
시작하기 전
말로만 듣던 Circuit Breaker, Rate Limiter를 직접 도입해봤다. 감당하기 어려운 비정상적인 트래픽을 제어함으로써 나의 서버를 안전한 상태로 유지하고, 우리 서버의 장애를 타 서버들에게 전이시키지 않는 경험을 할 수 있었다.
이 경험을 나누고자 한다.
갈등의 원인은 Retry로부터
비정상적인 트래픽이 발생하는 이유는 항상 Retry였다. Retry가 발생하면 순식간에 평소의 트래픽보다 N배 많은 트래픽이 발생한다. 또, 네트워크 홉을 많이 탈수록 Retry에 의한 트래픽 증가량이 지수함수를 그릴 확률이 높다. 중간 서버에서 또 Retry를 시도하고 있을 수 있기 때문이다.
지수함수 그래프를 그리며 가파르게 늘어나는 트래픽은 슈퍼컴퓨터로도 처리할 수 없다. 그래서 어떤 시점에서는 반드시 트래픽을 제어해주어야 한다.
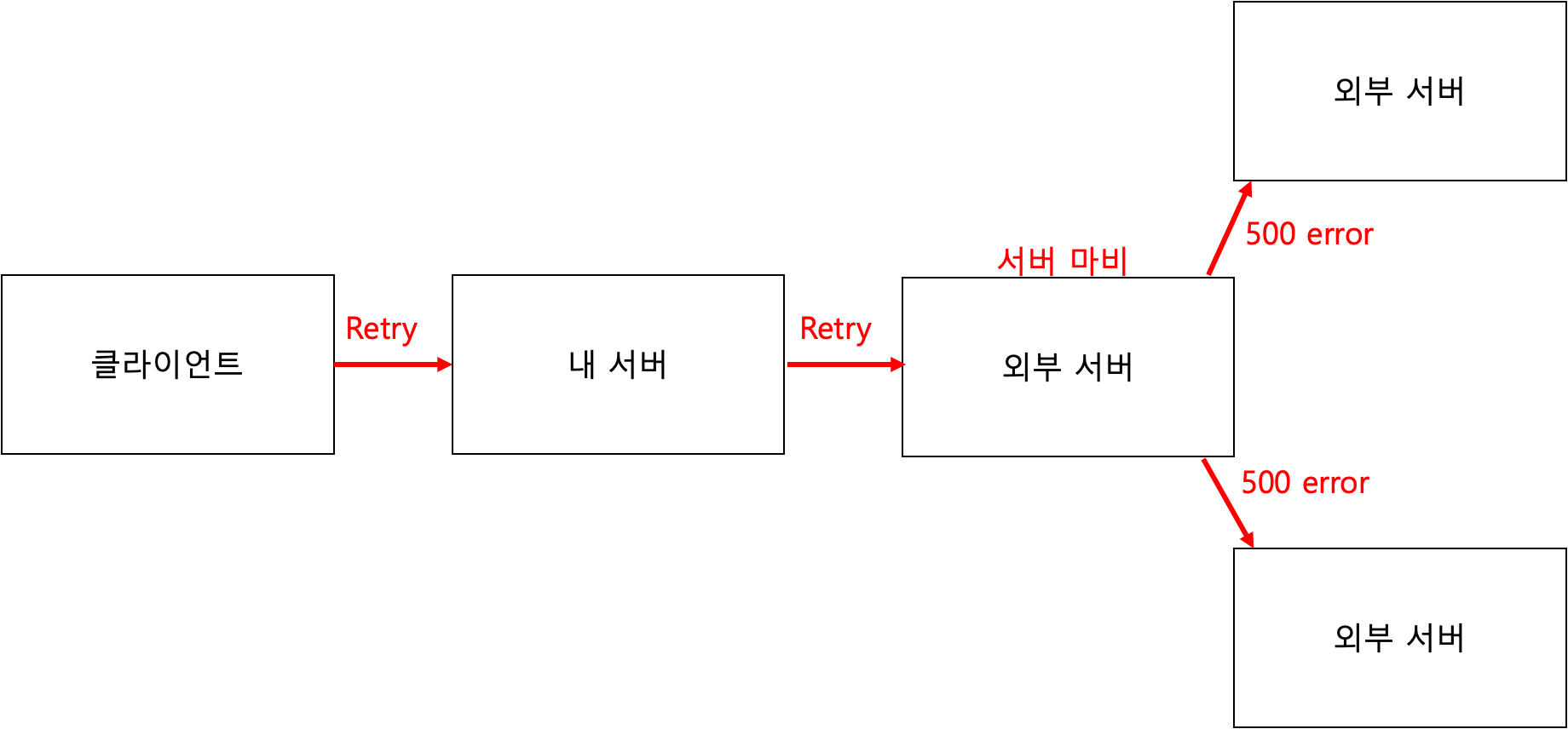
트래픽을 제어하지 않으면 위의 그림처럼 과도한 Retry가 발생하게되고 우리 서버와 통신하는 타 서버는 마비가 되어 동작 불능 상태에 빠진다. 결국 다른 원래 통신하던 다른 서버들에게도 응답할 수 없는 상태에 빠지며 조직 전체의 서버가 장애 상황에 빠질 수 있다.
이를 해결하기 위해서 트래픽을 제어하는 코드를 하드코딩하여 핫픽스 배포를 통해 장애를 복구해야한다. 그런데 이거 자신이 없다. 프로덕션 환경의 서비스에 QA 없이 배포하는 것은 또 다른 장애를 부를 수 있는 리스크를 짊어짐을 의미한다. 또, 장애 복구 시간은 배포 시간만큼 늦어진다. 서비스 신뢰도에 매우 큰 타격이 발생하는 상황이다.
그렇다면 이런 장애 상황에서 배포 없이 자동으로 트래픽을 제어할 수는 없는걸까?
갈등을 해결하기 위한 노력
기술적으로 해결하기 이전에 다른 방법으로 해결하도록 노력해볼 수 있다.
첫번째로, 상대 서버에게 Scale Out/Up 을 요청하자. Retry를 포함한 요청을 받아낼 수 있을 만큼의 하드웨어 자원을 투입할 수 있다면, 그렇게 하는 것이 낫다. 하드웨어 자원이 개발자의 인적 자원보다 저렴하기 때문이다.
두번째로, Retry 로직을 제거하는 것을 고려해봐야한다. Retry가 필요할까? Retry는 왜 설정하는걸까? 내 생각에는 Retry가 의미있게 동작하는 상황은 일시적인 오류로 실패한 경우에만 그렇다. 그러나 서버의 어떠한 오류로 인해서 오류가 해결되기 전까지는 모든 요청에 대해서 에러 응답을 내려주는 상황이라면 Retry는 그저 DDoS 공격일 뿐이다.
만약 이 두 가지 방법으로도 해결이 안된다면 이제는 내 서버에 어떠한 기술을 도입하여 직접 트래픽을 제어해주는 수 밖에 없다.
Circuit Breaker
Circuit Breaker는 유한 상태 머신의 구현체이다. 서킷의 상태를 기준으로 런타임에 자동으로 트래픽을 차단할 수 있고 다시 생성할 수 있다.
서킷의 상태는 일반적으로 OPEN, CLOSE, HALF_OPEN 세 가지 상태가 있다. 각각의 상태가 무엇을 의미하는지 살펴보자.

CLOSE는 서킷이 닫힌 상태이다. 트래픽이 정상적으로 발생되고 다른 서버와 정상적으로 통신하는 상황이다. 즉, 평상시에는 Circuit Breaker의 상태가 CLOSE이다.
OPEN은 서킷이 열린 것이다. 서킷이 열리면 트래픽이 제어된다. 즉, 장애상황일 때 Circuit Breaker의 상태는 OPEN 상태이다.
HALF_OPEN 상태는 여전히 OPEN 상태인 것으로 볼 수 있다. OPEN 상태와 다른 점이 있다면 상대 서버가 여전히 장애 상황인지 판단하기 위해서 테스트용 트래픽을 발생시킨다. 테스트용 트래픽의 응답이 정상이라면 서킷이 다시 CLOSE 상태로 변경되며 트래픽 차단이 해제된다.
그렇다면 이 상태는 어떤 기준으로 변경될까?
- Count-based sliding window
- Time-based sliding window
- Failure rate and slow call rate thresholds
세 가지 기준이 존재하며, 세 가지 기준에 대한 Hyper Parameter를 모두 설정해줘야한다. 모집단이 될 요청의 숫자, 요청의 숫자를 카운팅할 시간, 실패 요청 / 지연 요청의 비율 등이 기준이 된다.
복잡한 이야기를 미뤄두고 간단하게 말하면 상대 서버로부터 500 응답을 받으면 트래픽이 차단된다. 여기서 주목해야할 점은 장애를 어떻게 처리하는 것은 아니고 트래픽을 차단하는 것이다. 트래픽을 왜 차단해야 할까? 외부 서버가 100% 확률로 500응답을 준다면 트래픽을 굳이 흘려보낼 필요가 없기 때문이다. 보내봐야 500응답을 받을게 뻔하기 때문이다.
아쉽지만 Circuit Breaker 만으로는 트래픽 제어를 완벽하게 해낼 수 없다. 예외적인 시나리오가 있을 수 있는데, 예를들어 status code: 200인데 response body의 응답값이 일부 누락되어 있을 수 있다. 그렇다면 내 서버의 비즈니스 로직에 의해서 클라이언트에게 에러 응답을 내려주고, 결국 Retry가 발생할 수 있다.
이런 경우는 어떻게 핸들링해야할까?
Rate Limiter
Circuit Breaker로는 타 서버 응답에 대한 액션을 지정할 수 있다. Rate Limiter 로는 허용할 트래픽의 규모를 제한할 수 있다. Rate Limiter는 어떤 매커니즘으로 트래픽을 제어하는지 살펴보자.

그림을 간단하게 설명하자면 cycle 동안 최대로 보낼 수 있는 트래픽의 숫자가 있다. 트래픽을 permission 이라는 용어로 나타내며 이 permission 의 숫자를 넘어서는 요청에 대해서는 항상 에러 응답을 내보낸다.
재밌는 점은 이 permission이 고갈되더라도 일정 숫자까지는 다음 cycle의 남는 permission을 사용해서 응답을 할 수 있다는 점이다. 1번 cycle에서는 40개의 요청이 왔으나 2번 cycle에서는 20개의 요청만 올 수 있기 때문에 이런 유연함을 제공하는 것 같다.
어찌됐든 Rate Limiter를 도입하여 요청의 총량을 조절할 수 있다.
두 기술만으로 잘 동작할 수 있을까?
답은 No이다. 반드시 모니터링 연동이 필요하다.
- Circuit Breaker state
- Active permission count
- WebClient connection pool, latency
- in/out bound call's http status code
적어도 위의 지표들을 수집해줘야 한다.
위의 지표들을 수집하고 지속적으로 모니터링하며 우리가 도입한 Circuit Breaker, Rate Limiter가 의도대로 동작하고 있는지 확인해야 한다.
permission은 지나치게 많지 않은지?
permission에 비해 web client connection이 부족하지 않은지?
요청이 너무 많아서 latency가 늘어나지는 않는지?
모두 확인이 필요한 부분이다. 그리고 지금 당장은 적절한 파라미터들일 수 있으나 시간이 지나서 트래픽이 늘거나 줄면 또 파라미터를 튜닝해줘야 한다. 튜닝에 대한 근거를 확보하기 위해서 메트릭 수집을 열심히 할 필요가 있다.
도입 후기
왠만하면 사용하지 말자. 진심이다.
Circuit Breaker, Rate Limiter는 도입하는 것이 어렵지 않다. 훌륭한 오픈소스들이 구현체를 제공하고 있고 적은 코드로도 잘 동작하게 만들 수 있다.
구현 비용보다 엔지니어링 비용이 굉장히 크다. 모니터링 시스템 연동, 메트릭 수집 시스템 연동, 애플리케이션에 구현체 도입, 모니터링 데이터 분석이 필요하다. 메트릭을 저장할 스토리지가 필요하고 시각화하기 위한 대시보드 시스템도 필요하다.
이렇게 많은 비용을 들일만큼 가치 있는 일인지 잘 생각하고 정말 이것밖에 선택지가 없을 때 사용해야 한다. 세부적인 내용을 언급할 수 없지만 업무상 특별한 상황이어서 사용했고 잘 사용하기까지 쉽지 않은 과정을 겪었다.
왠만하면 다른 서버나 클라이언트에서 대응을 할 수 있도록 시도해보고, 반드시 우리 서버에서 대응을 해야 하는 상황이면 도입하도록 하자.
마지막으로 결론을 정리하고 글을 마친다.
- 사용을 안할 수 있으면 사용하지 말자
- Circuit Breaker는 남의 서버를 지켜주는 기술이다.
- Rate Limiter는 나의 서버를 지켜주는 기술이자 남의 서버를 지켜주는 기술이다.
그림 출처
.jpg)