데이터베이스 모델링
데이터 모델링(data modeling)이란 주어진 개념으로부터 논리적인 데이터 모델을 구성하는 작업이다.
데이터베이스 모델링(database modeling)이란 논리적인 데이터 모델을 물리적인 데이터베이스 모델로 환원하여 고객의 요구에 따라 특정 정보 시스템의 데이터베이스 반영하는 작업을 말한다.
데이터베이스 모델링은 데이터를 담을 테이블의 구조를 미리 설계하는 개념이다. 건축에 들어가기 전 건축 설계도를 그리는 과정이라고 볼 수 있다.
데이터베이스 모델링에는 정답은 없지만 좋은 모델링과 나쁜 모델링 존재하며 나쁜 모델링은 막대한 비용을 발생시킬 수 있기 때문에 데이터베이스 모델링은 전문 서적이 따로 있을 정도로 깊게 생각해야 하는 부분이다.
그러나 데이터베이스 모델링 공부는 양도 많지만, 정말 재미가 없기 때문에 간단한 모델링으로 데이터베이스를 구성해보자.
데이터베이스 구성도
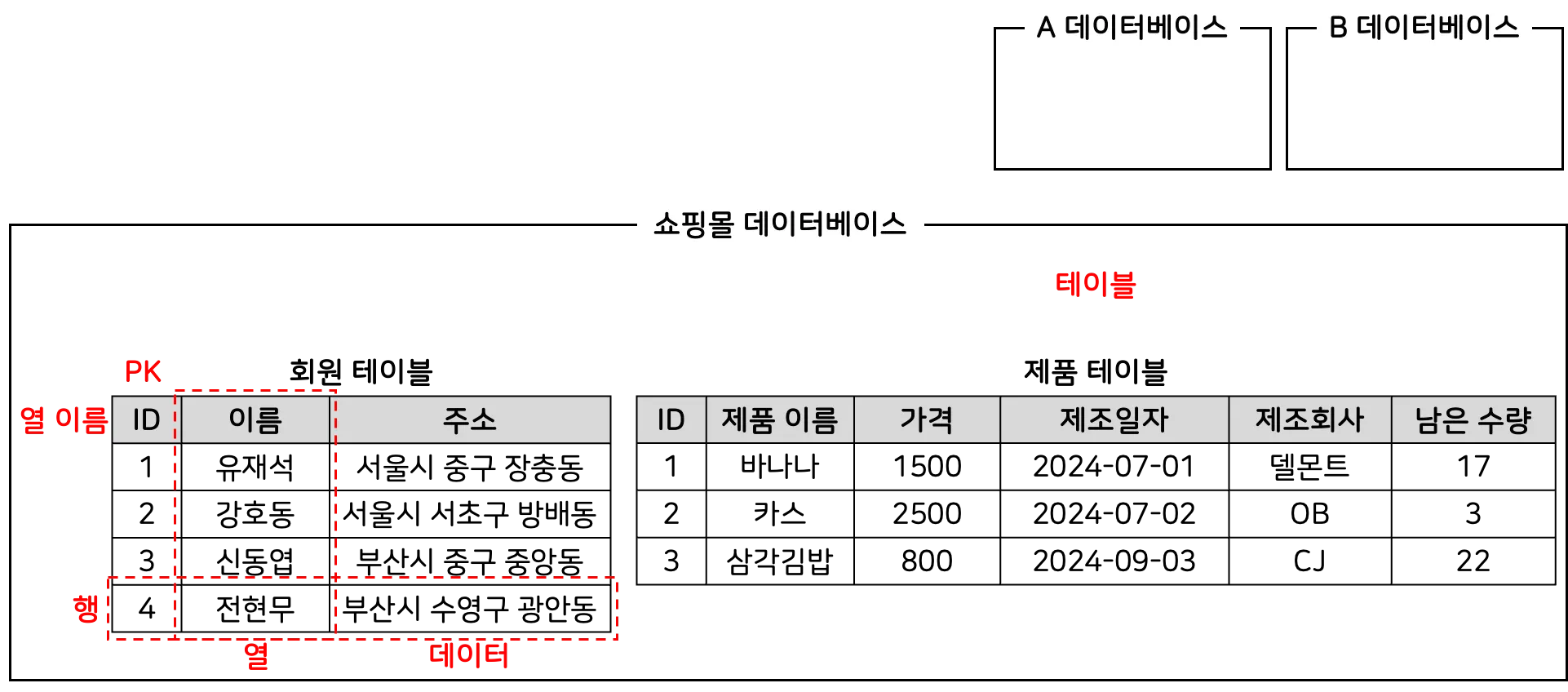
구성도에서 각각의 용어는 다음과 같은 의미를 가진다.
데이터(data)
그림에서 유재석, 2500, CJ와 같은 개별적인 정보와 같이 하나하나의 단편적인 정보를 말한다. 즉 정보를 나타내는 기본 단위이다.
테이블(table)
데이터를 구조화된 방식으로 저장하는 데이터베이스 객체로 행과 열로 구성된다.
데이터베이스(database)
관련된 데이터를 조직화하고 저장하는 시스템으로 테이블이 저장되는 저장소이다. 데이터베이스 끼리의 이름은 서로 달라야 한다.
행(row)
테이블에서 한 개체나 항목에 대한 데이터를 담고있는 한 줄로, 실질적인 진짜 데이터를 말한다. 그림에서 (1, 유재석, 서울시 중구 장충동)이 하나의 행이다.
열(column)
테이블에서 데이터의 속성을 정의하는 것으로 테이블의 세로 줄을 말한다. (바나나, 카스, 삼각김밥)이 제품 테이블에서 하나의 열이다.
열 이름(column name)
테이블에서 각 열을 구분하는 이름이다. 이름, 주소가 회원 테이블의 열 이름들이다.
데이터 형식(data type)
특정 열에 저장될 수 있는 데이터의 유형을 말하며, 회원 이름의 경우 문자 형식이고, ID는 숫자 데이터 형식이다.
기본 키(primary key, PK)
테이블에서 각 행을 고유하게 식별하는 열, 또는 열들의 조합이다. 각 행을 구분하기에 기본 키는 중복되어서는 안되며, 절대로 비어있어서도 안된다.
데이터베이스 생성
SQL을 이용하여 데이터베이스를 생성하는게 정석이지만, 시작은 편의를 위해 DBeaver를 사용하여 데이터베이스를 생성해보겠다.
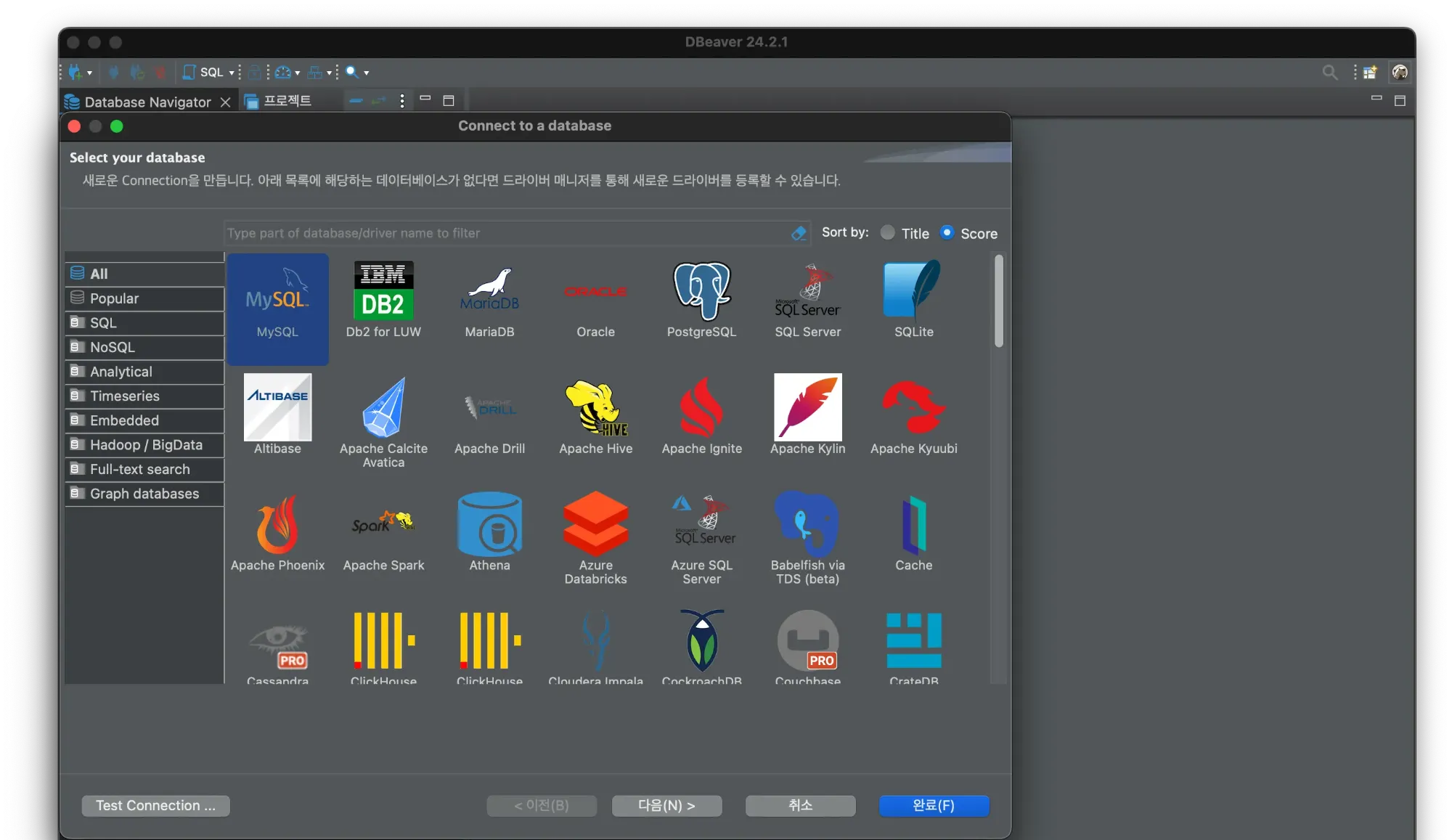
우선 DBeaver 프로그램 최상단 도구 모음의 제일 왼쪽에 있는 플러그 모양(새 데이터베이스 연결)을 클릭한 후, MySQL을 선택한다. 만약 다른 데이터베이스를 사용중이라면 사용하는 데이터베이스 맞게 선택하자.
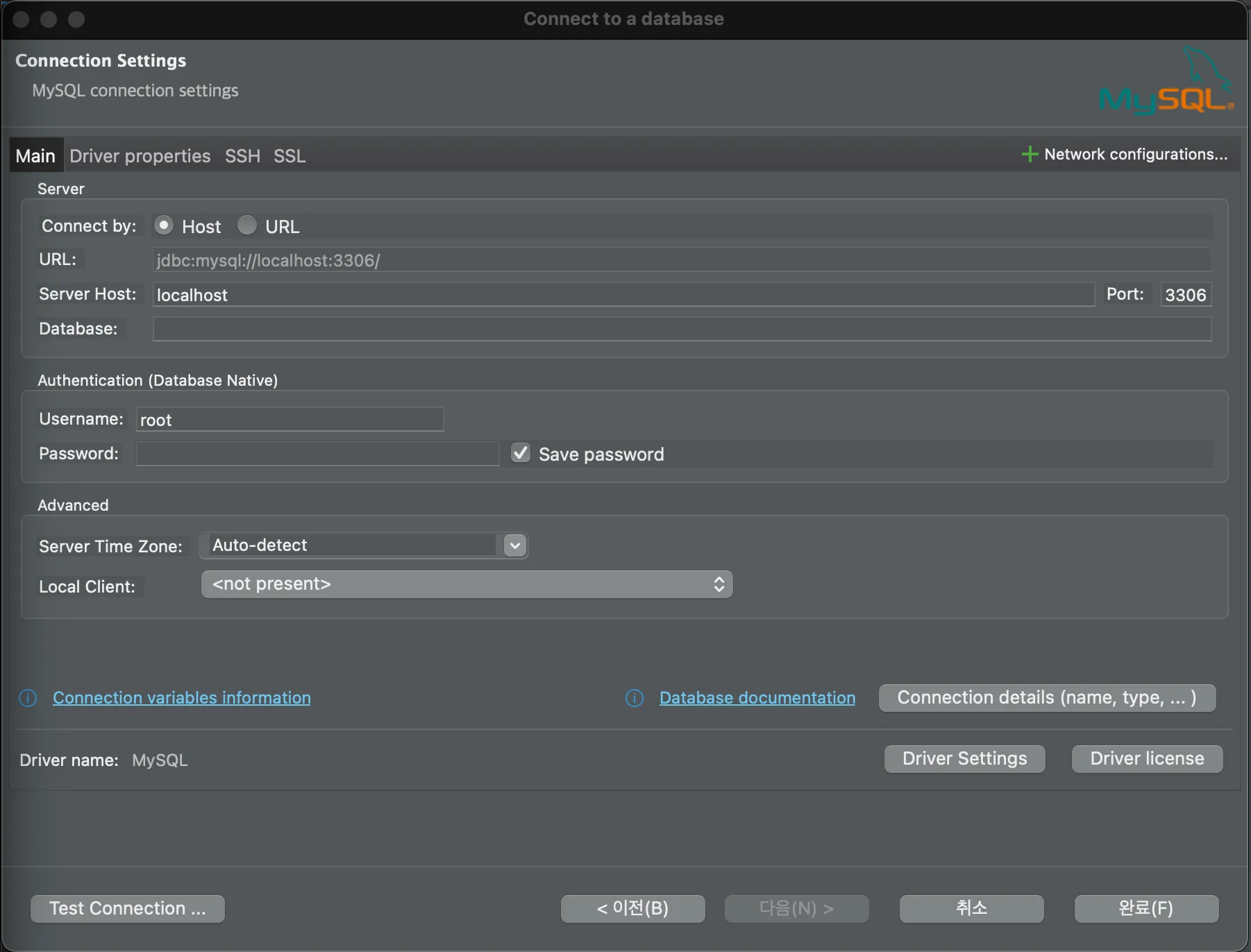
그 후, 초기 DB 설정에 맞추어서 연결을 세팅해준다. localhost 환경에서 실행할 것이기 때문에 Server 항목은 건드리지 않는다.
Authentication도 설정해주는데, 이는 사용자가 처음 MySQL을 설치하면서 설정한 Username과 Password를 입력해준다. 하나라도 맞지않으면 정상적으로 연결이 안되니, 초기에 설치하면서 설정해둔 Username과 Password는 잊지말고 기억해두자.
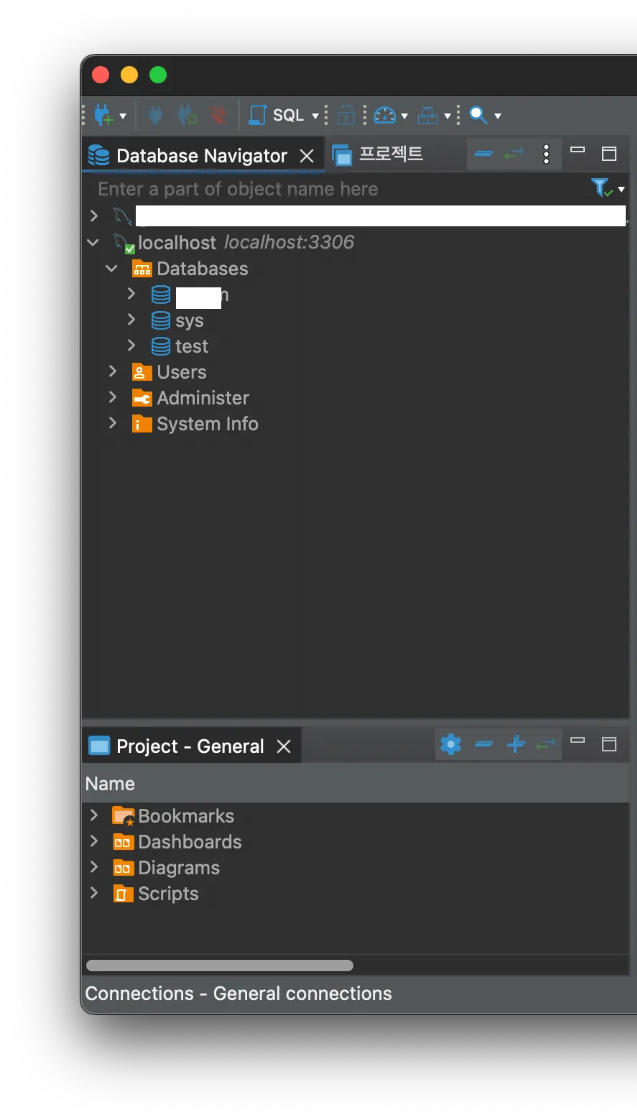
성공적으로 연결이 완료되면 Database Navigator의 하위 항목에 localhost 데이터베이스 연결 항목이 보인다. 더블 클릭할 시 내부의 데이터베이스와 시스템 정보를 확인할 수 있다. 성공적으로 연결이 된다면 체크표시가 뜬다.
데이터베이스 디렉터리를 클릭하면 현재 생성된 데이터베이스의 목록을 확인할 수 있다. 데이터베이스 폴더 위에서 우클릭을 하여서 Create New Database를 한 뒤, Database name에 shop_db라고 입력한 뒤 생성하자.
정상적으로 생성이 완료될 경우 Databases 디렉터리 아래에 shop_db가 생성된다. shop_db에서 우클릭을 하여 Create → Table을 누른다.
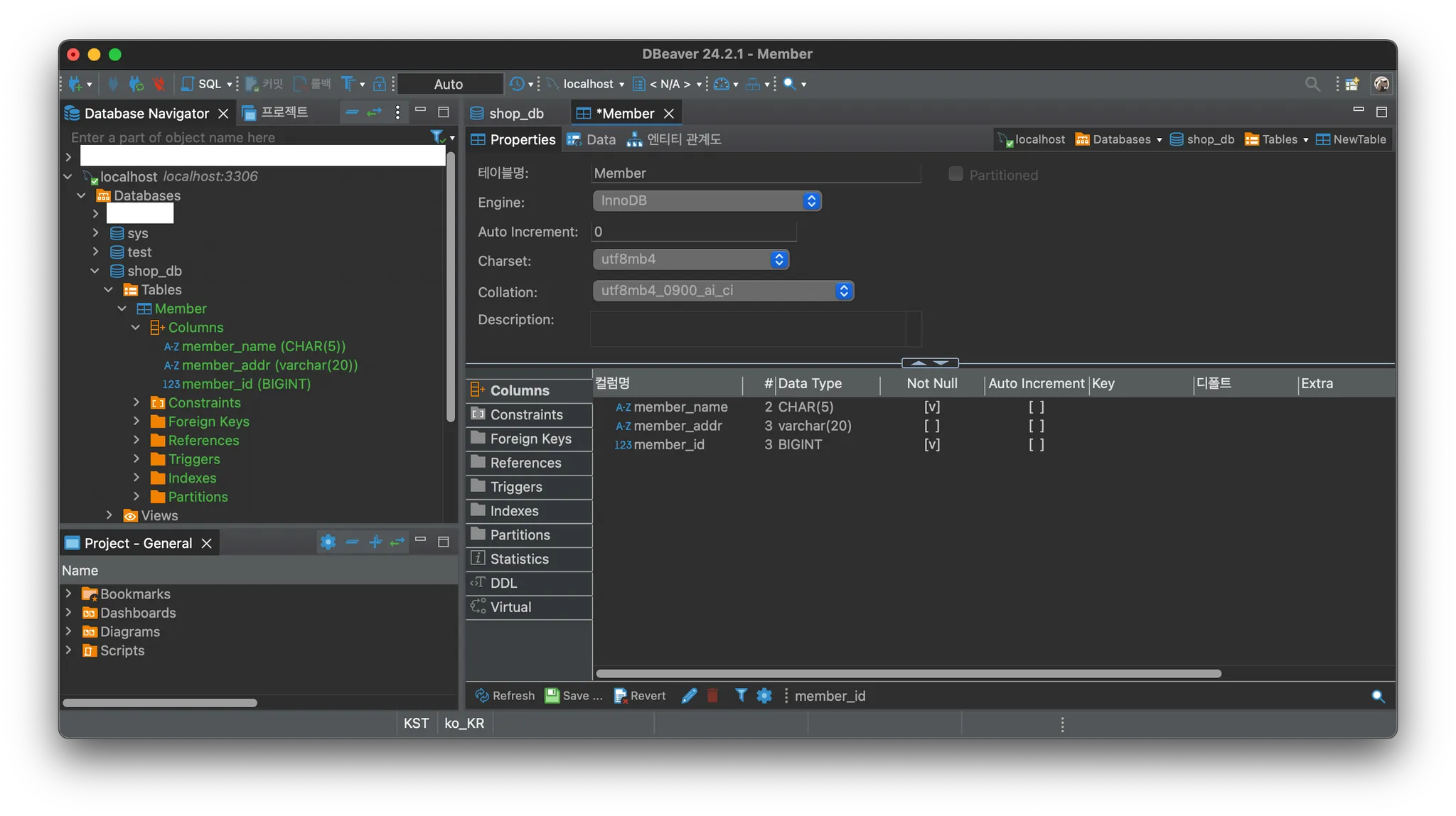
그 후, 필요한 테이블명과 컬럼을 입력한다. 컬럼은 우측 하단의 빈 공간에 우클릭 후 Create New Column을 눌러서 생성한다. 이때, member_id는 PK이므로 Keys의 Unique를 체크한 후, Type을 Primary Key로 지정한다.
생성할 테이블의 정보는 아래와 같다.
member 테이블
| 열 이름(한글) | 열 이름(영문) | 데이터 형식 | 문자의 최대 길이 | 널 비허용(Not Null) |
|---|---|---|---|---|
| ID(기본 키) | member_id | BIGINT(숫자) | Yes | |
| 회원 이름 | member_name | CHAR(문자) | 5글자 | Yes |
| 주소 | member_addr | CHAR(문자) | 20글자 | No |
product 테이블
| 열 이름(한글) | 영문 이름 | 데이터 형식 | 문자의 최대 길이 | 널 비허용(Not Null) |
|---|---|---|---|---|
| ID(기본 키) | product_id | BIGINT(숫자) | Yes | |
| 제품 이름 | product_name | CHAR(문자) | 4글자 | Yes |
| 가격 | cost | INT(숫자) | Yes | |
| 제조일자 | created_at | DATE(날짜) | No | |
| 제조회사 | company | CHAR(문자) | 5글자 | No |
| 남은 수량 | amount | INT(숫자) | Yes |
Not Null이란 널 비허용 옵션으로 설정할 경우 해당 열에는 반드시 값이 존재해야 한다. 예를 들어 ID와 같은 기본 키의 경우 행을 식별하는 고유값이 반드시 존재해야하므로 Not Null이어야 한다.
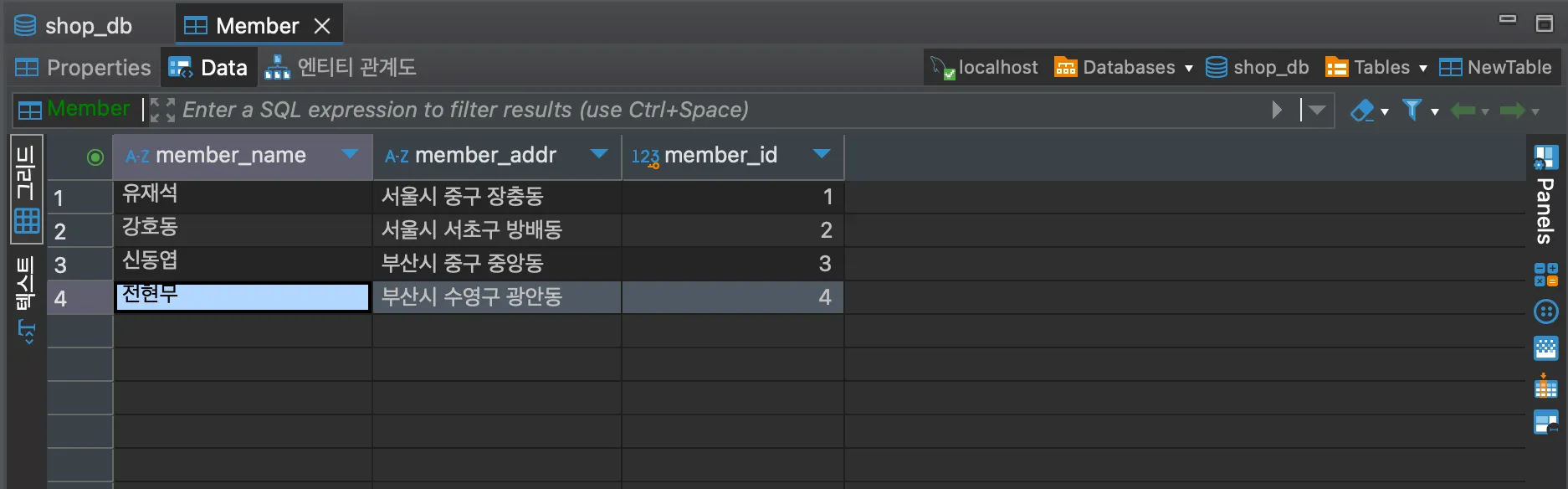
그 후, 생성된 테이블을 클릭하여 Data 항목에 들어간 뒤, 위 데이터베이스 구성에서 사용된 데이터를 삽입한다.
데이터는 해당 셀 아무곳에서나 우클릭하여 Edit → 로우 추가를 통해 추가할 수 있다. 앞서 데이터베이스 구성에서 보인 데이터들을 모두 삽입해주자.
데이터 활용하기
이제 테이블에 삽입한 데이터를 조회해보도록 하자. 생성한 shop_db에서 우클릭을 하여 SQL 편집기 → 새 SQL 편집기를 눌러서 편집기를 열고 아래 커맨드를 입력해보자.
SELECT * FROM member;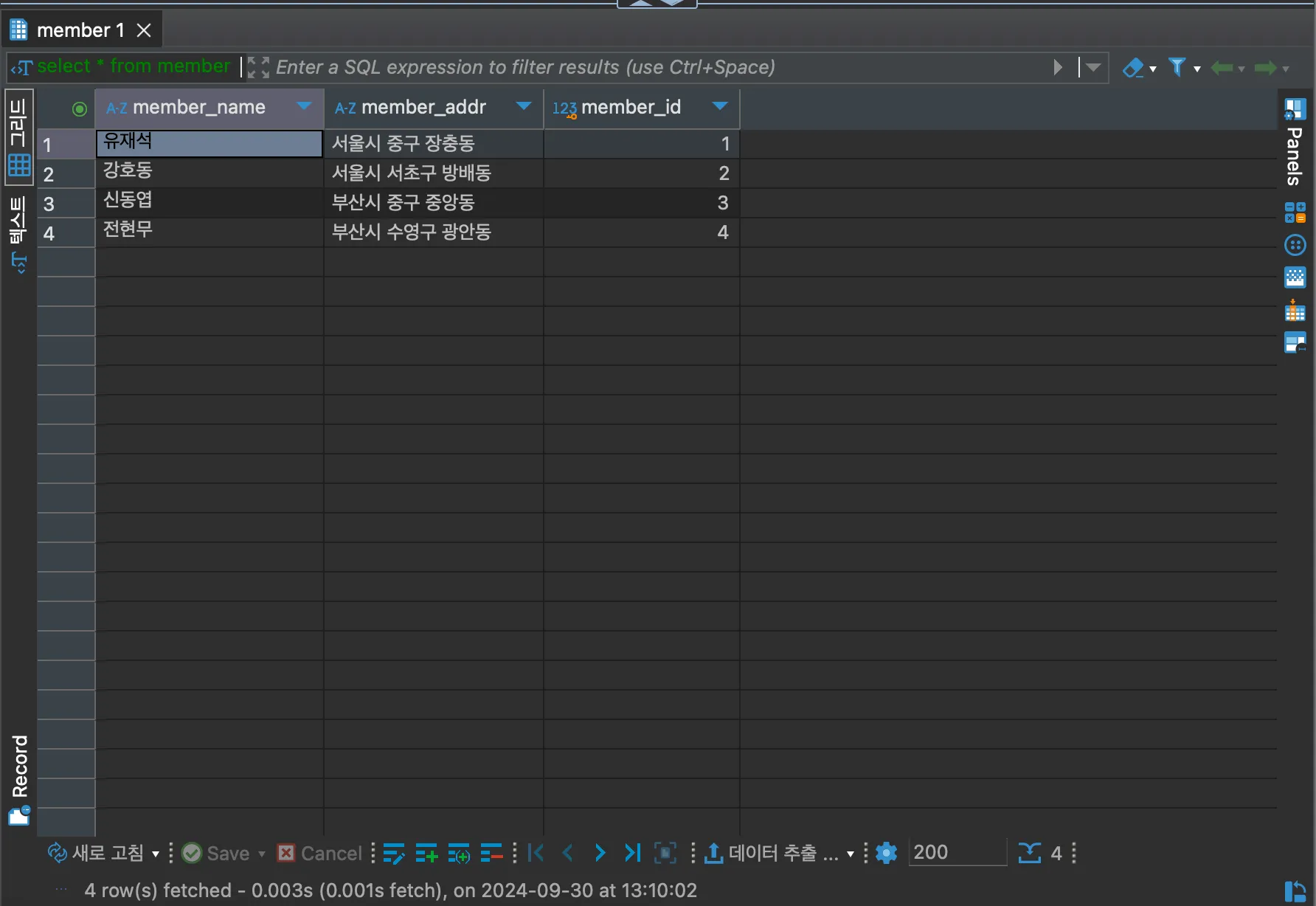
입력한 후, SQL문을 실행할 경우, member 테이블에 삽입한 데이터를 모두 조회할 수 있다. 이때 SQL은 Table name, column name, SQL 모두 대소문자를 구분하지 않으므로 SELECT * FROM member;와 select * from member;는 같은 SQL문으로 인식한다.
그러나 가독성을 위해 보통 데이터베이스 예약어(SELECT, FROM 등)는 대문자로 작성하는 것이 일반적이다. 또한 SQL의 문장 끝에는 세미콜론(;)이 있어야 한다. 없어도 동작하는 경우가 있지만 있는게 더 안전하게 때문에 항상 SQL 끝에는 세미콜론을 넣어주자.
이번에는 member 테이블에서 ‘신동엽’이란 이름을 가진 member를 조회해보자.
SELECT * FROM member WHERE member_name = '신동엽';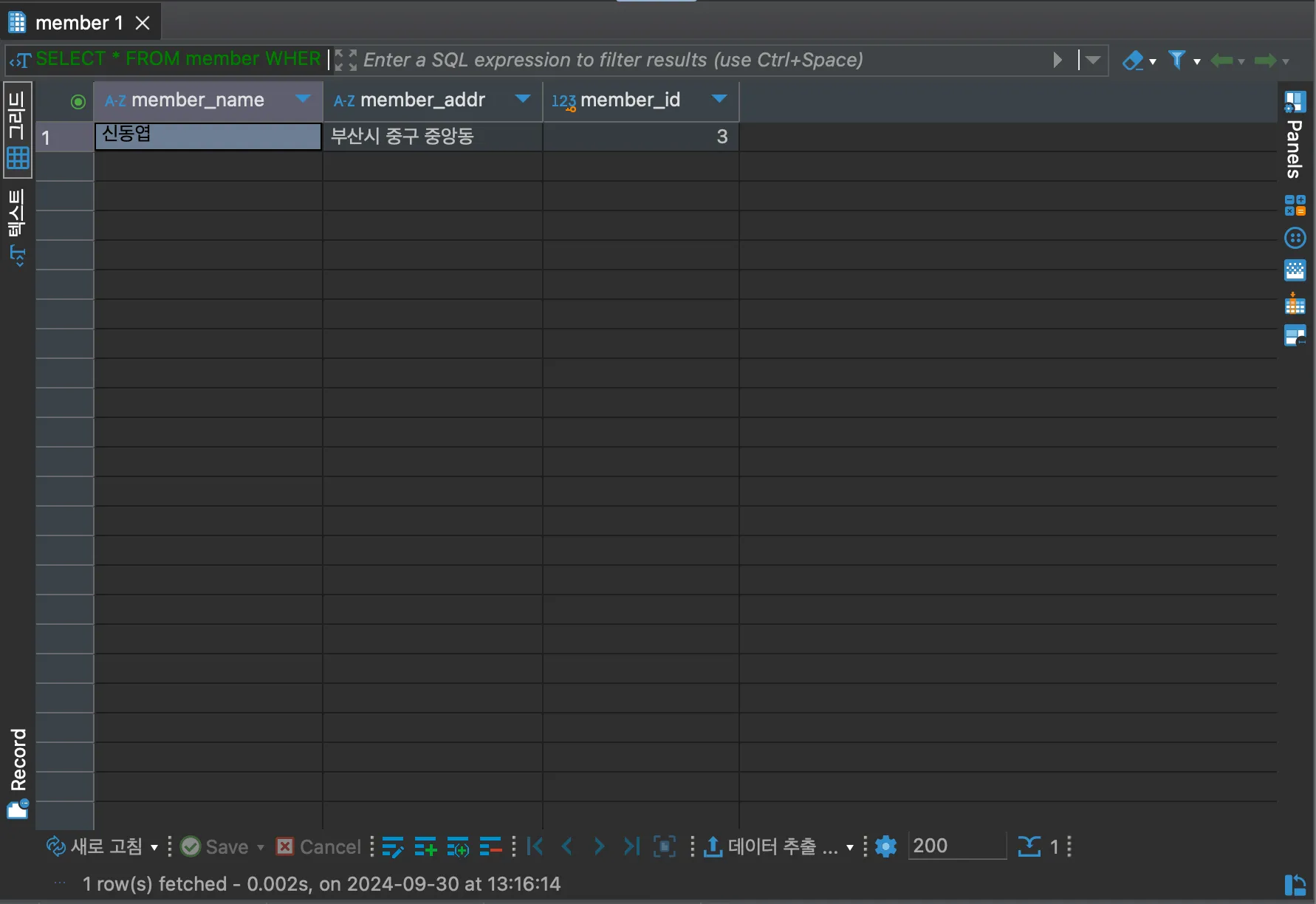
member_name은 ‘신동엽’인 사람을 조회하기 위해 WHERE member_name = ‘신동엽’ 을 추가했더니 조회가 성공적으로 되었다. 이때 ‘신동엽’과 “신동엽" 모두 맞는 문법으로 처리되나, 보통 문자열은 작은 따옴표를 사용한다. DB에 따라 다르게 동작할 수도 있으니 확인해보고 사용하도록 하자.
그러면 이번엔 member 테이블에서 ‘신동엽’이란 이름을 가진 member의 이름과 주소만 조회해보자.
SELECT member_name, member_addr FROM member WHERE member_name = '신동엽';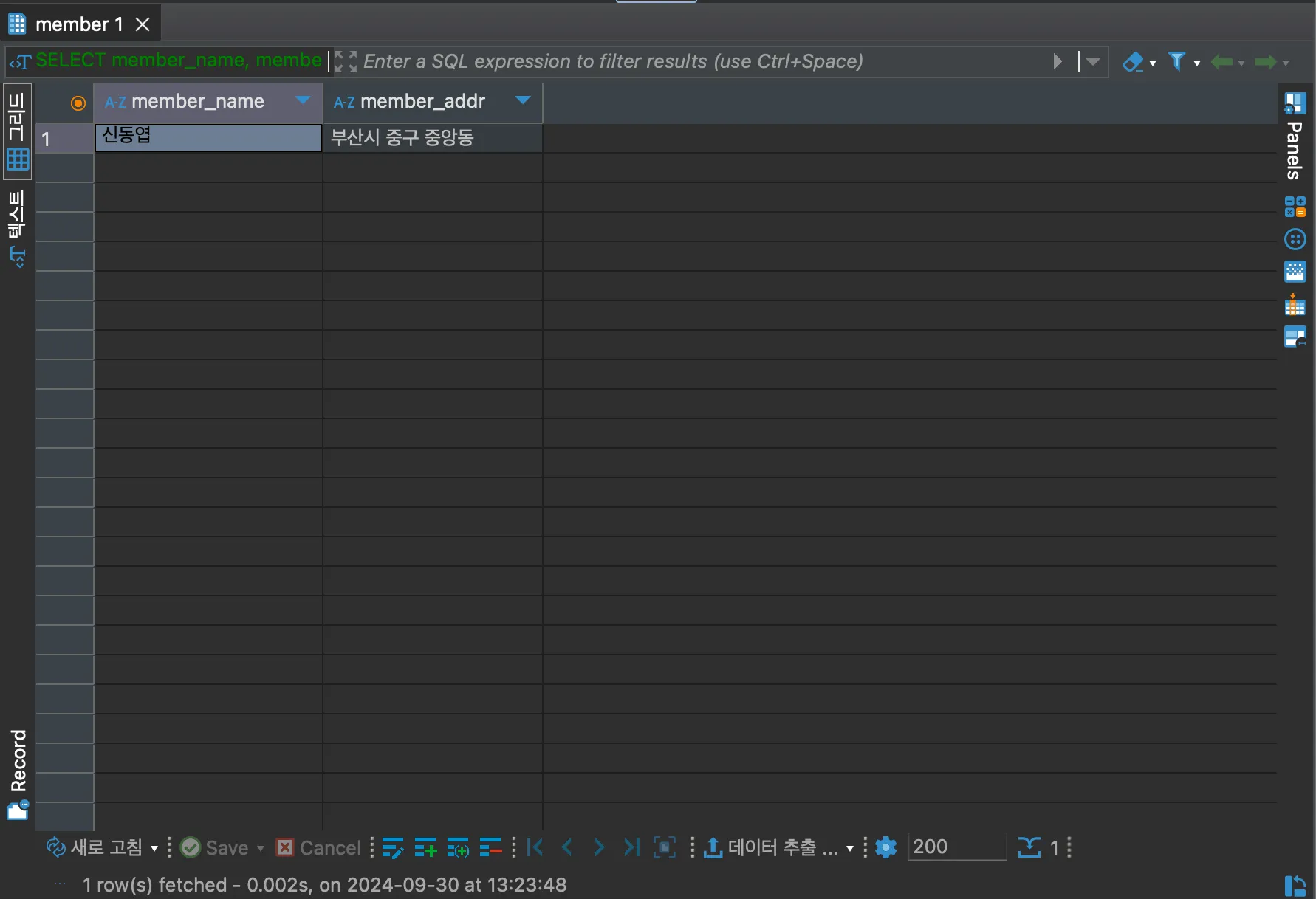
*이 있던 자리에 조회하고자 하는 열의 이름(member_name, member_addr)을 넣고 조회하니 성공적으로 member의 이름과 주소가 조회된 것을 확인할 수 있다.
데이터베이스 개체
이번에는 좀 더 어려운 개념을 적용해볼까 한다. 뒤에 가서 배우겠지만, 데이터베이스의 개체에는 테이블만 있는 것이 아니라 인덱스, 뷰, 스토어드 프로시저, 트리거, 함수, 커서 등의 개체가 존재한다.
인덱스는 데이터가 조회될 때의 속도를 매우 빠르게 만들어주고, 뷰는 테이블의 일부를 제한적으료 표현할 때 사용한다. 스토어드 프로시저는 SQL에서 프로그래밍이 가능하도록 해주고, 트리거는 데이터가 들어가거나 사라질 때의 특정 동작이 행해지도록 한다.
인덱스(index)
인덱스(index)란 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다.
테이블에 들어있는 데이터의 크기가 작다면, 데이터를 조회할 때 크게 속도에 문제가 없지만 데이터가 1억 건과 같이 굉장히 많은 양의 데이터가 쌓이면 데이터를 조회하는 시간은 굉장히 오래 걸린다.
이런 문제를 해결하기 위해 인덱스란 개념이 나왔는데 인덱스란 책의 맨 뒤에 있는 ‘찾아보기’와 같다. 찾아보기에서 특정 단어나 개념을 찾으면 그 옆에 해당 단어가 나온 페이지 수를 확인하여 금방 찾아가는 것과 같이 데이터를 빠르게 조회할 수 있도록 돕는다.
우선, 실제로 1억 건의 데이터를 삽입할 수는 없기 때문에, 조회에서 어떤 차이가 일어나는지 확인해보도록 하자. SQL 편집기에 아래 SQL문을 입력하고 ctrl + shift + e를 눌러서 execution plan을 확인해보자.
SELECT * FROM member WHERE member_name = '신동엽';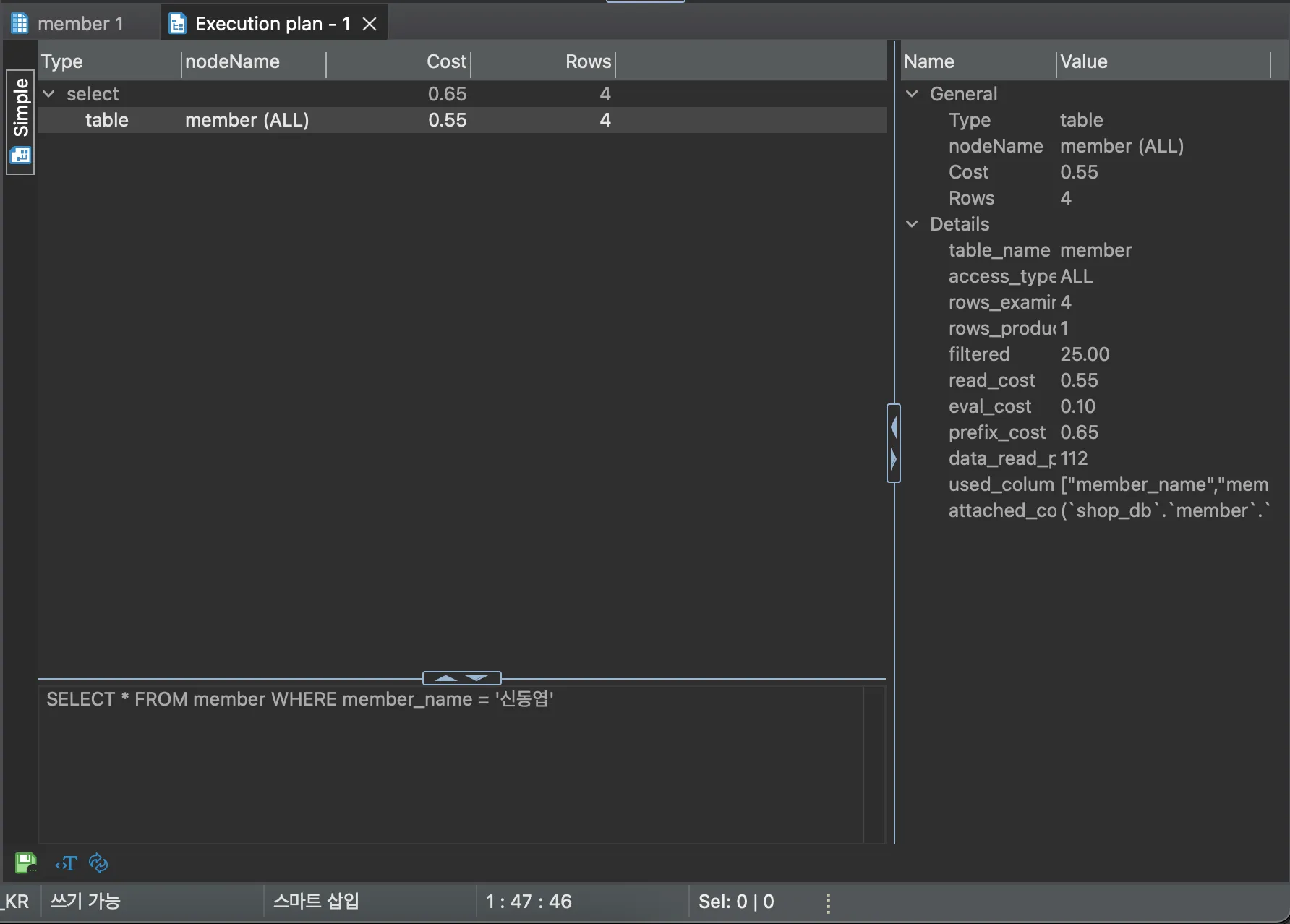
확인할 경우 access_type이 ALL로 표시되는 것을 확인할 수 있다. MySQL workbench에서 확인하면 full table scan이라고 확인할 수 있는데, 전체 테이블을 검색했다라고 이해하면 된다. 즉 테이블을 처음부터 끝까지 확인한 것이다.
이번에는 member_name에 인덱스를 생성한 후에 조회해보도록 하자.
CREATE INDEX idx_member_name ON member(member_name);위 SQL문을 입력하여 인덱스를 만드는데 ON member(member_name)은 member 테이블의 member_name 컬럼에 인덱스를 지정하라는 의미이다. 지정 후, 다시 앞선 ‘신동엽’을 조회하는 SQL문을 실행하면 execution plan이 바뀌는 것을 확인할 수 있다.
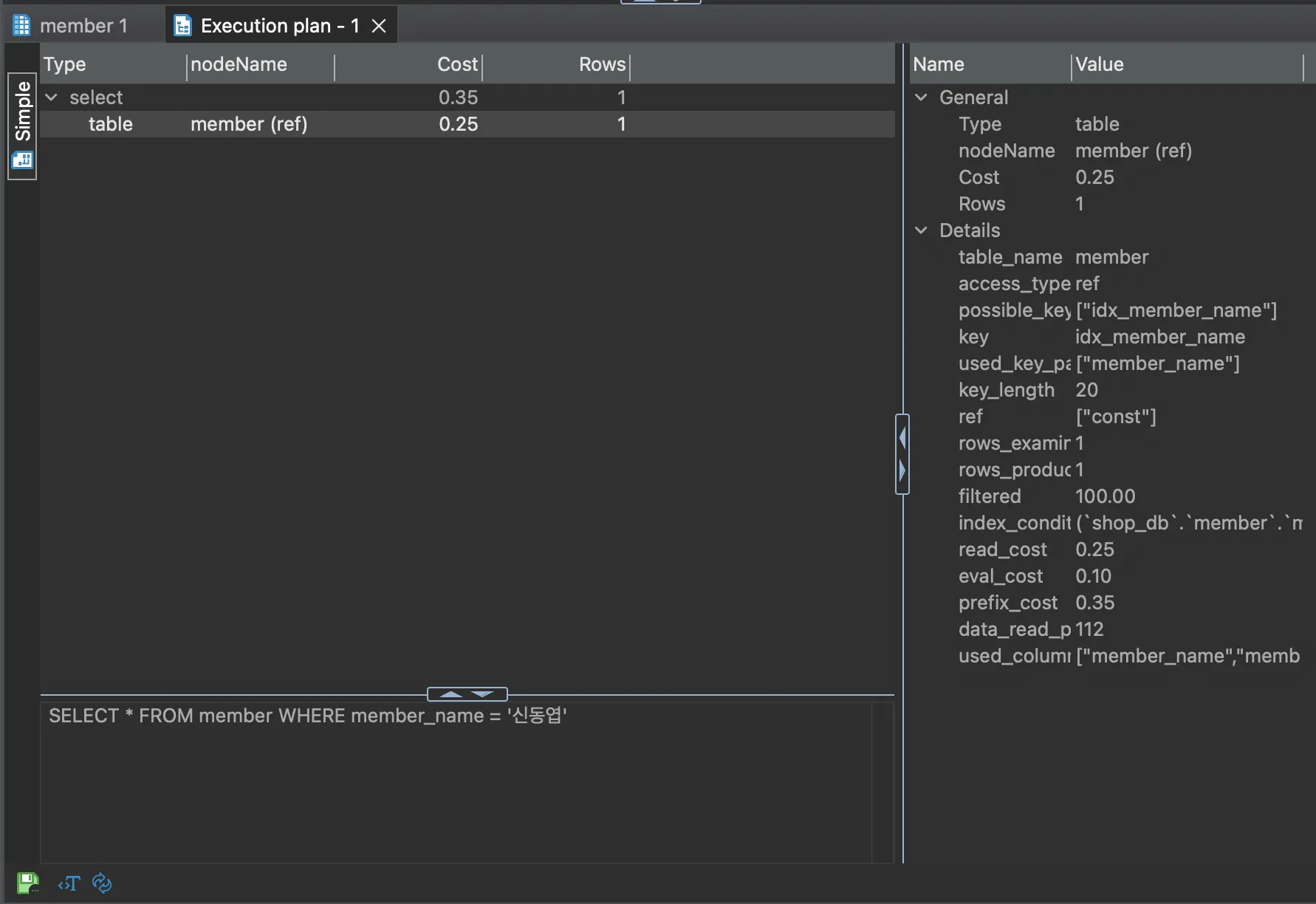
access_type이 ALL에서 REF로 바뀐 것을 확인할 수 있다. MySQL workbench에서는 Non-Unique Key Lookup을 확인할 수 있는데, Keep Lookup은 인덱스를 통해 결과를 찾은 걸로 이해하면 된다. 이를 인덱스 검색이라고 한다.
다만 인덱스를 생성하는 것이 무조건 좋은 것이 아니며, 조회에서 높은 성능을 보이는 것이지 나머지 삽입, 수정, 삭제에서 더 나쁜 성능을 보이니 신중하게 고려하여 사용하는 것이 좋다.
뷰(view)
뷰(view)는 관계형 데이터베이스의 SQL에서 하나 이상의 테이블 (또는 다른 뷰)에서 원하는 모든 데이터를 선택하여, 그들을 사용자 정의하여 나타낸 것이다.
뷰는 즉 ‘가상의 테이블’이라고 할 수 있다. 일반 사용자 입장에서 테이블과 동일하게 취급하면 되지만, 뷰는 실제 데이터를 가지지 않으며, 진짜 테이블에 링크(link)된, 바로가기 아이콘과 비슷한 개념으로 이해하며 된다.
아래 SQL을 입력하여 회원 뷰를 생성해보도록 하자.
CREATE VIEW member_view
AS
SELECT * FROM member;그리고 member 테이블을 조회하는 것이 아닌, member_view에서 데이터를 조회해보도록 하자.
SELECT * FROM member_view;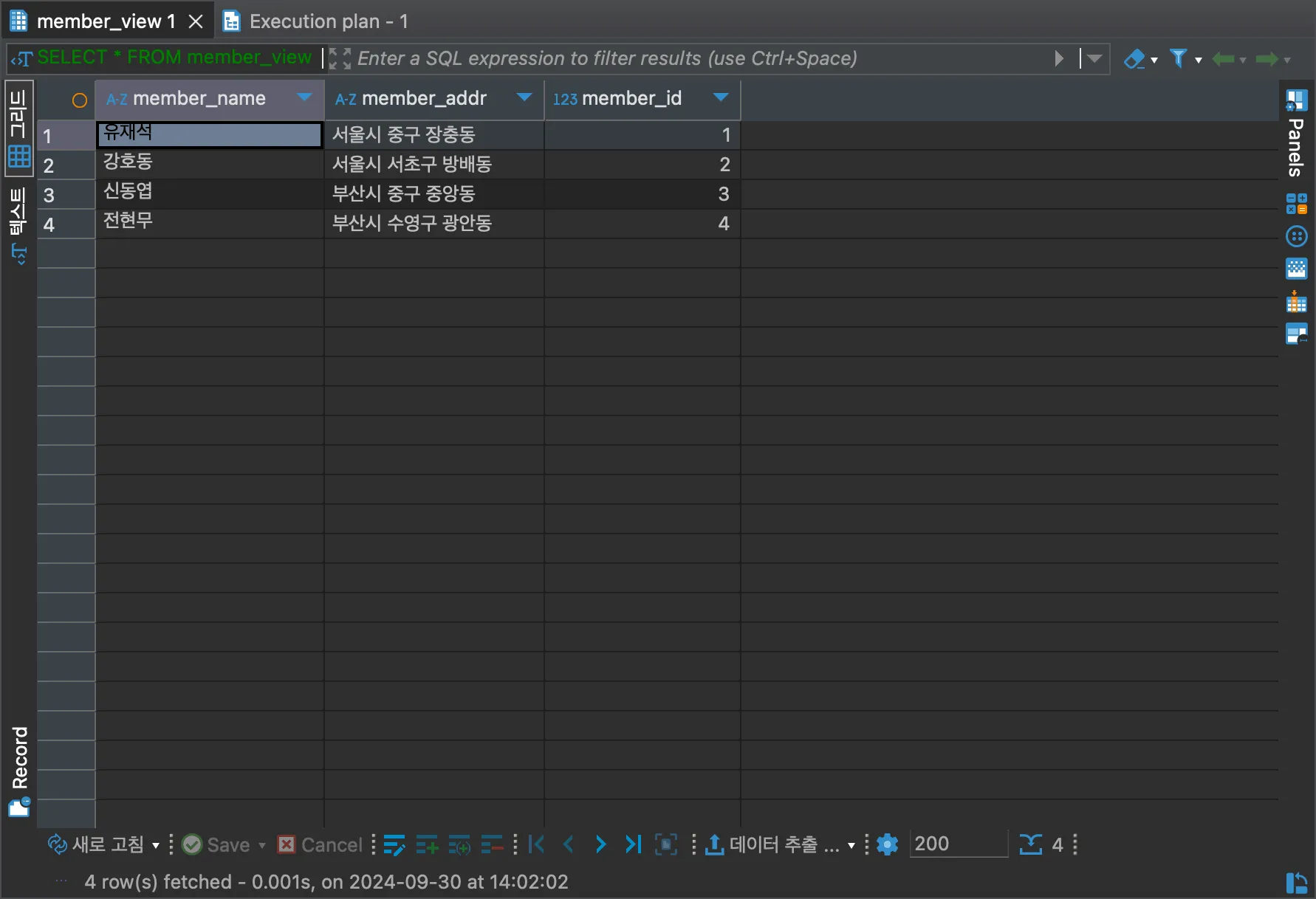
member 테이블을 조회한 것과 똑같은 결과를 확인할 수 있다. 즉 사용자는 테이블에 접근하는 것이 아닌 뷰에 접근하여 SELECT하고, 뷰는 테이블과 내부적으로 연결되어 실제 데이터값을 불러올 수 있다.
이러한 뷰를 사용하는 이유는 우선 보안에 도움이 되고, 긴 SQL 문을 뷰를 생성하면서 간략하게 만들 수 있다는 장점이 있기 때문에 사용한다.
스토어드 프로시저(stored procedure)
스토어드 프로시져란 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합이다.
이는 MySQL에서 제공하는 프로그래밍 기능으로 여러 개의 SQL문을 하나로 묶어서 편리하게 사용할 수 있다. 간단한 스토어드 프로시져를 생성해보도록 하자.
DELIMITER //
CREATE PROCEDURE myProc()
BEGIN
SELECT * FROM member WHERE member_name = '나훈아';
SELECT * FROM product WHERE product_name = '삼각김밥';
END //
DELIMITER ;여기서 DELIMITER (구분자)는 (구분자)를 SQL의 끝을 표시하는 문자로 설정하는 SQL로 일시적으로 세미콜론이 아닌 다른 문자를 구분자로 사용하겠다는 것이다. 즉, PROCEDURE 내부에 SELECT ~;로 문장이 끝나지 않고 성공적으로 END까지 하나의 SQL문으로 입력될 수 있도록 만들어주는 것이다.
위 스토어드 프로시저를 입력하고, 아래 SQL을 실행해보도록 하자.
CALL myProc();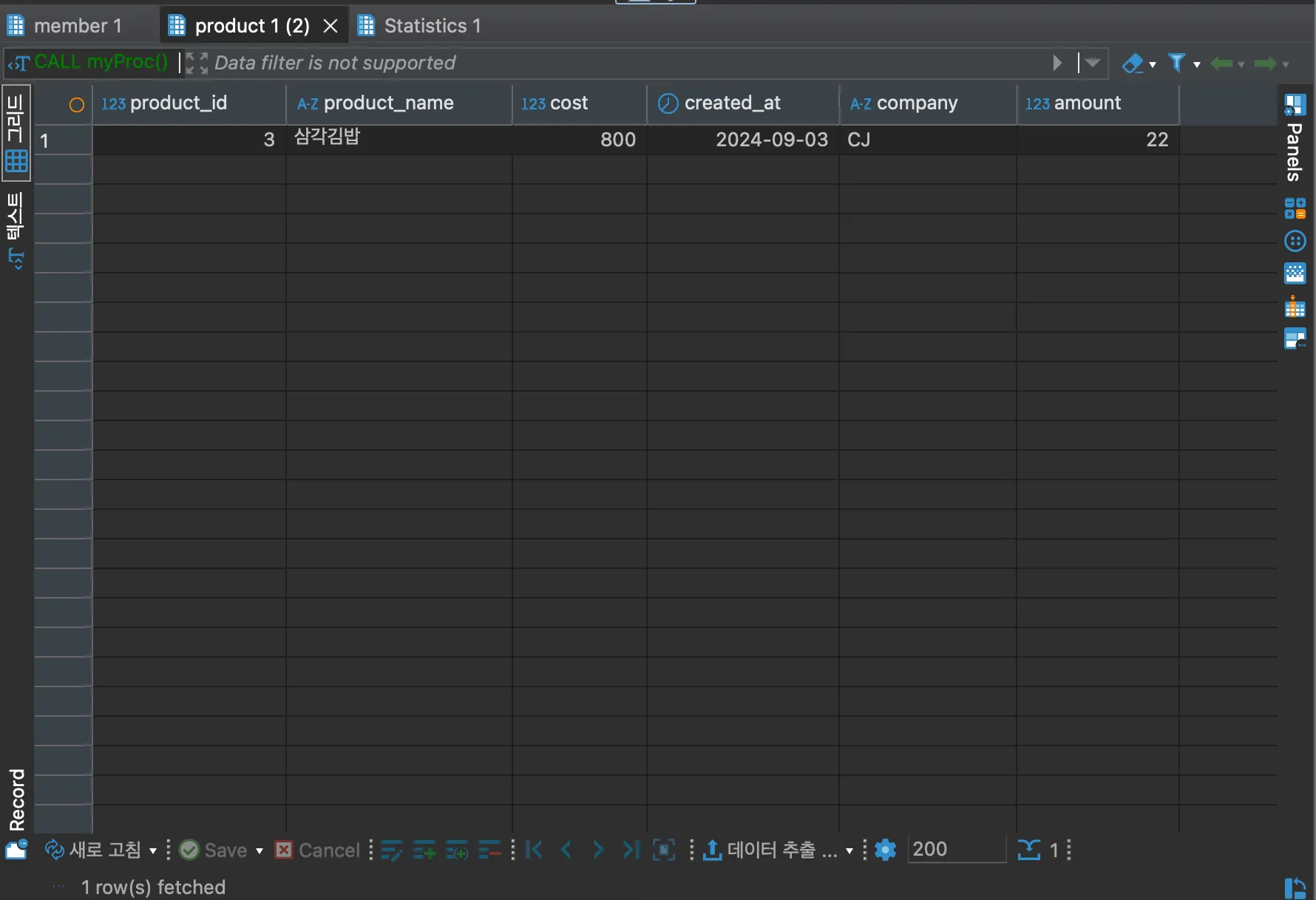
실행하면 member 테이블에서 조회한 결과와 product 테이블에서 조회한 결과를 모두 확인할 수 있다. 즉 하나의 함수 호출로 2개의 select 문을 호출한 결과를 얻을 수 있는 것이다.
즉 스토어드 프로시저를 통해 긴 SQL을 간소화할 수 있다. 생성한 프로시저는 아래 SQL로 삭제할 수 있다.
DROP PROCEDURE myProc;출처
- 혼자 공부하는 SQL(우재남 저, 한빛미디어)
- 위키피디아
