3.5 산술 연산과 논리 연산
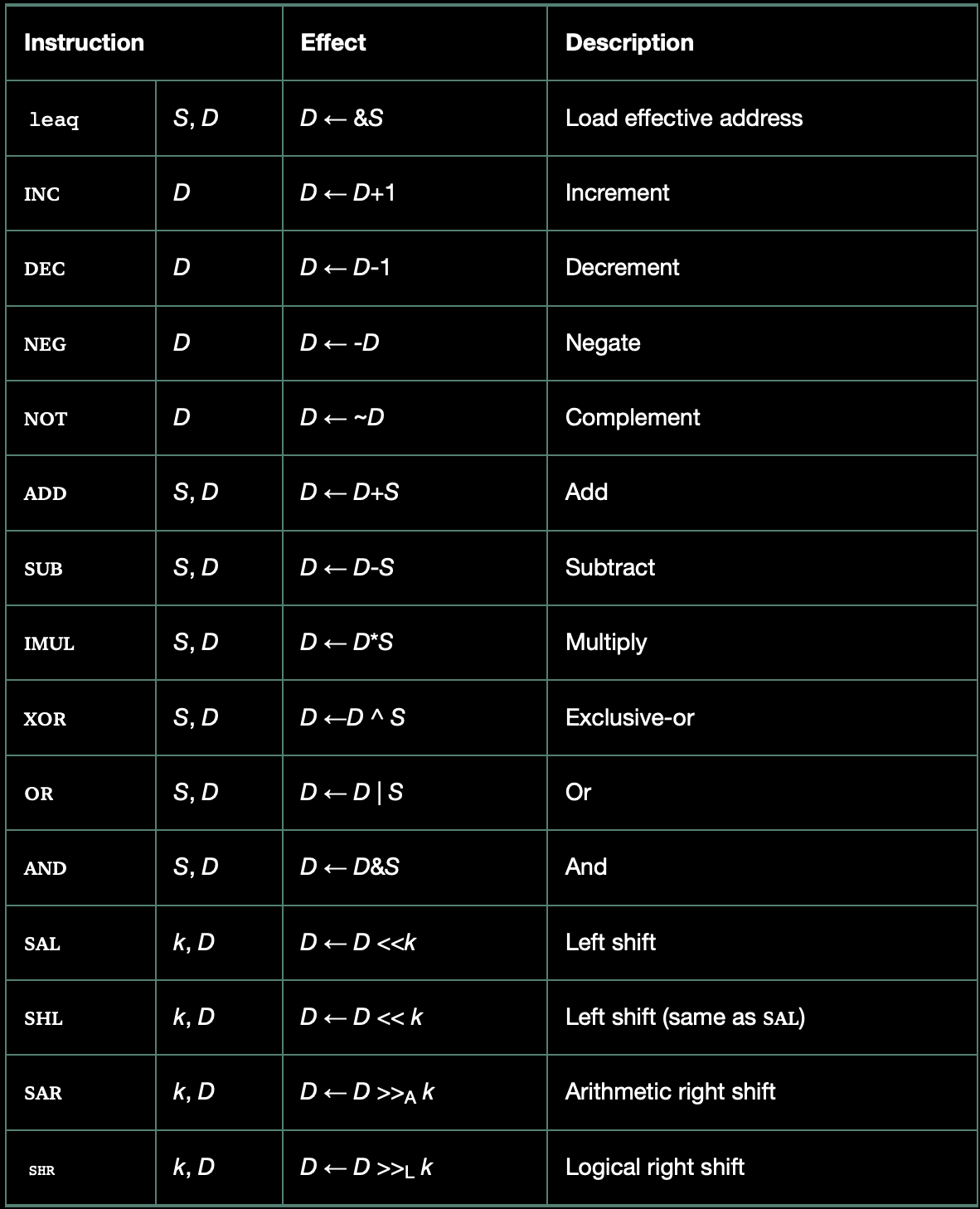
정수의 산술연산 / leaq는 일반적으로 간단한 산술연산을 위해서 사용함.
해당 표는 정수와 논리연산의 리스트를 보여준다. 오퍼랜드의 길이에 따른 다양한 변형이 가능하기 때문에 대부분의 연산을 인스트럭션 클래스에 따라 나열하였다. (leaq는 길이 따른 변형 없음)
Ex) 인스트럭션 클래스 ADD는 네 개의 덧셈 인스트럭션으로 이루어져 있다.
→ addb: 바이트, addw: 워드, addl : 더블워드, addq: 쿼드워드 덧셈
실제로 각 클래스는 네 개의 서로 다른 크기의 데이터 연산을 가진다.
또한 유효주소 적재, 단항, 이항, 쉬프트의 네 개의 그룹으로 나누어진다.
이항 연산은 두 개의 오퍼랜드를 가지는 반면에 단항 연산은 한 개의 오퍼랜드를 가진다. 기존의 표기법과 동일.
3.5.1 유효주소 적재
유효주소 적재 인스트럭션 leaq는 실제 movq의 변형이다. 이건 메모리에서 레지스터로 읽어들이는 인스트럭션의 형태를 갖지만, 메모리를 전형 참조하지 않는다.
첫 번째 오퍼랜드는 메모리 참조처럼 보이지만, 가리키는 위치에서 읽기를 수행하는 대신에 유효주소를 목적지에 복사한다. 위 리스트에서 C주소 연산자 &S를 사용해서 이러한 계산을 수행하는 것을 보여준다.
이 인스트럭션은 나중의 메모리 참조에 사용하게 되는 포인터를 생성하기 위해 사용한다. 또, 일반적인 산술연산을 간결하게 설명하기 위해 사용한다.
Ex) 레지스터 %rdx가 x를 가지고 있을시, leaq 7(%rdx, %rdx, 4) → 레지스터 %rdx에 5x + 7 저장.
컴파일러는 자주 실제 유효 주소계산과 무관한 경우에 leaq를 적절히 사용하곤 한다. 목적 오퍼랜드는 반드시 레지스터만 올 수 있다.
컴파일한 코드에서 leaq의 사용을 살펴보기 위한 예제로 다음의 C코드를 생각하면
long scale(long x, long y, long z) {
long t = x + 4 * y + 12 * z;
return t;
}컴파일시, 이 함수의 산술열산들은 연속된 3개의 leaq로 구현된다.
long scale(long x, long y, long z)
x in %rdi, y in %rsi, z in %rdx
scale:
leaq (%rdi,%rsi,4), %rax # x + 4*y
leaq (%rdx,%rdx,2), %rdx # z + 2*z = 3*z
leaq (%rax,%rdx,4), %rax # (x+4*y) + 4*(3*z) = x + 4*y + 12*z
ret#이후의 주석이 설명이다. leaq는 덧셈을 실행할 수 있고, 제한된 형태의 곱셈을 할 수 있는 능력은 이 예제처럼 간단한 수식을 컴파일할 때 유용하다.
3.5.2 단항 및 이항 연산
두 번째 그룹에서 연산은 하나의 오퍼랜드가 소스와 목적지로 동시에 사용되는 단항 연산이다.
이 오퍼랜드는 레지스터나 메모리 위치가 될 수 있다.
Ex) incq (%rsp)는 스택 탑의 8바이트 원소의 값을 증가시켜준다. 이 문법은 C에서의 증가 와 감소 연산자를 연상시킨다.
세 번째 그룹은 이항 연산자들로 구성되며, 두 번째 오퍼랜드는 소스이면서 목적지로 사용된다.
이 문법은 C에서의 할당 연산자인 x -= y 같은 문장과 유사하다. 그렇지만, 소스가 먼저 오고 목적지가 나중에 나온다. 이건 비교환성 연산으로 특이하게 보인다.
Ex) subq %rax, %rdx는 레지스터 %rdx에서 %rax 값만큼 빼준다.
여기서 첫 번째 오퍼랜드는 상수나 레지스터, 메모리 위치가 올 수 있다.
두 번째는 레지스터나 메모리가 올 수 있다.
MOV처럼 두 개의 오퍼랜드가 모두 메모리 위치가 될 수 없다. 두 번째 오퍼랜드가 메모리 위치일 때 프로세서가 메모리에서 값을 읽고, 연산을 하고, 그 결과를 다시 메모리에 써야한다는 점을 유의해야한다.
3.5.3 쉬프트 연산
마지막 그룹은 쉬프트 연산으로 구성된다. 비트를 이동시킨다.
방식: 쉬프트하는 크기를 먼저 주고, 쉬프트할 값을 두 번째로 준다.
산술과 논리형 우측 쉬프트가 모두 가능하다. 여러 가지 쉬프트 인스트럭션들은 쉬프트할 양을 즉시 값이나 단일 바이트 레지스터 %cl로 명시할 수 있다. 원직적으로, 1바이트 쉬프트 양은 2^8 - 1 = 255까지 가능하다.
x86-64에선 w비트 길이의 데이터 값에 적용하는 쉬프트 연산은 레지스터 %cl의 하위 m 비트로 쉬프트 양을 결정한다. 2^m = w의 관계가 성립하며 상위 비트들은 무시된다.
Ex) 레지스터 %cl이 16진수 값 0xFF를 가질시, salb는 7만큼 쉬프트하고, salw는 63만큼 쉬프트한다.
상단의 리스트처럼 좌측 쉬프트 인스트럭션에는 두 가지 이름이 있다. SAL과 SHL.
이것은 모두 동일한 효과를 내고, 우측에서부터 0을 채운다. 우측 쉬프트 인스트럭션은 SHR이 논리 쉬프트(0채움)를 수행하지만, SAR이 산술 쉬프트(부호 비트 복사해서 채움)을 수행한다는 점에서 차이가 있다. 쉬프트 연산의 목적 오퍼랜드는 레지스터나 메모리 위치가 될 수 있다. 위 리스트에서 이 두가지 다른 우측 쉬프트 연산을 >>A(산술) 과 >>L(논리)라 표시했다.
3.5.4 토의
상단의 리스트의 대부분의 인스트럭션은 비부호형과 2의 보수 산술연산에 사용될 수 있다. 오직 우측 쉬프트 만이 부호형과 비부호형 데이터를 구분하는 인스트럭션을 요구한다.
이것이 부호형 정수 산술연산을 구현하는 방식으로 2의 보수 산술연산을 선호하는 주요 특징이다.
C언어
long arith(long x, long y, long z)
{
long t1 = x ^ y;
long t2 = z * 48;
long t3 = t1 & 0x0F0F0F0F;
long t4 = t2 - t3;
return t4;
}어셈블리어
long arith(long x, long y, long z)
x in %rdi, y in %rsi, z in %rdx
1 arith:
2 xorq %rsi, %rdi t1 = x ^ y
3 leaq (%rdx,%rdx,2), %rax 3*z
4 salq $4, %rax t2 = 16 * (3*z) = 48*z
5 andl $252645135, %edi t3 = t1 & 0x0F0F0F0F
6 subq %rdi, %rax Return t2 - t3
7 ret위 산술연산을 수행하는 함수와 이것의 어셈블리 코드로 번역된 형태의 예시를 보여준다.
초기 줄: 인자 x, y, z는 각각 레지스터 %rdi, %rsi, %rdx에 저장된다.
어셈블러 코드의 인스트럭션은 C 소스코드의 줄번호와 밀접하게 대응된다.
2줄: x ^ y를 계산한다.
3, 4줄: z*48을 leaq와 쉬프트를 결합해서 계산.
5줄: t1과 0x0F0F0F0F의 AND를 계산
6줄: 마지막 뺄셈 계산
뺄셈의 목적지는 %rax이므로 이 함수가 리턴하는 값이 된다.
위 그림의 어셈블리 코드에서 %rax에 저장되는 값들은 3z, z48, t4(리턴 값으로 사용)에 대응된다.
일반적으로 컴파일러는 각각의 레지스터를 여러 가지 프로그램의 값을 저장 및 이동하는데 사용.
3.5.5 특수 산술연산
두 개의 64비트 부호형 또는 비부호형 정수들 간의 곱셈은 결과값을 표시하기 위해 128비트를 필요로 한다. x86-64 명령어 집합은 128비트(16바이트) 숫자와 관련된 연산에 대해서 제한적인 자원을 제공한다.
기존의 명명법인 워드, 더블워드, 쿼드 워드 방식을 이어가면서 인텔은 16바이트 워드를 옥트워드라고 명명했다.

특수 산술연산
위 그림은 나눗셈뿐 아니라 두 개의 64비트 수를 곱하여 완전 128비트 곱을 생성할 수 있도록 지원하는 인스트럭션을 보여준다.
imulq 명령어는 정수 곱셈을 수행하는 데 사용되며, 두 가지 주요 형태가 존재한다.
첫 번째 형태는 두 개의 피연산자를 사용하는 방식으로, 일반적인 정수 곱셈 연산을 수행한 뒤 결과를 64비트로 자른다(truncate).
Ex)imulq source, destination와 같은 형식으로 사용되며, 두 피연산자(모두 64비트)를 곱한 뒤 결과를 destination에 저장한다. 이때 내부적으로는 부호 있는 곱셈(*64t) 또는 부호 없는 곱셈(*64u) 중 어떤 것이 사용되든, 결과가 64비트로 잘리기 때문에 비트 수준 결과는 동일하다.
즉, 부호 유무가 결과에 영향을 주지 않는다.
두 번째 형태는 하나의 피연산자만 사용하는 방식으로, 전체 128비트 곱셈 결과를 얻기 위한 방식이다. 이 경우 반드시 %rax 레지스터에 하나의 피연산자를 넣어야 하며, 명령어에 명시된 다른 하나의 피연산자(source operand)와 곱해진다. 연산 결과는 두 개의 레지스터에 나뉘어 저장되는데, 하위 64비트는 %rax, 상위 64비트는 %rdx에 각각 저장된다. 이때 imulq는 부호 있는 정수 곱셈(signed multiplication)을 수행하고, 같은 방식으로 부호 없는 곱셈을 수행하는 명령어는 mulq이다. 이 두 명령어 모두 결과를 128비트로 확장해서 저장하기 때문에, 오버플로우 여부를 판단하거나 큰 수 계산에 유용하다.
→ 결론적으로 imulq는 피연산자의 수에 따라 동작 방식이 달라지며, 어셈블러는 피연산자의 개수를 기반으로 어떤 방식의 곱셈을 할 것인지 자동으로 판단한다. 두 피연산자가 있을 경우 일반적인 64비트 곱셈을 수행하고 결과를 잘라 저장하며, 하나의 피연산자일 경우에는 %rax와 %rdx를 사용하여 전체 128비트 결과를 저장한다. 이처럼 imulq는 하나의 이름으로 두 가지 다른 역할을 수행하므로, 프로그래머는 문맥에 따라 올바르게 사용해야 한다.
Ex) 다음의 C 코드는 두 개의 비부호형 수 x와 y의 128비트 곱을 생성하는 것을 보여준다.
#include <inttypes.h>
typedef unsigned __int128 uint128_t;
void store_uprod(uint128_t *dest, uint64_t x, uint64_t y) {
*dest = x * (uint128_t) y;
}해당 프로그램에서 C표준 확장 형태 inttypes.h에 선언된 정의들을 이용해서 x와 y를 64비트 숫자로 선언한다.
그러나 이 표준은 128비트 값들에 대해서 제안하지 않는다. 대신, 128비트를 위해 GCC가 제공하는 __int128을 이용해서 선언하는 방법에 의존한다. 우리 코드는 inttypes.h에 있는 다른 자료형들의 명명법을 본따서 typedef함수를 사용해서 자료형 unit128_t을 정의한다.
이 코드는 곱셈 결과 값이 포인터 dest로 지시된 16바이트에 저장되야하는 것을 명시한다.
위의 특수 산술연산 내용을 GCC로 생성한 어셈블리 코드는 아래다.
void store_uprod(uint128_t *dest, uint64_t x, uint64_t y)
dest in %rdi, x in %rsi, y in %rdx
1 store_uprod:
2 movq %rsi, %rax x를 곱해지는 수에 복사
3 mulq %rdx y를 곱한다
4 movq %rax, (%rdi) dest에 하위 8비트를 곱한다
5 movq %rdx, 8(%rdi) dest+8에 상위 8비트를 곱한다
6 ret곱을 지정하기 위해서는 두 개의 movq 인스트럭션이 필요하다. 하나는 하위 8바이트, 하나는 상위 8 바이트.
이 코드가 리틀 엔디안 머신을 위해 생성된거라 주소지시자 8(%rdi)로 표기한 것처럼 상위 바이트들은 높은 주소에 저장된다.
앞에 나온 산술 연산 표에선 나눗셈이나 나머지 연산들이 빠져 있었지만, 해당 연산은 단일 오퍼랜드 곱셈 인스트럭션과 비슷한 단일 오퍼랜드 나눗셈 인스트럭션으로 제공된다. 부호형 나눗셈 인스트럭션 idivq는 피제수를 128비트로 %rdx와 %rax에 저장한다. 제수는 인스트럭션의 오퍼랜드로 주어진다. 인스트럭션의 몫은 레지스터 %rax에 나머지는 %rdx에 저장한다.
64비트 나눗셈의 응용 대부분에서 피제수는 64비트에 값으로 주어진다. 이값은 %rax에 저장되어야하고 %rdx의 비트들은 모두 0(비부호형 산술연산) 또는 %rax의 부호비트(부호형 산술연산)로 설정되야한다. 후자의 연산은 cqto를 이용해서 실행 가능하다. 오퍼랜드가 없고 %rax의 부호비트를 묵시적으로 읽어서 %rdx 전체에 복사한다.
x86-64로 나눗셈을 구현한 예제로 다음의 C함수는 두 64비트 부호형 수의 몫과 나머지를 계산한다.
void remdiv(long x, long y,
long *qp, long *rp) {
long q = x/y;
long r = x%y;
*qp = q;
*rp = r;
}이건 밑의 어셈블리 코드로 컴파일된다.
void remdiv(long x, long y, long *qp, long *rp)
x in %rdi, y in %rsi, qp in %rdx, rp in %rcx
1 remdiv:
2 movq %rdx, %r8 ; 몫을 저장할 포인터(qp)를 %r8 레지스터로 복사
3 movq %rdi, %rax ; x 값을 %rax에 복사 (나눗셈을 위한 하위 64비트 설정)
4 cqto ; %rax의 부호를 확장하여 %rdx에 저장 (128비트 피제수 설정)
5 idivq %rsi ; %rdx:%rax 값을 y(%rsi)로 나눔 (몫은 %rax, 나머지는 %rdx에 저장)
6 movq %rax, (%r8) ; 계산된 몫(%rax)을 qp가 가리키는 주소에 저장
7 movq %rdx, (%rcx) ; 계산된 나머지(%rdx)를 rp가 가리키는 주소에 저장
8 ret ; 함수 종료 및 복귀인자 qp는 인자 %rdx가 나눗셈 연산을 위해 필요하므로 다른 레지스터에 먼저 저장되어야한다.
3, 4 줄은 x를 부호 확장해서 복사하여 피제수를 준비한다.
나눗셈 후 레지스터 %rax에 들어 있는 몫은 qp에 저장되며
레지스터 %rdx의 나머지는 rp에 저장된다.
비부호형 나눗셈은 divq를 이용한다. 일반적으로 %rdx는 계산에 앞서 0으로 설정된다.
