
LinkedList
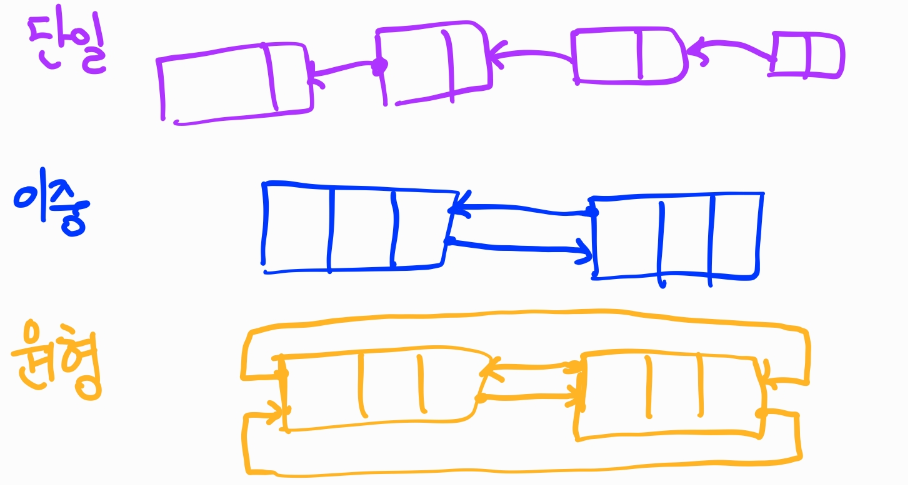
연결 리스트는 세 종류가 있다.
- 단일 연결 리스트
- 부모의 노드만 한 단계 자식 노드의 정보를 알고 있다.
- 탐색을 할 때 무조건 부모 노드로부터 순차적으로 탐색해야한다.
- 이중 연결 리스트
- HEAD에는 부모노드의 정보를 알고 있고 TAIL은 자식노드의 정보를 알고 있다.
- 단일 연결 리스트에 비해 삭제 연산이 효율적이다.
- 단일 연결 리스트에 비해 HEAD 노드의 정보를 가지고 있기 때문에 메모리를 추가 사용한다.
- 원형 연결 리스트
- 이중 연결 리스트와 같지만 가장 첫 노드의 HEAD는 가장 마지막 노드의 TAIL을 알고 있고 가장 마지막 노드의 TAIL은 가장 첫 노드의 HEAD를 알고 있다. 원형으로 연결되어 있다
- 가장 마지막 노드의 정보를 알고 있기 때문에 마지막 노드를 찾는 연산이 필요 없다.
- 구현이 조금 어렵다.
나는 단일 연결 리스트를 구현해봤다. LinkedList의 장점과 단점은 아래와 같다. 나중에 배우겠지만 ArrayList는 LinkedList와 장단점이 반대라고 보면되낟.
장점
- 자료의 추가와 삭제가 빠르다.
O(1)의 시간에 가능하다.
단점
- 특정 위치의 데이터를 검색해 내는데에는
O(n)의 시간이 걸린다. 반드시 맨 처음의 노드부터 탐색을 해야한다.
구현목록
- 정수를 저장하는
ListNode클래스ListNode add(ListNode head, ListNode nodeToAdd, int position)ListNode remove(ListNode head, int positionToremove)boolean contains(ListNode head, ListNode nodeTocheck)
ListNode Class
멤버변수
public class ListNode {
private ListNode tail;
private Integer value;
}- 다음 노드의 정보를 알기위한
ListNode tail - 정수를 저장하기 위한
int value
add method
ListNode add(ListNode head, ListNode nodeToAdd, int position)
총 3가지의 경우가 있다고 생각했고 그렇게 구현했다.
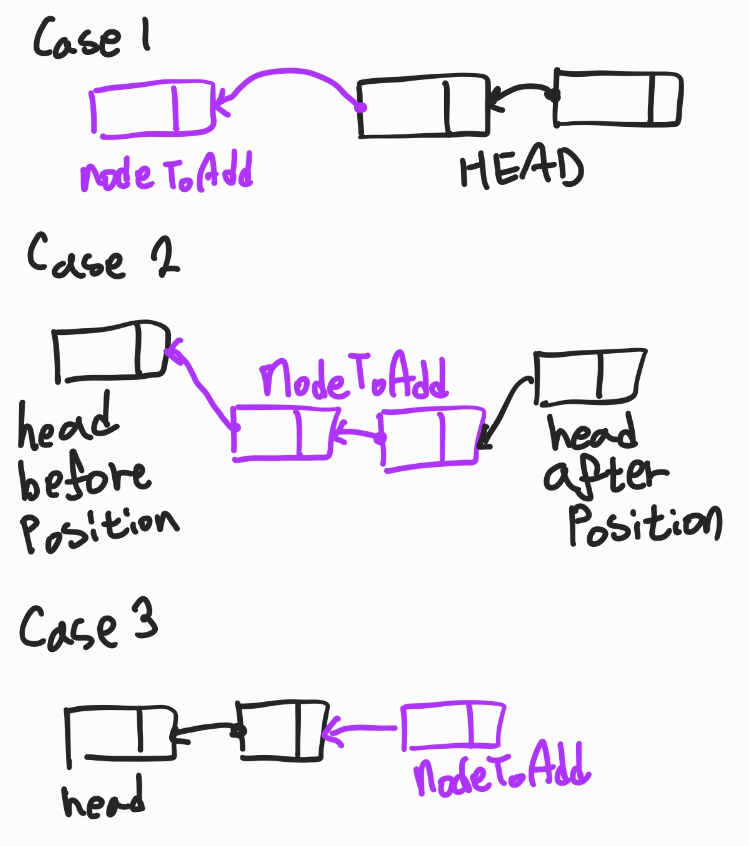
case1:position이 0일 때 /nodeToAdd의 가장 끝에 있는 노드와head를 연결한다.case2:position이 1이상이며head의 맨 마지막이 아닐 때 /position에 해당하는 위치를 찾고position을 기준으로head를 분리하고nodeToAdd를 연결시킨다.case3:position이head의 크기와 같을 때 /nodeToAdd를head의 맨 마지막 노드와 연결한다.
public static ListNode add(ListNode head, ListNode nodeToAdd, int position) {
// 파라미터의 원본들이 훼손되지 않도록 복사본 생성
head = head.duplicate();
nodeToAdd = nodeToAdd.duplicate();
// case1 인 경우에 바로 아래 로직 수행 후 리턴
if (position == 0) {
// nodeToAdd의 크기가 1 이상일 경우를 대비해서 항상 getLastTail() 호출
nodeToAdd.getLastTail().tail = head;
return nodeToAdd;
}
// case2, case3인 경우 재귀 호출
head.add(nodeToAdd, position);
return head;
}
private void add(ListNode nodeToAdd, int position) {
// position이 1보다 크면 무조건 다음 노드로 이동
// 다음 노드로 이동하기 위해 tail을의 add를 호출
// 그리고 position을 1씩 감소 --position
if (1 != position) {
tail.add(nodeToAdd, --position);
return;
}
// position이 1일 때 노드 바꿔치기
// case3도 커버 가능
nodeToAdd.getLastTail().tail = tail;
tail = nodeToAdd;
}위와 같은 코드를 작성했다. 필요에 의해 getLastTail()과 duplicate() 메소드를 추가 구현했다.
listNode.getLastTail():listNode의 가장 마지막 노드를 리턴한다.listNode.duplicate():listNode의 복사본을 리턴한다.
// 마지막 노드 가져오기
public ListNode getLastTail() {
return this.tail == null ? this : tail.getLastTail();
}
// 복사하기
public ListNode duplicate() {
// 호출한 노드의 크기가 1이라면 바로 리턴
ListNode cloneNode = new ListNode(value, null);
if (tail != null) {
// 호출한 노드의 크기가 1보다 크다면 재귀호출
tail.duplicate(cloneNode);
}
return cloneNode;
}
private void duplicate(ListNode cloneNode) {
// 재귀를 위한 오버로딩 함수
cloneNode.tail = new ListNode(this.value, null);
if (tail != null) {
tail.duplicate(cloneNode.tail);
}
}TEST
그리고 테스트 코드를 작성했다. 앞으로 등장하는 모든 테스크 코드에는 다음과 같은 @BeforeEach, @AfterEach 메소드와 함께 동작한다.
@BeforeEach
void init() {
head = new ListNode(0,
new ListNode(1,
new ListNode(2,
new ListNode(4, null))));
tail = new ListNode(999, null);
longTail = new ListNode(998, new ListNode(997, null));
node1 = new ListNode(0, null);
node2 = new ListNode(0, new ListNode(1, null));
node3 = new ListNode(0, new ListNode(0, new ListNode(1, null)));
}
@AfterEach
void after() {
assumeTrue(head.toString().equals("[ 0 1 2 4 ]"));
assumeTrue(tail.toString().equals("[ 999 ]"));
assumeTrue(longTail.toString().equals("[ 998 997 ]"));
assumeTrue(node1.toString().equals("[ 0 ]"));
assumeTrue(node2.toString().equals("[ 0 1 ]"));
assumeTrue(node3.toString().equals("[ 0 0 1 ]"));
}테스트를 직관적으로 하기 위해서 toString()을 오버라이딩했다. 포스팅이 너무 길어지니 코드는 굳이 첨부하지 않겠다.
BeforeEach: 테스트를 위한 데이터셋을 준비한다.AfterEach: 각 메소드들을 테스트 한 후 테스트 데이터 셋의 원본이 훼손되었는지 확인한다.
테스트 코드를 살펴보자
@Test
@DisplayName("ADD TEST")
void addTest() {
ListNode case1 = ListNode.add(head, tail, 0);
assumeTrue(case1.toString().equals("[ 999 0 1 2 4 ]"));
ListNode case2 = ListNode.add(head, longTail, 4);
assumeTrue(case2.toString().equals("[ 0 1 2 4 998 997 ]"));
ListNode case3 = ListNode.add(tail, longTail, 1);
assumeTrue(case3.toString().equals("[ 999 998 997 ]"));
}테스트 메소드에는 항상 @Test 어노테이션이 필요하다.
내가 원하는 이름으로 출력하기 위해서 @DisplayName 어노테이션도 사용했다.

remove method
ListNode remove(ListNode head, int positionToRemove)
remove도 마찬가지로 add처럼 3개의 케이스를 가진다. 처음 노드를 삭제할 때 / 중간 노드를 삭제할 때 / 마지막 노드를 삭제할 때
public static ListNode remove(ListNode head, int positionToRemove) {
ListNode clone = head.duplicate();
if (positionToRemove == 0) {
clone = head.tail;
return clone;
}
clone.remove(positionToRemove);
return clone;
}
private void remove(int positionToRemove) {
if (positionToRemove != 1) {
tail.remove(--positionToRemove);
return;
}
tail = tail.tail;
}add와 구조가 똑같다. 아쉬운점도 똑같다..
TEST
테스트도 마찬가지다. 세 가지 케이스를 모두 확인했다.
@Test
@DisplayName("REMOVE TEST")
void removeTest() {
ListNode case1 = ListNode.remove(head, 0);
assumeTrue(case1.toString().equals("[ 1 2 4 ]"));
ListNode case2 = ListNode.remove(head, 1);
assumeTrue(case2.toString().equals("[ 0 2 4 ]"));
ListNode case3 = ListNode.remove(head, 3);
assumeTrue(case3.toString().equals("[ 0 1 2 ]"));
}
contains method
boolean contains(ListNode head, ListNode nodeTocheck)
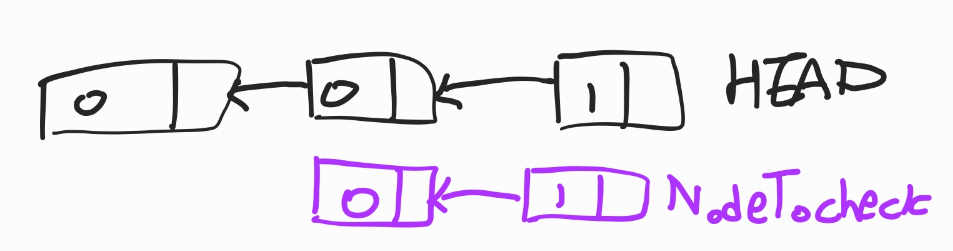
NodeTocheck의 길이가 1이면 head와 같은 부분을 발견하면 바로 삭제하면 되지만 만약 길이가 2이상이면 다음의 head 값과도 같은지 확인해야 한다.
그 중에서도 아래 그림과 같이 head가 [ 0 0 1 ] 이고 NodeTocheckt가 [ 0 1 ]일 때는 처음 0이 같더라도 그 다음에는 0과 1이기 때문에 잘 고려해야한다.
public static boolean contains(ListNode head, ListNode nodeTocheck) {
// nodeTocheck 가 head 보다 길면 안된다.
if (nodeTocheck.getSize() > head.getSize()) {
return false;
}
// 그림과 같은 경우를 고려하기 위해서 nodeTocheckt의 size보다 작아질 때 까지 head를 방문한다.
for (int i = 0; i < head.getSize(); i++) {
// 재귀 함수가 true면 바로 true를 리턴하며 함수 종료
if (head.contains(nodeTocheck)) {
return true;
}
// 재귀 함수가 true가 아니면 head를 다음 노드로 이동
head = head.tail;
}
return false;
}
private boolean contains(ListNode nodeTocheck) {
// nodeTocheck가 마지막 노드인치 체크
if (nodeTocheck.tail == null) {
// 마지막 노드이면서 값이 값으면 true 값이 다르면 false
return value == nodeTocheck.value;
}
// nodeTocheck가 마지막 노드가 아닌데 값이 다르면 false
if (value != nodeTocheck.value) {
return false;
}
// nodeTocheck가 마지막 노드가 아닌데 값이 같으면 다음 노드로 이동
return tail.contains(nodeTocheck.tail);
}TEST
@Test
@DisplayName("CONTAIN TEST")
void containtTest() {
assumeTrue(ListNode.contains(head, node1));
assumeTrue(ListNode.contains(head, node2));
assumeFalse(ListNode.contains(node1, node2)); // nodeTocheck가 더 길면 false
assumeTrue(ListNode.contains(node3, node2));
}
느낀점
많이 부족하다고 느꼈다. 공부를 열심히 해야겠다. 하나의 메소드로 구현할 수 있지 않았을까도 싶다.
.jpg)