세븐일레븐 홈페이지를 활용하여 전국 매장 파악하기.
가맹사업을 하는 회사들은 대부분 지점을 각 사의 홈페이지에 업데이트를 한다.
이를 바탕으로 파이썬 크롤링작업을 하여 전국 세븐일레븐의 매장명, 주소 그리고 제공서비스를 데이터화 하고자 한다.
이 과정에서 필요한 모듈은 작업시 하나씩 추가 해가야하지만 완성된 코드를 바탕으로 정리할 것이다.
크롤링과정에서 사용된 모듈
from selenium import webdriver from selenium.webdriver.common.by import By import time from bs4 import BeautifulSoup as BS import requests import re import pandas as pd#by모듈을 사용하게 되면 오류가 날 확률이 줄어든다.
#기다리는 시간 추가하기위해서.
#웹 구성이 어떻게 되어있는지 열거형식 말고 기본 형식 그대로 보기위한 모듈
#requests : http 라이브러리
#re모듈은 정규식 같은 것 관련
#pandas 데이터를 시각화 하기 위한 모듈
셀레니움 웹드라이버, by모듈, time 모듈, 뷰리풀 숩 모듈, requests 모듈, re모듈, pandas 모듈
총7개의 모듈을 사용할 예정이다.
셀레니움 헤드레스 설정
작업중에는 어떻게 진행되고 있는지 파악하면서 해야하기 때문에 크롬을 headless 하지 않는 것이 좋을 것 같다.
options = webdriver.ChromeOptions( options.add_argument('headless')#웹드라이버에서 크롬옵션을 options 로 정의
#옵션스에 headless로 작동하게 하는 옵션 추가
드라이버 명명 및 url 주소 입력
driver = webdriver.Chrome() url = "https://www.7-eleven.co.kr/" driver.get(url)#웹드라이버 크롬을 드라이버로 정의한다.
#url은 세븐일레븐 홈페이지
#크롬드라이버에서 url을 입력한다.
점포찾기로 찾아가기
target_store = "#header > div > div > div.head_util > a.util_store.store_open" driver.find_element(By.CSS_SELECTOR, target_store).click() time.sleep(3)#점포찾기 버튼을 누르기위한 과정
#점포찾기 누른후 딜레이를 줘야 오류가 나지 않는다.
크롬 드라이버에서 css_selector를 사용하여 위치를 파악한다.
target_store을 보고 이동.
시도 기준으로 도시명 저장하기
city_dict= {} for x in range(2, 19): driver.find_element(By.CSS_SELECTOR, f"#storeLaySido > option:nth-child({x})").click() time.sleep(2) city = driver.find_element(By.CSS_SELECTOR, f"#storeLaySido > option:nth-child({x})").text city_dict[city] = [x.text for x in BS(driver.page_source).find("select", id="storeLayGu")][3::2] for key, value in city_dict.items(): print(key, value)#시도기준으로 도시명을 딕셔너리로 저장할거다.
#0,1은 선택하는 것이 있기때문에 2부터 시작
#요소를 찾아서 클릭하는데 css seector로 한다.
#중간에 쉬어주고
#:nth-child()는 형제 요소 중 an+b번째 요소들을 선택하는 선택자이다.
#css에서 찾는다. 스토어 시도.
#따라서 키랑 밸류를 반복문을 통해 출력하면 구군 리스트가 출력이 된다.
#여기서 [3::2]를 해준 이유는 3부터 시작해야 빈 값이 안들어가는데다 2계단씩 올라가야 빈 이상한 값이 안들어간다. \n이 빠질 수 있다.
#.items를 사용하면 딕셔너리의 키값과 value를 가져올 수 있다.
작업내용을 출력
for key, value in city_dict.items(): print(key, value)#.items를 사용하면 딕셔너리의 키값과 value를 가져올 수 있다.
#따라서 키랑 밸류를 반복문을 통해 출력하면 구군 리스트가 출력이 된다.

세종에는 매장이 없다.
def api_seven(page): seven = BS(page) seven_total = [] for tmp in seven.find("div", class_="list_stroe").findAll("li"): seven_dict = {} seven_dict['offeringService'] = [x['alt'] for x in tmp.findAll("img")] seven_dict['shopName'] = tmp.find("span").text.strip() try: seven_dict['address']= " ".join(tmp.findAll("span")[-2].text.split()) except: return [] if len(seven_dict['address']) < 2 : seven_dict['address']= " ".join(tmp.findAll("span")[-3].text.split()) _, lat, lon = re.findall("(?<=\().+(?=\))", tmp.find('a')['href'])[0].split(",") seven_dict['longs'] = lon seven_dict['lat'] = lat seven_total.append(seven_dict) return pd.DataFrame(seven_total)#api_seven 이라는 함수를 만든다.
#세븐은 뷰리풀 숩으로 page를 넣고 돌리는 것으로 정의한다.
#세븐 토탈이라는 리스트를 준다.
#tmp를 포문으로 반복 돌리는데, seven을 뷰리풀숩으로 보여주는 값에서 div 를 찾는데 class 명은 리스트 스토어를 찾는다.
#그밑에서 li를 찾아준다.
#세븐 딕셔너리를 정의한다.
#세븐 딕셔너리에서 제공서비스를 찾는데, x를 반복한다. 이미지를 찾는다. 홈페이지에서 제공서비스를 표시한게 이미지형식이라 이렇게 찾는 듯 하다.
#같은 형식으로 샵네임을 bs로 찾는다..strip() 은 문자열 공백 제거하는 과정에서 사용된다.
#try, excepr, return을 이용하여 예외 처리를 해준다. (세종이랑 공백이 있어서 사용)
#정규화를 이용하였다.
api를 활용한 작업
seven_url = "https://www.7-eleven.co.kr/util/storeLayerPop.asp " payload = {"storeLaySido": "서울", "storeLayGu": "구로구", "hiddentext": "none"}
payload를 가져온다.
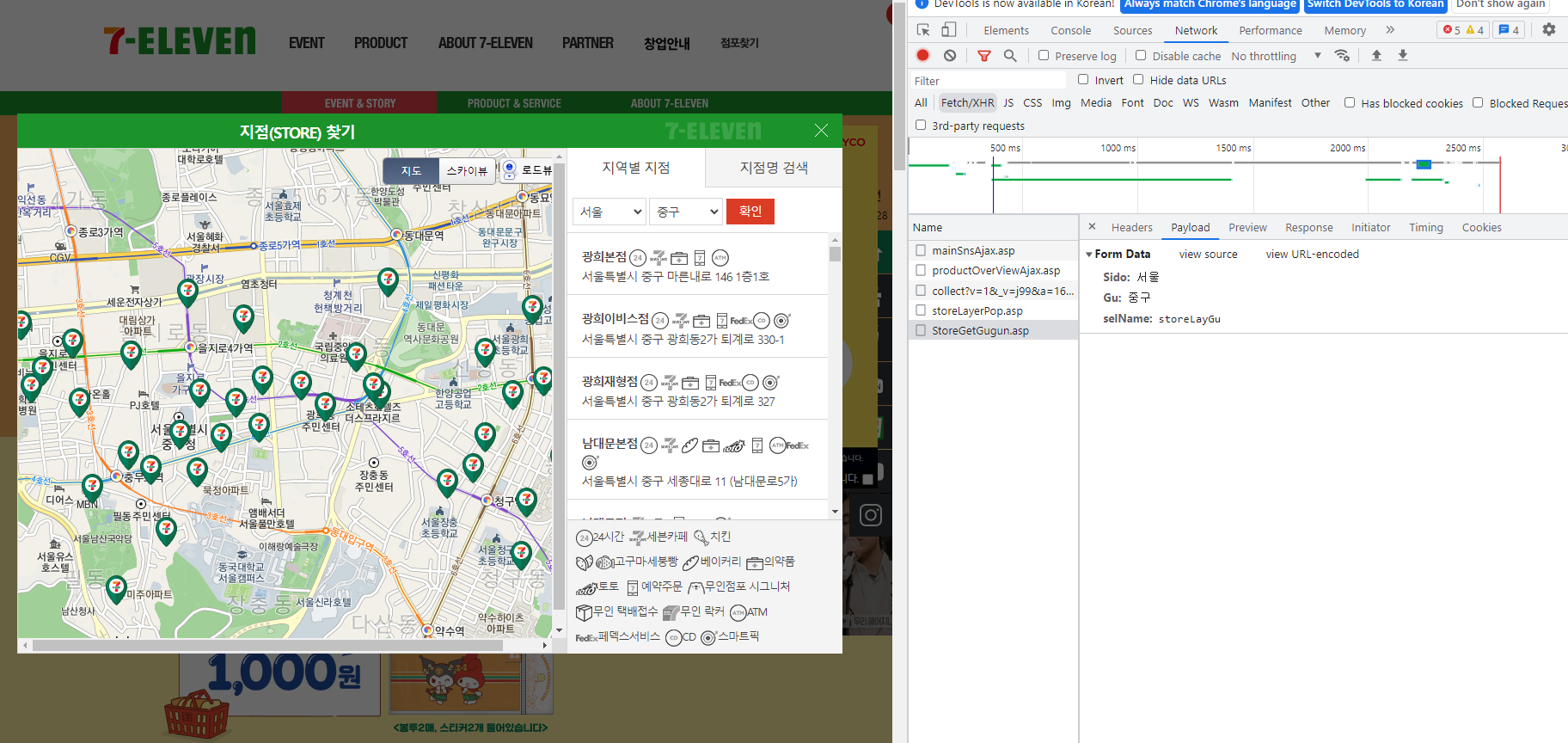
r= requests.post(seven_url, data=payload) total = [] for key, value in city_dict.items(): print(key) payload['storeLaySido'] = key for x in value: payload['storeLayGu'] = x total.append(api_seven(requests.post(seven_url, data=payload).text))#for문을 활용하여 반복작업을 진행한다. 키에 대한 반복문과 값에대한 반복 두가지가 나와있다.
value에 대해서 다 print 하면 복잡하기에 key에 관해서 출력함으로 값이 제대로 적용되었는지 확인한다.
value는 .append를 이용하여 total에 추가됨.
total 재정의
total = pd.concat([x for x in total if type(x) == type(pd.DataFrame())]) total.shape #shape는 넘파이 명령문, shape attribute 는 array의 형태를 알려준다.total을 여러개의 데이터프레임을 하나로 합치는 역할.
total.shape에 shape는 넘파이 명령문으로 array의 형태를 알려준다.
출력 결과 (12676, 5)로 나온다.
총 12676개의 행이있다는 것으로 전국의 세븐일레븐 매장은 12676개가 있다.
출력 값 정렬 및 excel로 저장
total.reset_index(drop=True, inplace=True) total.to_excel("./세븐일레븐_전국_현황.xlsx") total열은 제공서비스. 지점명, 주소, 좌표로 이루어져있다.