
상상해봅시다. 우리가 세 명이서 밤에 라면을 끓이려는데, 불은 하나고 냄비도 하나입니다. 동시에 끓일 수는 없고, 순서대로 조금씩 써야 합니다. 그런데 각자 라면을 끓이기까지 시간이 걸리잖아요? 이럴 때 우리는 어떤 방식으로 공평하게 시간을 나눌까요?
리눅스 커널도 비슷한 고민을 합니다. 여러 프로세스가 하나의 CPU를 '사용하고 싶다'고 외칠 때, 커널은 누구에게 얼마나 CPU를 내줄지 고민하죠. 이걸 결정하는 존재가 바로 스케줄러입니다.
🧠 "CPU는 바쁘다 바빠! – 리눅스 스케줄러의 세계로 들어가기"
1. 들어가며 – CPU는 누구 차례일까?
운영체제가 관리하는 수많은 프로세스 중 대부분은 슬립 상태입니다. 그런데 가끔씩 "나도 일할래!"라며 깨어나는 프로세스들이 있습니다. 자, 여기서 질문 하나!
동시에 여러 개의 프로세스가 실행 가능 상태라면, 누가 먼저 CPU를 사용할까요?
이 질문의 답을 정하는 존재가 바로 프로세스 스케줄러(Process Scheduler)입니다. 리눅스 커널은 이 스케줄러를 통해 "누가 CPU를 쓸 것인가"를 결정하죠. 마치 PC방 자리 배정하는 알바생처럼요.
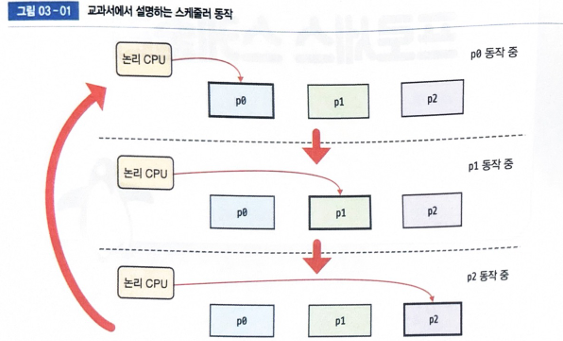
컴퓨터 관련 교과서에서는 스케줄러를 다음과 같이 설명합니다.
- 하나의 논리 CPU는 도시에 하나의 프로세스만 처리합니다.
- 실행 가능한 여러 프로세스가 타임 슬라이스 단위로 순서대로 CPU를 사용합니다.
교과서에서는 스케줄러 동작을 사진과 같이 동작한다고 합니다. 이게 실제로 리눅스에서 동작하는지 확인해봅시다!
여기서 잠깐?
논리 CPU란 무엇일까요?
우리가 흔히 말하는 CPU, 즉 중앙 처리 장치(Central Processing Unit)는 컴퓨터의 ‘두뇌’ 역할을 합니다. 그런데 요즘 컴퓨터는 "물리적으로 하나의 CPU 칩" 안에 여러 개의 ‘작업 단위’를 가지고 있어요. 이 작업 단위를 우리는 논리 CPU(Logical CPU)라고 부릅니다.
조금 쉽게 설명하자면...
"물리 CPU = 공장",
"논리 CPU = 그 안에 있는 작업 라인"
이라고 생각하면 이해하기 편해요.
💬 예를 들어 볼까요?
내 컴퓨터가 4코어 CPU를 쓰고 있고, 이 CPU가 하이퍼스레딩(Hyper-Threading) 기술을 지원한다면?
각 코어당 2개의 논리 CPU가 생깁니다.
결과적으로 시스템은 총 8개의 논리 CPU를 가진 셈이죠!
즉, 논리 CPU는 커널 입장에서 “실제로 스케줄링할 수 있는 실행 단위”입니다. 우리가 프로세스를 실행할 때 운영체제는 이 논리 CPU 중 하나에 프로세스를 배정합니다.
🙋 요약하자면?
- 물리 CPU: 실제 하드웨어 칩
- 코어(Core): 물리 CPU 안에서 실제 연산을 수행하는 부분
- 논리 CPU: OS가 인식하고, 스케줄러가 작업을 할당하는 단위
(코어 수 × 스레드 수)
리눅스에서는 lscpu, cat /proc/cpuinfo 등을 통해 논리 CPU 수를 확인할 수 있어요!
2. 먼저 알아두면 좋은 시간 개념 두 가지
프로세스를 다룰 때 자주 등장하는 시간 개념 두 가지가 있습니다.
1) 경과 시간 (Elapsed Time)
- 말 그대로 시계를 들고 있다가, 시작~종료까지 측정한 시간입니다.
real시간으로도 표시돼요. 프로세스 시작부터 종료할 때까지 경과한 시간. 초시계로 프로세스 시작부터 종료할 때까지 측정한 값에 해당합니다.
2) 사용 시간 (CPU Time)
- 프로세스가 실제로 논리 CPU를 사용한 시간입니다. 사용자 영역에서의 시간(
user)과 커널 영역의 시간(sys)을 합친 값입니다.
간단한 예로, 반복문만 실행하는 load.py 프로그램을 time 명령어로 실행해 봅시다.
time 명령어를 사용해서 프로세스를 실행하면 대상 프로세스의 시작부터 종료까지 경과 시간과 사용 시간을 알 수 있습니다

- real : 경과 시간
- user: 유저 공간에서 순수하게 코드를 실행한 시간(사용 시간)
- sys: 커널 공간에서 system call을 처리한 시간(사용 시간)
user는 프로세스가 사용자 공간에서 동작한 시간을 뜻하고, sys는 프로세스의 시스템 콜 호출 때문에 늘어난 커널이 동작한 시간을 뜻합니다.
경과 시간과 CPU 사용 시간이 거의 동일하죠? 이 말은 이 프로세스는 CPU를 100% 활용하며 동작했단 뜻입니다.
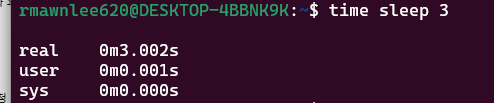
반대로, 아래 명령어는 CPU를 거의 사용하지 않습니다.
sleep은 슬립 상태로 있다가 시간만 지나면 종료되니 CPU는 거의 사용되지 않았네요.
sys가 완전히 0이 아닌 이유는, "파이썬이 시작하거나 종료할 때 살짝 커널의 도움을 받았기 때문"이라는 걸 나타냅니다.
즉, 파이썬 인터프리터가 몇 종류의 시스템 콜을 호출하기 때문입니다.
📌 비유로 설명하면?
load.py는 혼자 조용히 공부하는 학생처럼 보이지만,
수업 시작할 땐 선생님이 출석도 부르고,
끝날 땐 과제 제출하라고 알려주는 정도는 있다는 거예요.즉, 혼자 있는 것 같아도 커널(선생님)의 손길은 아주 살짝 필요합니다!
시작 후 3초를 기다렸기에 경과시간인 real은 약 3초입니다. cpu를 사용하는 일 없이 슬립 상탤 들어가서 3초 뒤에 다시 cpu를 사용하지만 곧바로 종료하므로 사용시간은 0입니다.
3) 둘을 비교하자면?
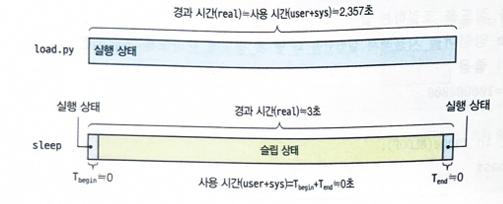
✅ time ./load.py는 CPU를 "풀로" 쓰는 프로그램
#!/usr/bin/python3
NLOOP = 100000000
for _ in range(NLOOP):
pass- 이 코드는 CPU에게 계속 일을 시킵니다.
- 아무 일도 안 하는 것 같지만,
pass를 1억 번 반복하면서 CPU는 열심히 루프를 돕니다. - 즉, 100% 사용자 공간에서 실행(user time).
- 시스템 콜은 거의 안 하기 때문에
sys time은 거의 0입니다.
출력 예시:
real 0m2.357s # 실제 걸린 시간
user 0m2.357s # 유저 공간에서 쓴 CPU 시간
sys 0m0.000s # 커널 공간 시간 거의 없음✅ time sleep 3은 CPU를 "거의 안 쓰는" 프로그램
sleep은 내부적으로nanosleep()이라는 시스템 콜을 한 번 호출하고,
그 이후에는 CPU를 반납하고 슬립 상태로 빠집니다.- 이 상태에서는 CPU는 다른 프로세스를 실행할 수 있어요.
- 3초가 지나면, 다시 깨어나서 그냥 종료함.
출력 예시:
real 0m3.009s # 실제로 3초 잠잠하게 기다림
user 0m0.000s # 유저 공간 거의 없음
sys 0m0.002s # 시스템 콜 한번 호출 정도🧠 요약: 둘의 가장 큰 차이점
| 항목 | ./load.py | sleep 3 |
|---|---|---|
| CPU 사용 | 계속 사용 (100%) | 거의 안 함 |
| user time | 크다 (≈ real) | 거의 0 |
| sys time | 거의 0 | 조금 (1~2ms 정도) |
| real time | 전체 걸린 시간 (≒ user) | sleep 시간 그대로 (3초) |
| 슬립 상태 | 없음, 계속 동작 | 있음, 대부분 슬립 |
🧩 쉽게 비유하자면?
./load.py는 3분간 계속 달리는 사람sleep 3은 3분간 자는 사람
둘 다 3분 뒤에 끝나지만, 에너지 소비(=CPU 점유도)는 완전히 다릅니다.
./load.py는 CPU 집중형 작업,
sleep 3은 대기형 작업이라고 이해하면 좋아요.
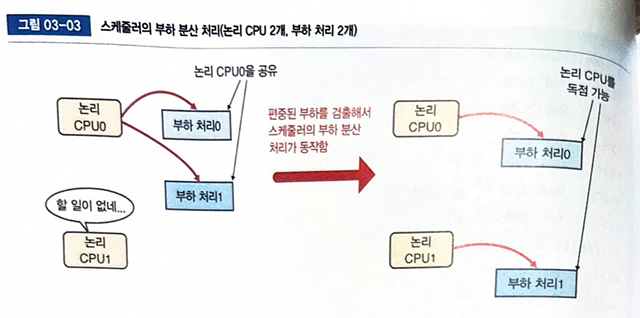
3. 논리 CPU 하나일 때 스케줄러의 동작
리눅스에서 스케줄러가 어떻게 동작하는지를 보기 위해 실험을 해봅시다. 우리가 사용할 실험 스크립트는 multiload.sh입니다. 이것은 여러 개의 load.py를 동시에 실행하고 그 실행 결과를 보여줍니다.
쉘 스크립트 분석
#!/bin/bash- Bash 셸 스크립트임을 알리는 shebang 선언입니다.
MULTICPU=0
PROGNAME=$0
SCRIPT_DIR=$(cd $(dirname $0) && pwd)MULTICPU=0: 기본값으로 하나의 논리 CPU만 사용하도록 설정합니다.PROGNAME: 실행된 스크립트 이름을 저장합니다 ($0).SCRIPT_DIR: 현재 스크립트가 위치한 디렉토리를 절대경로로 저장합니다.cd $(dirname $0): 스크립트 파일이 위치한 디렉터리로 이동.pwd: 현재 경로를 절대 경로로 출력.
usage() {
exec >&2usage함수는 잘못된 사용 시 사용자에게 도움말을 출력합니다.exec >&2는 이후echo출력이 표준 오류(stderr)로 나가도록 설정합니다.
echo "사용법: $PROGNAME [-m] <프로세스 개수>
일정 시간 동작하는 부하 처리 프로세스를 <프로세스 개수>로 지정한 만큼 동작시켜서 모두 끝날 때까지 기다립니다.
각 프로세스 실행에 걸린 시간을 출력합니다.
기본값은 모든 프로세스가 1개의 논리 CPU에서 동작합니다.
옵션 설명:
-m: 각 프로세스를 여러 CPU에서 동작시킵니다."
exit 1
}- 스크립트 사용법과 옵션 설명을 사용자에게 출력한 후 종료합니다.
while getopts "m" OPT ; do
case $OPT in
m)
MULTICPU=1
;;
\?)
usage
;;
esac
donegetopts를 사용해-m옵션을 처리합니다.-m옵션이 있으면MULTICPU=1로 설정 → 여러 논리 CPU를 사용하도록 설정- 옵션이 잘못되면
usage출력 후 종료합니다.
shift $((OPTIND - 1))getopts로 파싱한 옵션을 제거하고, 나머지 인자(즉, 프로세스 개수)를$1로 사용 가능하게 만듭니다.
if [ $# -lt 1 ] ; then
usage
fi- 프로세스 개수 인자가 없는 경우 사용법을 출력하고 종료합니다.
CONCURRENCY=$1CONCURRENCY: 동시에 실행할 부하 처리 프로세스의 개수를 저장합니다.
if [ $MULTICPU -eq 0 ] ; then
# 부하 처리를 CPU0에서만 실행시킴
taskset -p -c 0 $$ >/dev/null
fi-m옵션이 없으면 (즉,MULTICPU=0) 현재 쉘 프로세스를 논리 CPU 0에 고정합니다.taskset -p -c 0 $$: 현재 프로세스($$)를 CPU 0에서만 실행되도록 지정.- 이렇게 하면 자식 프로세스도 모두 CPU 0에서 실행됩니다.
for ((i=0;i<CONCURRENCY;i++)) do
time "${SCRIPT_DIR}/load.py" &
done- 설정된 개수만큼
load.py스크립트를 백그라운드에서 실행합니다. time명령어를 사용하여 각 실행의 경과 시간/사용 시간을 측정합니다.load.py는 단순히 반복 루프를 수행하며 CPU를 점유하는 부하 처리용 프로그램입니다.
for ((i=0;i<CONCURRENCY;i++)) do
wait
done- 백그라운드로 실행된 모든 부하 프로세스가 종료될 때까지 대기(wait)합니다.
✨ 전체 흐름 요약
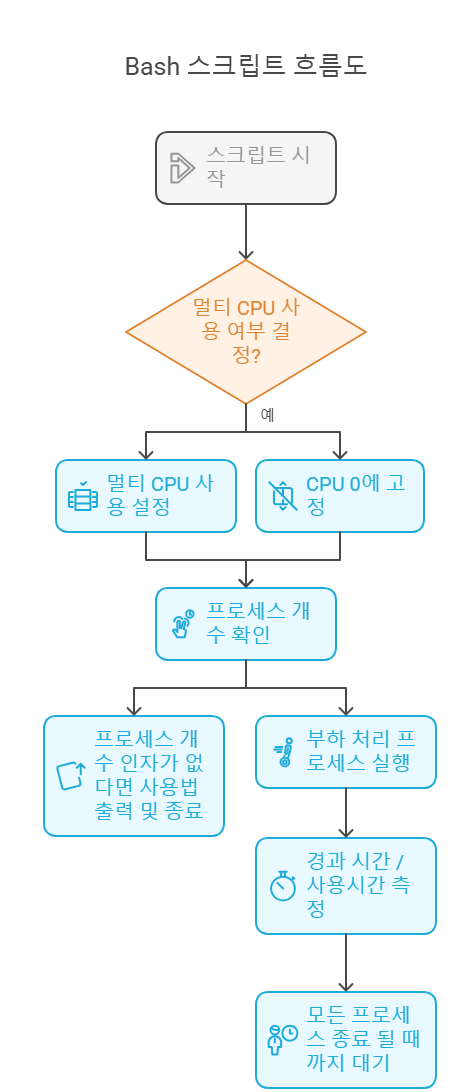
- 스크립트 실행 시
-m옵션 여부로 멀티 CPU 사용 여부 결정 load.py를 입력한 개수만큼 동시에 실행- 모든 실행이 끝날 때까지 기다림
- 각 프로세스가 얼마나 걸렸는지
time으로 측정
프로세스 지정 x

실험 1: 프로세스 하나

당연히 1개만 실행하면 CPU를 독점하니, 경과 시간과 사용 시간이 같습니다.
실험 2: 프로세스 둘
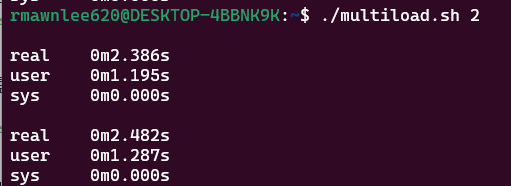
각 프로세스는 약 2.36초만 CPU를 썼지만, CPU는 하나뿐이라 순차적으로 실행되었고 전체 실행 시간은 거의 2배가 됐네요.
실험 3: 프로세스 셋
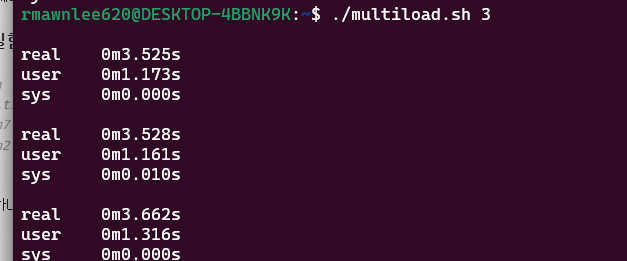
CPU가 하나니까, 세 프로세스가 줄서서 돌아가며 실행되고, 전체 시간은 약 3배로 늘어났습니다.
한 개의 논리 CPU는 한번에 프로세스 하나만 처리할 수 있으므로 스케줄러가 각 프로세스에 순서대로 CPU 자원을
할당하기 때문에 전체 실행 시간은 프로세스 개수에 비례합니다.
4. 논리 CPU 여러 개라면?
이번엔 -m 옵션을 주어 논리 CPU를 여러 개 사용해봅시다. 이 경우, 스케줄러는 부하를 각 CPU에 분산시킵니다.
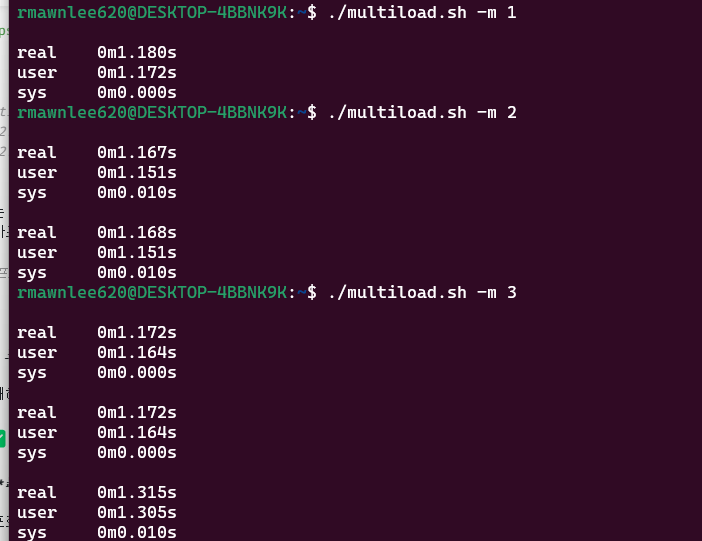
여러 CPU를 활용하면 각 프로세스가 병렬로 실행되며, 전체 실행 시간이 줄어듭니다. 스루풋(처리량)도 증가하죠.
모든 프로세스에서 real과 user+sys 값이 거의 같습니다. 이 말은 즉, 프로세스마다 각각의 논리 CPU 자원을 독점했다는 뜻입니다
참고로 “왜 프로세스 개수를 늘리면 전체 실행 시간이 늘어나는가?”는 스케줄링의 핵심을 이해하는 데 아주 중요한 포인트
이걸 이해하려면 먼저 논리 CPU가 동시에 몇 개의 프로세스를 실행할 수 있느냐를 생각해봐야 해요.
✅ 전제: 하나의 논리 CPU는 한 번에 하나의 프로세스만 실행할 수 있다
즉, 논리 CPU는 멀티태스킹처럼 보여도 실제로는 아주 빠르게 왔다 갔다 하면서 한 번에 하나씩만 처리해요.
그래서 프로세스가 1개일 땐, CPU는 그 프로세스에게 모든 시간을 줄 수 있어서 빠르게 끝나요.
하지만 프로세스가 2개가 되면?
🧠 예시로 설명해볼게요
💡 CPU가 1개고, load.py 같은 부하 처리 프로세스를 3개 실행했다고 가정해봐요.
각각의 load.py는 2.3초 정도 CPU를 100% 점유하며 실행돼요.
그럼 3개를 동시에 실행한다고 해서 모두가 2.3초만에 끝날까요?
아니에요!
CPU는 한 번에 하나만 처리할 수 있어서, 이렇게 처리하게 됩니다:
타임라인 (논리 CPU 하나)
[--- P1 ---]
[--- P2 ---]
[--- P3 ---]즉, P1이 끝나야 P2가 시작, P2가 끝나야 P3가 시작하는 식이 돼요.
그래서 전체 실행 시간은 약 2.3초 x 3 = 약 7초가 걸리는 거죠.
실제 실험에서도 프로세스 수가 늘어날수록 전체 실행 시간이 비례해서 늘어났던 걸 확인할 수 있어요!
✅ 핵심 정리
| 프로세스 개수 | 논리 CPU 수 | 동시 실행 가능? | 전체 시간 |
|---|---|---|---|
| 1 | 1 | 가능 | 약 2.3초 |
| 2 | 1 | 불가능 | 약 4.6초 |
| 3 | 1 | 불가능 | 약 6.9초 |
🤔 그럼 멀티코어면 왜 다르냐고?
만약 논리 CPU가 3개면, 3개의 프로세스를 각각 다른 CPU에 할당할 수 있으니
모두가 동시에 실행돼서 2.3초만에 끝날 수 있어요!
멀티코어 환경에서 -m 옵션을 주면 바로 그 동작을 하게 됩니다.
🎯 요약
-
논리 CPU가 1개이면 한 번에 한 프로세스만 처리 가능 → 줄 세워서 처리.
-
그래서 프로세스 수가 늘어나면 전체 실행 시간도 비례해서 늘어남.
-
반대로, 논리 CPU 수 ≥ 프로세스 수면 병렬 실행이 가능 → 실행 시간 크게 줄어듦.
-
real: 전체 경과 시간 (부하 2개가 끝날 때까지 기다리는 시간) -
user:multiload.sh자신 + 자식 프로세스의 CPU 사용 시간 합계 -
sys: system call 처리 시간 (자식 포함)
ime ./multiload.sh -m 2는 multiload.sh스크립트를 1번 실행하고, 그 스크립트 안에서load.py` 자식 프로세스를 2개 동시에 실행시키는 구조입니다!
5. real보다 user+sys가 커지는 경우
🤔 왜 user + sys > real 인 경우가 있을까?
1. 직감과는 다른 결과
우리는 보통 이렇게 생각하죠:
“실행에 걸린 전체 시간(real)이 제일 크고, 그 안에 CPU 사용 시간(user + sys)이 포함되겠지?”
그래서 대부분은
real ≥ user + sys
이렇게 될 것 같단 말이죠.
그런데!
real 0m2.728s
user 0m5.222s
sys 0m0.016s와 같이 user + sys > real인 결과가 나오는 경우도 있다는 거예요.
🧠 그 이유는?
1) user와 sys는 "누적된 CPU 사용 시간"
user는 유저 공간에서 실행된 CPU 시간sys는 커널 영역에서 시스템 콜 등으로 사용된 시간
→ 이 값들은 자식 프로세스까지 포함된 총합이에요!
즉, time 명령어로 어떤 스크립트를 실행했을 때
그 스크립트가 자식 프로세스를 만들었다면?
자식 프로세스의 CPU 사용 시간도
user와sys에 모두 더해집니다.
2) real은 "벽시계 시간"
- 스크립트가 시작해서 끝나기까지의 경과 시간
- 진짜로 흘러간 시간만 측정합니다.
- 병렬로 실행되더라도, 한 번만 카운트해요.
📌 실험 예제로 이해해봐요
./multiload.sh -m 2 명령어를 실행하면?
- 이 쉘 스크립트는
load.py를 2개 동시에 실행합니다. - 즉, 자식 프로세스가 2개 생성되어 동시에 CPU를 사용합니다.
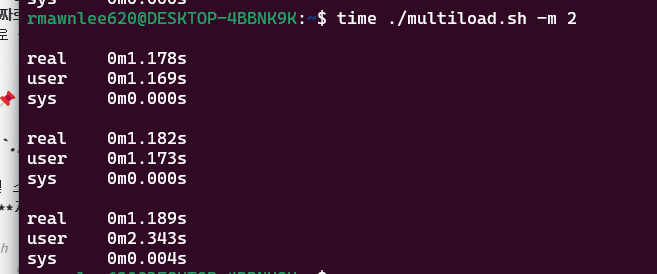
real: 총 경과 시간 → 약 1.18초user: 자식 2명이 각각 약 1.16초 동안 CPU를 썼다 → 합치면 2.34초sys: 약간의 시스템 콜
→ 총 CPU 사용 시간은 2.34 + 0.004 = 2.344초로 real보다 큽니다.
🧩 쉽게 비유해볼게요!
엄마(스크립트)가 애 둘(load.py 2개)에게 동시에 “청소해!”라고 시킵니다.
애 둘이 동시에 각자 방을 청소하는데, 각자 30분씩 일했어요.
엄마는 벽시계로 보니까, 청소 시작~끝까지는 30분 걸렸다고 느끼죠. (real)
하지만 애들이 각각 30분씩 일한 거니까,
청소에 쓰인 총 노동시간은 60분인 거예요! (user+sys)
✅ 정리하면
| 시간 종류 | 의미 | 특징 |
|---|---|---|
real | 실제로 걸린 시간 (벽시계 시간) | 병렬이어도 1회 측정 |
user | 유저 공간에서 쓴 CPU 시간 | 자식 프로세스 합산 포함 |
sys | 커널 영역에서 쓴 CPU 시간 | 자식 포함, 시스템 콜 영향 |
그래서 자식이 여러 명이고 병렬로 동시에 실행되면
user + sys가real보다 더 커질 수 있어요!
6. 타임 슬라이스: CPU는 조각조각 나눠 쓴다
논리 CPU가 하나인데, 동시에 3개의 프로세스를 실행하면?
CPU는 마치 피자를 나눠 먹듯 각 프로세스에게 짧은 시간씩 번갈아 CPU를 줍니다. 이것을 타임 슬라이스(Time Slice)라고 해요.
이를 실험으로 보여주는 게 sched.py입니다. 이 스크립트는 각 프로세스가 어떤 시간에 얼마나 CPU를 사용했는지를 시각화합니다.
✅ 목적
- sched.py는 CPU 시간을 사용하는 부하 처리용 프로세스들을 동시에 실행하면서 다음과 같은 정보를 수집합니다.
- 어떤 시점에 어떤 논리 CPU에서 어떤 프로세스가 동작 중인지
- 각 프로세스가 어느 정도 진척되었는지 이걸 통해 리눅스 스케줄러가 CPU를 어떻게 나눠쓰게 하는지 실제 실험을 통해 시각적으로 확인할 수 있어요.
✅ 동작 방식
- 입력된 <프로세스 개수>만큼의 부하 처리 프로세스들을 동시에 실행
- 이 부하 프로세스들은 100밀리초 동안 CPU 자원을 소비함
- 종료될 때까지 기다리고, 각 프로세스가 얼마나 CPU를 사용했는지 시간 기반으로 기록함
- 기록된 데이터를 기반으로 .jpg 그래프를 생성
✅ 같이 써야 하는 파일
- plot_sched.py (코드 03-04)는 그래프를 그리는 데 사용됨 → sched.py 실행 디렉토리에 함께 있어야 함
✅ 출력 결과
-
sched-<프로세스 개수>.jpg 형식의 이미지 파일이 생성됨
-
예: sched-2.jpg, sched-3.jpg
-
그래프 축 정보:
x축: 부하 처리 프로세스의 경과 시간 (밀리초)
y축: 해당 시간 동안의 진척도 (%)
(즉, "이 시점까지 프로세스가 얼마나 CPU를 사용했는지"를 백분율로 보여줌)
📌 전체 개요
- 목적:
nice값이 서로 다른 2개의 프로세스를 동시에 실행하여 CPU 자원을 어떻게 분배받는지 측정하고 그래프로 저장. - 결과물:
sched-2.jpg라는 그래프 이미지 (x축: 시간, y축: 진행도%) - 사용법:
./sched-nice.py <nice값>→ nice값은 0보다 큰 정수 (기본값보다 우선순위가 낮음)
🧠 코드 구조 & 주요 동작 설명
1) usage() 함수
- 잘못된 인자 입력 시 사용법 출력 후 종료
def usage():
...
sys.exit(1)2) 루프 횟수 측정 함수 estimate_loops_per_msec()
def estimate_loops_per_msec():
before = time.perf_counter()
for _ in range(NLOOP_FOR_ESTIMATION):
pass
after = time.perf_counter()
return int(NLOOP_FOR_ESTIMATION/(after-before)/1000)- 1밀리초에 대략 몇 번의 루프를 돌 수 있는지를 계산해서, 이후 부하 측정에 사용함.
- 이렇게 측정한
nloop_per_msec는 CPU 부하를 적절히 만들기 위한 기준.
3) child_fn(n) 함수 – 각 부하 처리 프로세스의 동작
def child_fn(n):
progress = 100*[None]
for i in range(100):
for _ in range(nloop_per_msec):
pass
progress[i] = time.perf_counter()
...100ms동안 루프를 계속 돌며 진척도를 측정- 진행 상황을 밀리초 단위로 저장 (
i가 0~99 → 100ms 기준) - 이후
"n.data"라는 이름으로 결과 파일로 저장됨
4) main 로직
if len(sys.argv) < 2:
usage()- 명령줄 인자로
nice값을 받지 않으면 사용법 출력
nice = int(sys.argv[1])
concurrency = 2- 두 개의 프로세스를 동시에 실행
- 이 중 하나만
nice값을 조정해서 우선순위를 낮춤
os.sched_setaffinity(0, {0})- 모든 부하 처리 프로세스를 논리 CPU 0번에 고정시킴
(다른 CPU에 분산되지 않도록 실험 통제)
nloop_per_msec = estimate_loops_per_msec()- CPU의 속도를 기반으로 적절한 루프량을 동적으로 결정
5) fork()를 통한 프로세스 생성
for i in range(concurrency):
pid = os.fork()
...- 2개의 자식 프로세스를 생성
if i == concurrency - 1:
os.nice(nice)- 두 번째 프로세스에만
nice값을 설정하여 우선순위 낮춤 - 즉, 프로세스 0은 기본 우선순위 (nice = 0)
프로세스 1은 낮은 우선순위 (예: nice = 5)
6) 결과 기다리고 그래프 출력
for i in range(concurrency):
os.wait()
plot_sched.plot_sched(concurrency)- 모든 자식 프로세스가 종료될 때까지 기다린 후,
- 수집된
n.data파일을 바탕으로sched-2.jpg그래프 생성
🧪 타임 슬라이스 실험 비교표
| 항목 | 동시 실행 = 1 | 동시 실행 = 2 | 동시 실행 = 3 |
|---|---|---|---|
| 그래프 이미지 | 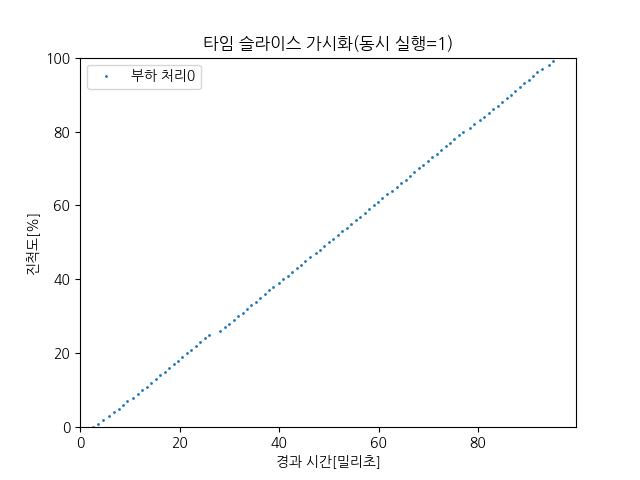 | 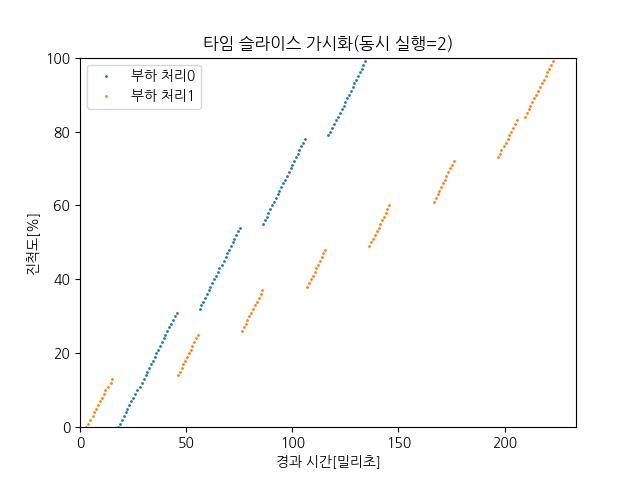 | 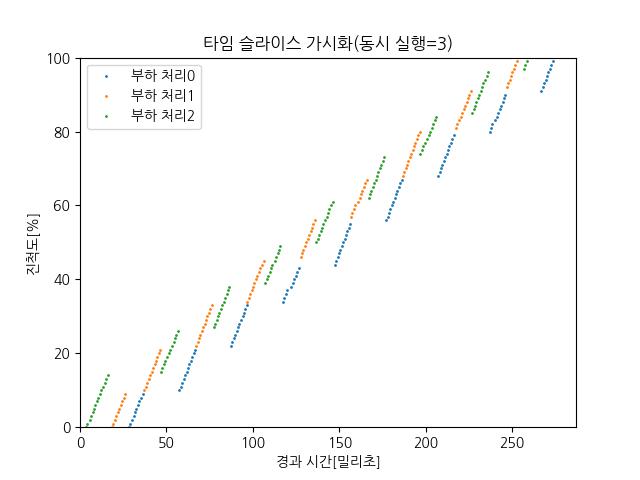 |
| 부하 처리 프로세스 수 | 1개 (0번) | 2개 (0번, 1번) | 3개 (0번, 1번, 2번) |
| 그래프 특징 | 직선 형태로 계속 진행됨 | 번갈아 가며 일정한 간격으로 점프 | 더 짧은 주기로 세 개가 번갈아 사용 |
| CPU 사용 방식 | 독점 사용 | 두 프로세스가 교대로 CPU 점유 | 세 프로세스가 짧은 타임슬라이스 단위로 교대로 점유 |
| 각 프로세스 진척도 변화 | 일정하게 꾸준히 증가 | 계단식 패턴 (한 쪽씩 번갈아 증가) | 세 줄이 번갈아 올라감 (계단 패턴 더 촘촘) |
| 의미 | 타임슬라이스가 필요 없음 (혼자 사용) | 타임슬라이스 작동 확인 가능 | 타임슬라이스 더 작아짐 (많이 나눠 가짐) |
| 레이턴시 영향 | 없음 | 약간 늘어남 | 더 길어짐 (대기시간 증가) |
🧠 요약 정리
| 동시 실행 수 | 설명 |
|---|---|
| 1개 | CPU를 혼자 독점해서, 중간에 끊기지 않고 계속 실행함 (그래프는 직선) |
| 2개 | CPU를 반반씩 나눠가짐 → 번갈아 가며 실행 (그래프는 계단식) |
| 3개 | CPU를 3분할 → 더 자주 번갈아가며 짧게 실행 (그래프는 더 촘촘한 계단식) |
- 동시 실행 1개 → CPU를 혼자 독점하므로 가장 이상적인 성능 (진행률이 직선).
- 동시 실행 2개 → 두 프로세스가 교대로 CPU를 사용. 타임 슬라이스 동작 확인 가능.
- 동시 실행 3개 → 세 프로세스가 나눠 쓰며 타임 슬라이스가 더 짧아짐, 문맥 전환 더 잦아짐.
💡 즉, 논리 CPU 1개에서 실행 가능한 프로세스가 늘어날수록, 진척도는 나눠지고, 응답 시간은 늦어질 수 있다는 걸 보여주는 실험이에요!
🎯 요점 정리
논리 CPU 하나를 여러 프로세스가 나눠 쓰는 구조에서는 한 프로세스가 독점할 수 없고, 조금씩 번갈아 사용하는 구조로 돌아갑니다.
이걸 타임 슬라이스 기반 스케줄링이라고 해요!
→ 부하 처리 1은 간헐적으로만 실행되며, 훨씬 적은 CPU 자원을 받음
결과 그래프를 보면 1개의 논리 cpu에서 여러 처리를 동시에 실행하는 경우, 각각의 처리는 수밀리초 단위의 타임 슬라이스로 쪼개서 cpu를 교대로 사용합니다.
7. nice 값의 영향 – 프로세스도 줄을 서요[리눅스 스케줄러의 타임 슬라이스 구조 정리]
리눅스에서 프로세스 우선도는 nice 값으로 조정할 수 있습니다. 낮을수록 우선도가 높고, 높은 값은 “나는 나중에 실행돼도 돼요”라는 뜻입니다.
nice 값을 5로 설정하면 해당 프로세스는 타임 슬라이스를 더 적게 받게 되죠. sched-nice.py를 이용해 시각화한 결과를 보면, 우선도 높은 프로세스가 더 많은 시간을 가져가는 걸 확인할 수 있어요.
1) 타임 슬라이스란?
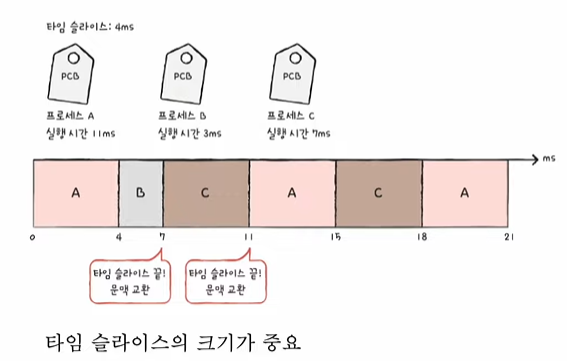
- CPU는 동시에 여러 프로세스를 실행할 수 없기 때문에, 짧은 시간 단위로 CPU를 나눠서 각 프로세스에게 할당합니다.
- 이 "짧은 시간 단위"를 타임 슬라이스(time slice)라고 해요.
2) 목표 레이턴시와 타임 슬라이스 관계
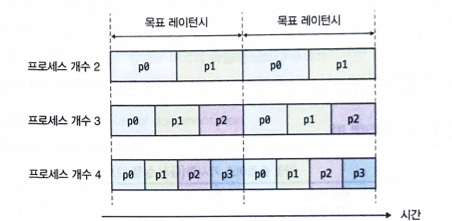
- 리눅스는 일정 간격마다 각 프로세스에 한 번씩 CPU를 할당하려고 해요.
- 이 간격을 목표 레이턴시(targeted latency)라고 부릅니다.
- 예를 들어,
kernel.sched_latency_ns = 24000000이면, 24ms마다 한 번씩 돌아가게 하겠다는 뜻이에요.
타임 슬라이스 계산 공식:
타임 슬라이스 = 목표 레이턴시 / 실행 가능한 프로세스 수예시:
| 실행 가능한 프로세스 수 | 목표 레이턴시 | 각 프로세스 타임 슬라이스 |
|---|---|---|
| 2개 | 24ms | 12ms |
| 3개 | 24ms | 8ms |
| 4개 | 24ms | 6ms |
3) 정적 타임 슬라이스 vs 동적 타임 슬라이스
| 과거 (커널 2.6.23 이전) | 현재 |
|---|---|
| 타임 슬라이스가 고정 (ex. 100ms) | 동적으로 조절됨 |
| 프로세스가 많으면, 기다리는 시간이 너무 길어짐 | 프로세스 수에 따라 슬라이스도 나눠짐 |
4) nice값이란?
- 프로세스의 실행 우선도(priority)를 조절하는 값입니다.
- 범위: -20 (가장 높은 우선도) ~ +19 (가장 낮은 우선도)
| nice값 | 의미 |
|---|---|
| -20 | 매우 빠르게 실행됨 (루트만 가능) |
| 0 | 기본값 |
| 19 | 느리게 실행됨 (CPU 적게 차지함) |
5) 스케줄러는 어떻게 동작하나?
- nice값이 낮은 프로세스에 더 많은 타임 슬라이스를 할당합니다.
- 결과적으로, 우선도가 높은 프로세스는 CPU를 더 자주, 더 오래 사용합니다.
🔬 실험 결과 분석
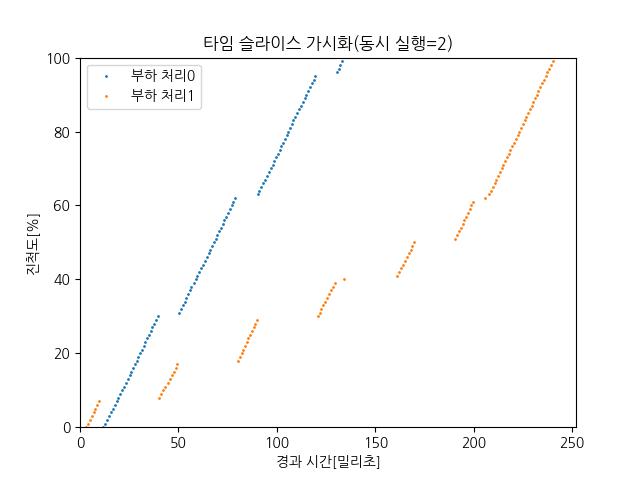
- 부하 처리0 (nice=0) → 더 자주 실행되며 직선처럼 빨리 올라감
- 부하 처리1 (nice=5) → 우선도가 낮아 CPU를 덜 배정받음, 진척도가 느림
📊 요약: nice값 차이에 따라 CPU 점유율이 확실히 달라지는 걸 시각적으로 보여줌
8. 컨텍스트 스위치: 교대 근무의 시작과 끝
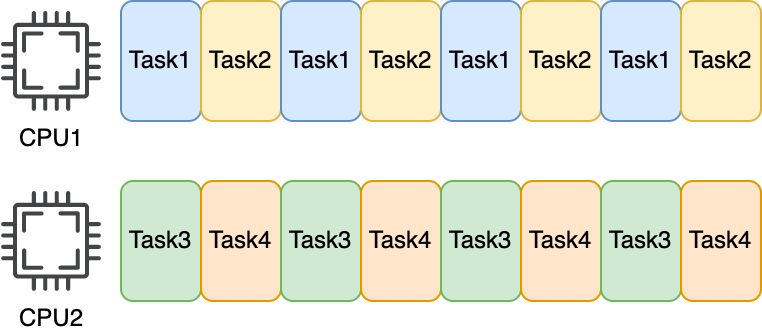
CPU가 한 프로세스를 중단하고 다른 프로세스를 실행할 때, 그 상태를 저장하고 복원하는 것을 컨텍스트 스위치(context switch)라고 합니다.
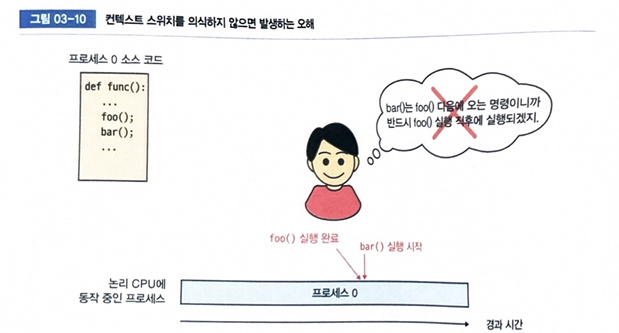
타임 슬라이스가 끝나면 무조건 스위치가 일어나기 때문에, 코드 흐름 상으로는
foo(); bar();처럼 연속되는 함수 호출이라도 실제 실행 시간은 뚝뚝 끊겨서 뒤늦게 실행될 수 있어요.
이런 상황을 이해하면 어떤 처리에 생각보다 많은 시간이 걸릴 때, '처리 자체에 무슨 문제가 있는 게 분명하다'고 이렇게 단순히 결론 내리기보다는 '처리를 하다가 컨텍스트 스위치가 발생해서 다른 프로세스가 동작했을 가능성이 있을지도 모른다'라는 관점으로 볼 수 있습니다.
9. 처리 성능 측정 – 평균 시간과 스루풋
📊 리눅스 스케줄러에서의 성능 측정 및 실험 정리 (확장판)
리눅스 시스템에서 다양한 프로세스를 효과적으로 스케줄링하고 실행하는 것은 시스템의 성능을 좌우하는 핵심 요소입니다.
특히 실험을 통해 얻은 데이터를 시각화하여 실질적인 이해를 도우며, 프로세스 개수와 CPU 수에 따른 성능 변화를 직접적으로 확인할 수 있도록 구성했습니다.
✅ 1. 성능 측정에서 주로 사용하는 핵심 지표
리눅스에서 스케줄링 성능을 측정할 때, 아래 두 가지 지표가 매우 중요합니다:
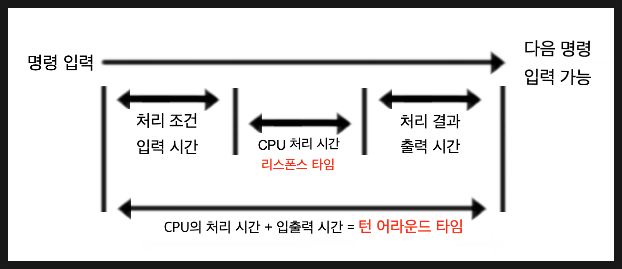
1) 턴어라운드 타임 (Turnaround Time)
- 프로세스가 시작 요청을 받고 종료될 때까지 걸리는 총 시간입니다.
- 실제 사용자의 체감 응답성과 밀접한 관련이 있으며,
real time을 기반으로 계산됩니다.
턴어라운드 타임(Turnaround Time)은 항공기가 도착한 후 다음 비행을 위해 지상에서 체류하는 시간을 뜻하기도 합니다. 턴오버 타임, 그라운드 타임이라고도 불립니다
2) 스루풋 (Throughput)
- 단위 시간 동안 완료된 작업(프로세스) 수를 의미합니다.
- 공식:
스루풋 = 총 프로세스 수 / real time - 시스템의 처리 능력을 가늠하는 핵심 척도입니다.
이러한 지표를 측정함으로써 리눅스 시스템이 얼마나 효율적으로 프로세스를 실행하고 처리하는지 정량적으로 평가할 수 있습니다.
✅ 2. 실험을 위한 도구 및 스크립트 설명
실험은 다음 세 가지 프로그램으로 구성되어 있으며, 각각의 역할은 다음과 같습니다:
- multiload.sh: 지정된 개수만큼 부하 처리 프로세스를 실행하여 CPU를 일정 시간 동안 점유하게 합니다.
- cpuperf.sh: multiload.sh를 기반으로 프로세스를 반복 실행하고 평균 턴어라운드 타임과 스루풋을 계산합니다.
- plot-perf.py: 성능 측정 데이터를 바탕으로 시각화된 그래프를 생성하여 분석에 활용합니다.
이러한 도구를 통해 프로세스 개수와 CPU 사용량의 관계를 실험적으로 분석할 수 있습니다.
✅ 3. cpuperf.sh 상세 설명 및 주석 (코드 03-06)
#!/bin/bash
# 사용법 안내 함수
tion usage() {
exec >&2
echo "사용법: $0 [-m] <최대 프로세스 개수>"
echo " 1. 'cpuperf.data' 파일에 성능 정보를 저장합니다."
echo " 2. 평균 턴어라운드 타임 그래프: 'avg-tat.jpg' 저장"
echo " 3. 스루풋 그래프: 'throughput.jpg' 저장"
echo " -m 옵션은 multiload.sh에 그대로 전달합니다."
exit 1
}
# 측정 함수: multiload.sh를 통해 성능 측정
measure() {
local nproc=$1 # 프로세스 수
local opt=$2 # 옵션 (-m 여부)
bash -c "time ./multiload.sh $opt $nproc" 2>&1 \
| grep real \
| sed -n -e 's/^.*0m\([0-9.]*\)s$/\1/p' \
| awk -v nproc=$nproc '
BEGIN { sum_tat=0; }
(NR <= nproc) { sum_tat += $1; }
(NR == nproc + 1) { total_real = $1; }
END {
printf("%d\t%.3f\t%.3f\n", nproc, sum_tat/nproc, nproc/total_real);
}'
}
# 옵션 처리
declare MEASURE_OPT=""
while getopts "m" OPT; do
case $OPT in
m) MEASURE_OPT="-m";;
?) usage;;
esac
done
shift $((OPTIND - 1))
# 인자 검증
if [ $# -lt 1 ]; then
usage
fi
rm -f cpuperf.data
MAX_NPROC=$1
# 측정 반복 실행
for ((i = 1; i <= MAX_NPROC; i++)); do
measure $i $MEASURE_OPT >> cpuperf.data
done
# 그래프 생성 호출
./plot-perf.py $MAX_NPROC✅ 4. plot-perf.py 설명 및 기능 정리 (코드 03-07)
#!/usr/bin/python3
import sys
import plot_sched
progname = sys.argv[0]
def usage():
print("""사용법: {} <최대 프로세스 개수>
- 'cpuperf.data' 파일 기반 성능 그래프 생성
- 'avg-tat.jpg': 평균 턴어라운드 타임 그래프
- 'throughput.jpg': 스루풋 그래프
""".format(progname), file=sys.stderr)
sys.exit(1)
if len(sys.argv) < 2:
usage()
max_nproc = int(sys.argv[1])
plot_sched.plot_avg_tat(max_nproc)
plot_sched.plot_throughput(max_nproc)이 프로그램은 cpuperf.data 파일을 바탕으로 성능 정보를 시각화하여 실험 결과를 보다 명확히 파악할 수 있도록 돕습니다.
🔍 실험 결과 분석: 논리 CPU 수에 따른 차이
1) 논리 CPU 1개일 때의 성능 변화
- 프로세스 수가 늘어날수록 처리 시간은 선형적으로 증가합니다.
- 하지만 CPU가 하나이기 때문에 컨텍스트 스위치가 빈번하게 발생해 평균 처리 시간의 증가 속도도 함께 커집니다.
- 스루풋은 초기에는 약간 상승하다가 일정 수준 이후에는 정체됩니다.
2) 모든 논리 CPU 사용 (예: 4코어 8스레드)
- 프로세스 수가 CPU 수와 같아질 때까지 스루풋은 선형적으로 증가합니다.
- 그 이후 프로세스를 더 늘리면 컨텍스트 스위치 오버헤드로 인해 평균 처리 시간은 급증하고, 스루풋은 오히려 하락합니다.
이 실험을 통해 CPU 자원 활용의 한계를 명확히 파악할 수 있으며, 실제 시스템 설계에서 적절한 프로세스 수 조정이 얼마나 중요한지를 알 수 있습니다.
✅ 종합 결론 요약 테이블
| 조건 | 평균 턴어라운드 타임 | 스루풋 |
|---|---|---|
| 논리 CPU < 프로세스 수 | 증가 | 일정하거나 감소 |
| 논리 CPU = 프로세스 수 | 최소화 | 최대치 도달 |
| 논리 CPU > 프로세스 수 | 안정적 | 여유 있지만 자원 낭비 우려 |
💡 실험 환경 설정 팁: SMT (Simultaneous Multi Threading)
SMT는 CPU 코어 하나당 두 개 이상의 스레드를 동시 실행하는 기술입니다. 실험에서는 SMT가 성능 측정 결과에 영향을 줄 수 있으므로, 다음과 같이 설정하는 것이 좋습니다.
- SMT 비활성화 (정확한 측정을 위해):
$ sudo echo off > /sys/devices/system/cpu/smt/control- 실험 후 SMT 다시 활성화:
$ sudo echo on > /sys/devices/system/cpu/smt/control- 논리 CPU 개수 확인 명령어:
$ grep -c processor /proc/cpuinfo참고 : Throughput (쓰루풋) 오해와 진실
많은 사람들이 시스템이나 스토리지의 성능을 비교할 때, MB/s 수치만을 보고 우위를 판단하는 경우가 많습니다. 심지어 IOPS는 Throughput이 아니다라고 생각하는 오해도 흔히 볼 수 있는데요, 이는 아마도 MB/s가 단위 자체가 직관적이고, 눈에 보이는 수치로 이해하기 쉬운 지표이기 때문일 겁니다.
하지만 사실, IOPS도 Throughput의 일종입니다.
Throughput은 말 그대로 "처리량"이며, 단위 시간 동안 처리한 요청의 개수 또는 데이터의 양을 말하죠. 그러므로 MB/s도 Throughput이고, IO/s(=IOPS)도 Throughput입니다. 단지 무엇을 처리했느냐, 어떤 단위를 기준으로 삼느냐의 차이일 뿐입니다.
예를 들어:
- Throughput (MB/s) 는 초당 데이터 전송량을 의미하며, 주로 파일 복사, 백업, 스트리밍 등에서 중요합니다.
- Throughput (IO/s) 또는 IOPS 는 초당 I/O 요청 횟수를 나타내며, 데이터베이스, 트랜잭션, 웹 요청과 같은 작업에서 핵심 지표로 쓰입니다.
이처럼 IOPS도 Throughput이며, 오히려 많은 소규모 요청이 빈번하게 발생하는 시스템에서는 MB/s보다 IOPS가 훨씬 중요한 지표가 됩니다.
문제는 제조사나 벤치마크 도구들이 이 용어들을 혼용하거나 부정확하게 표현하는 경우가 많다는 점입니다. 예컨대, MB/s를 Throughput이라고 표시해놓고 IOPS는 별도로 분리해서 보여주는 대시보드를 보면, 마치 두 지표가 서로 다른 범주인 것처럼 보이기도 하죠.
이런 혼선을 줄이기 위해서는 단위를 명확히 표기하는 습관이 중요합니다.
- "Throughput (MB/s)"
- "Throughput (IO/s)"
이처럼 단위를 붙여서 쓰면 의미를 오해할 일이 거의 없습니다.
또한, 정밀하게 이야기하자면 MB/s는 시스템의 처리량이 아니라 대역폭(Bandwidth) 개념에 더 가깝습니다.
예를 들어, 데이터를 얼마나 빨리 옮길 수 있는지를 나타내는 지표이고, 처리할 수 있는 요청 수(IOPS)와는 본질적으로 다릅니다.
1) 리눅스에서도 IOPS와 Throughput은 별개의 개념
iostat,fio,perf,blktrace등 리눅스에서 많이 쓰는 도구들도 IOPS와 MB/s를 별도로 보여줍니다.- 이유는 간단합니다:
IOPS = 초당 입출력 횟수,
MB/s = 초당 전송한 바이트 양
➤ 이 둘은 직접적 관계는 있지만, 완전히 다른 성격의 지표예요.
2) MB/s는 Throughput이지만, 모든 Throughput은 MB/s가 아니다
- 리눅스에서
dd명령어처럼 큰 파일을 연속해서 읽고 쓰는 경우 MB/s가 중요한 지표입니다. (ex. 백업, 로그 저장) - 하지만
DB 서버나웹 서버처럼 작고 빠른 요청을 많이 처리하는 환경이라면 IOPS가 훨씬 중요한 지표예요.
예: 리눅스에서 MySQL 돌리는 시스템이 있다고 해볼게요.
- 이 시스템은 수천 개의 작은 쿼리를 동시에 처리하느라 수많은 작은 블록을 읽고 쓰죠.
- 이런 경우 MB/s는 낮아도, IOPS는 매우 높습니다.
→ 이 시스템의 성능을 MB/s만으로 판단하면, 잘못된 결론을 내릴 수 있습니다!
3) 리눅스에서도 Throughput은 다양한 단위를 가짐
- 네트워크 측에서는 Throughput = MB/s 또는 Mb/s (bandwidth)
- 디스크 I/O에서는 Throughput = IOPS 또는 MB/s
- 시스템 전반에서는 TPS (Transaction Per Second)도 Throughput으로 봅니다
→ 리눅스는 용도에 따라 다양한 단위를 가진 Throughput을 구분해서 사용해야 합니다.
4) 실제로 IOPS와 MB/s는 이렇게 계산돼요
MB/s = IOPS × Block Size (KB) / 1024
IOPS = (MB/s × 1024) / Block Size (KB)- 리눅스에서
fio나iostat로 실험해보면 이 공식이 그대로 적용됩니다. - Block Size가 커지면 MB/s는 올라가고 IOPS는 줄어드는 구조.
5) 우체부에 비유한다면 , IOPS는 배달 횟수고 MB/s는 전체 무게다.
🎯 개념 정리
| 용어 | 의미 | 비유 |
|------|------|------|
| IOPS (IO/s) | 초당 입출력 요청 수 | 우체부가 하루에 몇 번 배달을 했는가 |
| MB/s | 초당 전송한 데이터 양 | 우체부가 하루에 총 몇 kg의 택배를 옮겼는가 |
| Throughput | 처리량(위 둘 다 포함) | 배달의 빈도 + 총 양을 모두 포함한 개념 |
| Bandwidth | 최대 전송 가능 용량 | 우체부의 가방 크기, 트럭 용량 |
🚚 예시: 택배 회사에 비유하기
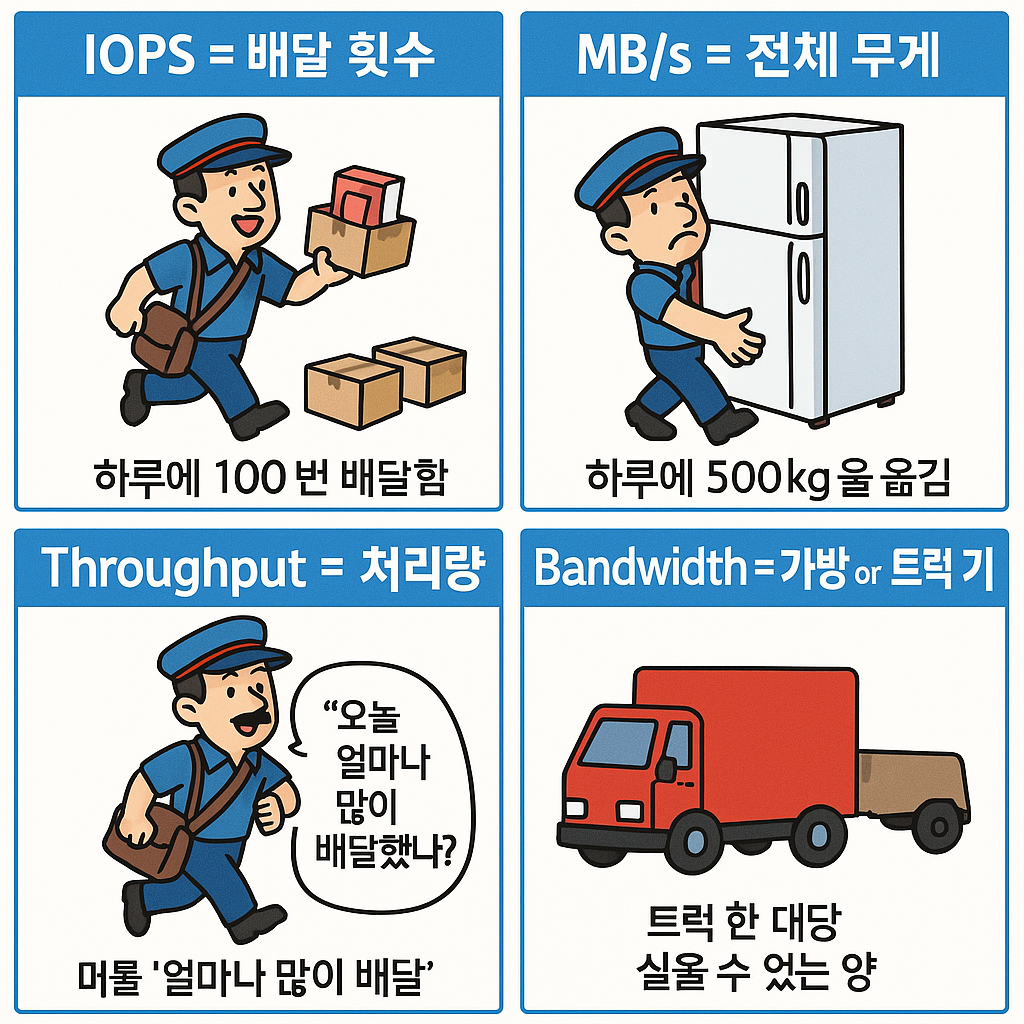
-
IOPS = 배달 횟수
- 한 건당 소형 택배(책 한 권)를 배달한다고 했을 때, 하루에 100번 배달하면 IOPS가 100입니다.
- 즉, 얼마나 자주 작고 빠르게 일하느냐를 나타냅니다.
-
MB/s = 전체 무게
- 우체부가 하루 동안 500kg을 옮겼다면 MB/s는 높습니다.
- 한 번에 냉장고처럼 큰 물건을 실어 나르면 요청은 적지만 무게는 크기 때문에 MB/s가 높게 나옵니다.
-
Throughput = 처리량
- 위의 배달 횟수(IOPS)와 무게(MB/s)는 모두 처리량(Throughput)입니다.
- 택배 회사 입장에서 "오늘 얼마나 많은 배달을 했냐?" 는 두 가지 모두 중요하죠.
-
Bandwidth = 가방 or 트럭 크기
- 트럭 한 대당 실을 수 있는 양 = Bandwidth
- 아무리 트럭이 커도, 배달을 하루에 두 번밖에 안 하면 실제 처리량은 낮습니다.
🧩 요약 정리
| 상황 | IOPS | MB/s | 해석 |
|---|---|---|---|
| 책 한 권씩 1000번 배달 | 높음 | 낮음 | 요청은 많지만, 데이터량은 작음 |
| 냉장고 3개 한 번씩 배달 | 낮음 | 높음 | 요청은 적지만, 데이터량은 큼 |
| 책 1000권 한 번에 배달 | 낮음 | 높음 | 큰 요청이지만, 빈도는 낮음 |
| 책 1000권 1000번에 나눠 배달 | 높음 | 같음 or 더 낮음 | 많은 요청, CPU 부하↑, IOPS 중요 |
🎬 현실 예시
- 데이터베이스: 수많은 작은 쿼리 → IOPS 중요!
- 동영상 스트리밍: 큰 파일을 쭉쭉 읽어야 함 → MB/s 중요!
- 웹서버: 동시 접속자 많고 요청 작음 → IOPS 중심
- 백업 시스템: 대량 전송 → MB/s 중심
💬 IOPS는 요청의 "빈도", MB/s는 처리의 "무게"다!
마치 하루 100번 배달 나가는 오토바이 기사와, 하루 한 번 냉장고 가득 싣고 나가는 트럭처럼요.
🔍 용어 정리 + 설명
- IOPS는 "얼마나 자주" → 횟수 기준
- MB/s는 "얼마나 많이" → 양 기준
- 둘 다 Throughput이지만 목적이 다름!
- 리눅스에서도 구분해서 사용해야 정확한 성능 분석 가능
| 지표명 | 뜻 | 의미 | 주로 중요한 상황 |
|---|---|---|---|
| IOPS (Input/Output per Second) | 초당 입출력 횟수 | 얼마나 많은 I/O 요청을 빠르게 처리하는지 | OLTP, DB, 웹서버 등 → 요청 수가 많은 환경 |
| MB/s (Megabytes per Second) | 초당 데이터 전송량 | 얼마나 많은 데이터를 옮기는지 | 백업, 대용량 파일 복사 등 → 한 번에 많은 데이터를 처리할 때 |
| Latency | 지연 시간 | 하나의 요청이 끝나는 데 걸리는 시간 | 실시간 시스템, 반응성 중요한 곳 (게임 서버, 실시간 통신 등) |
💡 IOPS는 수, MB/s는 양, Latency는 속도 개념
→ 다 Throughput이지만, 서로 다른 목적에 쓰입니다!
📌 리눅스에서 각 지표 어떻게 확인할까?
리눅스에서는 아래 도구들을 통해 IOPS, MB/s, Latency를 직접 확인할 수 있습니다:
✅ 1. iostat – 디스크 단위 I/O 성능 보기
sudo apt install sysstat # 없으면 설치
iostat -dx 1 5 # 1초마다 5번 측정| 주요 항목 | 의미 |
|---|---|
| tps | 초당 I/O 횟수 (IOPS) |
| kB_read/s, kB_wrtn/s | 초당 읽기/쓰기 양 (KB/s → MB/s) |
| await | 평균 I/O 응답 시간 (Latency) |
✅ 2. iotop – 실시간으로 프로세스별 I/O 확인
sudo iotop| 주요 항목 | 의미 |
|---|---|
| DISK READ/WRITE | 해당 프로세스의 실시간 MB/s |
| IO% | 디스크 사용률 |
→ 누가 얼마나 쓰는지 직관적으로 보기 좋아요.
✅ 3. blktrace – 블록 단위 I/O 활동 추적
sudo blktrace -d /dev/sda -o - | blkparse -i -- 매우 상세한 디스크 이벤트 추적 가능 (고급 분석용)
- 초당 I/O 수, 큐 깊이, 디스크 큐 길이 등까지 파악 가능
✅ 4. perf stat – 시스템 전체의 성능 카운터 확인
perf stat -e block:block_rq_issue,block:block_rq_complete dd if=/dev/zero of=tempfile bs=1M count=1000 oflag=direct- I/O 횟수, 사이클 수, instruction 수 등과 함께 I/O 활동도 측정 가능
🔬 실험: fio로 IOPS vs MB/s 차이 직접 보기
fio는 가장 강력한 I/O 벤치마크 도구입니다.
1) 작은 I/O (IOPS 중심)
fio --name=iops-test --ioengine=libaio --rw=randread \
--bs=4k --size=512M --numjobs=1 --runtime=30 --group_reporting- 블록 크기: 4KB
- 랜덤 읽기
- 결과: IOPS는 높고, MB/s는 낮음
2) 큰 I/O (MB/s 중심)
fio --name=mbps-test --ioengine=libaio --rw=read \
--bs=1M --size=512M --numjobs=1 --runtime=30 --group_reporting- 블록 크기: 1MB
- 순차 읽기
- 결과: MB/s는 높고, IOPS는 낮음
📈 실험 결과 예시 비교
| 실험 | 블록 크기 | IOPS | MB/s |
|---|---|---|---|
| 랜덤 읽기 | 4KB | 10,000 | 40 MB/s |
| 순차 읽기 | 1MB | 100 | 100 MB/s |
→ 요청 횟수가 많다고 해서 전송량이 높은 건 아님!
→ 요청 크기가 커지면 한 번에 더 많은 데이터를 옮기게 됨.
🧠 요약: 리눅스에서도 이렇게 구분해야 한다!
- IOPS는 트랜잭션 수 / 요청 수에 민감한 환경 (DB, OLTP)
- MB/s는 대용량 처리 성능이 중요한 환경 (백업, 미디어 서버)
- Latency는 응답 속도에 민감한 환경에서 중요 (게임, API)
| 구분 | IOPS | MB/s | Latency |
|---|---|---|---|
| 단위 | IO/s | MB/s | ms |
| 관점 | 요청 수 | 데이터 양 | 속도 |
| 중요 환경 | DB, OLTP | 백업, 복사 | 게임, API 서버 |
- 리눅스에서도 IOPS ≠ MB/s
- 둘 다 Throughput이지만 목적과 용도가 다름
- 실제 분석에는
fio,iostat,iotop,blktrace,perf등을 함께 사용해야 함 - 그리고 무엇보다도!
"어떤 작업을 측정하느냐"에 따라 적절한 지표를 고르는 것이 진짜 중요합니다.
10. 병렬 실행이 중요한 이유
예전에는 CPU 하나만 빠르면 대부분의 프로그램이 빨라졌습니다. 하지만 지금은 멀티코어 시대입니다. 코어 수가 늘어나며 프로그램도 병렬로 잘 쪼개서 실행되도록 만들어야 해요. 운영체제도, 커널도, 그리고 우리 애플리케이션도 이 흐름에 맞춰 변화해야 합니다.
마치며 – 스케줄러는 운영체제의 보이지 않는 심장이다
리눅스 스케줄러는 단순히 프로세스 순서를 정하는 게 아닙니다. 시스템 자원의 활용도, 응답 속도, 그리고 전체적인 사용자 경험에 막대한 영향을 미치는 중요한 구성 요소입니다.
지금 이 순간에도 여러분의 시스템에서는 수많은 프로세스들이 "제 차례는 언제인가요?"라고 줄을 서 있습니다. 그 줄을 빠르게, 공정하게, 그리고 효율적으로 돌리는 리눅스 스케줄러의 세계는 우리가 생각했던 것보다 훨씬 정교하고 똑똑합니다.
"멀티태스킹의 시대, 그 중심에는 언제나 스케줄러가 있다."
