
개발환경
머신러닝
종류
- Supervised Learning : 정답이 있거나 정답예측 모델을 만들때
- Unsupervised Learning : 정답이 없을때, 컴퓨터야 알아서 분류좀
- Reinforcement Learning : 컴퓨터에게 게임가르치기_강화학습 ( 정답이면 보상 )
딥러닝
- 머신러닝에서 기계가 사람처럼 생각하면 좋지 않을까 싶어서 만듦.
HiddenLayer
- 중간 Hidden Layer 사용( 여러개 만들면 정교해짐 ) : 기계가 생각할 영역을 만드는 것
- Loss Function우리 예측모델 오차구하는법

- (절대값) 예측한 점수 빼기 정답들의 제곱의 합 -> 오차
- 시그마는 다 더해주세요 라는 뜻
- 텐서 쓸때는 파이썬 코드 한줄로 수학식 다 끝남
활성함수
- 활성함수 : 가중치를 넣고 답을 확인하는데 가중치를 넣은것과 안넣은것이 비슷하면 가중치에 적용시켜보는 함수
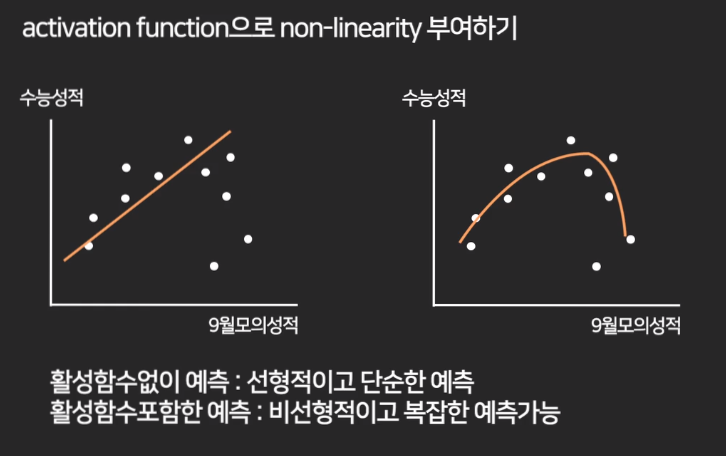
- Layer가 의미가 있어진다
- 비선형적인 예측을 할때 사용된다.
경사하강법
- 최적의 Weight 구하기
- 현재 w값에서 접선의 기울기를 w에서 빼는 것
- 기울기가 오르면 +, 내려가면 -
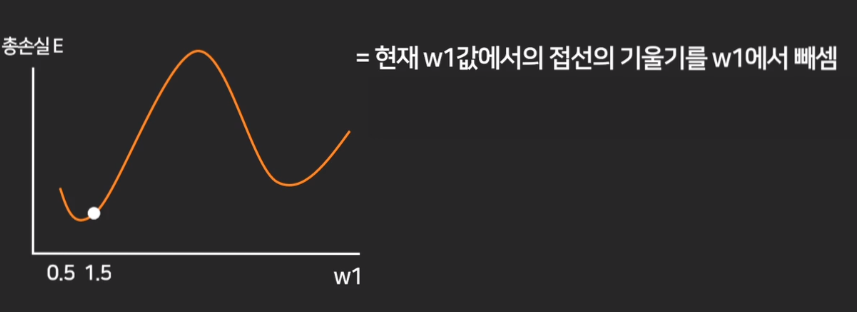
- 기울기가 오르면 +, 내려가면 -
- 딥러닝 학습과정
- w 값 랜덤으로 찍음
- w값 바탕으로 층손실 E를 계산
- 경사하강으로 새로운 w 값 업데이트
반복.
- learning rate : 경사하강 가짜 최저점을 찍는 오류를 면하는 방법
- 굉장히 실험적인 부분. 우리가 알아서 해야함 ( 0.001 부터 시작 )
- 계속 바꿔줘야함 이걸 optimizer라고 함
- Momentum : 가속도 유지
- AdaGrad : 자주 변하는 w는 작게, 자주변하면 크게
- RMSProp : AdaGrad인데 제곱
- Adam ; RMSProp + Momentum (젤 ㄱㅊ은거 같음)
TensorFlow 기본
- Tensor 가 필요한 이유
- 행열로 쉽게 계산 가능

- 행열로 쉽게 계산 가능
constant
import tensorflow as tf
텐서 = tf.constant(3) # constant : 텐서의 숫자, 리스트 담는 곳
print(텐서).zeros()
- 0으로 가득착 텐서생성

tensor 수학함수
- .add()
- .subtract()
- .divide()
- .multipy()
- .matmul() : 행렬 곱
.shape
- 텐서의 모양을 알 수 있다. (행, 열 순)
dtype
- float, int32
- 보통 float 을 사용한다. tf.cast 혹은 tf.float 32를 사용
.Variable()
- weight 값 지정, 저장
.assign()
- weight 값 변경
- 행열값도 변경할 수 있음
.keras.optimizers
- tf.keras.optimizers : 경사하강법을 도와주는 고마운 친구
- .Adam(learning_rate=0.nn) : gradient 를 스마트하게 바꿔줌 ( 기본 )
- 러닝레이트를 알아서 작성하면 됨_ 작성안해도 0.0001 부터 시작
- .Adam(learning_rate=0.nn) : gradient 를 스마트하게 바꿔줌 ( 기본 )
.minimize()
- 경사하강 실행
- opt.minimize(손실함수이름, var_list)
- 손실함수 = 실제값 - 예측값
- 함수이름이 들어가는 곳에는 함수이름만 들어가야한다. ( 함수() X )
lambda:익명함수 만들기
- 만약 함수의 매개변수가 필요하면 lambda::함수() 쓰면 된다. . (lambda:함수() O )
텐서에서 리스트계산
- 리스트 자체를 계산할때 리스트 이름으로 계산식을 때려박으면 행렬 덧셈 느낌으로 계산 다 해줌.
.keras.losses.mse
- 손실함수 return 식 중 하나
def 손실함수():
# 텐서상에서는 리스트를 for문 으로 돌리면 우리가 생각했던 대로 리스트 속 값들 하나하나 차례로 만져짐
예측_y = train_x * a + b
# mean Suared Error = 평균((예측값-실제)^2 + n ...)
return tf.keras.losses.mse(train_y, 예측_y) #실제값 , 예측값딥러닝 모델 만들기( 히든 레이어 )
# 딥러닝 모델 만들기 ( 히든레이어 )
## 딥러닝 노드 갯수는 마음대로 넣어도 됨 -> 실험적을 파악해야함 (관례적으로 2의 제곱수로 넣음)
### 결과는 하나기 때문에 하나만 적어두겠음
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='tanh'),
tf.keras.layers.Dense(128, activation='tanh'), # tanH 그냥 넣음
tf.keras.layers.Dense(1, activation='sigmoid') # sigmoid = 뱉는 값이 0.0~1.0 뿐
]).compile(), .fit() : 모델 컴파일하고 학습하기
## 모델 완성단계
### optimizer 는 adam 쓰는게 일반적
### loss 는 0,1 값을 가져올거면 binary_corssentropy
model.compile(optimizer ='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 학습시기키
## x에서는 학습데이터, y데이터는 실제정답
## 에포크는 데이터 보는 횟수
modle.fit(x데이터, y데이터, epochs=1)pandas.read_csv csv 데이터 읽기
- import pandas ad pd 하기
- pandas 이용하는 이유는 csv 읽기 위해
import pandas as pd
data = pd.read_csv('gpascore.csv')
print(data)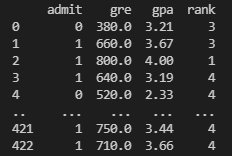
데이터 전처리
- 데이터를 받다보면 중간에 빵구난 값들이 종종 있음
- 이친구들 처리하는 것
- .isnull() : null 값 찾기
- .sum() : 더하기
print(data.isnull().sum())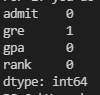
-
null이 gre 에서 하나 나왔다고 나옴
-
.dropna : NA 값들 이 있는 행들을 삭제.
data = data.dropna()
print(data.isnull().sum())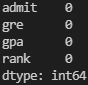
-
삭제되었음을 확인
-
.fillna() : na에 값을 넣어줄 수 있음.
-
데이터['해당 테이블'] : 해당되는 테이블값을 가져올 수 있음.
- ['해당 테이블'].min() : 최소값 반환
- .max() : 최대값 반환
- .count() : 개수 반환
-
.valuse() : 값들을 리스트로 변환
-
.iterrow() : 판다스 데이터프레임에서 한행씩 볼수있음.
for i, rows in data.iterrows():
# iterrow() : 판다스 데이터프레임에서 한행씩 볼수있음.
print(rows)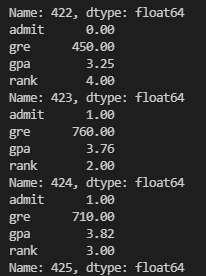
- [ gre, gpa, rank ] 이렇게 데이터 넣어보기
x데이터 = [ ]
for i, rows in data.iterrows():
# iterrow() : 판다스 데이터프레임에서 한행씩 볼수있음.
x데이터.append([rows['gre'], rows['gpa'], rows['rank']])
.fit()
- 교육시켜주기
- model.fit() 에는 numpy 행열만 들어갈수 있음.
## numpy로 넣어야함
model.fit(np.array(x데이터), np.array(y데이터), epochs=10)- 교육결과

- loss : 손실 합산
- accuracy : 정확도
- 에포크값을 늘려주면 정확도 향상 가능

달리다 넘어져도 아픔마저 즐기려하는 사람