
타 서비스 data를 사용해보기 위하여 작업하던 중 MS Fabric의 분석 tool 포지션인 notebook을 약간 deep 하게 파고 들어가게 되었다.
1. Ms fabric 노트북 뭐로 구성되어있는데?
해당 환경은 스파크로 되어있어 빠른 분석을 제공한다.
라고 되어있는게 공식설명이고 그건 알겠으니 더 자세한 정보를 보도록 한다.
노트북에서 linux 명령어를 사용하려면 ! 를 붙여 명령어를 사용하면 된다.
1.1 os를 확인해본다.
!cat /etc/os-release
NAME="Common Base Linux Mariner"
VERSION="2.0.20240425"
ID=mariner
VERSION_ID="2.0"
PRETTY_NAME="CBL-Mariner/Linux"
ANSI_COLOR="1;34"
HOME_URL="https://aka.ms/cbl-mariner"
BUG_REPORT_URL="https://aka.ms/cbl-mariner"
SUPPORT_URL="https://aka.ms/cbl-mariner"해당환경은 ms에서 클라우드 인프라와 등등 제품들을 위해 만든 linux 배포판이다.
CBL-Mariner는 Microsoft의 클라우드 인프라와 엣지 제품 및 서비스를 위한 내부 Linux 배포판이다.
common base linux mariner
- lightweight characteristics of CBL-Mariner also provides faster boot times and a minimal attack surface
가볍고, 빠른 부팅타임 그리고 최소한의 공격이 있다고는한다.
1.2 python 버전확인
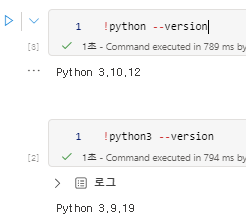
- python은 3.10.12
- python3은 python3.9.19로 나온다.
두개다 설치 되어있나보다
1.3 나는 어디에 있나?

!pwd 내 위치를 확인해본다.
- /mnt/var/hadoop/tmp/nm-secondary-local-dir/usercache/trusted-service-user/a`ppcache/application1718162946304_0001/container~ 로나온다.
해당 리소스가 하둡 기반으로 설정해놓은걸 확인했다.
1.4 구조를 다 보여줘
!tree
이걸로 스파크의 리소스 등을 파악 할 수 있었다.
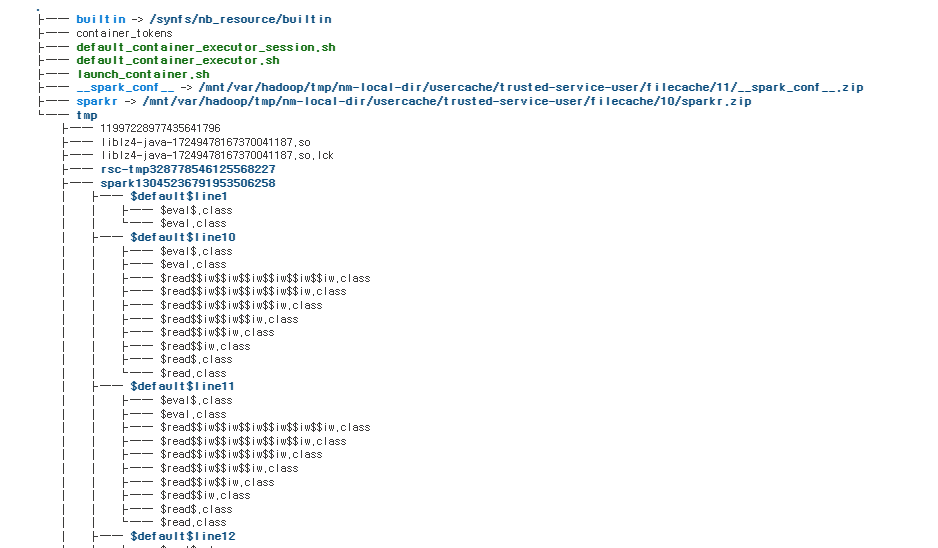
.
├── builtin -> /synfs/nb_resource/builtin
├── container_tokens
├── default_container_executor_session.sh
├── default_container_executor.sh
├── launch_container.sh
├── __spark_conf__ -> /mnt/var/hadoop/tmp/nm-local-dir/usercache/trusted-service-user/filecache/11/__spark_conf__.zip
├── sparkr -> /mnt/var/hadoop/tmp/nm-local-dir/usercache/trusted-service-user/filecache/10/sparkr.zip
└── tmp- builtin: 이 디렉토리는 Spark 애플리케이션 실행에 필요한 기본적인 기능과 리소스를 담고 있다.
- 이 안에는 Spark의 기본적인 함수, 데이터 구조, 예외 처리 등의 기능이 포함되어 있습니다.
- container_tokens: Spark 애플리케이션 실행에 필요한 컨테이너 토큰이 포함되어 있습니다.
- Spark 애플리케이션은 자원을 효율적으로 활용하기 위해 컨테이너를 사용. 컨테이너 토큰은 컨테이너 생성, 실행, 종료 등을 제어하는 역할.
- default_container_executor_session.sh: Spark 컨테이너 실행기를 위한 세션을 시작하는 스크립트.
- 이 스크립트는 컨테이너 실행에 필요한 환경 변수, 파일 시스템, 네트워크 연결 등을 설정.
- default_container_executor.sh: Spark 애플리케이션에서 사용하는 기본 컨테이너 실행기 스크립트.
- 컨테이너 실행을 담당하는 핵심적인 스크립트. 컨테이너 내에서 Spark 애플리케이션을 실행하고 관리하는 역할.
- launch_container.sh: Spark 컨테이너를 시작하는 데 사용.
- 컨테이너 실행기에 대한 설정과 정보를 전달하고 컨테이너를 실행하는 데 필요한 명령을 실행.
- spark_conf: Spark 애플리케이션의 구성 정보를 담은 파일.
mnt/var/hadoop/tmp/nm-local-dir/usercache/trusted-service-user/filecache/11/__spark_conf__.zip에 심볼릭 링크.- 이 파일은 Spark 애플리케이션의 설정, 자원 할당, 실행 옵션 등의 정보를 포함.
- sparkr: SparkR 라이브러리 파일입니다.
mnt/var/hadoop/tmp/nm-local-dir/usercache/trusted-service-user/filecache/10/sparkr.zip에 심볼릭 링크.- R 프로그래밍 언어에서 Spark 애플리케이션을 사용할 수 있도록 하는 라이브러리.
2. 접근 권한
연결 테스트를 해보는 중 특정 라이브러리가 호출이 안되는 문제가 발생했다.
해당 라이브러리를 실행하려면 base가 되는 라이브러리가 필요했는데 그게 connecting 되는 destination에 따라서 주입을 해줘야했기 때문이다.
이를 위해 LD_LIBRARY_PATH 라는 환경변수에서 주입이 필요한 라이브러리를 넣어주어야했다.
2.1 동적 라이브러리 path 추가해주기 (실패)
!export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/synfs/nb_resource/env
이런방법으로 동적 라이브러리 스캔되는 폴더를 추가해주려고하였다.
하지만 echo $LD_LIBRARY_PATH를 했을때 추가가 되었다는걸 확인했지만, 라이브러리가 인식을 하지 못하였다.
실패 이유
- 아마 해당 folder를 export 한 이후 세션을 종료하고 다시 up 해야했지 않나 싶다.
이렇게 된다면 fabric notebook은 세션을 종료하면 기존 작업이 다 사라지기때문에 불가능했다.
2.2 기등록된 폴더에 해당 라이브러리를 넣어주기
단순하게 생각하면 여기에 넣으면 되는건데 멀리 돌아간 것 같다.
분명 기존 세팅되어있는 폴더에 넣게된다면 충돌이나 여타 문제가 발생할 것이라 생각이되어 추후에 진행하고자 하였다.
2.2.1 hadoop-client lib 에 바로 넣기(실패)
/usr/hdp/current/hadoop-client/lib/native/ 에 라이브러리를 copy하는 작업을 하였다. 하지만 처참한 실패.
permission deny가 발생하였다.

2.2.2 두번째 path에 집어넣기
!cp ~lib/* /opt/gluten/dep/
문제없이 복사가 되었고, 이후 원하던 라이브러리도 문제없이 import가 되었다.
3. 반쪽 승리
원하던 라이브러리를 import 하는데까지 성공했지만
fabric의 노트북은 유동ip라서 세션이 updown 될때마다 ip가 변경된다.
- 애저 서비스를 이용하면 tag를 이용하여 ip 주소 대역을 등록하는게 쉬워보인다.하지만 destination이 온프렘이나 AWS와 같은 타 cloud 서비스라면.... 안될 듯하다.
- 위와 같은 이유로 성공을 하지는 못했다. (vnet 설정이나 조금 더 찾아보아야할 것 같긴하다.)
3.1 알게된점
- ms에서 linux 기반 클라우드용 os도 만들어놨다.
- fabric notebook은 계속 ip가 바뀐다.
- notebook을 도커컴포즈로 하둡 스파크를 띄운다고 생각을 하면 이해하기 쉬운 것 같다.
