데이터 조회 심화
별칭(AS)
미리 테이블에 지정된 컬럼명이 아닌, 조회하고 싶은 형태의 컬럼명이 있다면 별칭을 통해서 기존 컬럼명을 조회할 때 바꿀 수 있다.
<실행>
SELECT addr AS 주소, debut_date "데뷔 일자", mem_name FROM member;<결과>
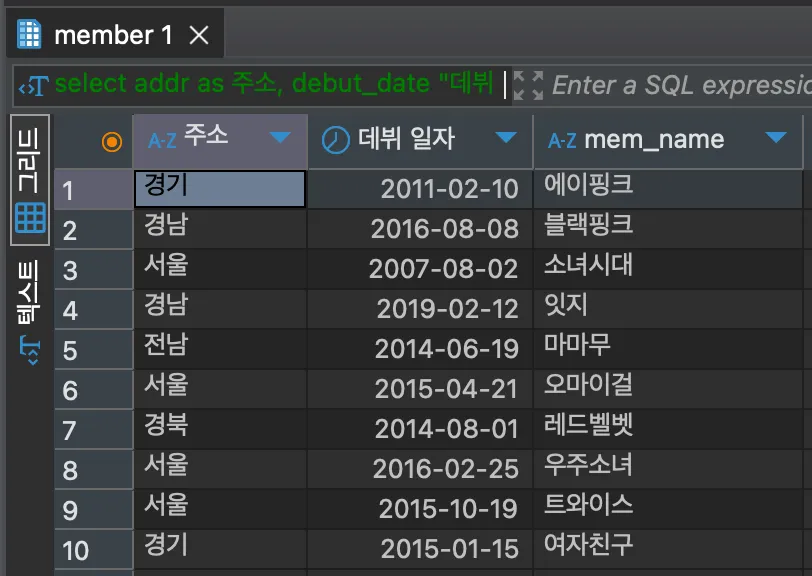
컬럼명 다음에 AS와 함께 지정하고 싶은 이름을 입력하여 별칭(alias) 지정이 가능하다. 별칭에 공백이 있을 시 큰따옴표를 사용하고, 작은 따옴표도 사용 가능하나 큰 따옴표 사용을 권장한다.
또한 SELECT 다음에 나오는 별칭의 경우 AS가 생략 가능하나 가독성을 위해 써주자.
데이터 출력 정렬(ORDER BY)
ORDER BY는 데이터가 조회되는 순서를 조정할 수 있다. 오름차순 기반, 내림차순 기반, 우선순위 기반으로 정렬할 수 있으며, ORDER BY (컬럼명) (정렬 조건)의 형태로 사용하면 된다.
<실행>
SELECT mem_id, mem_name, debut_date
FROM member
ORDER BY debut_date;<결과>
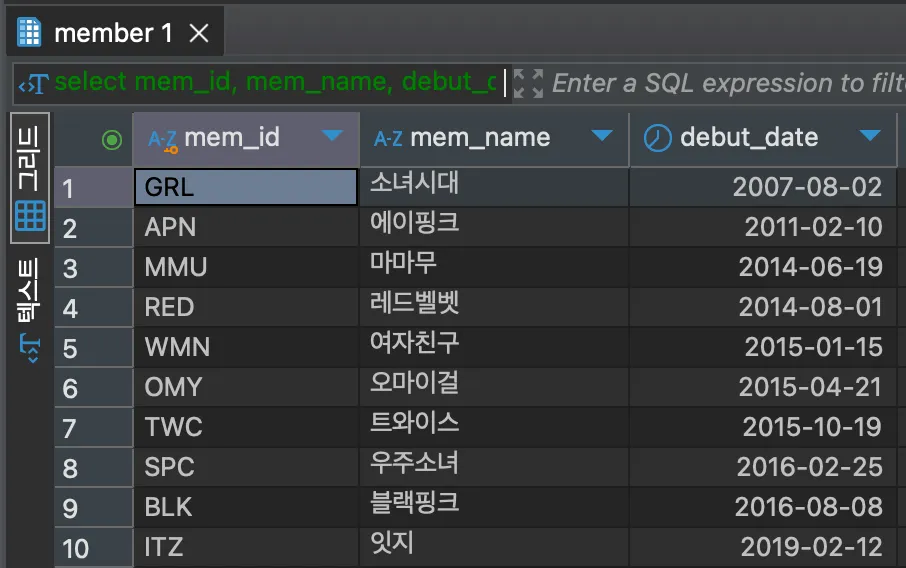
주어진 쿼리문은 debute_date가 빠른 순(오름차순)으로 데이터 추출 후 정렬하는 것으로, ORDER BY는 결과의 값이나 개수에 영향을 미치지 않고 오직 출력되는 순서에만 영향을 미친다.
<실행>
SELECT mem_id, mem_name, debut_date
FROM member
ORDER BY debut_date DESC;<결과>
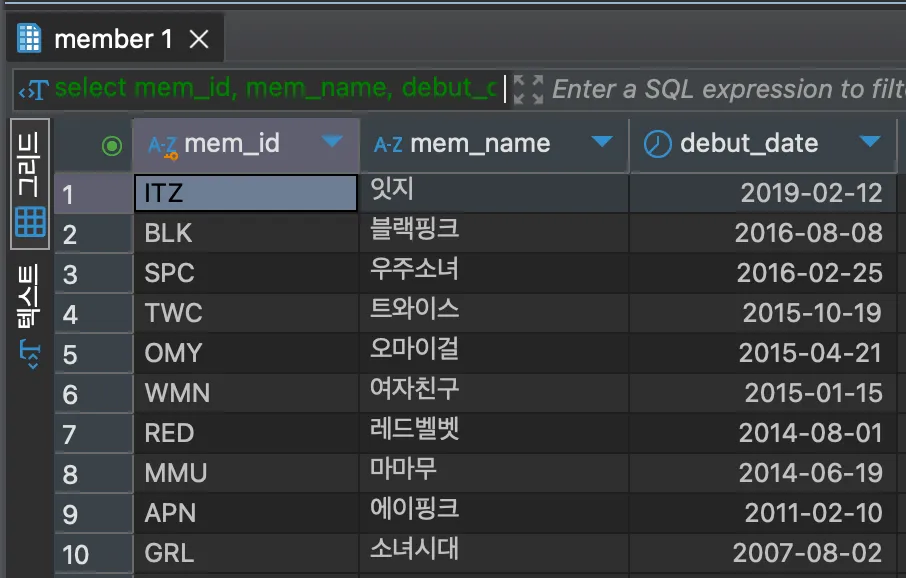
출력 순서 기본값은 ASC(ascending)로 오름차순이다. 기본값이기에 따로 명시를 해주지 않아도 기본적으로 적용이되고, DESC(descending)으로 지정할 시 내림차순으로 정렬된다.
그렇다면 이번에는 여러 개의 정렬 조건으로 정렬을 실시해보자.
<실행>
SELECT mem_id, mem_name, debut_date, height
FROM member
WHERE height >= 164
ORDER BY height DESC, debut_date ASC;<결과>
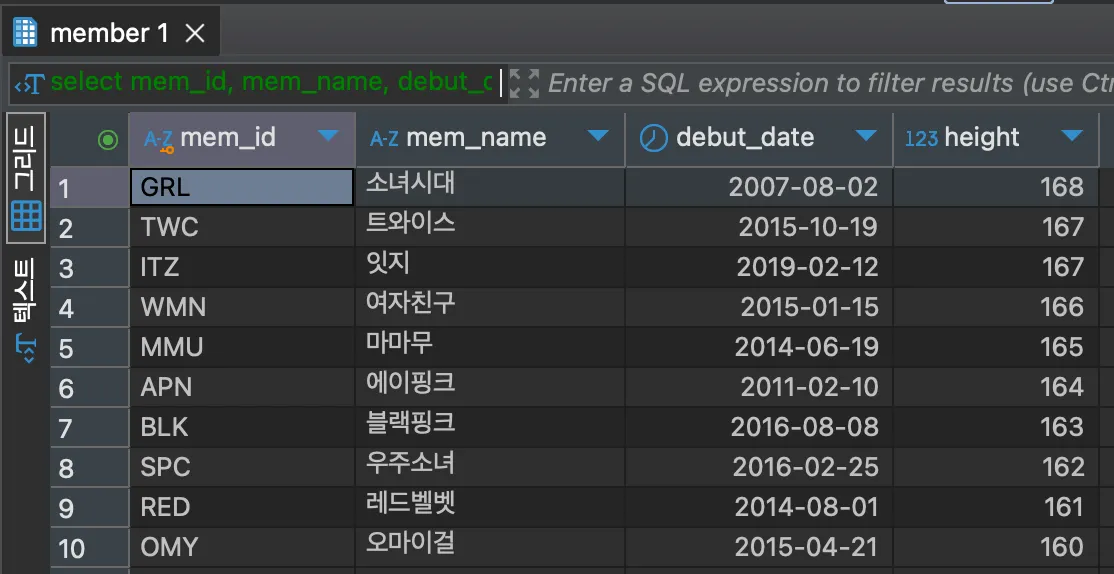
주어진 쿼리문은 평균 키(height)가 164 이상인 멤버들을 height순으로 먼저 정렬하고, 만약 height가 동일할 경우 데뷔일자(debut_date) 빠른 순으로 정렬된다.
정렬 기준을 여러 개 설정하면 n번째 열로 정렬 후, 만약 n번째 열의 값이 같다면 n+1 열로 정렬한다.
데이터 출력 개수 제한(LIMIT)
LIMIT는 조회되는 데이터의 개수를 제한하는데 쓰인다. LIMIT [시작], (개수)의 형태로 쓰이며 [시작]은 생략할 수 있다. 만약 생략하고 (개수)만 쓸 경우 첫번째부터 (개수)만큼 데이터를 조회하겠다는 의미이다.
<실행>
SELECT * FROM member LIMIT 3;<결과>

위 쿼리문은 member 테이블에서 앞에서 3개의 데이터만 조회하는 쿼리로, LIMIT를 사용하여 출력하는 개수 제한할 수 있다.
<실행>
SELECT mem_name, debut_date
FROM member
ORDER BY debut_date
LIMIT 3;<결과>
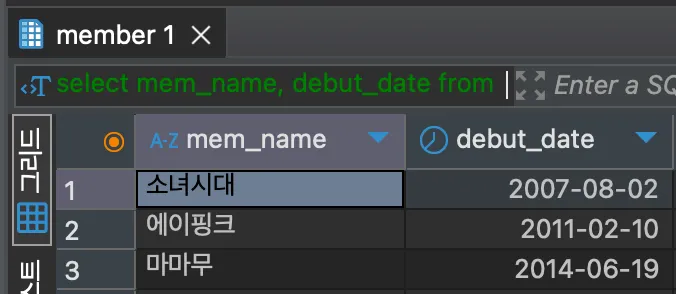
LIMIT는 보통 ORDER BY와 함께 사용하여 특정 조건으로 정렬 후 데이터 조회한다, LIMIT 형식은 앞서 말했듯이 LIMIT [시작], (개수)이며 LIMIT (숫자)만 쓰면 LIMIT 0, (숫자)와 동일, 즉 0번째부터 (숫자)만큼의 데이터를 조회하겠다는 의미가 된다. LIMIT에서 1번째 데이터는 0으로 시작하니 주의하자.
이번에는 직접 [시작] 오프셋을 지정해보자.
<실행>
SELECT mem_name, height
FROM member
ORDER BY height DESC
LIMIT 3, 2;<결과>
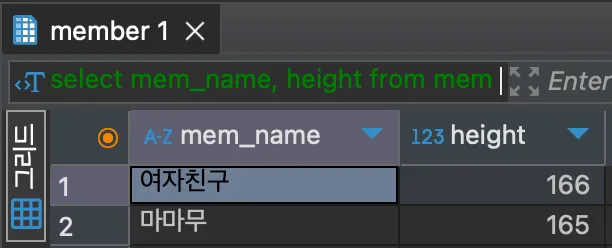
위 쿼리문은 4번째 데이터 부터 2개의 데이터를 추출하는 것이다.
LIMIT [시작], (개수)는 LIMIT [개수] OFFSET [시작]과 동일하기 때문에, 전자를 쓰든 후자를 쓰든 동일한 결과가 나온다.
데이터 중복 결과 제거(DISTINCT)
DISTINCT(컬럼명1, ...)은 데이터 조회를 한 결과에서 중복된 데이터가 있다면 1개의 데이터만 남긴다.
<실행>
SELECT DISTINCT addr FROM member;<결과>
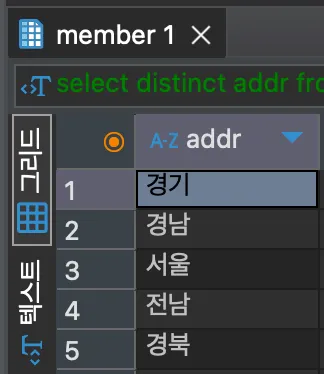
member 테이블에서 addr이 중복 되는 데이터를 1개만 남기고 추출하였다. DISTINCT는 조회된 결과에서 중복된 데이터를 1개만 추출하기에, 중복되는 경기, 경남, 서울, 전남, 전북 데이터는 하나로 통일되었다.
데이터 그룹화(GROUP BY)와 집계함수
GROUP BY와 함께 사용하는 집계 함수(aggregation function)
GROUP BY는 조회 결과를 그룹으로 묶어주는 역할을 한다. 그룹으로 묶을 수 있기에 주로 집계 함수를 사용한다. MYSQL에서 지원하는 기본적인 집계 함수는 아래와 같다.
| 함수명 | 설명 |
|---|---|
| SUM() | 합계 계산 |
| AVG() | 평균 계산 |
| MIN() | 최솟값 계산 |
| MAX() | 최댓값 계산 |
| COUNT() | 행의 개수 계산 |
| COUNT(DISTINCT) | 행의 개수 계산(중복은 1개만 인정) |
<실행>
SELECT mem_id, SUM(amount) FROM buy GROUP BY mem_id;<결과>
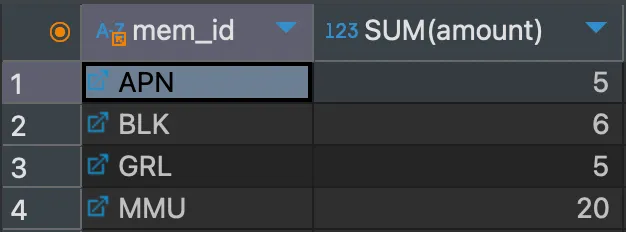
mem_id 별로 그룹을 묶어준 후, SUM() 집계 함수를 사용하여 amount 개수의 총합을 계산했다.
기본적인 집계 연산은 GROUP BY로 지정한 열을 묶어주고 집계 함수로 계산하여 출력하는 형태로 사용한다.
<실행>
SELECT mem_id "회원 아이디", SUM(amount) "총 구매 개수"
FROM buy
GROUP BY mem_id;<결과>
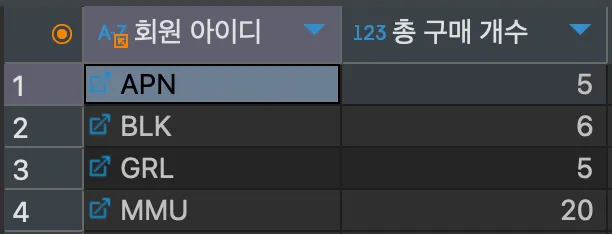
이번에는 선택된 열에 별칭을 부여해서 조회하였다. 기존에는 SUM()과 같은 집계 함수가 열의 이름에 그대로 드러나기 때문에 별칭을 부여하여 더 알아보기 쉽게 사용한다.
참고로 별칭에 작은 따옴표를 사용해도 되지만, INSERT 등에서 문자를 입력할 때는 큰 따옴표 사용을 권장한다.
이번에는 단순히 특정 회원이 구매한 상품의 총합이 아닌 금액의 총합을 구해보도록 하자.
<실행>
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액"
FROM buy
GROUP BY mem_id;<결과>
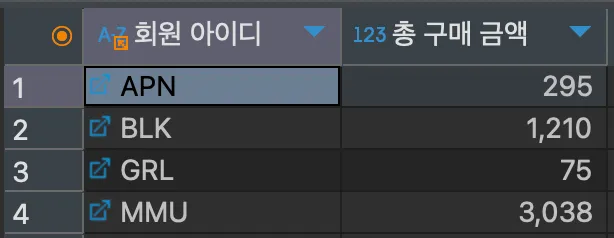
mem_id가 구매한 금액의 총합에 관한 데이터 추출하기 위해 가격 * 수량의 SUM()을 계산하였다.
이번에는 전체 회원이 구매한 물품 개수의 평균을 구해보도록 하자.
<실행>
SELECT AVG(amount) "평균 구매 개수" FROM buy;<결과>

AVG() 집계 함수를 사용하여 전체 회원이 구매한 물품 개수의 평균 데이터를 추출하였다. 모든 집계 함수가 반드시 GROUP BY 절과 함께 써야 하는건 아니기 때문에 적절히 상황에 맞게 사용하자.
이번에는 각 회원마다 한번 물품을 구매할 때, 평균적으로 몇 개씩 구매하는지 평균을 구해보도록 하자.
<실행>
SELECT mem_id, AVG(amount) "평균 구매 개수"
FROM buy
GROUP BY mem_id;<결과>
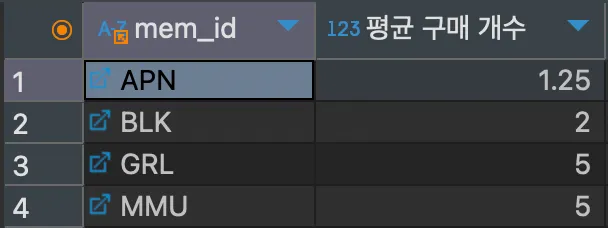
mem_id를 그루핑 한 후, AVG()를 사용하여 amount의 평균을 구해서 회원 당 구매 개수 물품의 평균을 구하였다.
이번에는 총 회원 수를 구해보도록 하겠다.
<실행>
SELECT COUNT(*) FROM member;<결과>
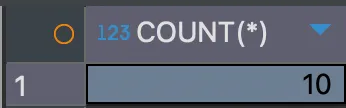
데이터의 수를 조회하기 위해 COUNT()를 사용하였다. COUNT() 함수의 열의 이름이 아닌 *을 사용하면 NULL값인 행도 포함하여 개수를 계산한다.
이번에는 전체 회원 수가 아닌 연락처가 있는 회원을 조회해보도록 하자.
<실행>
SELECT COUNT(phone1) "연락처가 있는 회원" FROM member;<결과>

phone1 열의 값이 NULL인 항목을 제외하고 값이 있는 데이터를 조회하기 위 COUNT()에 phone1열을 지정하였다. COUNT() 함수의 인자에 열 이름을 지정할 시 해당 열의 값이 NULL인 것을 제외한 행의 개수 계산하여 반환한다.
데이터 그룹화 조건(HAVING)
앞서 그룹화를 통해 특정 열로 묶어준 후, 집계 함수를 사용하여 데이터들을 조회해왔다. 그렇다면 집계 함수를 적용한 후, 조건을 걸어 특정 조건을 만족하는 결과만 출력하려면 어떻게 해야할까?
WHERE로 조건을 건다고 생각할 수 있지만, WHERE 절에는 집계 함수를 사용할 수 없다. 따라서 집계 함수의 결과에 조건을 걸고 싶다면 HAVING 절을 사용하여 결과를 필터링해야한다.
이번에는 회원 중에서 총 구매 금액이 1000을 넘는 회원들만 조회해보도록 하자.
<실행>
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액"
FROM buy
GROUP BY mem_id
HAVING SUM(price*amount) > 1000;<결과>
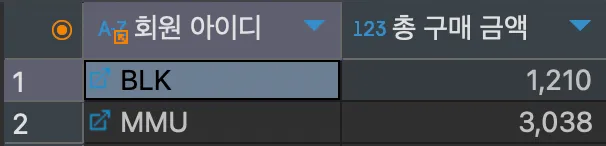
총 구매 금액이 1000을 넘는 그룹의 데이터를 추출하기 위해 HAVING 절에서 집계 함수를 사용하여 조건을 지정하였다.
절의 순서는 GROUP BY 다음에 HAVING으로 반드시 GROUP BY 이후에 HAVING을 사용한다.
이번에는 총 구매 금액이 1000을 넘는 그룹의 데이터를 총 구매 금액의 내림차순으로 조회해보자.
<실행>
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액"
FROM buy
GROUP BY mem_id
HAVING SUM(price*amount) > 1000
ORDER BY SUM(price*amount) DESC;<결과>
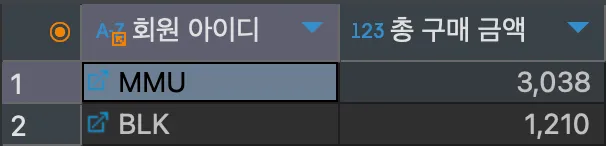
총 구매액이 큰 그룹 순서로 정렬하기 위해 ORDER BY와 DESC를 사용하여 집계 함수의 결과를 정렬하였다.
데이터 변경
데이터 입력(INSERT)
테이블에 새로 데이터를 입력할 때는 아래와 같이 INSERT문을 사용하여 입력할 수 있다.
INSERT INTO 테이블명 [(열1, 열2, ...)] VALUES (값1, 값2 ...)INSERT는 테이블에 행 데이터를 입력하는 키워드로 테이블 이름 다음에 나오는 열은 생략 가능하나, 이때 VALUES 다음에 나오는 값들의 순서 및 개수는 테이블의 정의된 모든 열의 순서 및 개수와 동일해야 한다.
USE market_db;
CREATE TABLE hongong1 (toy_id INT, toy_name CHAR(4), age INT);
INSERT INTO hongong1 VALUES (1, '우디', 25);예를 들어 hongong1 테이블에 정의된 열의 개수와 타입에 맞게 값 삽입하려면 위와 같이 데이터 타입과 순서를 다 맞춰야 한다.
INSERT INTO hongong1 (toy_id, toy_name) VALUES (2, '버즈');만약 특정 열에 해당하는 열을 생략 시 NULL 값이 입력 따라서 위 경우에 age 열에는 NULL값이 자동으로 삽입된다.
INSERT INTO hongong1 (toy_name, age, toy_id) VALUES ('제시', 20, 3);만약 단순히 열의 순서를 바꿔서 입력하고 싶다면 앞서 열을 설정하는 부분에서 순서를 바꿔서 지정하면 된다.
AUTO INCREMENT
AUTO_INCREMENT는 열을 정의할 때 1을 시작으로 1씩 증가하는 값을 입력해준다. 테이블을 정의할때 AUTO_INCREMENT로 지정하는 열은 반드시 PRIMARY KEY로 지정해야 하고, 해당 열에는 값을 입력하지 않는다.(자동으로 값이 1씩 올라가기 때문)
아래는 PRIMARY KEY에다가 AUTO_INCREMENT를 적용한 예시이다.
CREATE TABLE hongong2
(
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT
);자동 증가값을 이용하여, hongong2 테이블에 값을 삽입하여 보자.
<실행>
INSERT INTO hongong2 VALUES (NULL, '보핍', 25);
INSERT INTO hongong2 VALUES (NULL, '슬링키', 22);
INSERT INTO hongong2 VALUES (NULL, '렉스', 21);
SELECT * FROM hongong2;<결과>
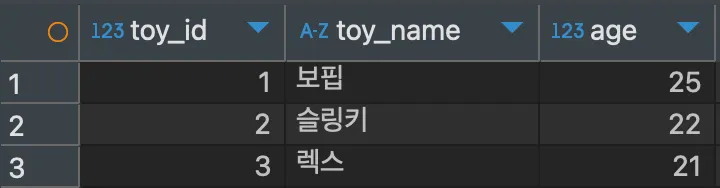
AUTO_INCREMENT로 지정한 열은 NULL값으로 지정하여도 자동으로 값이 증가되어 삽입된다. 만약 AUTO_INCREMENT를 사용하였을 때 마지막으로 증가된 값을 확인하려면 어떻게 해야할까?
<실행>
SELECT LAST_INSERT_ID();<결과>

LAST_INSERT_ID() 함수를 이용하여 마지막으로 증가된 값을 확인할 수 있다. 그렇다면 특정 테이블의 자동 증가값을 바꾸려면 어떻게 해야할까?
<실행>
ALTER TABLE hongong2 AUTO_INCREMENT=100;
INSERT INTO hongong2 VALUES (NULL, '재남', 35);
SELECT * FROM hongong2;<결과>
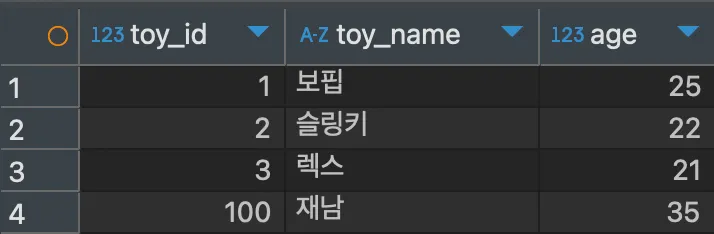
ALTER TABLE은 테이블을 변경하라는 쿼리문으로 AUTO_INCREMENT=(숫자)로 지정 시 해당 숫자부터 시작하여 증가하도록 변경된다. 이번에는 증가폭을 변경해보도록 하자.
<실행>
CREATE TABLE hongong3
(
toy_id INT AUTO_INCREMENT PRIMARY KEY,
toy_name CHAR(4),
age INT
);
ALTER TABLE hongong3 AUTO_INCREMENT=1000;
SET @@auto_increment_increment=3;
INSERT INTO hongong3 VALUES (NULL, '토마스', 20);
INSERT INTO hongong3 VALUES (NULL, '제임스', 23);
INSERT INTO hongong3 VALUES (NULL, '고든', 25);
SELECT * FROM hongong3결과
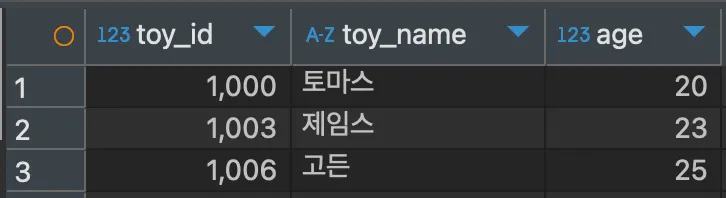
자동 증가값의 시작을 1000으로 설정하였고, 시스템 변수인@@auto_increment_increment=(숫자)를 사용하여 증가폭을 1이 아닌 3으로 변경하였다.
SELECT @@(시스템 변수 이름)시스템 변수는 앞에 @@ 접두어를 붙이며, 위 쿼리문으로 특정 시스템 변수의 값을 확인할 수 있다.
SHOW GLOBAL VARIABLES;위 쿼리문으로 전체 시스템 변수의 종류를 확인할 수 있다.
INSERT INTO 테이블_이름 VALUES (값1, 값2, ...), (값1, 값2, ...), ...참고로 INSERT 뒤에서는 VALUES 뒤에 여러 개의 값들의 그룹을 입력하여 한꺼번에 데이터 입력할 수 있다.
SELECT를 이용한 INSERT
INSERT를 할때는 직접 값을 입력하면 오래 걸리기 때문에, 다른 테이블에 입력하는 데이터가 있는 경우 INSERT INTO ~ SELECT 쿼리문을 사용하여 다른 테이블에 입력되어 있는 데이터를 한 번에 입력할 수 있다.
INSERT INTO 테이블 이름 (열 이름1, 열 이름2, ...)
SELECT ...;단, SELECT 뒤에 나오는 열의 개수는 INSERT할 테이블의 열의 개수와 동일해야하는 전제 조건이 있다.
해당 전제 조건을 만족하기 위해서는, 특정 테이블에서 전체 열을 뽑아오는 것이 아닌, 값을 삽입하려는 테이블의 열에 맞게 SELECT를 해야한다.
CREATE TABLE city_popul (city_name CHAR(35), population INT);
INSERT INTO city_popul
SELECT Name, Population FROM world.city;따라서 위 예시 SQL과 같이 world.city라는 테이블에서 전체 열을 추출하는게 아닌, Name, Population만 추출하도록 한다.
테이블 구조 파악(DESC)
특정 테이블의 구조를 파악하기 위해서는 DESC(describe) 명령어를 사용하여 테이블의 구조를 확인할 수 있다.
<실행>
DESC hognong3;<결과>

hongong3 테이블 구조를 파악하기 위해 DESC 명령을 사용하여쏙, 그 결과 컬럼명과 타입, NOT NULL 여부 등을 확인할 수 있다.
데이터 수정(UPDATE)
이미 삽입된 데이터를 수정하기 위해서는 UPDATE 구문을 사용하여 데이터를 수정할 수 있다.
UPDATE 테이블 이름
SET 열1=값1, 열2=값2, ...
WHERE 조건;UPDATE는 기존에 입력되어 있는 값을 수정하는 명령어로 기본적인 형식은 위 형식과 같다.
이번에는 hongong3 테이블에서 toy_name이 ‘제임스’인 행의 toy_name을 ‘마키스’로 바꿔보도록 하자.
<실행>
USE market_db;
UPDATE hongong3
SET toy_name = '마키스'
WHERE toy_name = '제임스';
SELECT * FROM hongong3 WHERE toy_name = '마키스'<결과>

의도한 대로 toy_name이 제임스인 데이터의 toy_name 열의 값을 마키스로 변경하였다. 이번에는 여러 개의 열을 수정해보도록 하자.
<실행>
USE market_db;
UPDATE hongong3
SET toy_name = '토드', age = 27
WHERE toy_name = '고든';
SELECT * FROM hongong3 WHERE toy_name = '토드'<결과>

위와 같이 SET 뒤에서 여러 개의 열의 값을 한번에 변경할 수 있다. (열 이름) = (값)을 콤마로 분리해서 여러 개의 열을 나열하여 변경 가능하다.
UPDATE hongong3 SET toy_name = '서울'이때 UPDATE 쿼리문에서 WHERE 절은 문법 상 생략할 수 있는데, WHERE 절을 생략할 시 모든 행이 조건에 true로 판정되어 모든 행의 열의 값이 변경된다.
<실행>
UPDATE hongong3 SET age = age / 10;
SELECT * FROM hongong3 LIMIT 3;<결과>
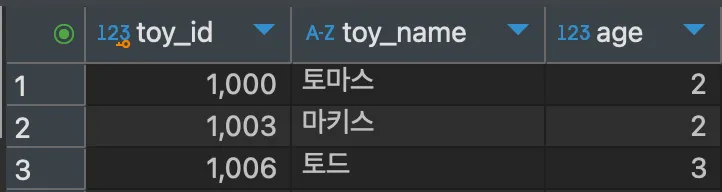
이번에는 hongong3의 모든 행에 대해 age 값을 10으로 나눈 값으로 변경하였다. 이렇게 update는 다중 열의 값만 바꿀 수 있는게 아닌, 조건에만 맞다면 조건에 해당하는 여러 개의 행의 값도 변경할 수 있다.
데이터 삭제(DELETE)
테이블에서 특정 행의 데이터를 삭제해야 하는 경우도 생기는데 이럴 때 DELETE 구문을 사용하여 특정 행의 데이터를 삭제할 수 있다.
DELETE FROM 테이블 이름 WHERE 조건;데이터를 삭제할때 사용하는 DELETE문은 UPDATE와 유사하며 DELETE는 행 단위로 삭제한다.
DELETE FROM hongong3
WHERE toy_name LIKE '%스';만약 hongong3 테이블에서 toy_name이 ‘스’로 끝나는 값을 가진 데이터를 삭제하고 싶다면 위와 같이 입력하여 해당하는 데이터들을 삭제할 수 있다.
DELETE FROM hongong3
WHERE toy_name LIKE '%스'
LIMIT 5;또한 LIMIT를 사용하여 hongong3 테이블에서 toy_name이 ‘스’로 끝나는 값을 가진 데이터 상위 5개만 삭제할 수 있다.
대량의 데이터 삭제(DELETE, DROP, TRUNCATE)
DELETE를 사용하여 데이터를 삭제할 수 있지만, 만약에 삭제해야하는 데이터의 엄청 많거나 특정 테이블의 데이터 전체를 삭제해야 한다면 시간이 오래 걸리게 된다. 그럴 때는 DROP이나 TRUNCATE를 사용하여 데이터를 삭제할 수 있다.
DELETE FROM big_table1;
TRUNCATE TABLE big_table3;
DROP TABLE big_table2;만약 DELETE를 사용할 시 조금 느리나 WHERE 조건절을 사용하여서 특정 데이터를 삭제할 수 있게 되고, 테이블을 유지할 수 있다.
TRUNCATE를 사용할 시 테이블 내 모든 데이터를 삭제하는데, 이는 DELETE보다 훨씬 빠르나 모든 데이터를 삭제하기에 WHERE 조건절 사용할 수 없다. 테이블은 유지된다.
DROP을 사용할 시 테이블 내 모든 데이터를 삭제하게 되고 테이블도 삭제되어 테이블 유지할 수 없게 된다.
즉 테이블의 구조를 유지하면서 특정 데이터만 삭제하고 싶다면 DELETE를, 모든 데이터를 삭제하고 싶다면 TRUNCATE를, 테이블도 삭제하고 싶다면 DROP을 사용하면 된다.
출처
- 혼자 공부하는 SQL(우재남 저, 한빛미디어)
