 않을 것 같았다.
이게 첫 번째 자만이었다.
3. 강의 CRUD를 얹어보자 — 두 번째 함정
원리를 알았으니 본래 목적이었던 CRUD 4개를 이 위에 올려보기로 했다. HTTP 요청 첫 줄을 파싱해서 메서드와 경로로 분기하면 끝일 줄 알았다.
final String requestLine = in.readLine(); // "POST /lectures HTTP/1.1"
final String[] tokens = requestLine.split(" ");
final String method = tokens[0];
final String path = tokens[1];여기까진 깔끔하다. 그런데 POST의 바디(JSON)를 어떻게 읽지?라는 지점에서 막혔다.
고민 1: POST 바디는 어디에 있나
HTTP 메시지 구조를 다시 들여다봤다.
POST /lectures HTTP/1.1 ← 요청 라인
Host: localhost:8080 ← 헤더 시작
Content-Type: application/json
Content-Length: 47
← 빈 줄 한 개 (구분자)
{"title":"클린 코드","price":50000} ← 바디요청 라인을 읽고, 빈 줄이 나올 때까지 헤더를 한 줄씩 읽고, 그 중 Content-Length 를 찾아서 그만큼 바디를 추가로 읽어야 한다. 헤더와 바디를 가르는 기준이 단지 "빈 줄 한 개"라는 것도 처음 알았다. RFC를 따로 안 봐도 될 거라고 생각한 게 또 하나의 자만이었다.
int contentLength = 0;
String headerLine;
while (!(headerLine = in.readLine()).isEmpty()) {
if (headerLine.startsWith("Content-Length:")) {
contentLength = Integer.parseInt(headerLine.split(":")[1].trim());
}
}
final char[] bodyBuffer = new char[contentLength];
in.read(bodyBuffer, 0, contentLength);
final String body = new String(bodyBuffer);CRUD 하나 처리하는 데 이 정도 코드가 들어간다. 그리고 이건 POST에만 필요한 게 아니라 PUT도 똑같이 필요하다.
고민 2: 분기는 어떻게?
이제 if/else로 4개 케이스를 처리해본다.
if ("GET".equals(method) && "/lectures".equals(path)) {
final String body = toJson(findAllLectures());
out.println("HTTP/1.1 200 OK");
out.println("Content-Type: application/json; charset=UTF-8");
out.println("Content-Length: " + body.getBytes(UTF_8).length);
out.println();
out.println(body);
} else if ("POST".equals(method) && "/lectures".equals(path)) {
// 위에서 만든 헤더/바디 파싱 로직...
saveLecture(parseJson(body));
out.println("HTTP/1.1 201 Created");
out.println();
} else if ("PUT".equals(method) && "/lectures".equals(path)) {
// 또 헤더/바디 파싱 반복...
} else if ("DELETE".equals(method) && "/lectures".equals(path)) {
// 경로에서 ID는 어떻게 추출하지?
} else {
out.println("HTTP/1.1 404 Not Found");
out.println();
}여기서 또 함정이 보였다. DELETE /lectures/3 처럼 경로 변수가 들어오면 어떻게 잘라내지? path.startsWith("/lectures/") 로 시작 부분 비교하고, path.substring(10) 으로 ID 잘라내고... 이걸 모든 RESTful URL마다 직접 짜야 한다.
거기다 쿼리 파라미터(/lectures?page=1&size=20)가 붙으면 ? 뒤를 또 따로 파싱해야 하고, URL 디코딩도 필요하다. 한국어가 들어가면 %ED%81%B4%EB%A6%B0 같은 인코딩을 풀어야 한다.
엔드포인트 4개에 이 정도다. 회원, 강의, 결제, 통계, 댓글, 알림... 100개로 늘어나면 어떻게 되지? 머리가 아파왔다.
4. 무엇이 보일러플레이트인가
위에서 짠 코드를 다시 들여다보면, 진짜 비즈니스 로직은 딱 4줄이다.
findAllLectures()
saveLecture(parseJson(body))
updateLecture(parseJson(body))
deleteLecture(id)나머지는 전부 HTTP 메시지를 풀고 다시 싸는 일이다. 한 번 표로 정리해봤다.
| 단계 | 코드량 | 본질? |
|---|---|---|
| 요청 라인 파싱 (메서드, 경로, 버전) | 3줄 | 보일러플레이트 |
| 헤더 파싱 (Content-Length, Content-Type 등) | 5~10줄 | 보일러플레이트 |
| 바디 읽기 (Content-Length만큼 정확히) | 3줄 | 보일러플레이트 |
| 경로 변수/쿼리 파라미터 추출 | 5~15줄 | 보일러플레이트 |
| URL 디코딩 (한국어, 특수문자) | 2~3줄 | 보일러플레이트 |
| 비즈니스 로직 | 1줄 | 본질 |
| 응답 상태 라인 작성 | 1줄 | 보일러플레이트 |
| 응답 헤더 작성 (Content-Type, Content-Length) | 2~3줄 | 보일러플레이트 |
| 응답 바디 직렬화 | 1~2줄 | 보일러플레이트 |
전체 코드의 95%가 모든 엔드포인트마다 똑같이 반복된다. 그리고 이 95%는 우리가 마음대로 바꿀 수도 없다. HTTP 스펙(RFC 9110, 9112)이 정해놓은 그대로다.
여기서 자연스럽게 떠오른 생각이 있다. "스펙이 정해져 있다"는 건 "표준화될 수 있다"는 뜻이다. 모든 자바 웹 개발자가 매번 똑같은 헤더 파싱 코드를 짤 게 아니라, 누군가 한 번 잘 만들어두고 다 같이 쓰면 되는 일이다.
게다가 위 코드는 가장 단순한 경우만 다뤘다. 실제로는 chunked transfer encoding, keep-alive 커넥션, multipart 파일 업로드, 쿠키와 세션, gzip 압축, HTTPS까지 따라온다. 이걸 다 직접 구현한다? 사실상 불가능하고, 무엇보다 불필요한 일이다.
흥미로운 건 §2에서 본 OS 커널의 역할과 정확히 같은 패턴이라는 점이다. TCP/IP 스펙도 정해져 있어서 커널이 그걸 통째로 처리해주듯, HTTP 스펙도 정해져 있으니까 누군가가 그걸 통째로 처리해주면 된다. 계층의 위치만 다를 뿐, 같은 발상이다.
5. 그래서 서블릿이 등장한다
이 깨달음의 끝에 서블릿(Servlet) 이 있다. 서블릿은 본질적으로 이런 계약이다.
"HTTP 메시지를 풀고 싸는 일은 컨테이너가 다 처리할 테니, 너는 비즈니스 로직만 짜라."
서블릿을 쓰면 우리 코드는 더 이상 BufferedReader.readLine() 으로 첫 줄을 파싱하지 않는다. 대신 HttpServletRequest 객체에서 깔끔한 메서드로 정보를 꺼낸다.
| 직접 짜기 | 서블릿 |
|---|---|
requestLine.split(" ")[0] | request.getMethod() |
헤더 루프 돌리며 Content-Length 찾기 | request.getContentLength() |
| 빈 줄 후에 정확히 N 바이트 읽기 | request.getReader() |
| 쿼리 스트링 split하고 디코드 | request.getParameter("page") |
| 응답 상태 라인 직접 쓰기 | response.setStatus(201) |
응답 쪽도 마찬가지로 HttpServletResponse 가 헤더와 상태 코드를 알아서 조립해준다. 우리 손에는 비즈니스 로직만 남는다.
정리하면 이런 위계가 생긴다.
| 계층 | 우리가 다루는 것 | 누가 처리하는가 |
|---|---|---|
| 비즈니스 로직 | "강의를 저장한다" | 너의 코드 |
| HTTP 메시지 처리 | 요청 파싱, 응답 직렬화 | 서블릿 컨테이너 (톰캣) |
| TCP/IP 통신 | 패킷 라우팅, 재전송 | OS 커널 |
| 물리 신호 | 전기/전파 | NIC + 드라이버 |
§2에서 OS 커널이 TCP/IP 보일러플레이트를 다 처리해줬듯, 서블릿 컨테이너는 그 위에서 HTTP 보일러플레이트를 처리한다. 추상화가 한 층 더 쌓인 셈이다.
서블릿이 정확히 어떻게 동작하는지, 톰캣 같은 서블릿 컨테이너가 무슨 일을 하는지는 다음 글에서 풀어보려 한다. 이 글의 목적은 "왜 서블릿이라는 추상화가 필요해졌는가"를 직접 코드를 짜보면서 체감하는 것이었으니까.
마무리 — "ServerSocket이면 충분할 줄 알았다"
처음 ServerSocket 예제를 봤을 때는 "어, 별거 아니네. CRUD 4개 정도는 직접 짜도 되겠는데?"라는 자신감이 있었다. 그런데 직접 짜보니, 매 단계에서 생각이 틀렸다.
| 단계 | 내가 생각한 것 | 직접 짜보니 |
|---|---|---|
| §1 ServerSocket 코드 | "텍스트만 쓰면 끝, 별거 아니네" | 텍스트만 써도 통신이 된 게 의문이었다 |
| §2 Socket 추상화 | "그냥 객체 하나겠거니" | 커널이 떠받치는 4계층 시스템의 핸들이었다 |
| §3 CRUD 분기 | "if/else 4개면 충분하지" | 헤더 파싱, 바디 길이, 경로 변수, URL 디코딩... 함정이 분기마다 늘어났다 |
| §4 보일러플레이트 | "어차피 한 번만 짜면 되니까" | 엔드포인트가 늘수록 곱연산으로 증가했다 |
| §5 직접 짜기 vs 서블릿 | "프레임워크는 무겁고 복잡한 거 아닌가" | 보일러플레이트를 컨테이너에 위임한다는 명료한 계약이었다 |
서블릿은 과잉 설계가 아니었다. HTTP가 표준 스펙이라는 사실 그 자체가 이미 "표준화된 처리 계층"을 요구하고 있었다. OS 커널이 TCP/IP 스펙을 처리해주듯, 서블릿 컨테이너는 HTTP 스펙을 처리해준다. 모든 개발자가 매번 직접 짜는 게 비효율이었던 거고.
직접 ServerSocket으로 짜는 건 매일 출근길에 직접 도로를 깔고 다리를 놓는 일과 비슷하다. 한두 번은 멋지지만, 매일 그러려면 시간이 모자란다. 도로와 다리는 누군가 이미 깔아놓은 것을 쓰고, 우리는 그 위에서 어디로 갈지만 결정하는 게 효율적이다.
그래도 도로 밑에 어떤 콘크리트와 철근이 들어가 있는지 한 번쯤 봐두면, 나중에 도로가 무너졌을 때 그 위에서 길을 잃지 않는다. 결국 프레임워크를 잘 쓴다는 건 프레임워크 없이도 무엇이 일어나는지를 아는 것에서 시작한다는 걸 느꼈다. 이 글이 그 한 번의 들춰보기였길 바란다. 다음 글에서는 이 도로 — 서블릿과 톰캣 — 가 정확히 어떻게 깔려 있는지를 들여다보자.
