
1~4까지는 machine independant. 4번에서 macine dependant 코드를 만들어 낼 것
1~4 는 frontend, 5~6은 backend
Scanner, Parser,
Abstract syntax trees(syntax tree) 그냥 요약임 != Parse Tree

symentic analysis 는 annotation 이 있고,
위에꺼는 없음
annotated syntax tree 라고 함.
static 한 부분만 봄. dynamic은 안 보고, 타입 체킹을 함. attribute 를 하고, annotation을 하는 부분이 핵심
optimizing 과정에서는 input이 machine code일 수도 있다.
knowledge of the machine 을 아는 경우만.
code generation 단계에서도 optimization이 가능함
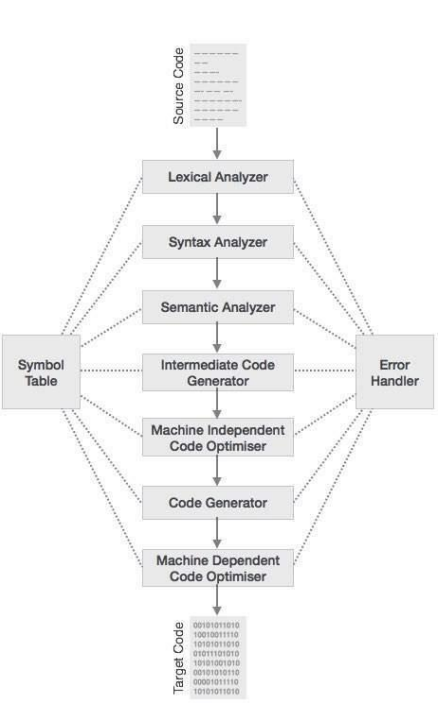
여기서 machine independent code optimizer 부분은 analysis 파트, code generator, machine depenent code optimiser 부분은 synthesis 라고 하는 파트임.
윗 부분은 그래도 찾기 쉽지만, 아래 부분은 machine 별로 다르기 때문에 찾기도 어려움.
frontend, backend 로 나누는 기준에서는 front 와 analysis, backend와 synthesis 가 서로 유사함
front 는 source code만 담당, backend는 target code만 담당함.
Pass 개념은 1단계 분석, 2단계 source code, 3단계 target code느낌으로 작동한다.
한 번에 다 작동하기는 어렵기에 여러 단계에 거쳐서 단계단계 작동한다는 것 뿐. 꼭 이렇게 정해진 것은 아니다
Error handling 은 모든 곳에 위에 사진처럼 작동해야 한다. 소스 코드가 어떤 부분에서 터졌는지 알려줘야 함. 각 Phase마다 핸들링 방식이 다름
Tiny Language 란
Structure
;로 끝나는 것
정수만 있고 그냥 대입하면서 변수가 생성됨
if도 end로 끝난다.
{}로 주석 처리를 하고, 중첩도 안됨
Expression
Boolean, Integer만 연산 가능함
+-*/ 같은 것도 정수형 기준으로만 처리되고, 아닌 것들은 처리 안됨
Boolean 은 조건문에서만 다뤄지고, 실제로 다뤄지지는 않음
{ Sample program
in TINY language –
computes factorial
}
read x; { input an integer }
if 0 < x then { do not compute if x <= 0 }
fact := 1;
repeat
fact := fact * x;
x := x – 1
until x = 0;
write fact { output factorial of x }
endsimple code
약간 script 같은 느낌
Scanner 라는 게 이제 실제로 Token 단위로 다 쪼개주는 과정이다.
9/14
Lexeme
xyz 만 있는 경우 같은 거를 보면
(x+y)?.[^x-y] 같은 거를 xxy(x|y|z)z|(x|y|z)z
(xxy|입실론)|(x|y|z)z 같은 것으로 쓸 수도 있음
같은 형식으로 바꿔버릴 수도 있다.
