배열
index와 value를 일대일 대응해 관리하는 자료구조
데이터를 저장할 수 있는 모든 공간이 index와 일대일 대응하므로 어떤 위치에 있는 데이터든 한번에 접근할 수 있음 (=random access)
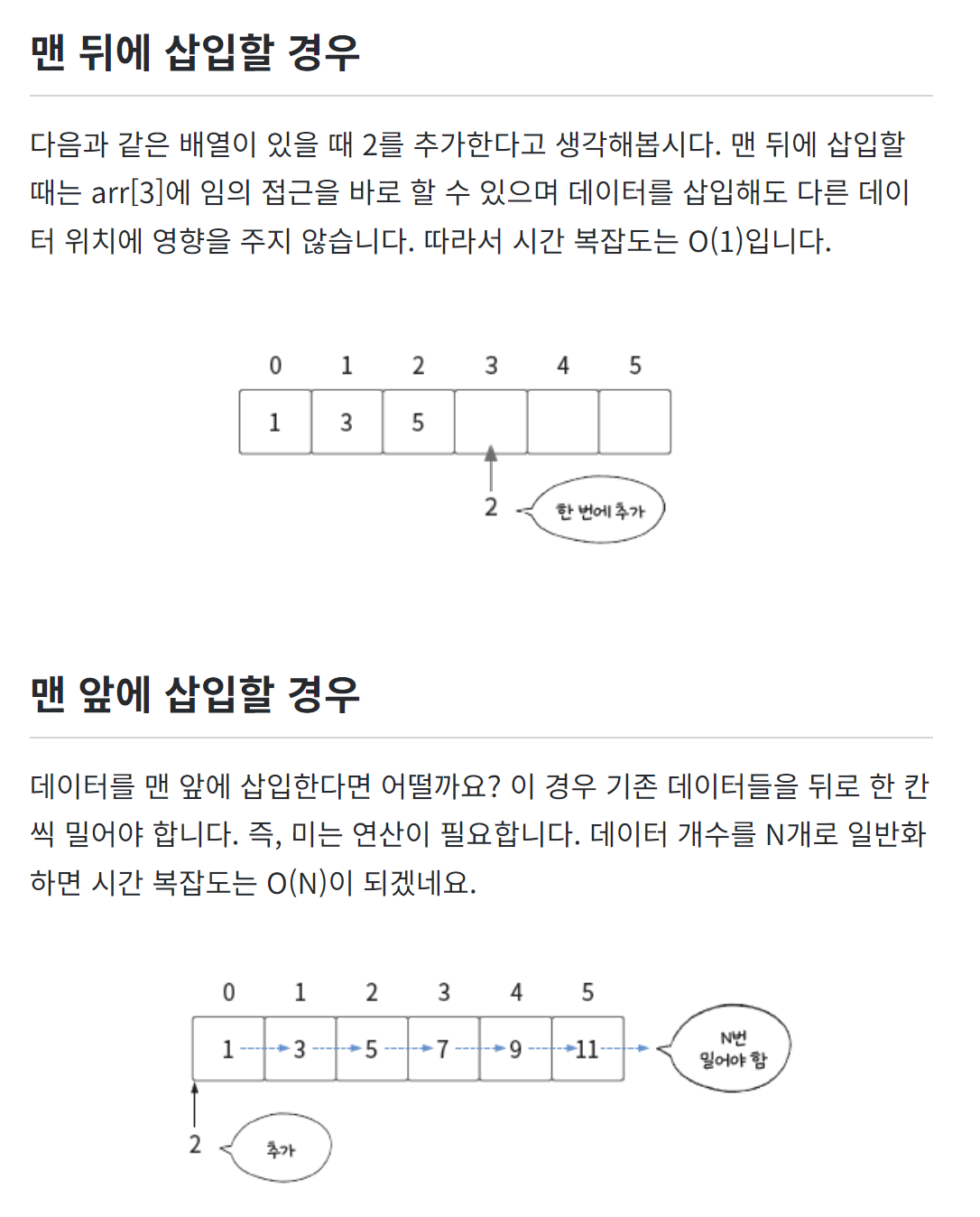
배열 데이터는 임의 접근 random access 으로 배열의 모든 위치에 있는 데이터에
단 한번에 접근할 수 있기 때문에
데이터에 접근하기 위한 시간복잡도는 O(1)
그럼 배열에 데이터를 추가로 삽입/삭제할 때에는?
때문에 배열을 선택할 때
배열의 장/단점을 잘 생각해야 함
배열의 데이터에 자주 접근한다면 배열이 효율적이지만
메모리 공간을 충분히 필요로 하기 때문에 메모리 낭비가 발생할 수 있음
그러므로 아래의 두 가지 주의사항이 있다.
1. 할당 가능한 메모리의 크기 확인할 것
2. 중간에 데이터 삽입/삭제가 많은지 확인할 것
문제 01. 배열 정렬하기
내가 한 것 :
def solution(x):
if not isinstance(x, list):
return None
x_sorted = x.sort()
return x_sorted내가 아는 것 : 배열을 정렬하는 함수
내가 모르는 것 : 문제의 제약조건의 활용법
제약조건 :
1. 정수 배열의 길이는 2이상 10^5이하
2. 정수 배열의 각 데이터 값은 -100,000이상 100,000이하
- 배열의 길이 최대값 : 10^5
제한시간이 3초라면, 초당 100,000,000번(10^8) 연산을 최대라고 보통 계산하기 때문에
O(N)이면 10^5회
O(N2)이면 10^10회 연산이 필요하다고 생각해 볼 수 있음(최소 100초는 필요하겟는데;;)
그래서 만약에 for문으로 배열을 하게되면 해당 문제는 틀릴수 밖에 없다
참고로 sort의 시간복잡도는O(NlogN)
문제 02. 배열 제어하기
내가 한 것 :
def solution(arr):
arr_unique = list(set(arr))
return arr_unique.sort(reverse=True) 내가 아는 것 : set함수, sort함수
내가 모르는 것 : 시간 복잡도 계산
- list->set : O(n)*O(1)=O(n)
- sort : O(nlogn)
최종 시간 복잡도는 O(NlogN)
문제 03. 2개 뽑아서 더하기
제약조건 :
1. numbers의 길이는 2이상 100이하
2. numbers의 모든 수는 0 이상 100이하
내가 한 것 :
def solution(numbers):
pairs = []
n = len(numbers)
for i in range(n):
for j in range(n):
if i == j:
pass
else:
sum_pair = n[i]+n[j]
pairs.append(sum_pair)
pairs_sorted = list(set(pairs)).sort()내가 아는 것 : 풀이 방법, 대략적인 시간 복잡도
내가 모르는 것 : A+B=B+A라는 것( j는 굳이 1부터 시작하지 않아도 되었음), 정확한 시간 복잡도
- for 문 2번 :
O(n^2) - list의 sort :
O(NlogN)인데N<=n^2이므로O(n^2logn^2)
여기서 n은 100이기 때문에 10000*4 정도니까 1초안에 풀림!
문제 04. 모의고사
내가 한 것 :
def solution(answers):
ques_num = len(answers)
a_answers = ques_num//5 * [1, 2, 3, 4, 5] + [1, 2, 3, 4, 5][:ques_num%5]
b_answers = ques_num//8 * [2, 1, 2, 3, 2, 4, 2, 5] + [2, 1, 2, 3, 2, 4, 2, 5][:ques_num%8]
c_answers = ques_num//10 * [3, 3, 1, 1, 2, 2, 4, 4, 5, 5] + [3, 3, 1, 1, 2, 2, 4, 4, 5, 5][:ques_num%10]
correct = [0, 0, 0]
for i in range(ques_num):
if a_answers[i] == answers[i]:
correct[0] += 1
if b_answers[i] == answers[i]:
correct[1] += 1
if c_answers[i] == answers[i]:
correct[2] += 1
max_grade = max(correct)
winner = []
for candi in range(3):
if correct[candi] == max_grade:
winner.append(candi+1)
return winner
문제 05. 행렬의 곱셈
내가 한 것 :
def solution5(arr1, arr2):
r1, c1 = len(arr1), len(arr1[0])
r2, c2 = len(arr2), len(arr2[0])
res = [[0]*c2 for _ in range(r1)] # 여기서 한참 해맴
for i in range(c2):
for j in range(r1):
for k in range(c1):
print("a: ", arr1[j][k])
print("b: ", arr2[k][i])
res[j][i] += arr1[j][k] * arr2[k][i]
print("c: ", res[j][i])
return res내가 아는 것 : 코드 짜는 법
내가 모르는 것 : immutable과 mutable
내가 처음에 짠 것 :
res = [[0] * c2] * r1이렇게 하면 어떻게 되는지 하나씩 살펴보면,
0 ← int (immutable)
[0] * 2 = [0] + [0] = [0,0]
: 첫번째와 두번째 모두 같은 위치의 0을 참조함[0,0] ← list (mutable)
[[0, 0]] * 3 = [[0, 0], [0, 0], [0, 0]]
: 첫번째, 두번째, 세번째 모두 같은 [0,0]을 참조함a = [[0, 0]]*3 a[0][0]=3 print(a) #[[3, 0], [3, 0], [3, 0]]list는 mutable하기 때문에 같은 위치의 list 자체가 변경됨
b = [[0]*2 for _ in range(3)] b[0][0]=3 print(b) #[[3, 0], [0, 0], [0, 0]]for을 통해서 반복하면 매번 새로운 리스트를 만듦
내가 연습할 것 : 시간복잡도 계산
n = 100
O(n^3)
문제 06. 실패율
답지를 참고하여 해낸 것
def solution(N, stages):
"""
N : stage 갯수
stages : 게임을 이용하는 사용자가 현재 멈춰있는 스테이지 번호 배열
"""
# stage별 player명 수
players = [0]*(N+2)
for stage_on_player in stages:
players[stage_on_player] += 1
challengers = [0]*(N+2)
for i in range(N+1, 0, -1):
challengers[i] = sum(players[i:])
fail_rates = {}
for i in range(1, N+1):
if challengers[i] == 0:
fail_rates[i] = 0
else:
fail_rates[i] = players[i]/challengers[i]
result = sorted(fail_rates, key=lambda x : fail_rates[x], reverse = True)
return result내가 모르는 것 :
## sort vs. sorted
a = list([1, 2, 4, 3])
### sort => list.sort() : list 객체의 method
a.sort() # -> a = [1, 2, 3, 4]
a.sort(reverse=True) # -> a = [4, 3, 2, 1]
### sorted => sorted(list) : python의 내장함수(iterable 객체를 정렬된 리스트로 반환)
b = sorted(list) # -> a = [1, 2, 4, 3], b = [1, 2, 3, 4]
## sort와 sorted의 key 인자
data = [(1, 3), (2, 2), (3, 1), (2, 1)]
sorted_data = sorted(data, key = lambda x:x[1])
print(sorted_data) # [(3, 1), (2, 1), (2, 2), (1, 3)]
data.sort(key = lambda x:x[1])
print(data) # [(3, 1), (2, 1), (2, 2), (1, 3)]
## 여러개의 key로 순서를 조절할 때
data = [(1, 3), (2, 2), (3, 1), (2, 1)]
sorted_data = sorted(data, key = lambda x: (x[0], -x[1]))
print(sorted_data) # [(1, 3), (2, 2), (2, 1), (3, 1)]
시간복잡도 계산 :
스테이지 갯수 N은 1과 500 이하의 자연수
stages의 길이 M은 1이상 200,000이하
1초면 10e8니까, 최대 시간 복잡도는 O(NM)이거나 O(MlogM)
제곱이 들어가면 안됨 (=for문이 겹쳐 들어가면 안됨)
내가 만든 코드의 시간복잡도는
첫번째 for문에서 O(M)
두번째 for문에서 O(N)
=> O(M+N) : challengers 계산
세번째 for문에서 O(N) : fail_rates 계산
네번째 정렬(sorted)할때, 시간 복잡도 O(NlogN)
=> O(2N+M+NlogN)
문제 07. 방문 길이
input인 dirs의 길이는 500이하의 자연수
내가 한 것:
def solution(dirs):
ini_pos = (0, 0)
path = []
min_pos = -5
max_pos = 5
for i, dir in enumerate(dirs):
if i == 0:
pre_pos = ini_pos
else:
pre_pos = path[i-1][1]
if dir == 'U':
cur_pos = [pre_pos[0], pre_pos[1]+1]
elif dir == 'D':
cur_pos = [pre_pos[0], pre_pos[1]-1]
elif dir == 'L':
cur_pos = [pre_pos[0]-1, pre_pos[1]]
elif dir == 'R':
cur_pos = [pre_pos[0]+1, pre_pos[1]]
if cur_pos[0] > max_pos : cur_pos[0] = max_pos
elif cur_pos[0] < min_pos : cur_pos[0] = min_pos
elif cur_pos[1] > max_pos : cur_pos[1] = max_pos
elif cur_pos[1] < min_pos : cur_pos[1] = min_pos
cur_pos = tuple(cur_pos)
path.append([pre_pos, cur_pos])
visited_path = set()
for line in path:
line.sort()
if line[0] == line[1]:
continue
line = tuple(line)
visited_path.add(line)
return len(visited_path)
