1. ElasticSearch 이란?
- Elasticsearch는 텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진으로 분산형과 개방형을 특징으로 합니다. Elasticsearch는 Apache Lucene을 기반으로 구축되었으며, 간단한 REST API, 분산형 특징, 속도, 확장성으로 유명한 Elasticsearch는 데이터 수집, 보강, 저장, 분석, 시각화를 위한 무료 개방형 도구 모음인 Elastic Stack의 핵심 구성 요소입니다. 보통 ELK Stack(Elasticsearch, Logstash, Kibana)이라고 하는 Elastic Stack에는 이제 데이터를 Elasticsearch로 전송하기 위한 경량의 다양한 데이터 수집 에이전트인 Beats가 포함되어 있습니다.
- Logstash
다양한 소스(DB, csv파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달 - Elasticsearch
Logstash로부터 받은 데이터를 검색 및 집계를 하여 필요한 관심 있는 정보를 획득 - Kibana
Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
- Logstash
사용
- 애플리케이션 검색
- 웹사이트 검색
- 엔터프라이즈 검색
- 로깅과 로그 분석
- 인프라 메트릭과 컨테이너 모니터링
- 애플리케이션 성능 모니터링
- 위치 기반 정보 데이터 분석 및 시각화
- 보안 분석
- 비즈니스 분석
검색에서 빠른 이유
역색인(Inverted-Index)과 색인(Index)이란?
- 색인이란? 특정한 데이터가 어느 위치에 있는지 미리 저장해두어 검색 시에 빠른 속도로 찾을 수 있는 것입니다. 국어사전에서 가나다순의 첫번째 단어마다 갈피를 만들어 놓아 우리가 찾는 단어를 빨리 찾을 수 있는 것과 비슷한 것입니다.
- Elasticsearch는 텍스트를 파싱해서 검색어 사전을 만든 다음에 inverted index 방식으로 텍스트를 저장합니다.

🏸 구성
1) 다큐먼트(Document)
Elasticsearch 데이터 최소 단위(RDBMS의 Row와 비슷). JSON 오브젝트 하나. 하나의 Document는 다양한 필드로 구성되어 있으며, 이 필드에는 데이터 필드에 해당하는 데이터 타입이 들어감. 중첩구조를 지원하기 때문에 Document 내부에 Document가 들어가는 것도 가능
2) 타입(Type)
여러개의 Document가 모여서 한개의 Type을 이룸(RDBMS의 Table과 비슷). 하지만 Elasticsearch 7.0부터 Type이 완전히 사라졌으며, 현재 Index가 RDBMS의 Table과 Database 역할
3) 필드(Field)
필드(Field)는 Document에 들어가는 데이터 타입으로 RDBMS의 열(Column)과 비슷하다. 하지만 Elasticsearch의 필드는 RDBMS보다 동적이다. RDBMS에서는 하나의 열(Column)이 하나의 데이터 타입만 가질 수 있지만, Elasticsearch에서는 하나의 필드(Field)가 여러개의 데이터 타입을 가질 수 있음
4) 매핑(Mapping)
매핑(Mapping)은 필드와 필드의 속성을 정의하고 색인 방법을 정의한다. 매핑 정보에 여러가지 데이터 타입 지정이 가능하지만 필드명 자체는 중복이 불가능하다.
4) 인덱스(Index)
여러개의 Type이 모여 한개의 Index를 이룸(RDBMS의 Database와 비슷). Elasticsearch 6.1부터는 하나의 Index는 하나의 Type만 가질 수 있기 때문에 Database + Table의 역할.
RDBMS는 쿼리 하나로 여러 데이터베이스의 데이터를 동시에 조회할 수 없지만, Elasticsearch는 가능함(멀티테넌시)
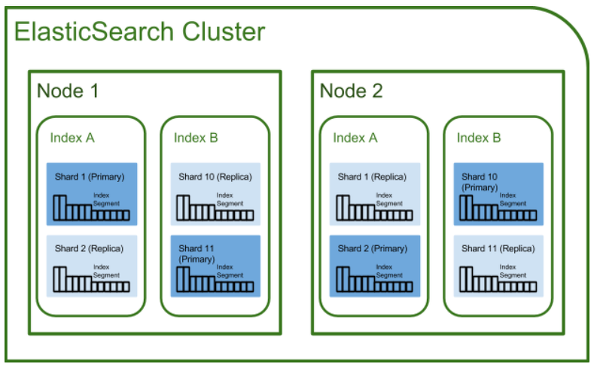
Elasticsearch를 클러스터(분산환경)으로 구성했을 경우 Index는 여러 노드에 분산 저장/관리된다. 기본설정은 5개의 프라이머리 샤드(Prmiary Shard)와 1개의 레플리카 샤드(Replica Shard)를 생성한다. 샤드 수는 인덱스 생성 시 옵션 값을 이용하여 변경 가능함.
1) 클러스터( cluseter )
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합입니다. 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있습니다.
2) 노드( node )
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미합니다.
그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
2. 실전 python 구현
1. ElasticSearch 시작하기
- 설치
pip install elasticsearch# index json 파일 경로
settings = f'./elasticsearch_relay/{index_name}-index_mappings.json'
#json 파일 로드
settings = self.__get_settings_dict(settings)
# parameter setting
settings = self.__set_params(settings)
# 의미 없음
df = self._read_table(rows_per_insert)
# 기존 index 삭제 후 create index
self.__create_index(settings)
self.__update_alias()
만약, 동일한 이름의 인덱스가 있을 경우(exists) 삭제하고(delete) 생성(create)
def make_index(es, index_name):
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
es.indices.create(index=index_name)※ 참고
https://www.elastic.co/kr/what-is/elasticsearch
https://esbook.kimjmin.net/01-overview
https://victorydntmd.tistory.com/308
