직면한 상황
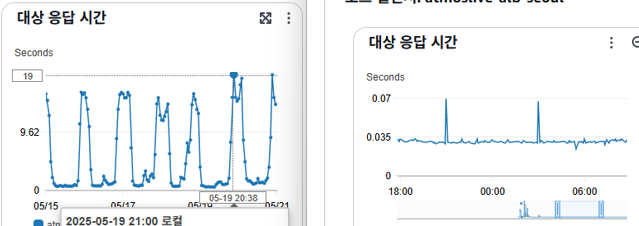
- 서버의 request 처리속도가 평균
19초가 소요되었고, 서비스 결과의 대부분이500대 Response를 제출하였다.
- 서버의 request 처리속도가 평균
- 서버는 Singapore, DB는 Seoul, EFS는 Singapore에 위치하였다.
- AWS EC2 Instance는 T3.Large를 사용하고 있었으며 Auto Scaling Group을 통하여 제어된다고 인계받았다. (다만, 상세한 상황은 후술한다.)
- 대부분의 요청은 서울을 위시한 한국/일본에서 발생하였다.
문제를 더 깊게 보기
- 일단 간략히 파악한 사항은 아래와 같다.
대부분의 수요는 서울에서 발생하나, 모종의 사유(아마도 법적 주체 등)로 싱가포르에 위치하였다.
DB가 서울에 위치한 경위와 싱가포르에 서버가 위치한 경위에 관해서는, 아무도 알지 못했다.
- 일단 간략히 파악한 사항은 아래와 같다.
- 트래픽이 몰리는 첨두시간대에, AutoScaling은 작동하지 않았고, 인스턴스의 Cpu가용량은 10%를 넘지 않았다.
- 서버와 DB를 연결하는 Connection간
ConnectionLimit = 3이었으며, 이는 초당 50K를 넘는 리퀘스트와 RTT를 수용하지 못 하고 Queue Overflow를 발생시킨 것으로 추정하였다.
- 서버와 DB를 연결하는 Connection간
- Server-DB간 RTT는 싱가포르-서울을 다녀오면서 100ms가 넘었다.
- 파일 시스템이 싱가포르에 있는점은 문제없었다. 다만, Prisma를 사용한 것으로 보아 연산속도 지연을 사유로 더 빠른 RTT가 필요하다 판단하였다.
- 비용 문제 이야기를 꺼냈었다. 2번문제와 결합해 비용을 내릴 여지가 충분함을 입증할 수 있다.
해결을 위한 과정
- 그러므로, 나는 두가지 관점으로 개선 가능하다 판단하였다.
Option 1. Server 연산 시간 및 대기 지연 감축
- 서버의 연산시간 분석부터 시작하였다.
첫번째 문제 : Round-Trip time
Round-Trip Time이란 : 하나의 패킷이 날라갔다 돌아오는 시간을 의미한다. 이 속도로부터 문제가 있을 것을 예상했다.- 일단 아주 간단한 문제가, 싱가포르 - 서울간
Round-Trip Time문제였는데, 이는 아래의 방식으로 확인가능했다.
$ : time nc -z -v <db_IP>- 서울에서는
0.007초, 싱가포르에서는0.075초가 나왔다. 10배가까이 줄일 수 있을 것으로 기대하였다. - 좋다. 일단, 뭔지 이유를 모르겠어서 PM에게 DB를 인스턴스가 있는 싱가포르로 이전시키겠다고 했으나, 서울로 인스턴스 이전을 결정한다.
- 따라서, 이에 종속된 설정과 EFS를 포함해 인프라를 모두 서울로 이전시킴으로서 문제를 해결하였다.
두번째 문제 : ConnectionLimit
ConnectionLimit: DB의 연결은 일종의 자원과 같다고 할 것이다. 그런데 너무 많은 연결 요청이 오는 경우, DB는 뻗어버리고 만다. 그러한 문제를 방지하기 위해, 클라이언트측으로부터 연결 수에 제한을 둔다.- Prisma를 기본 클라이언트로 쓰고 있었던데, 이 lib는 기본값으로
num_physical_cpus * 2 + 1의 수식으로 제공한다. - 그런데,
num_physical_cpus=1인 환경에서 별도의 설정이 없다면ConnectionLimit=3이 된다. (t3.large는vcpu = 2이지만,num_physical_cpus=1로 잡는듯 했다.) - 이는 실제로 쇄도한 초당 50k의 request를 견딜 수 없었다고 판단하며, pool size도 늘려서 cpu 점유율을 충분히 사용가능하게 하는 것이 필요했다는 것을 의미한다.
- 따라서, Prisma의 설정 방법을 따라
ConnectionLimit를 10이상으로 늘려두었다.
결론
- 이 두 방안이 실행되고 난 이후, 최소
400ms가 걸리던 테스트가30ms로 축소됨으로서 한 인스턴스당 통신 가용량을 최대한 늘어났다고 볼 수 있었다. - 그 다음 문제를 볼 때였다.
Option 2. Instance 사용 합리화 (Right Scale)
-
위에서,
AWS EC2 Instance는 T3.Large를 사용하고 있었으며 Auto Scaling Group을 통하여 제어된다고 인계받았다.고 하였고, 이는Auto Scaling Group을 통한 수평 제어조건을 충족시켜야 한다는 사실을 의미한다. -
그런데,
- 2. 트래픽이 몰리는 첨두시간대에, Auto Scaling 은 작동하지 않았고, 인스턴스의 Cpu가용량은 10%를 넘지 않았다.고 하였던 것을 보아,Auto Scaling이 명백히 허울임을 확인하였다. -
일단
Auto Scaling의 조건을 보았는데, Scale out 조건을Cpu 사용량 >= 50%를 조건으로 하고있었다. 이것이 위의 사건으로 인하여 의도한 Scale Out이 일어나지 않은 이유이다. -
때문에, 나는 한 가지 결정을 했다.
일단 서울로 이전 시킨 다음날, 서버의 사용량을 본다.
일단 fail-back을 위해서, Large를 하나, medium을 하나 둔다.
이후, medium이 20% 이상 소모하지 않는다면, Large는 필요없던 것이 아닌가? -> (Large의 Medium의 RAM은 2배이므로.)
그러므로, medium인스턴스의 최대 Cpu사용량이 20%이상을 찍지 않으면 인스턴스 사이즈를 medium으로 내리고, 예산을 줄여도 충분하다고 판단한다. -
결론은, 첨두시간대에도 두 인스턴스 모두
6%대 였어서 t3.medium으로 변경 이후 다음날까지 지켜보았다. -
medium으로 감축한 다음날에도
25%까지만 가용하였다. 꽤 충분하다고 여기고 (사실 조금 더 튜닝하면 small까지야 가능은 하겠다만.) 일단 여기서 작업을 마무리했다.
차기 개선 지점
- AWS DB 복제사용
이 부분은, 다중 지역화를 요구받을 때 읽기 전용 DB를 다수 지역에 배치함으로 여러 지역에서 사용가능 할 것으로 생각된다.
- AWS DB 복제사용
- S3 관련 튜닝
결론
-
그렇게 서버를 이전하고, 정비한 이후 아래와 같은 스펙을 얻는다.
기존 응답시간 19초 -> 0.035초, 대상 5xx 48k=>0
사용 예산 일 11$ -> 2 $ -
100배정도의 쿼리 개선 속도와 상당한 효과를 얻고 일단 여기서 마무리를 하였다. (여전히 p99이 마음에 안들기는 한다.)
-
Scale Out이 능사라고 생각하는 경우가 있을 수 있는데, 그 이전에 Scale을 다 쓸 수 있는지부터 알아보고 Scale out을 하기를 권한다.
-
사용예산이 감소한 이유는 AWS공식 문서를 보면, 나와있다.
리전 간 VPC 내부 통신을 하는 경우
워크로드 구성 요소가 VPC 피어링 연결 또는 Transit Gateway를 사용하여 여러 리전에서 통신하는 경우 추가 데이터 전송 요금이 부과됩니다. VPC가 리전 간에 피어링되는 경우, 표준 리전 간 데이터 전송 요금이 부과됩니다. -
때문에, 요금 폭탄을 피하기 위해서는 리전간 통합을 가능한 한 수행해야 한다.