개요
우테코 수료를 한지 한달이 조금 지났다.
그 중의 선택 강의로 네오의 고가용성 아키텍쳐 강의가 있었다.
하지만 프로젝트가 바쁘다는 핑계로 하지 않았던 것이 마음에 남았다.

- 입사를 앞두고 코드에 대한 감을 잡을 겸
- 대규모 트래픽에 대해서도 설계와 테스트를 해보고 싶어
지금에라도 해당 미션을 시작해보려고 한다.
조금 더 요구사항을 명확하게 가져가기 위해서 배달의 민족 쿠폰을 가정한다.
- 쿠폰은 항상 어드민이 만든다는 가정하에 존재한다.
- 유저는 쿠폰을 발급받을 수 있다.
세부 요구사항 정의
세부적인 요구사항을 다음과 같이 정했다.
1. 쿠폰 발급
유저가 쿠폰을 발급받는다
├─ 사전 조건: 쿠폰이 이미 생성되어 있어야 함
├─ 결과: 유저쿠폰 ID 생성
└─ 제약: 동일한 쿠폰을 중복 발급 불가
2. 쿠폰 사용
유저가 쿠폰을 사용한다
├─ 사전 조건: 발급받은 유저쿠폰 ID 존재
└─ 제약: 동일한 쿠폰을 중복 사용 불가
3. 쿠폰 관리 (어드민)
어드민이 쿠폰을 생성한다
├─ 쿠폰 정보: 이름, 할인율/금액, 유효기간
└─ 발급 가능 수량 설정
비기능 요구사항
1분당 10만 요청 (초당 1,666 RPS)
10,000명의 동시 사용자일관성재고 초과 발급 0건
목표
위 요구사항을 기반으로 다음의 목표들을 충족해야한다.
- 선착순 쿠폰을 제공하는 기능에서 일관성과 가용성을 확보
- 이벤트 드리븐 구조로 설계
- MSA 구조로 설계(할지 안할지 고민중!)
- 성능 개선 전후로 부하테스트로 측정
- Kotlin, MVC 대신 WebFlux 사용
간단한 화면
ai 딸깍을 통해 프론트를 만들어봤다.
이런식으로 쿠폰이 이미 만들어져있고, 유저들은 여기에서 쿠폰을 발급할 수 있는 구조이다.
MemberCoupon 설계
유저가 발급받는 멤버 쿠폰 엔티티는 다음과 같이 구현했다
@Entity
@Table(
name = "member_coupon",
uniqueConstraints = [
UniqueConstraint(name = "member_coupon_constraint", columnNames = arrayOf("coupon_id","member_id"))
]
)
class MemberCoupon(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
var id: Long? = null,
@Column(name = "member_id", nullable = false)
var memberId: Long? = null,
@Column(name = "coupon_id", nullable = false)
var couponId: Long? = null,
@Column(name = "used_at")
var usedAt: LocalDateTime? = null,
@Column(name = "created_at", nullable = false)
var createdAt: LocalDateTime? = null,
@Column(name = "modified_at", nullable = false)
var modifiedAt: LocalDateTime? = null
) {
fun isSameMember(memberId: Long): Boolean {
return this.memberId == memberId
}
fun isUsed(): Boolean {
return usedAt != null
}
fun use(usedAt: LocalDateTime = LocalDateTime.now()) {
if (this.usedAt != null) {
throw IllegalStateException("이미 사용된 쿠폰입니다.")
}
this.usedAt = usedAt
this.modifiedAt = LocalDateTime.now()
}
}제약조건을 통해 한 멤버가 같은 쿠폰을 여러번 발급받는 일은 생기지 않는다.
세부적인 로직은 다음과 같이 구현했다.
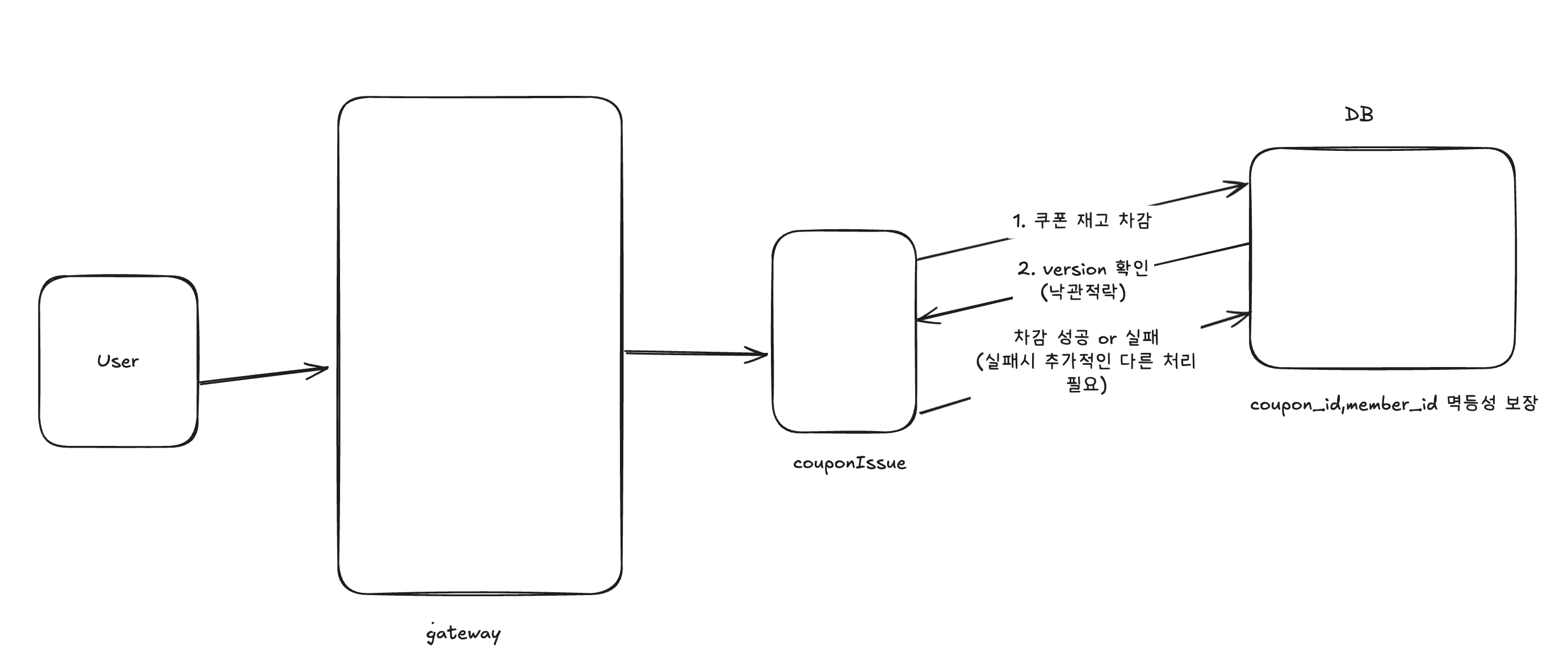
부하테스트 설계
이제 부하테스트를 위해서 부하 수준을 설정해보자
부하수준
1분간 총 10만 요청 발생
초당 1,666 요청 발생
10,000명의 랜덤 유저가 쿠폰 발급 시도
- 랜덤 유저가 쿠폰 발급을 시도한다는 점에서 부하테스트의 멱등성이 완벽하진 않을 수 있다는 점에 주의하자
테스트 조건
쿠폰 ID: 1~100개 범위에서 랜덤 선택 (사용가능한 개수가 정해져있음)
유저 ID: 1~10,000 범위에서 랜덤 선택
중복 발급 실패는 부하테스트상 생길 수 있는 정상 케이스로 간주 (비즈니스 로직)
- 400 예외
부하테스트 툴로는 스레드 효율적인 K6를 사용하자.
k6 코드
import http from 'k6/http';
import { check } from 'k6';
import { randomIntBetween } from 'https://jslib.k6.io/k6-utils/1.4.0/index.js';
import { Counter } from 'k6/metrics';
const successCounter = new Counter('success_issued');
const failSoldOutCounter = new Counter('fail_sold_out');
const failErrorCounter = new Counter('fail_server_error');
export const options = {
scenarios: {
constant_load: {
executor: 'constant-arrival-rate',
rate: 1666,
timeUnit: '1s',
duration: '1m',
preAllocatedVUs: 1000,
maxVUs: 5000,
},
},
thresholds: {
http_req_duration: ['p(95)<2000'],
},
};
const API_URL = 'http://localhost:8080/member-coupons';
export default function () {
const couponId = randomIntBetween(1, 100000);
const userId = randomIntBetween(1, 10000);
const payload = JSON.stringify({
userId: userId,
couponId: COUPON_ID
});
const params = {
headers: { 'Content-Type': 'application/json' },
};
const res = http.post(API_URL, payload, params);
if (res.status === 200 || res.status === 201) {
successCounter.add(1);
} else if (res.status === 409 || res.status === 400) {
failSoldOutCounter.add(1);
} else {
failErrorCounter.add(1);
if (__VU % 100 === 0 && __ITER % 10 === 0) {
console.error(`Error: Status ${res.status}`);
}
}
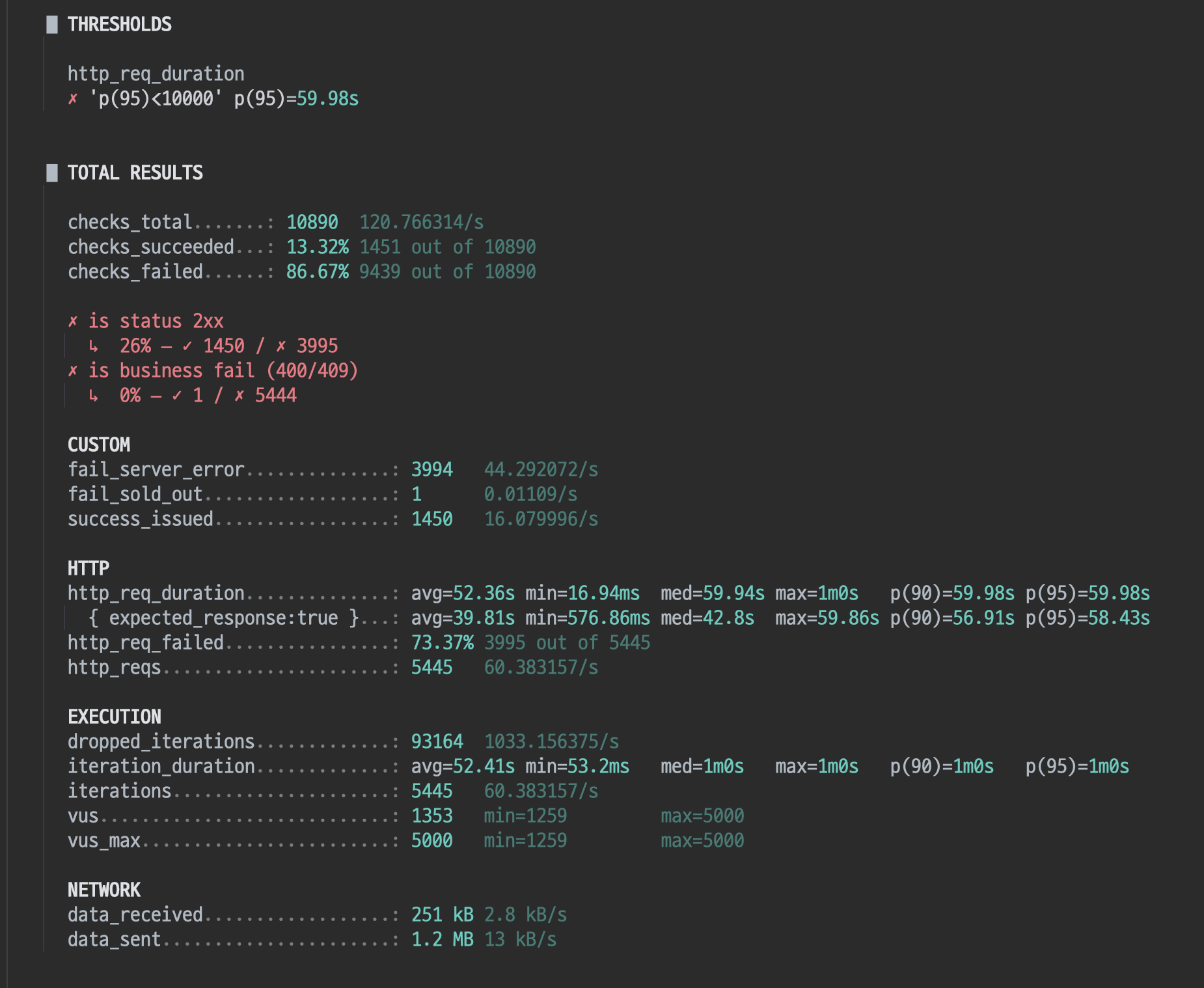
}부하테스트 결과
동시성
낙관적락이 잘 동작하는지를 확인해보자.
10만개 요청이 왔을때 최대 개수만큼의 쿠폰이 할당되었는지를 확인한다.

DB 부하(CPU 점유율)
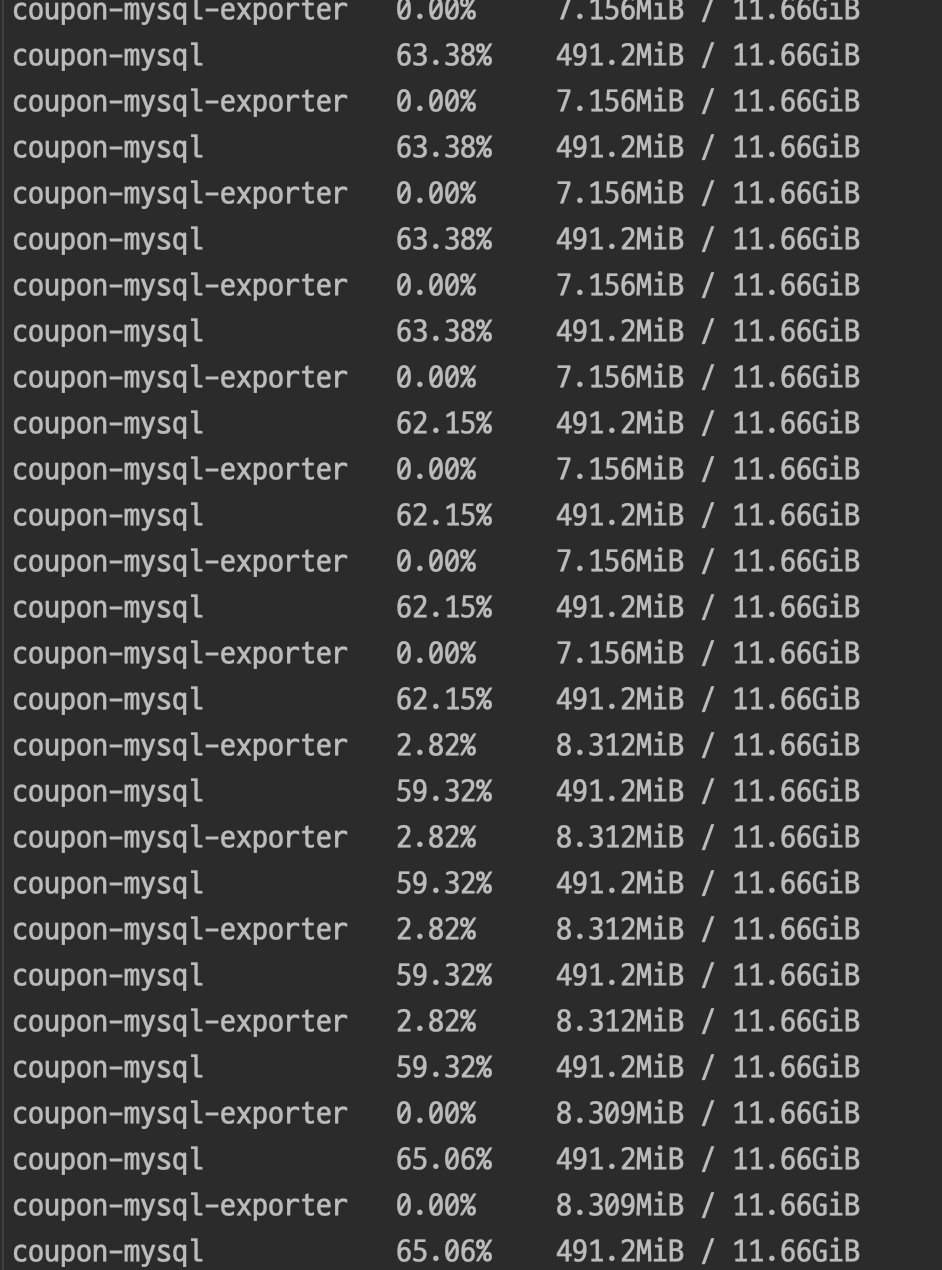
1분동안 10만개의 요청이 오면 65% 정도 점유율이 올라간다.
만약 점유율을 낮춰야한다면 어떻게 해야할까?
CPU 점유율을 낮추기 위해서 아키텍쳐를 개선해보자.
조회 미들웨어 도입
DB는 ACID를 준수하는데 용이하다
하지만 몇가지 쿼리들은 ACID가 반드시 필요하진 않다.
예로 쿠폰 개수 조회가 있다. 쿠폰 개수 조회는 얼핏 ACID 준수가 필요해 보이지만, 지켜지지않더라도 크게 비즈니스적으로는 문제가 없다.
- 쿠폰의 발급이 ACID 준수가 필요없다는 뜻은 아니다.
쿠폰 개수 조회를 Redis를 사용해서 조회하도록 했다. 다음과 같이 아키텍쳐를 바꿔보았다.
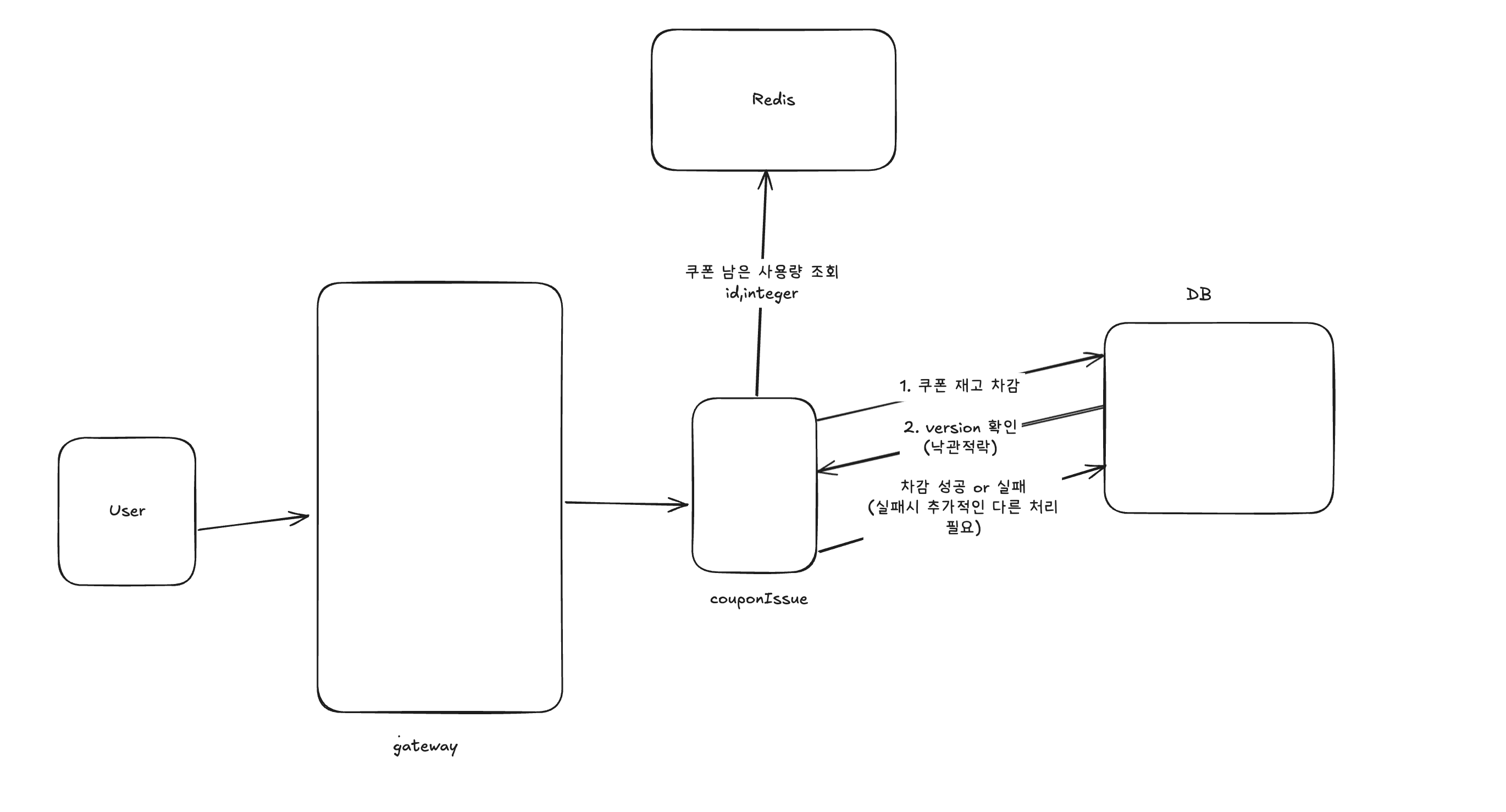
쿠폰의 남은 사용량 조회를 레디스에서 조회하도록 했다
이러면 이미 모두 발급된 경우에도 계속 DB에 조회가 발생하는 문제를 막을 수 있을 것이다.
이를 증명하기 위해서 테스트 해보자
캐싱 도입 후 부하테스트 결과
개선되었을까?
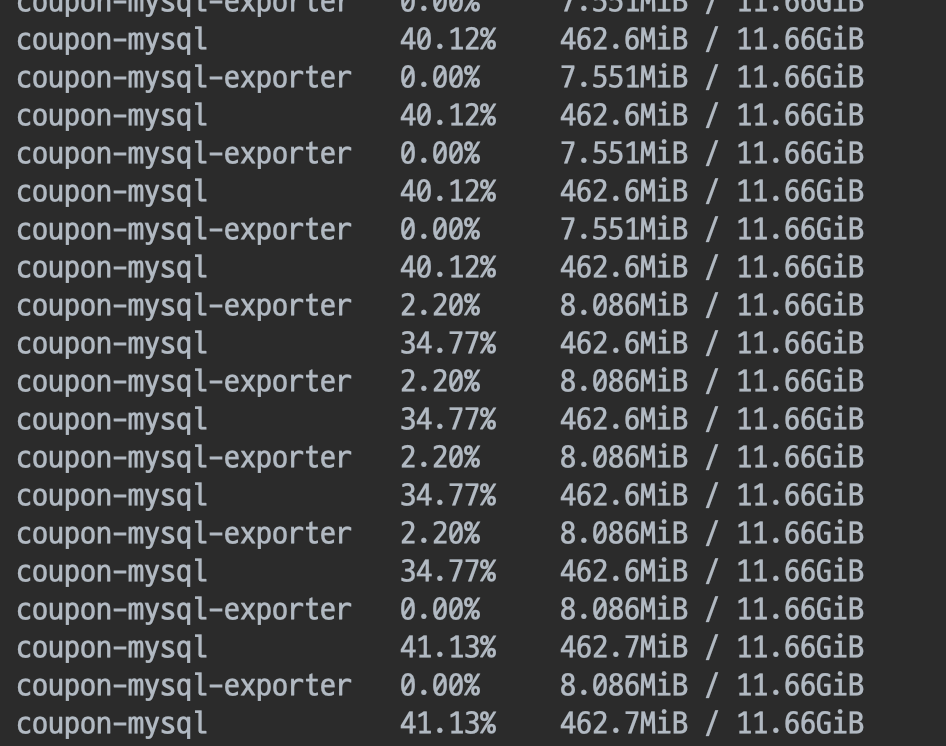
대부분 CPU 사용량이 약 4~50퍼센트고 간헐적으로 60%를 웃돌았다.
사실상 거의 개선되었다고 보기 힘들다.
왜냐하면 만료된 쿠폰이 아닌 경우 캐싱효과를 보기 힘들기 때문이다.
다르게 말하면 현재 도메인 정책에서는 해당 아키텍쳐가 크게 효과가 있지 않다 볼 수 있다.
- 쿠폰이 쉽게 만료가 되는 경우에는 유효한 방법일 것이다.
그렇다면 DB 병목을 해소하기 위한 또 다른 방법은 뭐가 있을까?
이는 다음 글에서 이어서 알아보자.
