캐릭터 필터 : 문자열 변경
토크나이저 : 문자열을 토큰으로 분리한다. 순서, 시작, 끝위치
토큰 필터 : 분리된 토큰의 필터 작업 한다 대소문자, 형태소 분석...
역 인덱싱
단어가 몇 페이지에 있는지를 색인(역 인덱싱)
분석기는 analyze라는 rest api가 있음
자주 사용되는 분석기
standard : 기본임. 영문법 기준 스탠다드 토크나이저, 소문자 변경 필터, 스톱 필터
simple : 문자만 토큰화. 공백, 숫자, 하이픈, 작은따움표 제거
whitespace : 공백 기준 토큰
stop : simple + 스톱 필터
분석기는 하나 이상의 토크나이저
토크나이저
standard : 쉼표, 점 제거 후 텍스트 기반
lowercase : 문자 소문자
ngram : n글자 짜리 모든 조합을 다 만들어냄. 메모리 소비 큼
uax_url_email : standard와 유사 URL이나 이메일 토큰화 강점 있음
분석기는 하나의 토크나이저 + 다수의 필터(없어도 무관)
캐릭터 필터 : " " nbsp를 공백으로 바꾸는 느낌
대부분의 분석기는 캐릭터 필터가 없음. 커스텀 분석기를 만들어야 함
토큰 필터 : 수정, 삭제가 잦음. 가이드에서 확인 가능
lowercase, stemmer : 영어 문법
stop : 기본 필터에서 제거 못 하는 특정 단어 제거 가능
stop 은 불용어 사전 등록
stemmer : loving - loved - love 같은 어간으로 봄
커스텀 분석기 : 특별한 형태의 분석기를 만들 수 있다. 순서, 조합을 다 자유롭게 가능
필터는 가능한 소문자 같은 통일이 우선되어야 함
쿼리 컨텍스트와 필터 컨텍스트
쿼리 컨텍스트는 캐싱 불가능. 내부 스코어 계산이 들어감
필터 컨텍스트는 캐싱 가능. 스코어 연산도 없음
hits 안에 total 안에 value가 실제 검색된 순서
배열이 유사도를 비교했을 때 적절하게 높은 순으로 정렬됨
요즘은 논리 쿼리가 나오면서 필터 컨텍스트가 논리 쿼리로 들어가버림
두개를 조합하는 추세
유사도 점수 기본 BM25 알고리즘.
계산 과정
IDF
빈도의 역수
발생 빈도가 적을수록 가중치를 높게 줌. 이를 문서 빈도의 역수(Inverse Document Frequency) 라고 함
너무 자주 등장하는 은, 는 같은 것은 의미 없을 가능성이 높아짐. 그래서 IDF로 낮게 처리함
TF
용어 빈도
같은 단어가 많이 나와야 됨.
이때 freq, avgdl, k1, b, dl 이 필요함
freq: 도큐먼트 내 용어가 나온 횟수
k1, b : 알고리즘 정규화를 위한 가중치. 공통 상수
dl : 필드 길이 한 도큐먼트의 토큰 수
avgdl : 전체 도큐먼트에서 평균 필드 길이. 모든 도큐먼트 평균 토큰 수
짧은 글에서 단어가 나오면 점수가 높다
점수 계산 결과. IDF, TF, boost 변수 까지 곱하면 됨
boost는 2.2 로 엘라스틱 서치 고정값
리프 쿼리, 복합 쿼리
리프 쿼리 : 특정 필드에서 용어 찾는 쿼리(match, term, range)
복합 쿼리 : 쿼리 조합. 논리 쿼리(bool)
리프쿼리중 전문 쿼리(full text query, term level query)
전문 쿼리 : 전문 검색 쿼리. text타입 매핑
용어 수준 쿼리 keyword 타입 쿼리
필수는 아니지만 정확도를 위한 권장사항이다
전문 쿼리는 검색어도 토큰화 되어버린다. 블로그처럼 텍스트가 많은 필드에서 특정 용어 검색을 위해 사용됨
전문 쿼리 방식에는 match, match phrase query, multi-match query, query string query 등이 있다
용어 수준 쿼리는 keyword 타입이라고 가정하고 쿼리가 됨
"I Like Elastic"이라는 내용이 있다면 토큰화 되지 않고 바로 검색됨. I Like Elastic 이라는 내용이 text타입으로 매핑되어 I, Like, Elastic 으로 토큰화되어 있다면 매칭 실패됨
where과 비슷한 역할. term query, terms query, fuzzy query 가 있음.
match query. 전문 쿼리 특정 용어나, 용어들을 검색할 때 사용
_source 파라미터 : 이 부분만 보여줘라 라는 select 느낌하고 비슷함
이때 or 연산임
단어 하나만을 찾는 것이 아니라, 구를 찾는 경우
match phrase 쿼리
용어가 모두 포함, 순서도 맞아야 하고, 다른 단어가 있으면 안됨.
많은 리소스가 들어가기에 막 하면 안됨
용어 쿼리
특정 타입으로 검색을 원한다면 term:{
필드.keyword : 검색어
}
같은 느낌으로 진행해야 함
용어들 쿼리
대소문자도 신경써야 하고, 여러 용어 사용함
멀티 매치 쿼리
개별 스코어 계산 후 가장 큰 스코어로 계산해줌
이때 와일드 카드로 필드도 가능함
필드에 ^2 같은 것을 붙히면, 가중치도 설정 가능함
범위 쿼리 : 날자, 숫자, ip는 범위 쿼리 가능함.
문자열, 키워드 타입에는 범위 쿼리 불가능
lte, gte 그 날 포함, 전날, 다음날
lt, gt 전날, 다음날
날짜/시간 데이터 타입
now-1M 같은게 가능함
시, 분, 초는 소문자. 나머지는 대문자
범위 데이터 타입에 일반 숫자 나오면 에러
relation 으로 추가적으로 쿼리가 가능함
relation
intersects 기본값. 쿼리 범위가 일부라도 포함하면 끝
contains : 도큐먼트 범위 데이터가 쿼리 범위값을 모두 포함해야 한다
within : 도큐먼트의 범위 데이터가 쿼리 범위 값 내에 전부 속해야 한다
논리 쿼리
복합 쿼리. 단독이 아닌, 조합 해야 한다
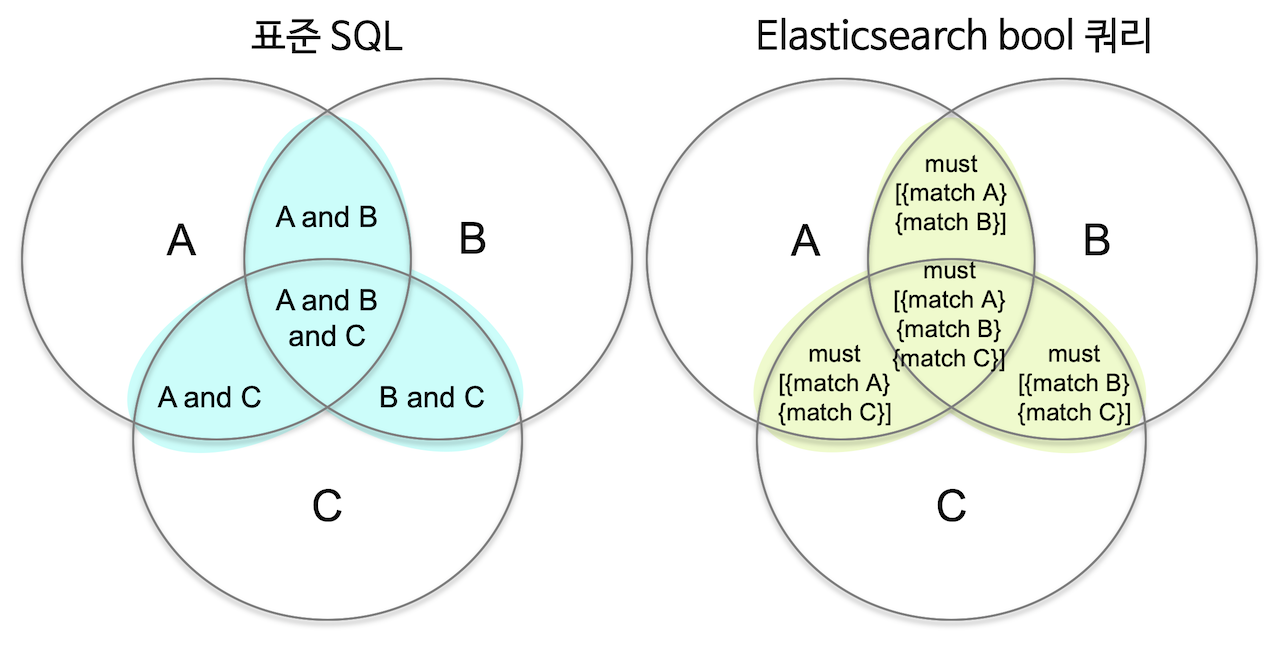
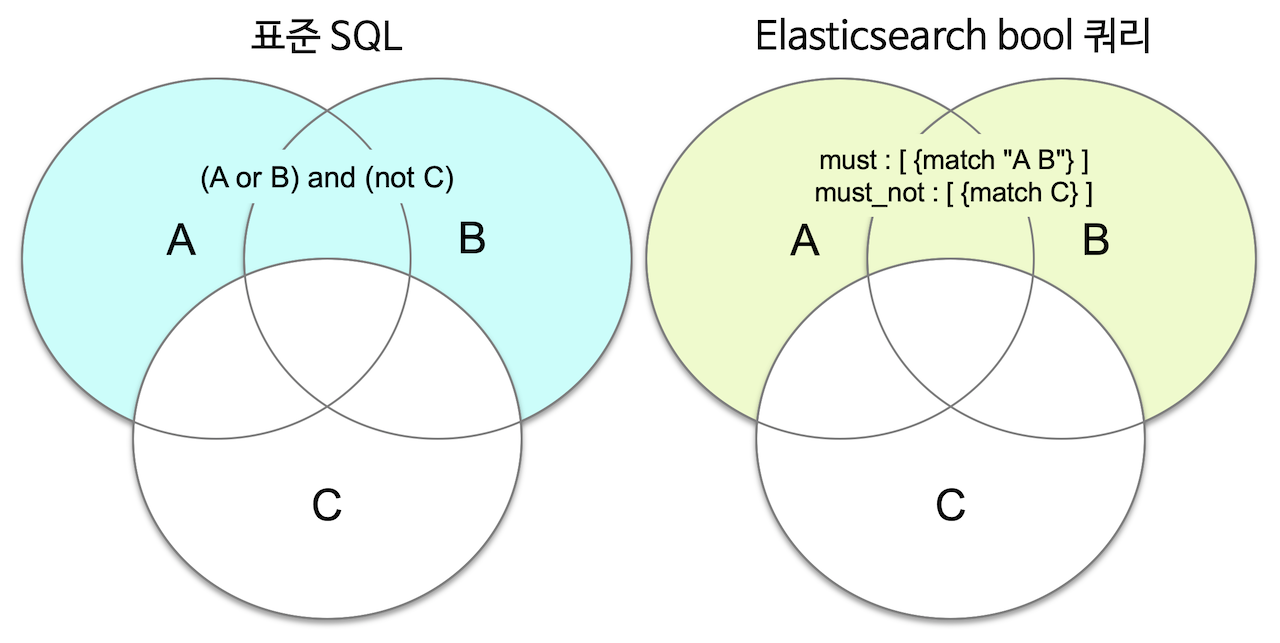
4개의 타입 지원
must, must_not, should, filter
must는 and
should 는 or
filter 는 예 아니오로 필터 컨텍스트
must_not은 거짓인 도큐먼트 and연산을 통해서 걸리는 것들 다 거름
should를 다른 타입과 같이 쓰면 검색 결과가 아닌 스코어만 영향을 줌
filter는 유사도가 없음
패턴 검색 : 와일드 카드 쿼리, 정규식 쿼리가 있음
와일드카드 쿼리 : 시작에 *나 ? 는 쓰지 말자
정규식 쿼리 : . 을 통한 하나의 문자
+로 여러 문자
agg로 집계 가능
매트릭 집계 :
1. avg, min, maax, sum, percentiles(필드 백분위값 계산), stats(min,max,avg,count를 한 번에 본다), cardinality(unique 값 수), geo-centroid(필드 위치 정보의 중심점)
size:0의 의미 집계에 사용한 도큐먼트를 결과에 포함하지 않기에 속도 증가 효과가 있음
precision_threshold : 파라미터 정확도 수치. 값이 크면 정확도가 올라가고, 리소스가 많이 소모됨.
HyperLogLog++ 알고리즘으로 중복 제거 계산을 함
지정한 리소스 이상의 메모리를 사용하지 않는 특징이 있음
기본 3000, 최대 40000
버킷 집계
통계가 아니라 그룹핑 하는 게 목적
histogram : 숫자 타입 일정 간격으로 분류
date_histogram : 날짜, 시간을 일정 날짜, 시간으로 분류
range : 숫자 타입 필드 사용자가 지정하는 범위로 분류
date_range : 날짜, 시간을 사용자가 지정하는 범위로 분류
terms : 필드에 많이 나타나는 용어값을 기준으로 분류
significant_terms : 통계적으로 유의미한 용어값을 기준으로 분류
filters : 포함시킬 문서의 조건을 직접 지정
배열을 집계할 경우 or 연산이 된다는 점이 있음
size를 통해서 버킷 수를 감출 수도 있음
size로 감춰버리는 경우에는 샤드에서도 다 감춰지기에, 취합 과정에서 결과가 달라질 수도 있다
doc_count_error_upper_bound 에 예외 범위를 표현할 수 있음
shard_size를 통해 개별 샤드당 집계 수를 낮출 수 있음
샤드 크기는 기본적으로 버킷 수 * 1.5 +10 으로 계산됨
group by와 정말 비슷하게 가능함
서브 버킷은 2뎁스 이상 가는게 안 좋다
부모 집계, 형제 집계 유형
부모 집계 : aggs:{aggs:{부모집계}}
형제 집계 : aggs:{aggs:{} 형제집계}
집계 작성 위치의 차이일 뿐
형제 집계
min_bucket
max_bucket
avg_bucket,
sum_bucket
stat_bucket
percentile_bucket
moving_avg
부모 집계
derivative: 기존 집계의 미분
cumulative_sum : 기존 집계의 누적합
로그 스태시
플러그인 기반 오픈소스 데이터 처리 파이프라인 도구
데이터 수집을 위한 새로운 어플리케이션 보다는 로그스태시 쪽이 편할 경우가 많음
보통 데이터 수집( 비츠or 각종 데이터)=> 로그스태시(데이터 가공)=>데이터 저장(엘라스틱서치)=>키바나(분석 및 시각화)
순으로 파이프라인이 됨
로그스태시는 플러그인 기반, 모든 형태 데이터 처리 가능(JSON, XML...)
자체 내장 메모리 사용하기에, 처리 속도와 안정성이 높은편
벌크 인덱싱을 수행할 뿐 아니라 파이프라인 배치 크기 조정을 통해 병목 현상 방지, 성능 최적화도 가능
안정성 : 재시도 로직이나 오류 발생 도큐먼트 보관 데드레터 큐가 있음.
로그 레벨
fatal, error, warn, info, debug, trace
입력, 필터, 출력 순으로 됨
로그 스태시는 json형태로 출력하는데, @version, 같은 @프리픽스를 통한
@필드는 로그스태시가 만든 것, 붙지 않은 필드는 직접 수집한 것
pipeline.yml같은걸로 설정 통일 과정이 중요했음
logstash-test.conf 파일에 붙혀넣어서 처리하는 것도 가능함
입력 플러그인
file : tail -f 명령처럼 파일 스트리밍
syslog : 네트워크 통해 전달되는 시스로그
kafka : 카프카 토픽에서 데이터를 읽어드린다
jdbc : jdbc 드라이버로 일정 마다 쿼리를 실행해 결과를 읽어들인다
로그스태시의 필터는 데이터를 정형화하고, 사용자가 필요한 데이터 형태로 가공하는 데 핵심적인 역할을 한다
grok : grok 패턴을 사용해 메시지를 구조화된 형태로 분석한다
dissect : 간단한 패턴을 사용해 메시지를 구조화된 형태로 분석한다. grok 에 비해 더 빠름
mutate : 필드명을 변경하거나 문자열 처리 등 일반적인 가공 함수
date : 문자열을 지정한 패턴의 날짜형으로 분석한다
input {
file {
path => "C:/logstash-7.10.1/config/filter-example.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
filter {
mutate {
split => { "message" => " " }
}
}
output {
stdout { }
}mutate 옵션
split : 구분자 기준 배열로 나눔
rename : 필드 명 변경
replace : 변경
uppercase, lowercase, join
gsup : 정규식이 일치하는 항목을 다른 문자열로 대체한다
merge : 특정 필드를 다른 필드로 포함
coerce : null 인 필드에 기본값
strip : 좌우 공백 제거
순서는 공식문서에서 확인
순서별로 다 정해져있음
