일주일이 지나고, 새로운 주차가 시작되었다. 새로운 팀원분들과 새로운 마음으로 시작하겠다.
이번주의 새로 배울 내용은 이분 탐색, 분할 정복, 스택, 큐, 우선순위 큐, Linked List, 해시 테이블 이다.
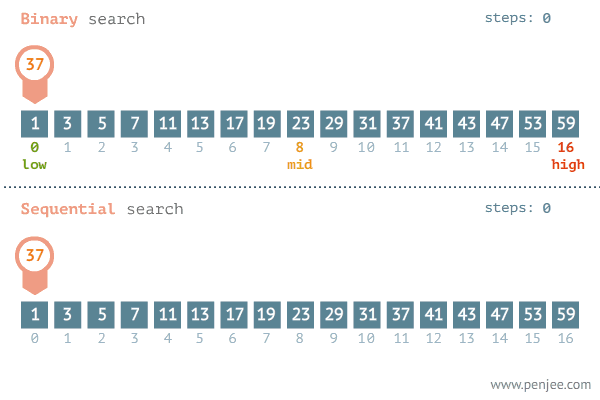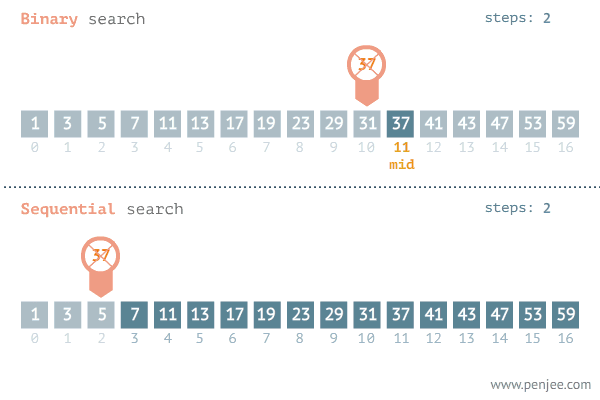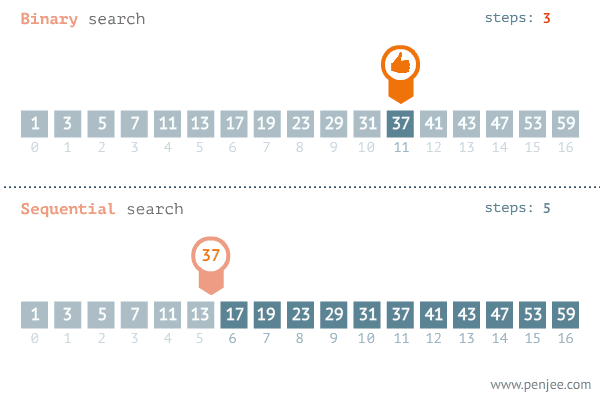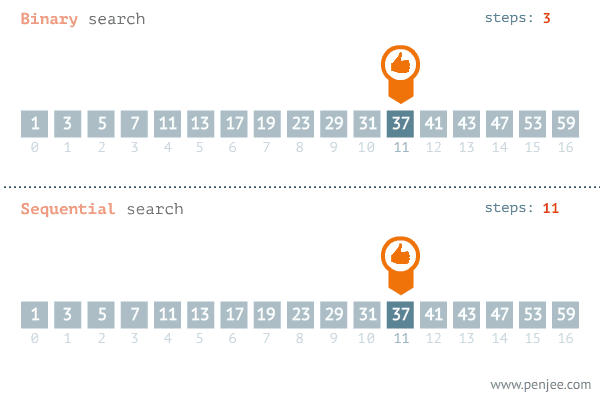
이진 검색 알고리즘
퀵소트하고 개념이 비슷하다. 어떤 수 x를 찾을 때 인덱스에서 1/2되는 지점을 기준인 pc로 잡는다. 그 후 x에 대해 pc와 비교해 가까운 구간만 검색 범위로 줄인다. 줄여진 범위에서 pc를 1/2 지점으로 재지정한 다음 전처럼 x와 pc를 비교하여 가까운 구간만 검색 범위를 줄인다. 언젠간 두개까지 남을 것이고 해당되는 x가 있으면 검색에 성공하고 한개까지 남았는데도 못찾으면 검색을 실패한 것이다. pl과 pr은 퀵소트처럼 왼쪽, 오른쪽 검색 시작 위치.
여기서 복잡한 개념이 있다. 검색범위를 나눌때,
만약 기존값보다 x값이 크면 pl(왼쪽 시작 부분)을 전체 자료값의 반인 pc에 +1을 하여 반절부터 검색하게끔하여 검색 범위를 뒤쪽 절반으로 좁힌다.
반대로, 기존값보다 x값이 작으면 pr(오른쪽 시작 부분)을 전체 자료값의 반인 pc에 -1을 하여 반절부터 검색하게끔하여 검색 범위를 앞 절반으로 좁힌다.
1번 (1920) 수 찾기
먼저 N개의 정수를 입력받아야한다. 비교할 줄인 다음줄 M개의 정수도 입력 받아야한다. 힌트가 이진 검색트리이니, 해당 방식으로 구현해 보겠다. 이진 검색트리는 이진검색 알고리즘하고 비슷하다. 책에 있는 내용을 따왔다. 내가 초반에 이진 검색 트리를 써서 시간좀 썻다. 이진 탐색을 사용하기 위해서는 값이 정렬되어 있어야한다.
from typing import Any, Sequence
def bin_search(num: Sequence, key: Any) -> int:
pl = 0 # 검색범위 맨 앞 원소의 인덱스
pr = len(num) - 1 # 검색범위 맨 끝 원소의 인덱스
while pl <= pr: # pl은 pr보다 작거나 같을 동안
# pc가 key하고 일치 할 경우에는 pl < pr인 케이스로 if문을 통과해 종료된다.
# 그러나 key가 일치 하지 않을 때, pl=pr이다. 만약 while True이면 if절로 pl이 pr을 뛰어 넘을때 종료
# 한다는 조건을 걸고 while문을 한바퀴 더 돌아야하지만, pl과 pr이 일치할때 첫 if문에 만족하지 않는다는 것은
# 탐색 리스트에서 key값이 없음을 의미하므로 바로 return -1을 출력하면 된다.
pc = (pl + pr) // 2 # 중앙 지정
if num[pc] == key: # 키랑 pc랑 같으면 찾음
return pc # pc값을 리턴
elif num[pc] < key: # 키값이 크면
pl = pc + 1 # 오른쪽 범위로 이동
else:
pr = pc - 1 # 키 값이 작으면 왼쪽 범위로 이동
return -1 # 비정상 종료(결과에 없음)
n = int(input())
num = sorted(list(map(int,input().split()))) # 이진 탐색을 위한 정렬(기준이 될 리스트이므로)
m = int(input())
keys = list(map(int,input().split())) # 찾아야되는 key들
# 이진 탐색 수행 및 결과 출력
for key in keys: # 한 개씩 돌아가면서 비교
result = bin_search(num, key) # 입력 받은 값을 대입
print(1 if result != -1 else 0) # 위 함수의 리턴이 -1이 아니면 1 출력20:00 ~ 21:45
매일 20시에 시행하는 그룹 스터디 시간을 가졌다. 본인의 문제 스타일을 이야기하고, 어떤 방식으로 접근했는지. 어려운 문제에 대해 힌트를 얻을 수 있는 유익한 시간이었다. 전에는 문제를 90퍼센트는 이해했다고 생각했는데, 막상 발표를 하다보니 떨리고 이해안된 부분도 있어서 나중에 다시 복습해야겠다.
2번 (2805) 나무 자르기
먼저 그림을 그려보면 문제를 이해하는건 어렵지 않다. 일단 내가 아는 건 N은 나무 갯수이고 M은 집에 가져가야하는 나무 길이, H는 결과로 알아야되는 절단기 최댓값이라는 점이다. 나무 N개의 길이를 받을 수 있는 Tree_length도 받아야한다.
import sys
N, M = map(int, sys.stdin.readline().split())
Tree_length = list(map(int, sys.stdin.readline().split()))
# high = 절단기 결과
# 이분탐색을 하려면 자를 높이의 최솟값(0)과 최대값(가장 긴 나무)를 설정해야한다.
low, high = 0, max(Tree_length)
# 이분 탐색을 시작한다. 계속해서 반복하면 절단하는 나무 M을 가져가기 위한 최댓값을 출력 할 수 있다.
while low <= high: # 기존의 pl과 pr이라 생각하면 편하다. 조건값을 찾으면 종료한다.
mid = (low + high) // 2 # 중간값을 정한다.
# 우린 잘린 나무의 합이 M보다 크기만 하면 된다.
# mid 높이에서 잘랐을 때 가져올 수 있는 나무 총량을 계산한다.
wood = sum(tree - mid for tree in Tree_length if tree > mid)
# 위의 리스트 컴프리헨션을 풀어보면 밑에 공식과 같다.
# wood = 0 # 가져올 수 있는 나무의 총량이다.
# for tree in Tree_length: # 트리 리스트에 있는 트리들의 높이들을 하나씩 수행해 본다.
# if tree > mid: # 나무가 자르는 높이(mid)보다 클 때만 계산(제일 큰 나무가 기준이라 작을 때는 없다)
# wood = wood + (tree - mid) # 기존 나무에서 잘린 부분만 합산.
if wood >= M: # M보다 더 많이 짤렸을때 기준값에 최솟값을 1 올린다.
low = mid + 1
else: # 그 외의 경우(M보다 클때)는 기준값에 높이 최댓값을 1 내린다.
high = mid - 1
# 절단기의 높이를 출력한다.
print(high)중간의 리스트 컴프리헨션 쓰는 것이 어렵다. 이진탐색이 개념은 이해하기 괜찮은데, 활용하는게 너무 어렵다…
두번재 문제인데도 벌써 어렵다. GPT의 도움을 받아 작성했다. 잠을 많이 못자 컨디션이 좋지 않은지 이해가 잘 되지 않는다... 빨리 끝내고 가서 자야겠다.
